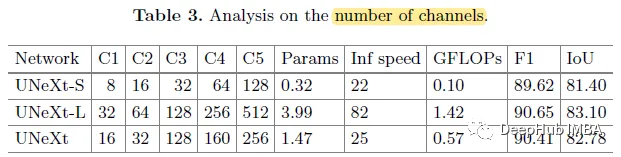
顺序表
数据结构 = 结构定义+结构操作
顺序表:结构定义
一个数组,添加额外的几个属性:size, count等
size: 数组有多大
count: 数组中当前存储了多少元素
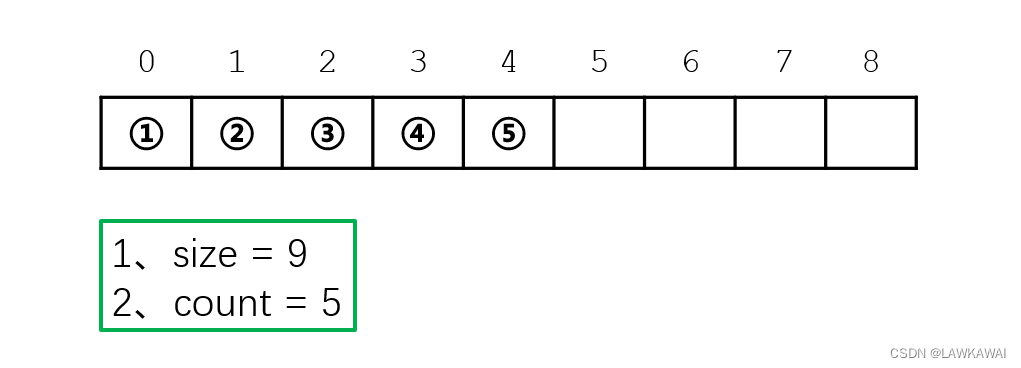
顺序表三部分:
- 一段连续的存储区:顺序表存储元素的地方
- 整型的变量size: 标记顺序表的大小
- 整型变量count: 标记顺序表中到底存储了多少了元素
代码
结构定义
typedef struct vector{
int size, count;
int *data; // 一段连续的存储区,存储的是整型元素, data指针指向整型的存储区
}vector;
构造函数
首先开辟顺序表本身的空间p, 然后给p的size赋值,p的count赋值,最后给p的data赋值,p的data指向的是顺序表中那段连续的存储区,存储区的大小是n
vector * getNewVector(int n)
{
vector *p = (vector *)malloc(sizeof(vector));
p->size = n;
p->count = 0;
p->data = (int*)malloc(sizeof(int)* n);
return p;
}
析构函数
销毁之前先判断一下,如果对象为空,就直接返回;先销毁顺序表中连续的存储区,再销毁顺序表本身的存储空间
void clear(vector* v)
{
if (v == NULL) return;
free(v->data);
free(v);
return;
}
顺序表:插入
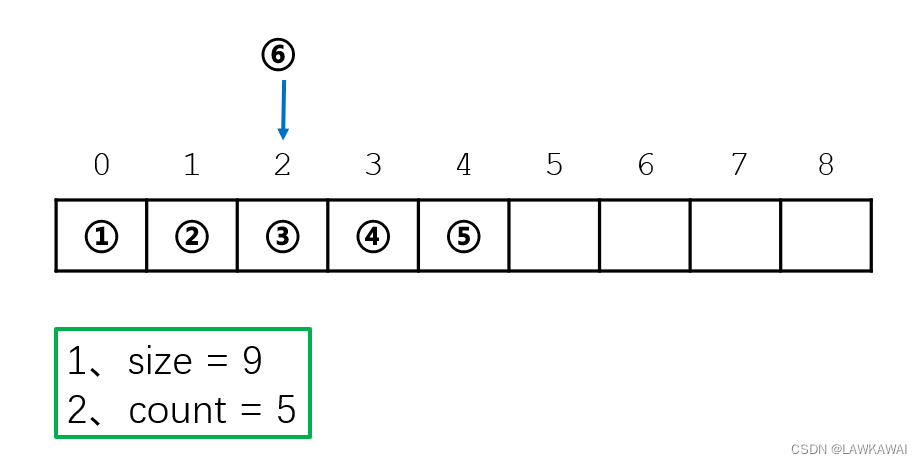
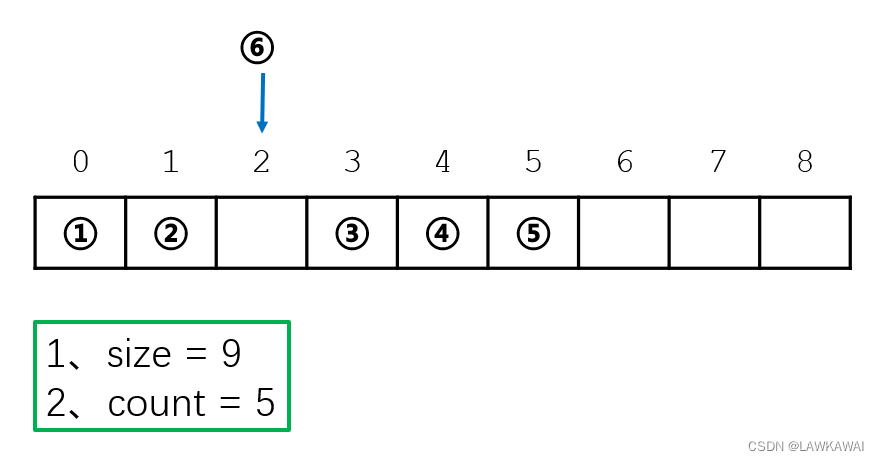
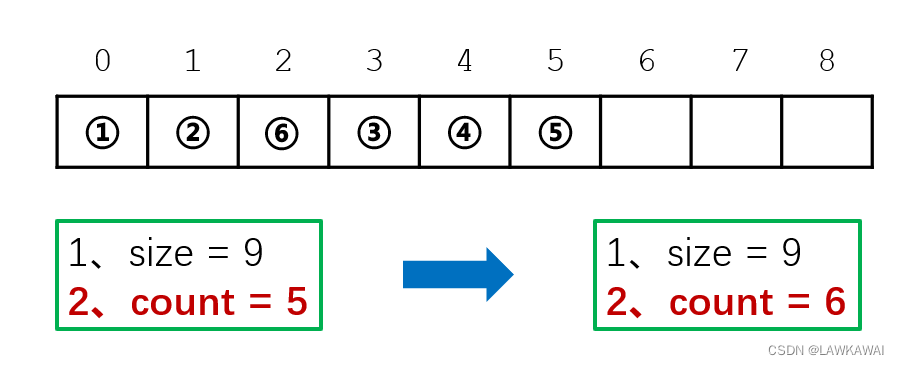
size不变
count+1
代码
插入之前先判断一下,插入位置的合法性以及顺序表的地方是否够用,如果存满了,本次插入不成功,返回0;否则没有存满,则可以将所有元素平行向后移动一位,以逆序遍历向后移动,从最后一位(count - 1)开始遍历,递减到插入位置pos,然后将元素插入。
最后,数据结构是包括性质的,还需要维护性质,即count+1
int insert(vector*v, int pos, int val)
{
if (pos < 0 || pos > v->count) return 0;
if (v->size == v->count) return 0;
for (int i = v->count - 1; i >= pos; i--)
{
v->data[i + 1] = v->data[i];
}
v->data[pos] = val;
v->count += 1;
return 1;
}
顺序表:删除
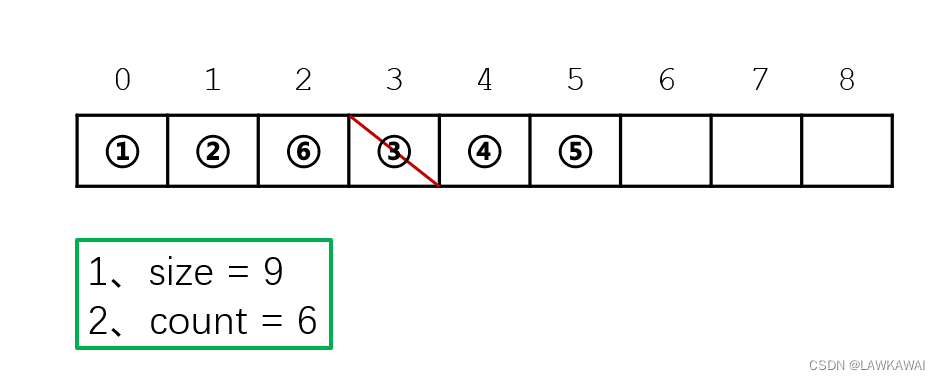
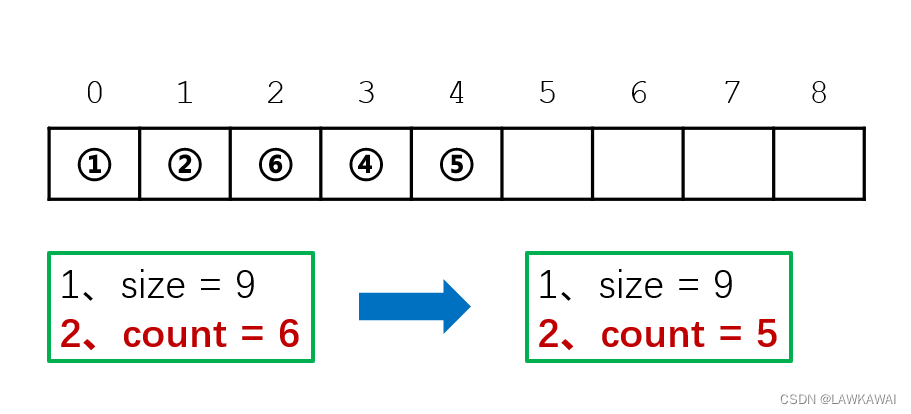
size不变
count-1
代码
判断删除位置的合法性,然后后面的元素平行向前移动一个元素
int erase(vector *v, int pos)
{
if (pos < 0 || pos >= v->count) return 0;
for (int i = pos + 1; i < v->count; i++)
{
v->data[i - 1] = v->data[i];
}
v->count -= 1;
return 1;
}
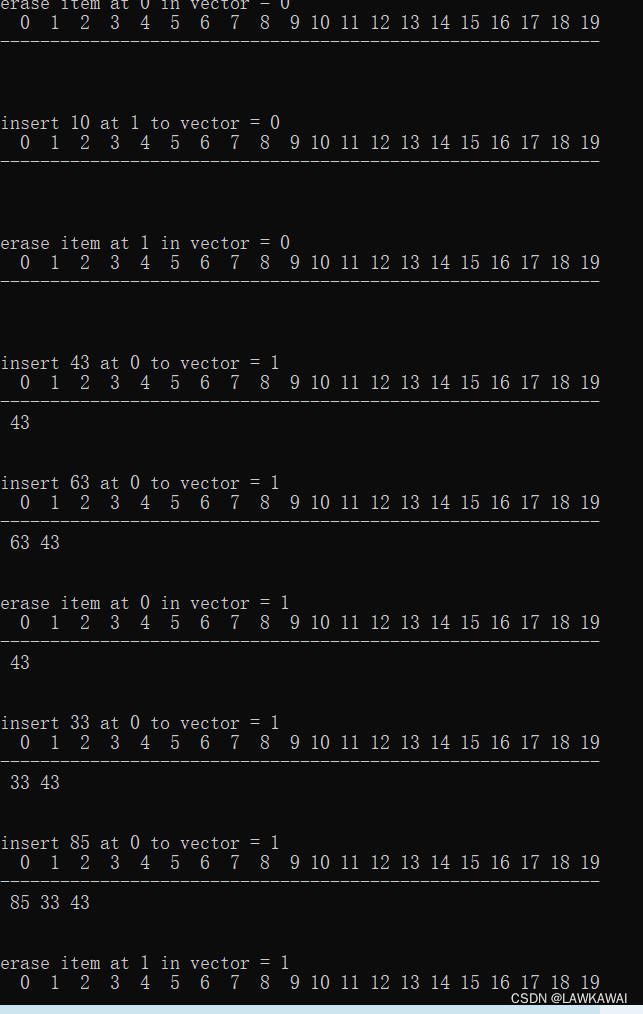
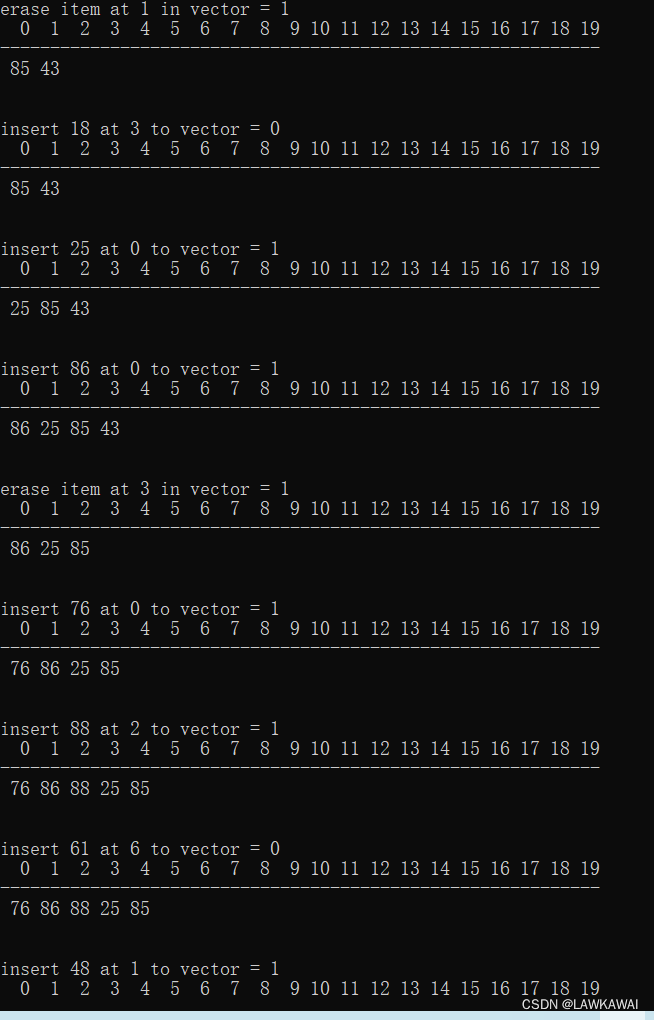
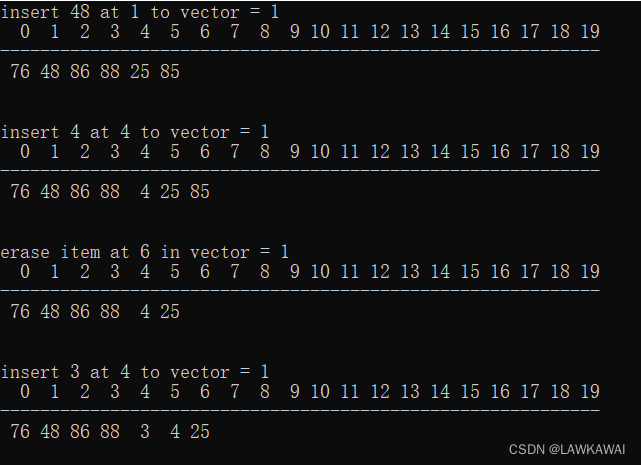
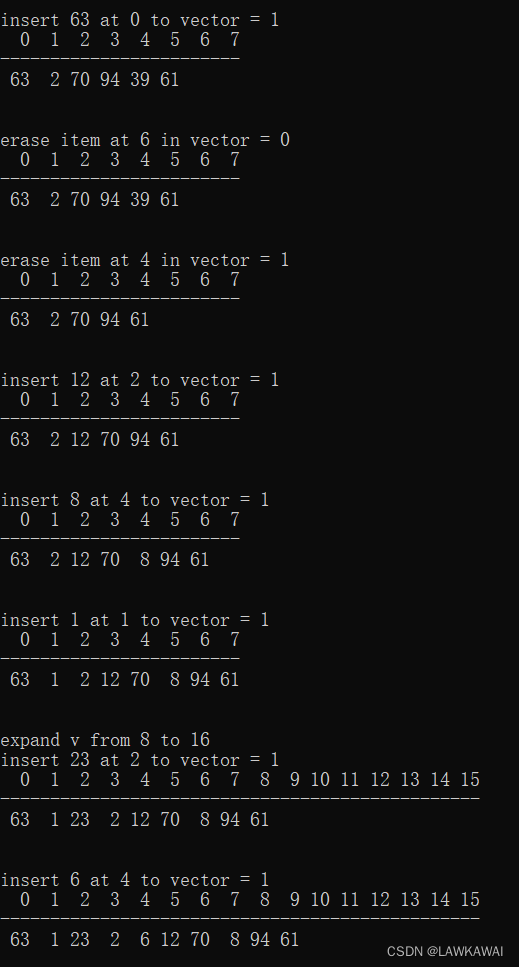
代码演示
用一组随机操作,对顺序表进行测试
可以在4范围内随机: 0, 1, 2表示插入, 3表示删除
随机插入的位置: 随机数 % (count +2), 随机出一些非法位置,测试程序返回的结果是否正确。
然后进行插入和删除操作
输出格式:第一行是数组的序号,第二行是小横线,第三行元素
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
typedef struct vector{
int size, count;
int *data; // 一段连续的存储区,存储的是整型元素, data指针指向整型的存储区
}vector;
vector * getNewVector(int n)
{
vector *p = (vector *)malloc(sizeof(vector));
p->size = n;
p->count = 0;
p->data = (int*)malloc(sizeof(int)* n);
return p;
}
int insert(vector*v, int pos, int val)
{
if (pos < 0 || pos > v->count) return 0;
if (v->size == v->count) return 0;
for (int i = v->count - 1; i >= pos; i--)
{
v->data[i + 1] = v->data[i];
}
v->data[pos] = val;
v->count += 1;
return 1;
}
int erase(vector *v, int pos)
{
if (pos < 0 || pos >= v->count) return 0;
for (int i = pos + 1; i < v->count; i++)
{
v->data[i - 1] = v->data[i];
}
v->count -= 1;
return 1;
}
void clear(vector* v)
{
if (v == NULL) return;
free(v->data);
free(v);
return;
}
void output_vector(vector *v)
{
int len = 0;
for (int i = 0; i < v->size; i++)
{
len += printf("%3d", i); // 控制整型输出的宽度, 累加输出的长度
}
printf("\n");
for (int i = 0; i < len; i++) printf("-"); // 注意输出的长度为len与上面对齐
printf("\n");
for (int i = 0; i < v->count; i++) // 注意输出的长度为count
{
printf("%3d", v->data[i]);
}
printf("\n");
printf("\n\n");
return;
}
int main()
{
srand(time(0));
#define MAX_OP 20
vector *v = getNewVector(MAX_OP);
for (int i = 0; i < MAX_OP; i++)
{
int op = rand() % 4, pos, val;
switch (op)
{
case 0:
case 1:
case 2:
pos = rand() % (v->count + 2);
val = rand() % 100;
printf("insert %d at %d to vector = %d\n", val, pos, insert(v, pos, val));
break;
case 3:
pos = rand() % (v->count + 2);
printf("erase item at %d in vector = %d\n", pos, erase(v, pos));
break;
}
output_vector(v);
}
clear(v);
std::cin.get();
return 0;
}
输出:
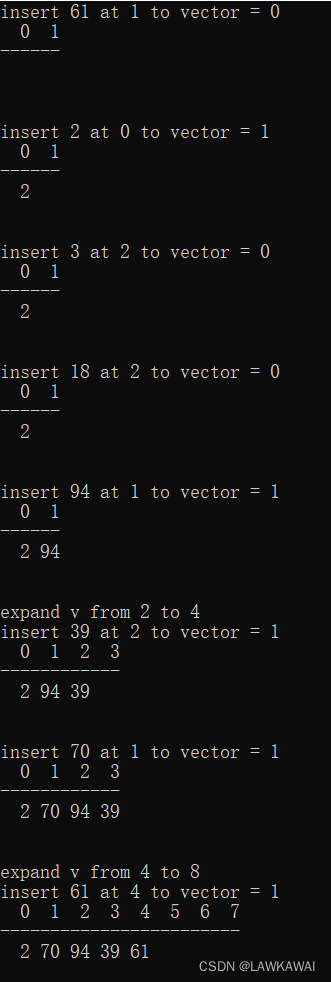
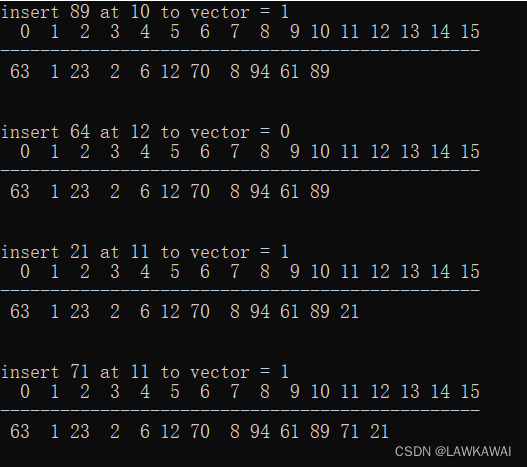
顺序表:扩容操作
当进行插入操作的时候,发现顺序表已经满了,可以自动扩容,扩容后就可以插入成功。
假设现在已经有了扩容成功了,什么情况下才返回插入不成功? 答案:顺序表满了,并且扩容操作不成功,才返回0
还是跟前面一样,先判断一下传进来的顺序表的指针合不合法,判断指针是否指向空地址。
扩容策略: 二倍扩容法,如果原来顺序表的大小是size,尝试将size的顺序表扩容到2*size的大小,扩容的是顺序表的data区
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
typedef struct vector{
int size, count;
int *data; // 一段连续的存储区,存储的是整型元素, data指针指向整型的存储区
}vector;
vector * getNewVector(int n)
{
vector *p = (vector *)malloc(sizeof(vector));
p->size = n;
p->count = 0;
p->data = (int*)malloc(sizeof(int)* n);
return p;
}
int expand(vector *v)
{
if (v == NULL) return 0;
printf("expand v from %d to %d\n", v->size, 2 * v->size ); // 输出扩容提示信息
v->data = (int *)realloc(v->data, sizeof(int) * 2 * v->size); // realloc(重新分配存储区的地址,希望重新分配的内存大小)
v->size *= 2; // 更新扩容后的size,2倍
return 1;
}
int insert(vector*v, int pos, int val)
{
if (pos < 0 || pos > v->count) return 0;
if (v->size == v->count && !expand(v)) return 0; // 如果满了且扩容失败,返回0
for (int i = v->count - 1; i >= pos; i--)
{
v->data[i + 1] = v->data[i];
}
v->data[pos] = val;
v->count += 1;
return 1;
}
int erase(vector *v, int pos)
{
if (pos < 0 || pos >= v->count) return 0;
for (int i = pos + 1; i < v->count; i++)
{
v->data[i - 1] = v->data[i];
}
v->count -= 1;
return 1;
}
void clear(vector* v)
{
if (v == NULL) return;
free(v->data);
free(v);
return;
}
void output_vector(vector *v)
{
int len = 0;
for (int i = 0; i < v->size; i++)
{
len += printf("%3d", i); // 控制整型输出的宽度, 累加输出的长度
}
printf("\n");
for (int i = 0; i < len; i++) printf("-"); // 注意输出的长度为len与上面对齐
printf("\n");
for (int i = 0; i < v->count; i++) // 注意输出的长度为count
{
printf("%3d", v->data[i]);
}
printf("\n");
printf("\n\n");
return;
}
int main()
{
srand(time(0));
#define MAX_OP 20
vector *v = getNewVector(2); //
for (int i = 0; i < MAX_OP; i++)
{
int op = rand() % 4, pos, val, ret;
switch (op)
{
case 0: // 注意case要从0开始
case 1:
case 2:
pos = rand() % (v->count + 2);
val = rand() % 100;
ret = insert(v, pos, val);
printf("insert %d at %d to vector = %d\n", val, pos, ret);
break;
case 3:
pos = rand() % (v->count + 2);
ret = erase(v, pos);
printf("erase item at %d in vector = %d\n", pos, ret);
break;
}
output_vector(v);
}
clear(v);
std::cin.get();
return 0;
}
输出:
进一步分析
其实在重新分配内存(realloc)的时候有bug,realloc的策略:
- realloc会在原内存地址上试着向后去进行延展,如果向后扩展成功了,那么返回的地址就会和原内存地址是一样的,但是大小会增加一倍
- 找一片新的内存,把原内存的内容拷贝到新内存里面,并且返回新内存的地址。
- 以上两种情况都找不到,就会返回NULL
所以,再返回来看源代码,第一和第二种情况都没有bug,但是第三种情况,即扩容不成功的情况下,realloc会返回一个空地址,空地址会覆盖掉原来存储的地址,这个时候就会发生我们data中原来存储的地址信息丢失了。
解决方案:新定义一个指针,把realloc的返回值赋值给这个新指针,然后先判断是否为空,不是空地址才将新地址赋值给data
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
typedef struct vector{
int size, count;
int *data; // 一段连续的存储区,存储的是整型元素, data指针指向整型的存储区
}vector;
vector * getNewVector(int n)
{
vector *p = (vector *)malloc(sizeof(vector));
p->size = n;
p->count = 0;
p->data = (int*)malloc(sizeof(int)* n);
return p;
}
int expand(vector *v)
{
if (v == NULL) return 0;
printf("expand v from %d to %d\n", v->size, 2 * v->size ); // 输出扩容提示信息
int *p = (int *)realloc(v->data, sizeof(int)* 2 * v->size); // realloc(重新分配存储区的地址,希望重新分配的内存大小)
if (p == NULL) return 0;
v->data = p;
v->size *= 2; // 更新扩容后的size,2倍
return 1;
}
int insert(vector*v, int pos, int val)
{
if (pos < 0 || pos > v->count) return 0;
if (v->size == v->count && !expand(v)) return 0; // 如果满了且扩容失败,返回0
for (int i = v->count - 1; i >= pos; i--)
{
v->data[i + 1] = v->data[i];
}
v->data[pos] = val;
v->count += 1;
return 1;
}
int erase(vector *v, int pos)
{
if (pos < 0 || pos >= v->count) return 0;
for (int i = pos + 1; i < v->count; i++)
{
v->data[i - 1] = v->data[i];
}
v->count -= 1;
return 1;
}
void clear(vector* v)
{
if (v == NULL) return;
free(v->data);
free(v);
return;
}
void output_vector(vector *v)
{
int len = 0;
for (int i = 0; i < v->size; i++)
{
len += printf("%3d", i); // 控制整型输出的宽度, 累加输出的长度
}
printf("\n");
for (int i = 0; i < len; i++) printf("-"); // 注意输出的长度为len与上面对齐
printf("\n");
for (int i = 0; i < v->count; i++) // 注意输出的长度为count
{
printf("%3d", v->data[i]);
}
printf("\n");
printf("\n\n");
return;
}
int main()
{
srand(time(0));
#define MAX_OP 20
vector *v = getNewVector(2); //
for (int i = 0; i < MAX_OP; i++)
{
int op = rand() % 4, pos, val, ret;
switch (op)
{
case 0: // 注意case要从0开始
case 1:
case 2:
pos = rand() % (v->count + 2);
val = rand() % 100;
ret = insert(v, pos, val);
printf("insert %d at %d to vector = %d\n", val, pos, ret);
break;
case 3:
pos = rand() % (v->count + 2);
ret = erase(v, pos);
printf("erase item at %d in vector = %d\n", pos, ret);
break;
}
output_vector(v);
}
clear(v);
std::cin.get();
return 0;
}
总结
相关数据结构到底支持什么操作,是一个不确定性的,非常灵活的,是自己设计的。



![[CF复盘] Codeforces Round 871 (Div. 4)20230506](https://img-blog.csdnimg.cn/fc0b0aa844344689bd7f9a5354d45717.png)