Redis 布隆过滤器总结
适用场景
大数据判断是否存在来实现去重:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1) 的级别,但是当数据量起来之后,还是只能考虑布隆过滤器。
解决缓存穿透:我们经常会把一些热点数据放在 Redis 中当作缓存,例如产品详情。通常一个请求过来之后我们会先查询缓存,而不用直接读取数据库,这是提升性能最简单也是最普遍的做法,但是 如果一直请求一个不存在的缓存,那么此时一定不存在缓存,那就会有大量请求直接打到数据库上,造成 缓存穿透,布隆过滤器也可以用来解决此类问题。
在我们使用 Redis 时候,经常会面临这么一个问题,缓存穿透,意思是数据库和 redis 中都没有数据,缓存和db完全形同虚设。
面对这种问题,我们一般解决办法是设置null 的空值缓存,还有优雅点的实现方式就是布隆过滤器。
空值缓存
String key = stringRedisTemplate.opsForValue().get("key");
if (StringUtil.isEmpty(key)){
//查询db
Object k = "test";
if (k!=null){
//存redis
stringRedisTemplate.opsForValue().set("key",k.toString(),100);
return k.toString();
}else {
stringRedisTemplate.opsForValue().set("key","nullstr",10);
return "";
}
}
if ("nullstr".equals(key)){
stringRedisTemplate.opsForValue().set("key","nullstr",10);
return "";
}
布隆过滤器
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不 存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可 能不存在;当它说不存在时,那就肯定不存在。
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,使用时候不能删除,如果有必须重新初始化。
实现原理
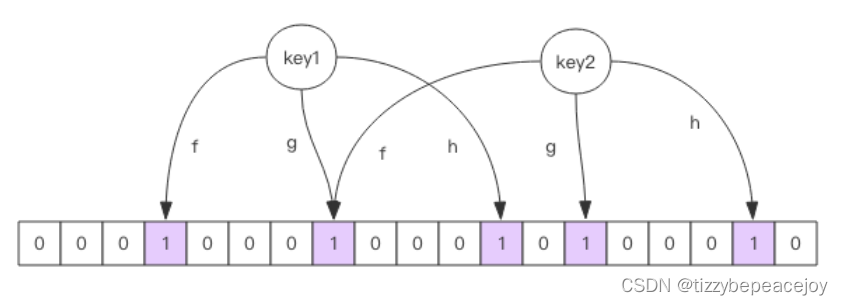
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。
所谓无偏就是能够把元素的 hash 值算得 比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度 进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就 完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位 置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。
如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组 比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为 复杂, 但是缓存空间占用很少。
布隆过滤器的优点:
-
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
-
保密性强,布隆过滤器不存储元素本身
-
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
数据结构
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
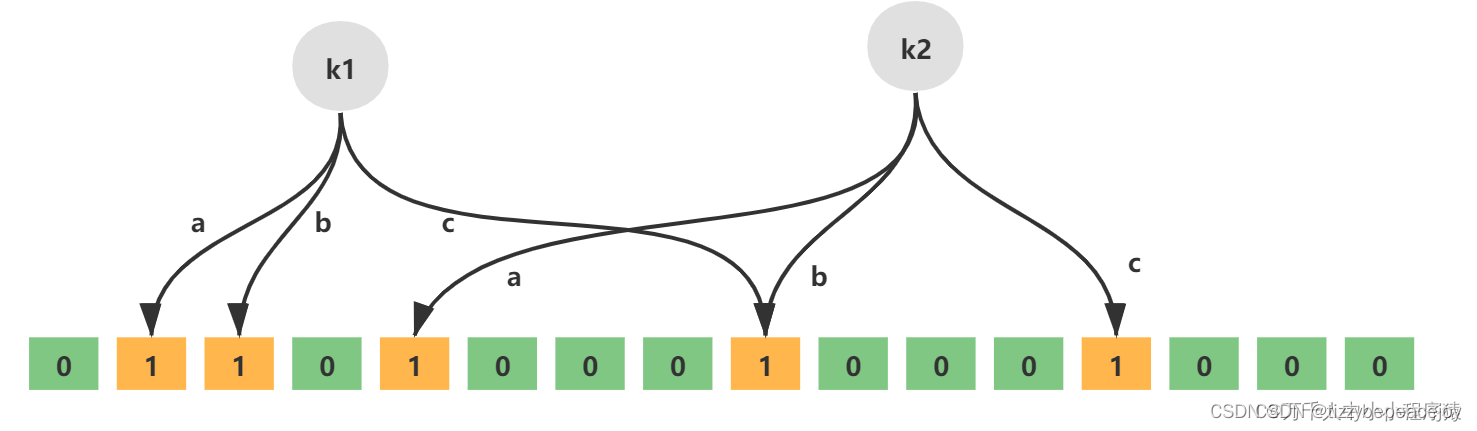
增加元素的步骤:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
将计算得到的数组索引下标位置数据修改为1
查询元素的步骤:
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
误判的情况: hash函数无法完全避免hash冲突,可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如彭于晏和程序员(莫打我)的hash值取模后得到的数组索引都是1,但实际上存储的只有彭于晏,如果此时判断程序员在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
布隆过滤器不支持删除元素。
代码演示
使用redisson
可以用redisson实现布隆过滤器,引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
实例代码
单Redis节点模式
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为 100000L ,误差率为3%,根据这两个参数会计算出底层的bit数组大小
bloomFilter.tryInit(100000L,0.03);
//将 test 插入到布隆过滤器中
bloomFilter.add("test");
bloomFilter.add("test2");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("test3"));//false
System.out.println(bloomFilter.contains("test4"));//false
System.out.println(bloomFilter.contains("test2"));//true
System.out.println(bloomFilter.count()); // 2个元素
System.out.println(bloomFilter.getSize()); // 长度
yaml 配置
---
singleServerConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
address: "redis://127.0.0.1:6379"
subscriptionConnectionMinimumIdleSize: 1
subscriptionConnectionPoolSize: 50
connectionMinimumIdleSize: 32
connectionPoolSize: 64
database: 0
dnsMonitoringInterval: 5000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
集群配置
Config config = new Config();
config.useClusterServers()
.setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒
//可以用"rediss://"来启用SSL连接
.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001")
.addNodeAddress("redis://127.0.0.1:7002");
RedissonClient redisson = Redisson.create(config);
yaml配置
配置集群模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与ClusterServersConfig和Config对象里的字段名称相符。
---
clusterServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
nodeAddresses:
- "redis://127.0.0.1:7004"
- "redis://127.0.0.1:7001"
- "redis://127.0.0.1:7000"
scanInterval: 1000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
哨兵配置
Config config = new Config();
config.useSentinelServers()
.setMasterName("mymaster")
//可以用"rediss://"来启用SSL连接
.addSentinelAddress("127.0.0.1:26389", "127.0.0.1:26379")
.addSentinelAddress("127.0.0.1:26319");
RedissonClient redisson = Redisson.create(config);
yaml
配置哨兵模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与SentinelServersConfig和Config对象里的字段名称相符。
---
sentinelServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
sentinelAddresses:
- "redis://127.0.0.1:26379"
- "redis://127.0.0.1:26389"
masterName: "mymaster"
database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
主从模式
Config config = new Config();
config.useMasterSlaveServers()
//可以用"rediss://"来启用SSL连接
.setMasterAddress("redis://127.0.0.1:6379")
.addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419")
.addSlaveAddress("redis://127.0.0.1:6399");
RedissonClient redisson = Redisson.create(config);
yaml
配置主从模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与MasterSlaveServersConfig和Config对象里的字段名称相符。
---
masterSlaveServersConfig:
idleConnectionTimeout: 10000
connectTimeout: 10000
timeout: 3000
retryAttempts: 3
retryInterval: 1500
failedAttempts: 3
password: null
subscriptionsPerConnection: 5
clientName: null
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
slaveAddresses:
- "redis://127.0.0.1:6381"
- "redis://127.0.0.1:6380"
masterAddress: "redis://127.0.0.1:6379"
database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
详细配置 https://github.com/redisson/redisson/wiki/2.-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95#241-%E9%9B%86%E7%BE%A4%E8%AE%BE%E7%BD%AE
使用Google 开源的 Guava 中自带的布隆过滤器
依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
代码实例
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(),
1000,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
在我们的示例中,当 mightContain() 方法返回 true 时,我们可以 99% 确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100% 确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的 ,但是它是单机使用 ,如果是分布式的场景,需要用到 Redis 中的布隆过滤器了