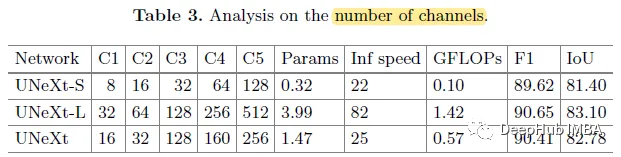
本次搭建的是清华大学开源的ChatGLM。源码地址。模型地址。
1、开启BBR加速
如何开启BBR加速可以去看我的这篇文章,Linux开启内核BBR加速。
2、拉取ChatGLM源码和ChatGLM模型
点击这里跳转到源码处。
点击这里跳转到模型下载处。
我这里在下载之前创建了一个目录专门存放ChatGLM相关的内容。
cd /opt
mkdir ChatGLM
cd ChatGLM
进入ChatGLM目录后,然后就可以下载ChatGLM源码了。
git clone https://github.com/lukeewin/ChatGLM-6B.git
然后我们还需要下载模型文件。并且模型比较大,所以在下载模型文件之前,我们还需要安装git-lfs。
apt install git-lfs
安装完全后,我们先创建一个目录专门存放模型文件,这里我在/opt/ChatGLM路径下创建一个目录。
mkdir model
cd model
然后我们就可以下下载模型数据了。
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b-int4
到这里,ChatGLM源码和对应的模型都克隆到服务器上了。
3、修改配置
在修改配置之前,我们还需要安装cuda。
apt install nvidia-cuda-toolkit
然后修改源码中的requirements.txt中的内容,在末尾添加下面三条语句。
chardet
streamlit
streamlit-chat
然后通过pip命令来安装相关的库。
pip install -r requirements.txt
然后,我们还要修改web_demo2.py文件。
修改下面两个地方,要使用绝对路径。

把上面这两个地方的值改为自己模型的路径,一定要使用绝对路径。
tokenizer = AutoTokenizer.from_pretrained("你自己模型的路径", trust_remote_code=True)
model = AutoModel.from_pretrained("你自己模型的路径", trust_remote_code=True).half().cuda()
然后我们开放一个端口作为web的对外访问端口。
ufw allow 8080/tcp
我这里开放的是8080端口。
你在开放前也可以使用下面的命令查看一下当前已经开放的端口。
ufw status
4、启动项目
python3 -m streamlit run ./web_demo2.py --server.port 8080
然后访问ip:8080就能够看到效果了。
5、效果
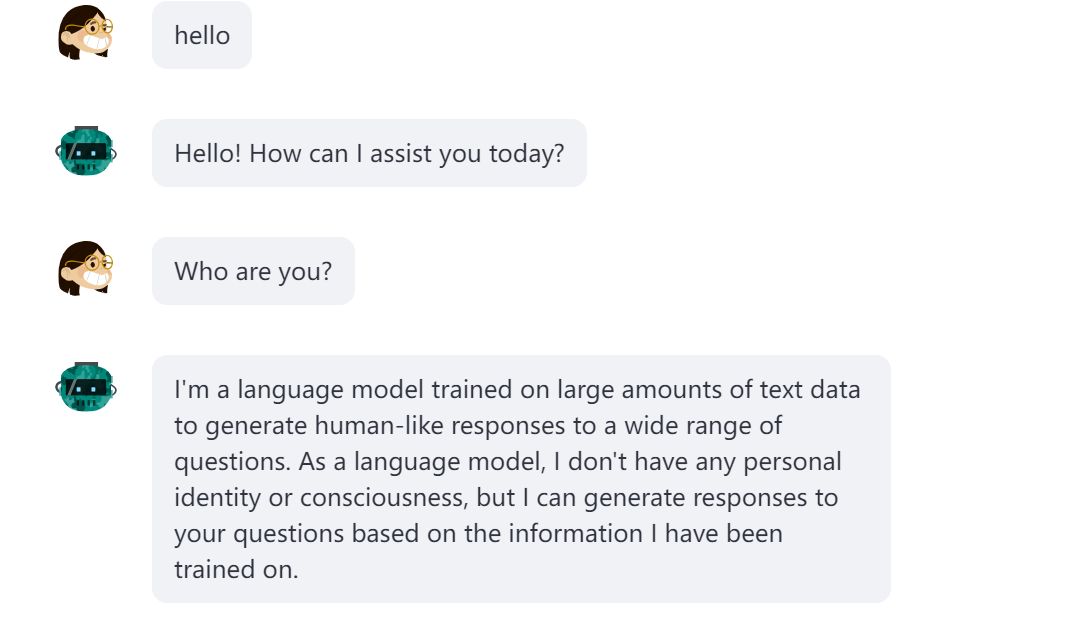
可以使用中文,也可以使用英语进行交流。
如果喜欢本篇文章,记得转发,点赞,收藏。
6、源码和模型下载
点击这里下载源码
点击这里下载模型
7、视频教程
基于云服务搭建ChatGLM
完整内容可以点击这里进行查看。



![[CF复盘] Codeforces Round 871 (Div. 4)20230506](https://img-blog.csdnimg.cn/fc0b0aa844344689bd7f9a5354d45717.png)