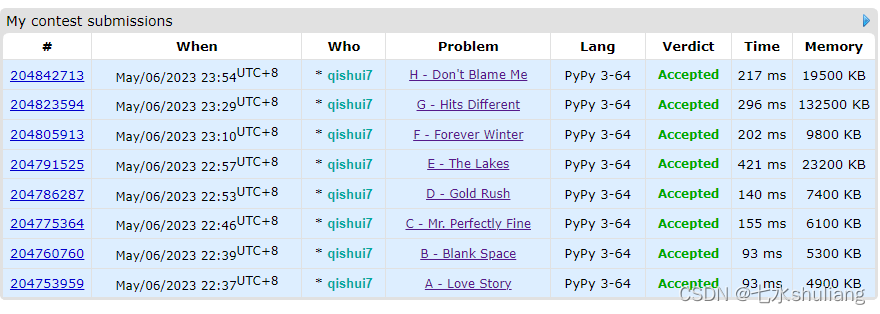
[CF复盘] Codeforces Round 871 Div. 4 20230506
- 总结
- A. Love Story
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- B. Blank Space
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- C. Mr. Perfectly Fine
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- D. Gold Rush
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- E. The Lakes
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- F. Forever Winter
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- G. Hits Different
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
- H. Don't Blame Me
- 1. 题目描述
- 2. 思路分析
- 3. 代码实现
总结
- 又是笨比的一周,只做出1题。
- A 模拟
- B DP
- C 哈希表模拟
- D 递归模拟。
- E BFS最大连通块点权。
- F 计数分类讨论。
- G DP
- H DP

A. Love Story
链接: A. Love Story
1. 题目描述
https://codeforces.com/contest/1829/problem/A
输入t组数据。
每组数据输入一个长为10的字符串。
计算有几个位置不对应"codeforces"
2. 思路分析
模拟
3. 代码实现
# Problem: A. Love Story
# Contest: Codeforces - Codeforces Round 871 (Div. 4)
# URL: https://codeforces.com/contest/1829/problem/A
# Memory Limit: 256 MB
# Time Limit: 1000 ms
import sys
RI = lambda: map(int, sys.stdin.buffer.readline().split())
RS = lambda: map(bytes.decode, sys.stdin.buffer.readline().strip().split())
RILST = lambda: list(RI())
DEBUG = lambda *x: sys.stderr.write(f'{str(x)}\n')
# print = lambda d: sys.stdout.write(str(d) + "\n") # 打开可以快写,但是无法使用print(*ans,sep=' ')这种语法
MOD = 10 ** 9 + 7
PROBLEM = """https://codeforces.com/contest/1829/problem/A
输入t组数据。
每组数据输入一个长为10的字符串。
计算有几个位置不对应"codeforces"
"""
# ms
def solve():
s, = RS()
p = 'codeforces'
ans = 0
for a, b in zip(p, s):
if a != b:
ans += 1
print(ans)
if __name__ == '__main__':
t, = RI()
for _ in range(t):
solve()
B. Blank Space
链接: B. Blank Space
1. 题目描述
https://codeforces.com/contest/1829/problem/B
输入t组数据。
每组数据输入n和长为n的数组a,0<=a[i]<=1。
找到最长的连续0
2. 思路分析
典
3. 代码实现
def solve():
n, = RI()
a = RILST()
f = [0] * n
if a[0] == 0:
f[0] = 1
for i in range(1, n):
if a[i] == 0:
f[i] = f[i - 1] + 1
print(max(f))
C. Mr. Perfectly Fine
链接: C. Mr. Perfectly Fine
1. 题目描述
https://codeforces.com/contest/1829/problem/C
输入t组数据。每组数据:
输入n。
接下来n行输入m和一个长为2的01串,代表阅读这本书需要m分钟,01串上的1代表给这个技能。
输入最少要几分钟可以获得2个不同技能。
2. 思路分析
由于只有01,一共4种情况,直接每种情况求最小即可
3. 代码实现
def solve():
n, = RI()
c = defaultdict(lambda: inf)
for _ in range(n):
m, s = RS()
m = int(m)
c[s] = min(c[s], m)
ans = min(c['11'], c['01'] + c['10'])
if ans < inf:
return print(ans)
print(-1)
D. Gold Rush
链接: D. Gold Rush
1. 题目描述
https://codeforces.com/contest/1829/problem/D
输入t表示t组数据,每组数据:
输入n,m。n表示你有初始n个金块堆成一堆。
每次操作你需要选一堆金块,分成两堆数量分别是x,y。满足x=2*y。
请问是否可以通过任意次操作得到一堆金块数量是m。
2. 思路分析
只有3的倍数才能继续操作,直接用dfs模拟,不需要记忆化
3. 代码实现
def solve():
n, m = RI()
if m == n:
return print('YES')
# @lru_cache(None) # 其实不需要记忆化
def ok(x):
if x == m:
return True
if x % 3 == 0:
return ok(x // 3) or ok(x // 3 * 2)
return False
if ok(n):
print('YES')
else:
print('NO')
E. The Lakes
链接: E. The Lakes
1. 题目描述
输入t组数据,每组数据:
输入n,m。
接下来输入n行,每行输入m个数,表示n×m的网格图g。
g[i][j]代表这个位置有深度为g[i][j]的水坑。水坑可以和上下左右四个相邻水坑相连。
问最大的一个连通坑的水体积。。
2. 思路分析
最大连通块点权
3. 代码实现
def solve():
m, n = RI()
g = []
for _ in range(m):
g.append(RILST())
def inside(x, y):
return 0 <= x < m and 0 <= y < n
def bfs(x, y):
s = g[x][y]
if not s:
return 0
g[x][y] = 0
q = deque([(x, y)])
while q:
x, y = q.popleft()
for dx, dy in DIRS:
a, b = x + dx, y + dy
if inside(a, b) and g[a][b]:
s += g[a][b]
g[a][b] = 0
q.append((a, b))
return s
print(max(bfs(i, j) for i in range(m) for j in range(n)))
F. Forever Winter
链接: F. Forever Winter
1. 题目描述
输入t代表t组数据,每组数据:
输入n,m代表图的点数和边数。
接下来输入m行代表边。
已知输入的图是雪花图,其中雪花图的定义是:
中间一个点有x条边,连接x个跳板点;对于每个跳板点,连接y条新边,y个新点。(x,y>1)
求输入图形的x和y
(建议去网站里看图)

2. 思路分析
记录每个点的度,只有最外层的点可以是1,中间点和跳板点的度可以相同,也可以不同。那么度只有2种或者3种。
若是3种,则中间点的度只出现1次。
若是2种,则中间点的度应该大。因为跳板点除了y还多连了一个中间点
3. 代码实现
def solve():
n, m = RI()
degree = [0] * n
for _ in range(m):
u, v = RI()
u -= 1
v -= 1
degree[u] += 1
degree[v] += 1
cnt = Counter(degree)
# print(cnt)
s = sorted([(k, v) for k, v in cnt.items()])
if len(s) == 3:
x, y = s[1][0], s[2][0]
if s[1][1] == 1:
x, y = y, x
x -= 1
print(y, x)
else:
x = y = s[1][0]
x -= 1
print(y, x)
G. Hits Different
链接: G. Hits Different
1. 题目描述
输入t组数据,每组数据:
输入一个n,代表击中的编号。
一些罐头按金字塔图(去看图)摆放:
第一行1个,第二行2个..编号按这个顺序从1开始递增,每个罐头的价值是编号的平方
你抛掷一个小球,仅会击中一个编号,叠在这个罐头以上的罐头都会摔落,问摔落的总价值
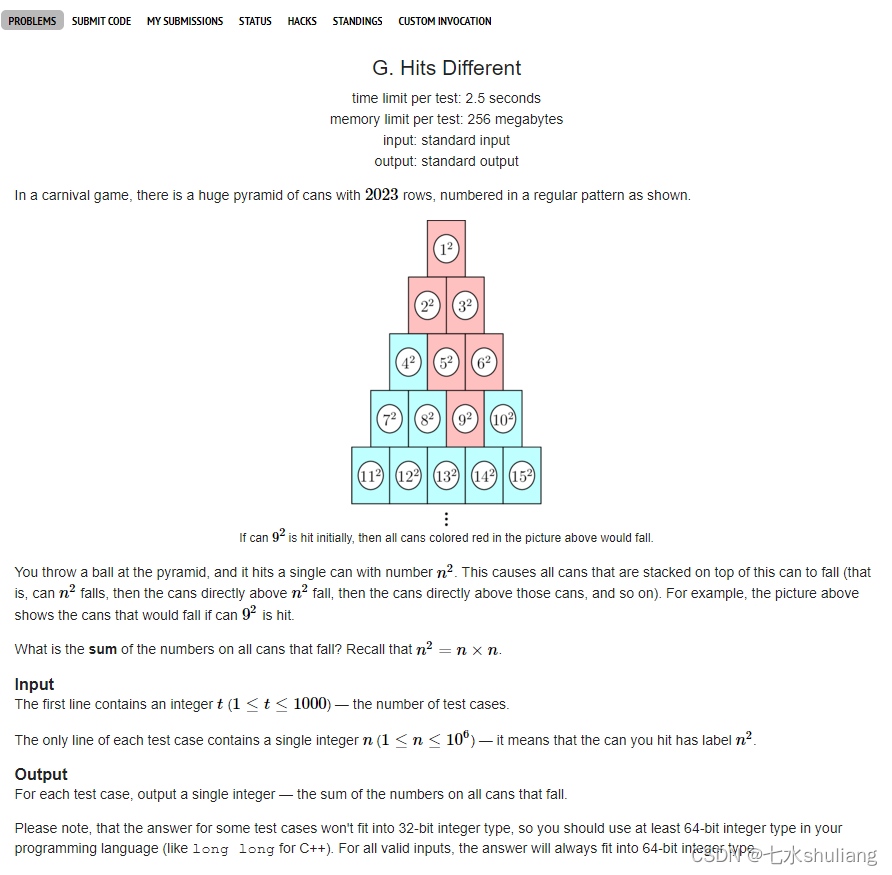
2. 思路分析
用dp预处理,然后查表。
- 首先按二维建图。
- f[i][j]为第i行第j个罐头的摔落值。
- 发现每个罐头的摔落值等于自己加上前一排的右侧值和左侧那一竖排。
- 那么令g[i][j]等于每个罐头的竖排求和,则可以递推。
- 由于是按编号查询的,因此构造一个ans下标等于编号。
3. 代码实现
NN = 2023
# a = [[0]*2023 for _ in range(NN)]
f = [[0] * 2023 for _ in range(NN)]
g = [[0] * 2023 for _ in range(NN)]
ans = [0]
x = 1
for i in range(NN):
for j in range(i + 1):
# a[i][j] = x*x
f[i][j] = x * x
g[i][j] = x * x
if i:
f[i][j] += f[i - 1][j]
if j:
f[i][j] += g[i - 1][j - 1]
g[i][j] += g[i - 1][j - 1]
x += 1
ans.append(f[i][j])
# ms
def solve():
n, = RI()
print(ans[n])
if __name__ == '__main__':
t, = RI()
for _ in range(t):
solve()
H. Don’t Blame Me
链接: H. Don’t Blame Me
1. 题目描述
输入t组数据,每组数据
输入n,k和一个长度为n的数据a。(0<=a[i]<=63)
问a中有多少个子序列,他们的位于结果里,有k个1。
2. 思路分析
看起来可以背包,但是查表法有些麻烦,由于a[i]范围64,可以刷表法,直接尝试所有转移。
3. 代码实现
def solve():
n, k = RI()
a = RILST()
f = [0] * 64
for v in a:
g = f[:]
f[v] += 1
for i, x in enumerate(g):
f[v & i] += x
f[v & i] %= MOD
ans = 0
for i, v in enumerate(f):
if bin(i).count('1') == k:
ans = (ans + v) % MOD
print(ans % MOD)