基于本人观看学习 哈工大李治军老师主讲的操作系统课程 所做的笔记,仅进行交流分享。
特此鸣谢李治军老师,操作系统的神作!
如果本篇笔记帮助到了你,还请点赞 关注 支持一下 ♡>𖥦<)!!
主页专栏有更多,如有疑问欢迎大家指正讨论,共同进步!
给大家跳段街舞感谢支持!ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ ዽ ጿ ኈ ቼ
内存管理 目录
- 第三章 内存管理
- 课程链接:
- 一、内存使用与分段
- 1.重定位
- 进程交换
- 2.分段
- 二、内存分区与分页
- 1.内存如何分区?
- 2.分页
- 三、多级页表与快表
- 1.多级页表
- 四、段页结合的实际内存管理
- 段 面向用户,页 面向硬件
- 段、页同时存在的重定位(地址翻译)
- 代码实现:
- 五、内存换入—请求调页
- 代码实现
- 六、内存换出
- 1.FIFO页面置换
- 2.MIN页面置换
- 3.LRU页面置换
- 代码实现:
- 内存换入和换出总结
第三章 内存管理
更多操作系统笔记:【哈工大李治军老师】操作系统
课程链接:
b站: 【哈工大】操作系统 李治军(全32讲)
大学MOOC:大学慕课—操作系统—主讲:哈工大李治军
一、内存使用与分段
程序进入内存,main函数的40地址必须放在物理内存地址
call40要求main放在真实的物理地址:40,程序从0地址开始,让PC等于0开始取指执行

如果另一个程序要运行,也从0地址开始,就会和上面的程序冲突
因此程序应该放在内存中空闲的单元

此时40(逻辑地址)需要修改到1040(物理地址)处,否则内存无法使用
1.重定位
重定位:修改程序中的地址(相对地址)
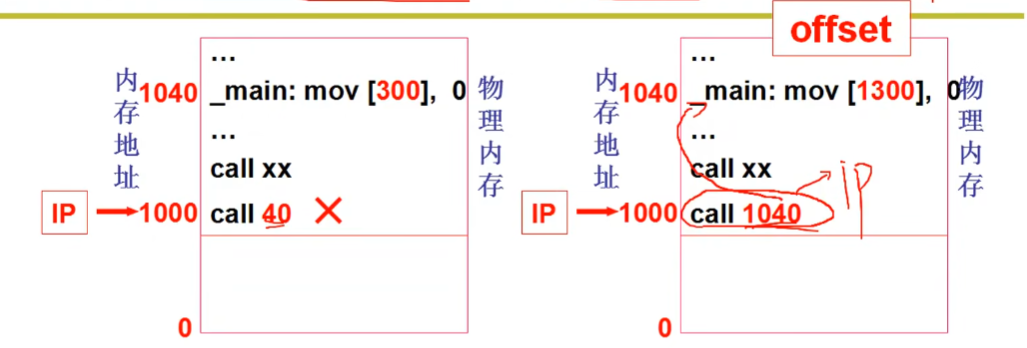
什么时候进行重定位?
编译时
编译时内存重定位是程序代码在编译为目标代码的过程中,跳转地址被绑定到一个固定的地址上。因此,生成的目标文件可以直接载入内存中执行,不需要进行额外的重定位。
编译时内存重定位适合静态编译的程序 编译时重定位的程序只能放在内存固定位置
载入时
载入时内存重定位是程序在载入内存后,操作系统会将程序的可执行代码、全局变量、动态链接库等资源加载到内存中,并进行地址的映射和调整。在编译期间无需考虑代码的实际内存布局,程序非常灵活
载入时内存重定位适合动态链接的程序,载入时重定位的程序一旦载入内存就不能动了
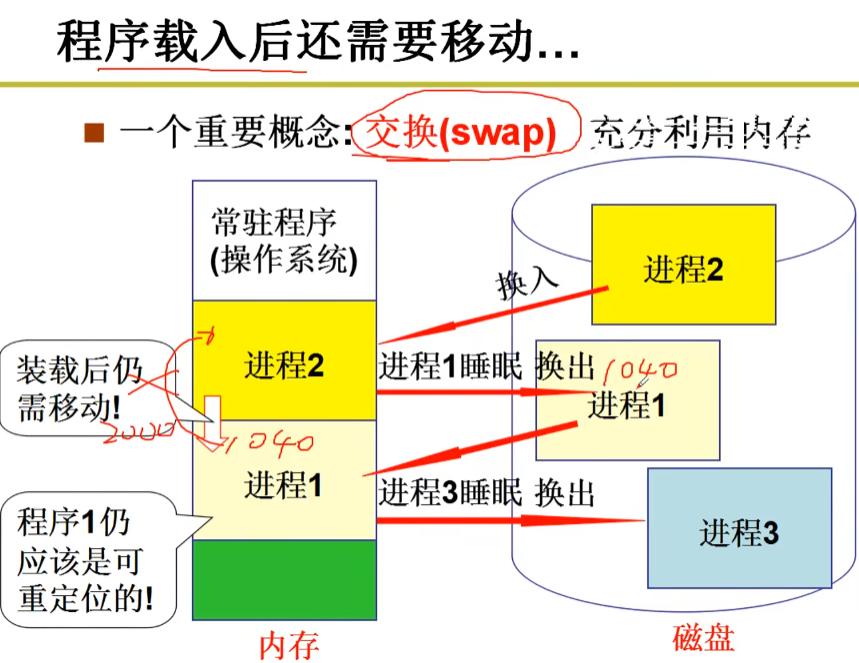
进程交换
当物理内存不足以满足当前所有正在运行的进程的需求时,操作系统就会将一些运行态进程暂停并将其内存交换到磁盘上,释放出一部分空间来容纳新的进程
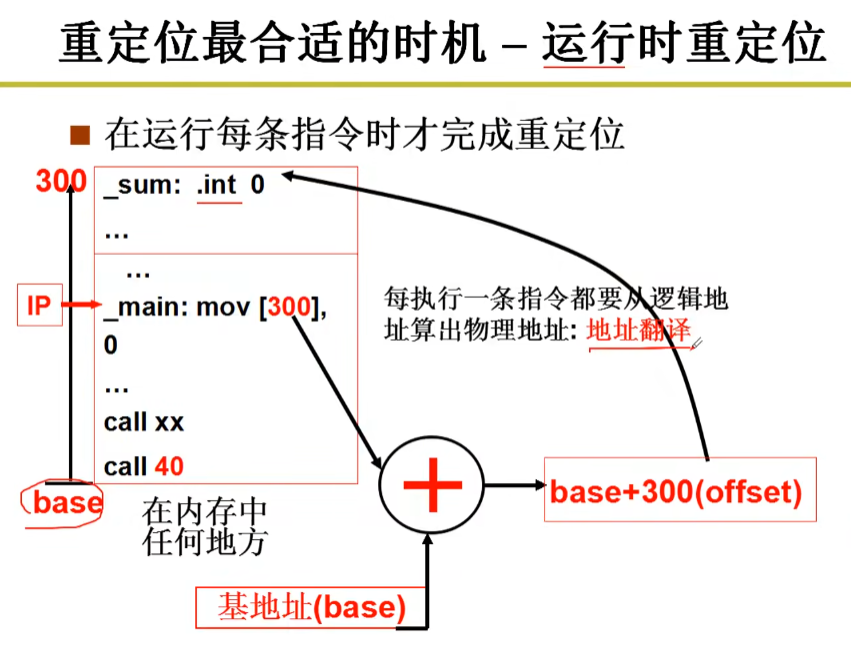
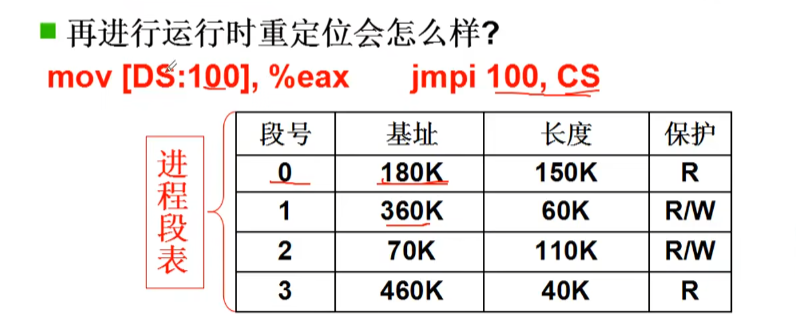
重定位最合适的时机:运行时重定位
无论程序放在哪里,在程序运行时,都可以根据逻辑地址40通过地址翻译算出物理地址。
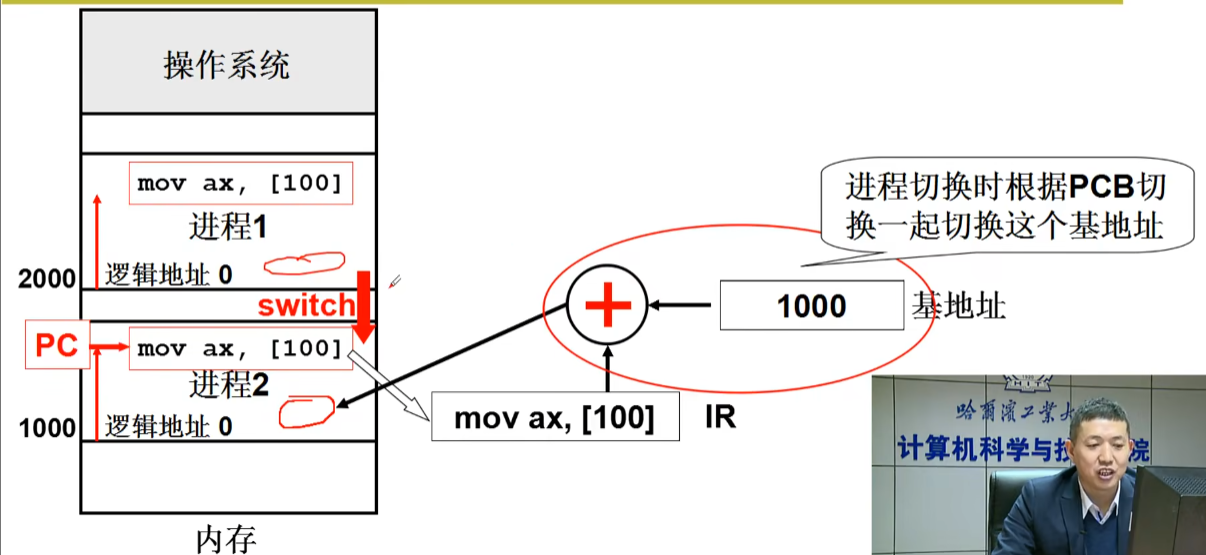
base放在PCB中,执行指令时第一步先从PCB中取出这个基地址
真实物理地址=基地址(起始地址)+偏移(逻辑地址)
进程切换时根据PCB切换一起切换这个基地址
2.分段
程序由代码段组成:
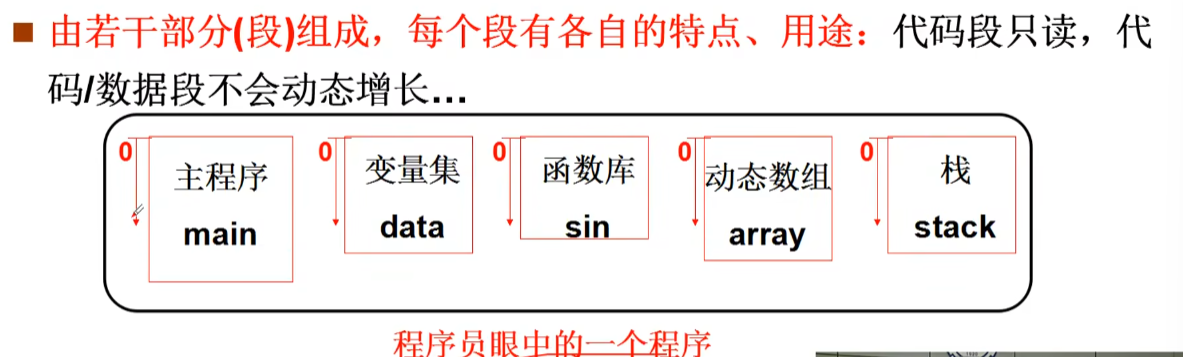
符合用户观点:用户可独立考虑每个段 (分治)
怎么定位具体指令(数据): <段号,段内偏移> 如mov [es:bx],ax
程序的各段分别放入内存:
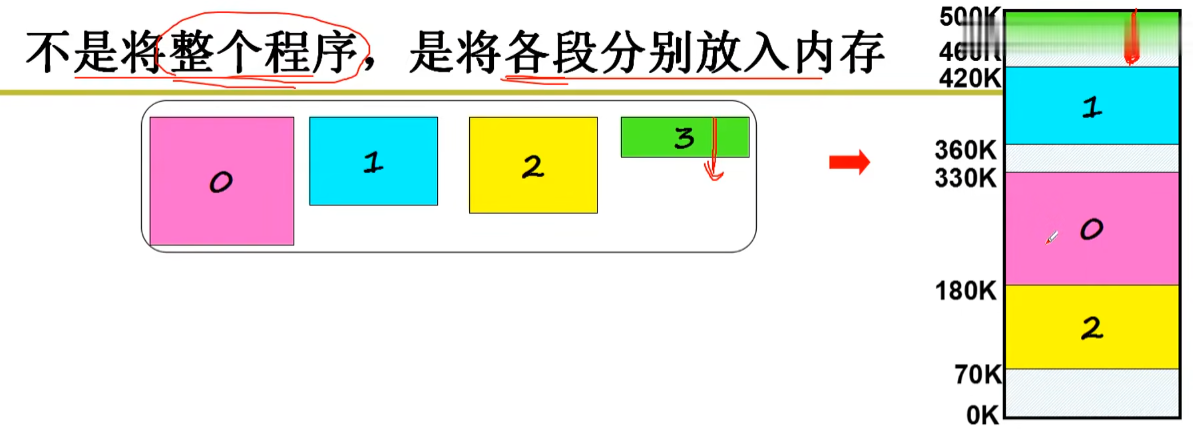
现在的PCB需要放每个段的基址
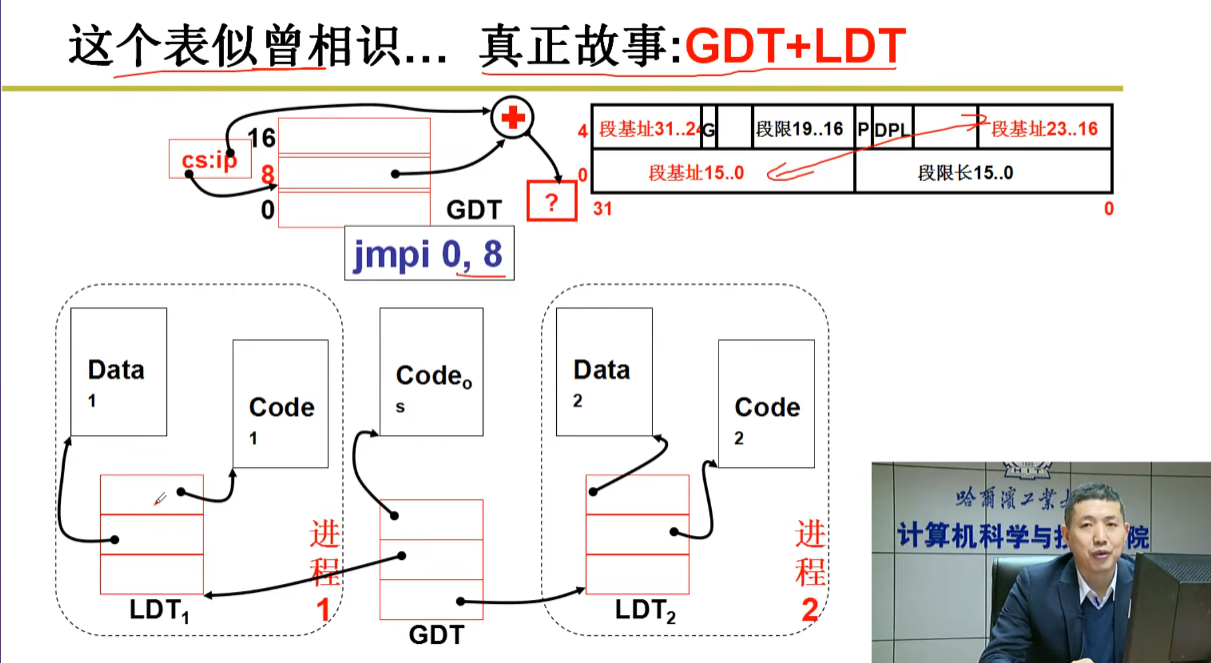
GDT是操作系统的段表 每个进程有自己的LDT表
二、内存分区与分页
程序分段->找空闲分区->通过映射表读写
1.内存如何分区?
固定分区 与 可变分区
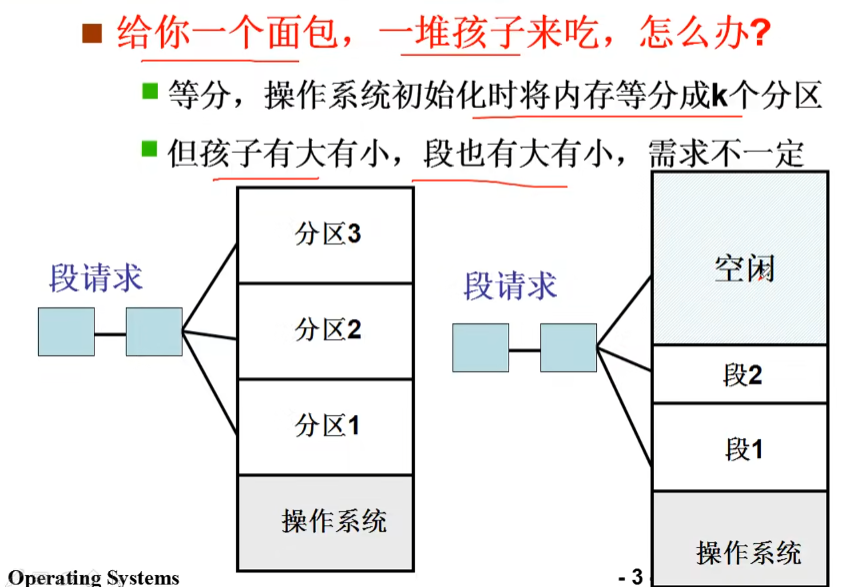
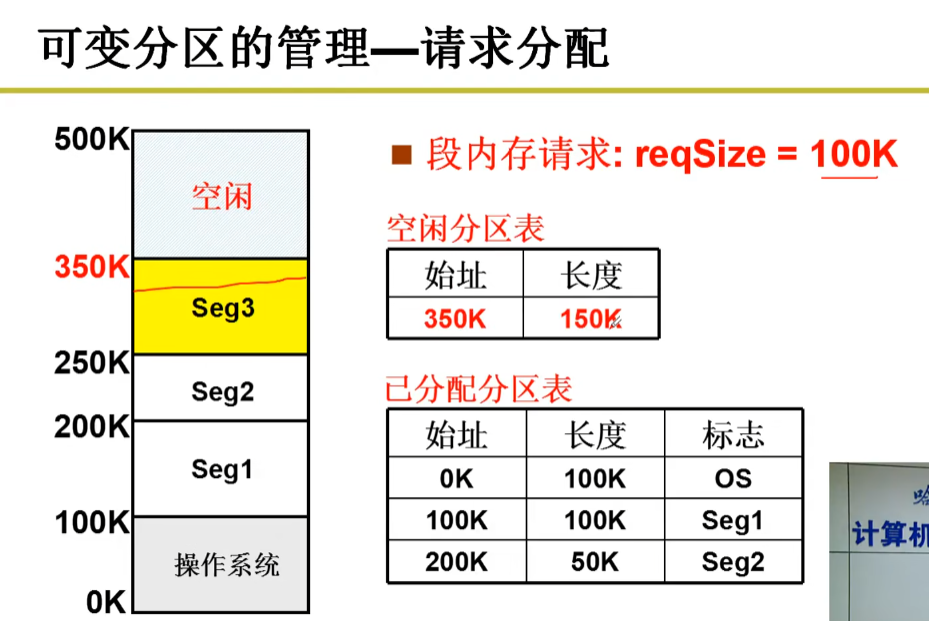
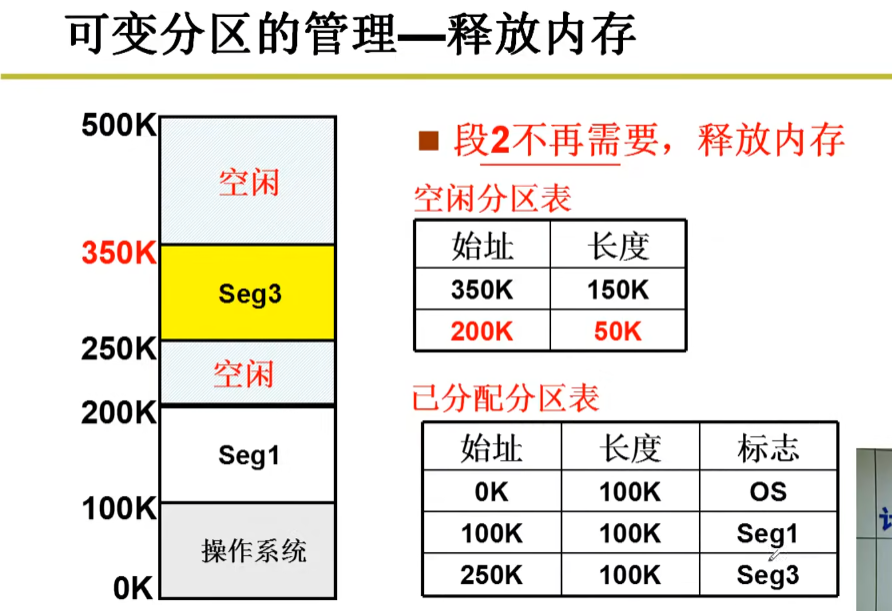
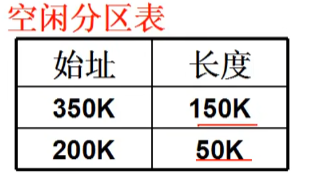
又一个段提出内存请求:reqSize=40K,怎么办?
目前的空闲分区:
首先适配:选择第一个大小足够的空闲区域进行分配 (350,150)
首先适配简单快速,但会留下许多无法使用的小碎片
最佳适配:选择尺寸最小、且足够容纳当前申请内存的空闲区域进行分配 (200,50)
最佳适配可以避免产生过多的碎片,但需要搜索所有空闲区域,效率相对较低
最差适配:选择尺寸最大、且足够容纳当前申请内存的空闲区域进行分配 (350,150)
差适配可以减少碎片的数量,但占用大内存空间,浪费大量空间

2.分页
内存分区会产生内存碎片 导致有内存使用不了
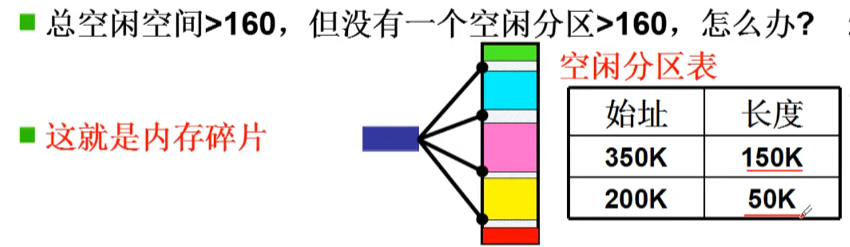
将空闲分区合并,需要移动1个段(复制内容):内存紧缩 花费时间长
从连续到离散…
不用进行内存紧缩,内存浪费少

页表重定位:
将所有指向旧物理地址的虚拟页面地址替换为对应的新物理页面地址,这样虚拟地址就能够正确映射到新的物理页面上

三、多级页表与快表
分页如果过大会造成浪费,为了提高内存空间利用率,页应该小
但是页小了页表就大了

大部分逻辑地址用不到,我们可以将他从页表中删除,只存放用到的页
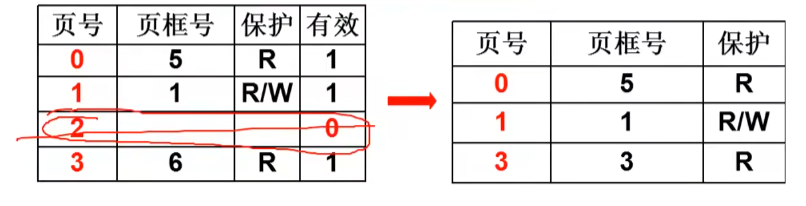
但是这种方法,会导致页表中的页号不连续
执行指令进入页表查找,额外访问内存,速度会慢
因此页表一定要连续(通过偏移直接查找),大页表占用内存,造成浪费
如何做到既连续,又要让页表占用内存少?
1.多级页表
用书的章目录和节目录来类比思考:先找章、再找节
多级页表,即页目录表(章)+页表 (节)
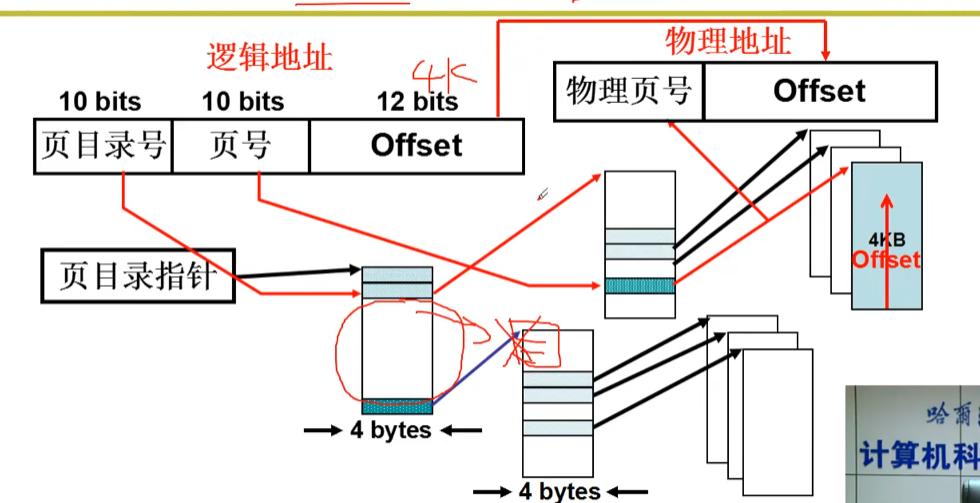
2^10个目录项 * 4字节地址 =4K,总共需要16K远远小于4M
多级页表提高了空间效率,但在时间上又出现问题:每增加一级就要多访问一次内存
类比看书的书签,最近看到了哪里,使用快表来弥补:
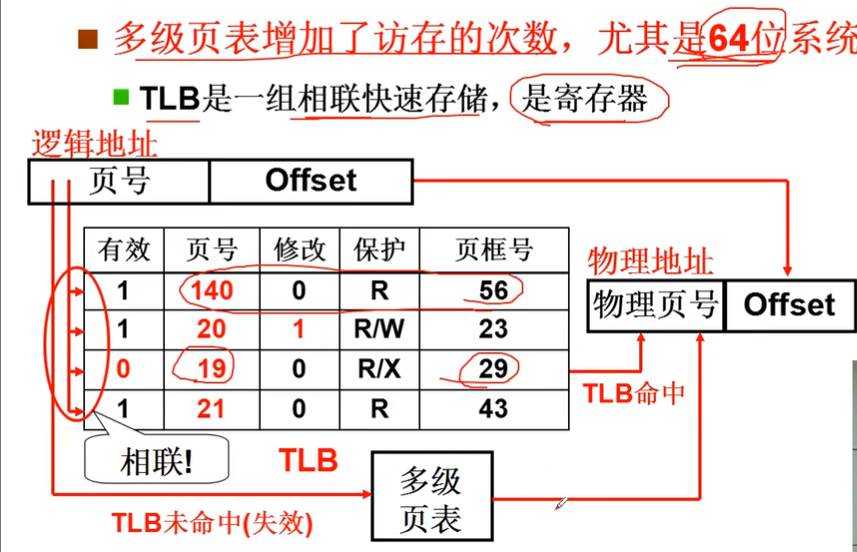
将最近访问的物理页放在快表中。
快表和多级页表组合在一起的结构保证了多级页表的连续,查找起来也比较快

关键:增大快表 提高命中率
TLB有效的原因: 程序的地址访问具有局部性:
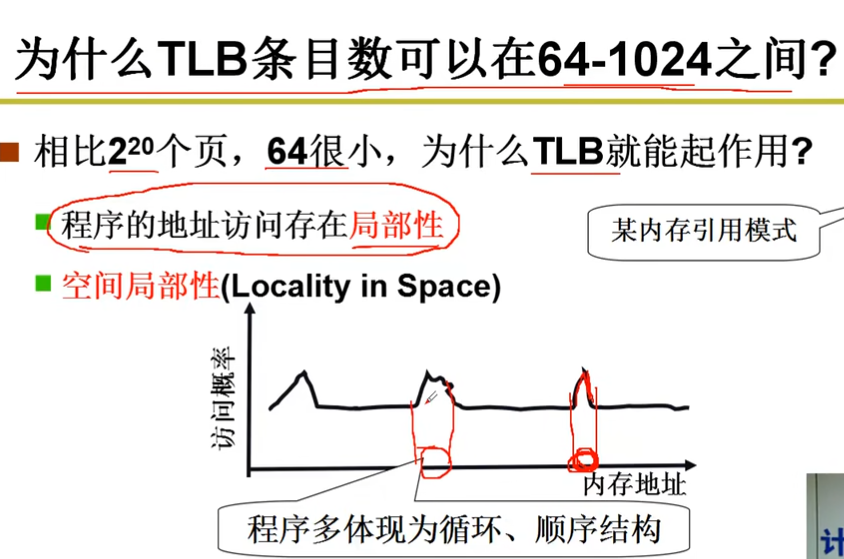
四、段页结合的实际内存管理
将段和页结合在一起
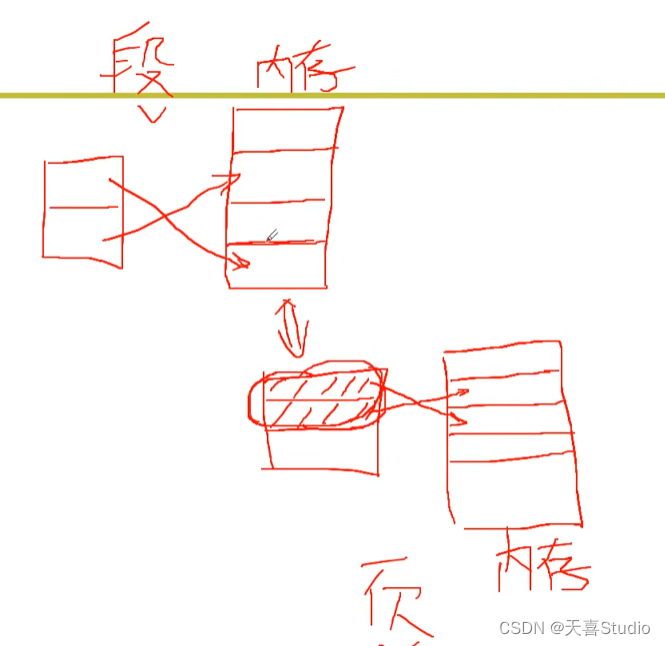
段页结合的虚拟内存管理方式是将物理内存划分为大小相等的页框,并将逻辑地址划分为段和页两部分
段号用来确定逻辑地址所在的段,页号用于确定段中具体某一页。
通过段号查找符号表可以得到该段的基地址,加上页号后即可找到该页在物理内存中的对应位置,从而完成地址映射。
段 面向用户,页 面向硬件
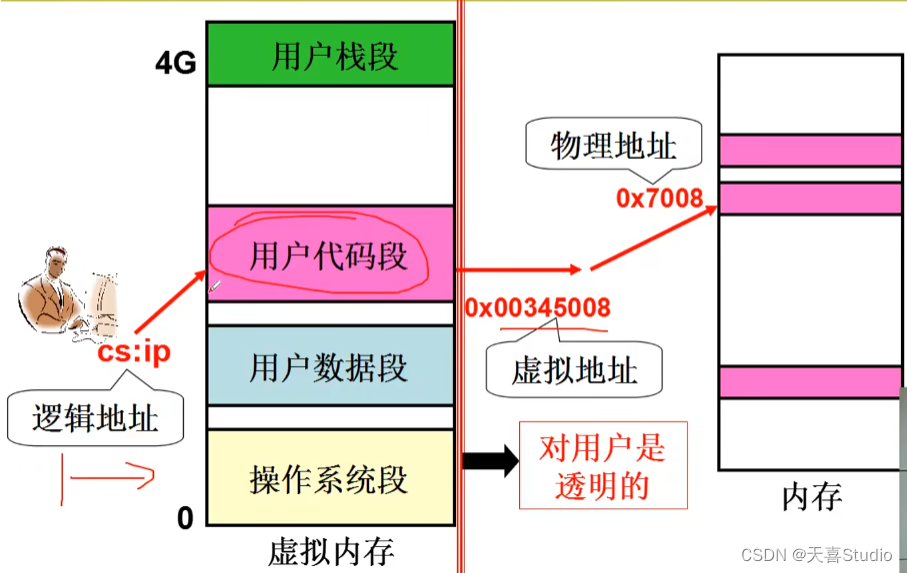
虚拟内存:应用程序运行所需要的内存量大于物理内存容量,实现了内存的动态扩展与管理。虚拟内存将进程中的地址空间分为若干个虚拟页面,每个页都可以被映射到物理内存上的一个对应的物理页面
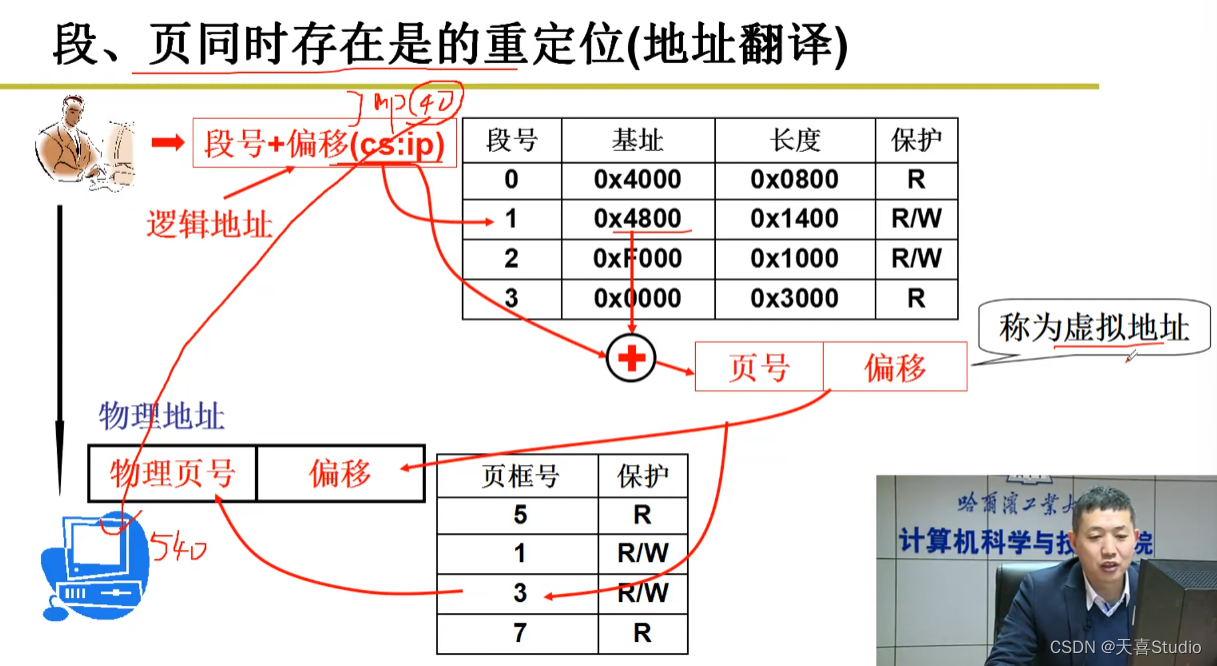
段、页同时存在的重定位(地址翻译)
从逻辑地址到虚拟地址,再从虚拟地址到物理地址
先根据段表的基址加偏移得到虚拟地址
再根据页号加偏移得到物理地址
代码实现:
分配段、建段表;分配页、建页表
进程带动内存使用的图谱
从进程fork中的内存分配开始…



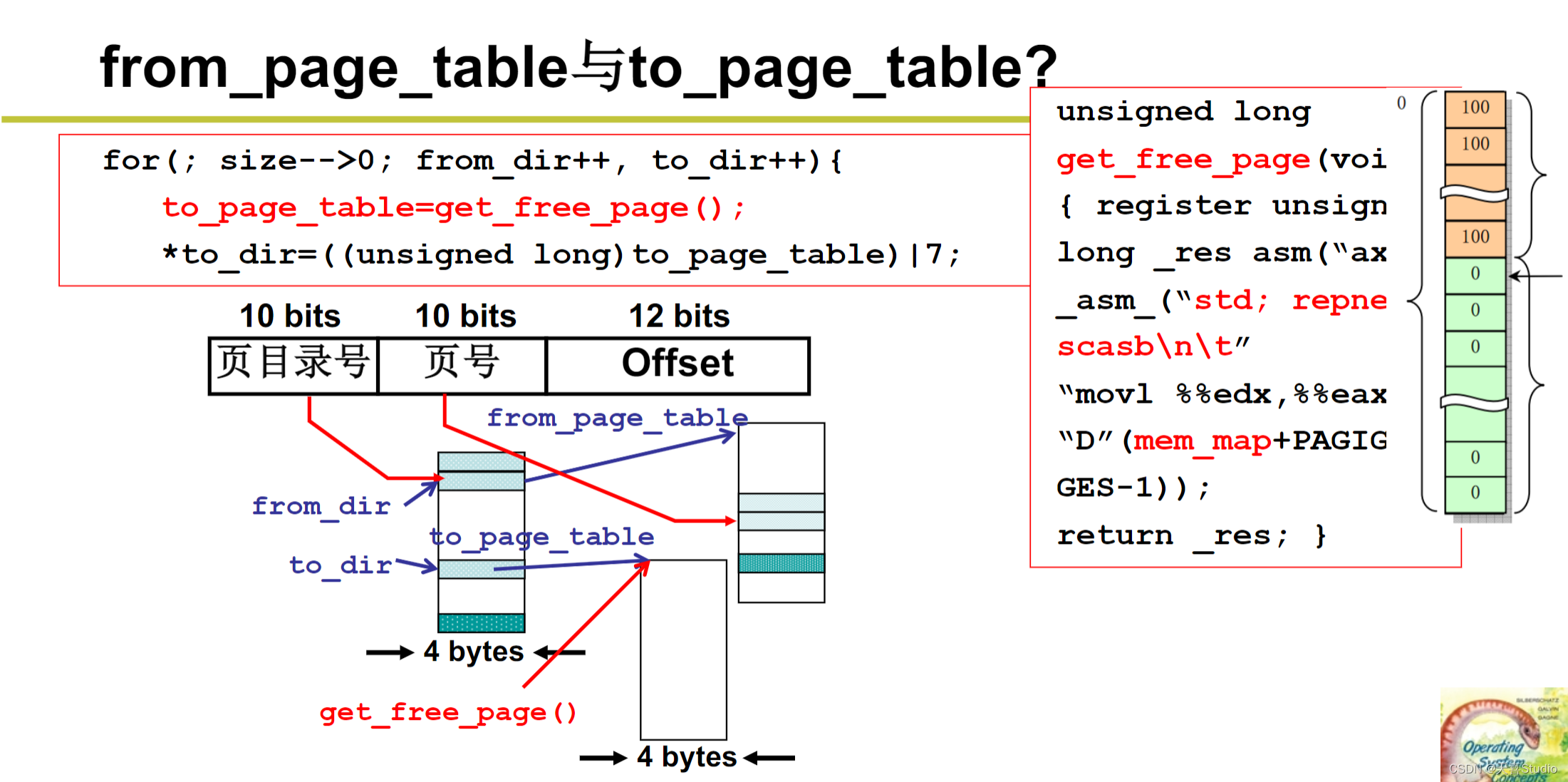
经过两大项工作后,父进程和子进程都创建了自己的段表、虚拟内存、页表。一个程序就被放在了内存中:
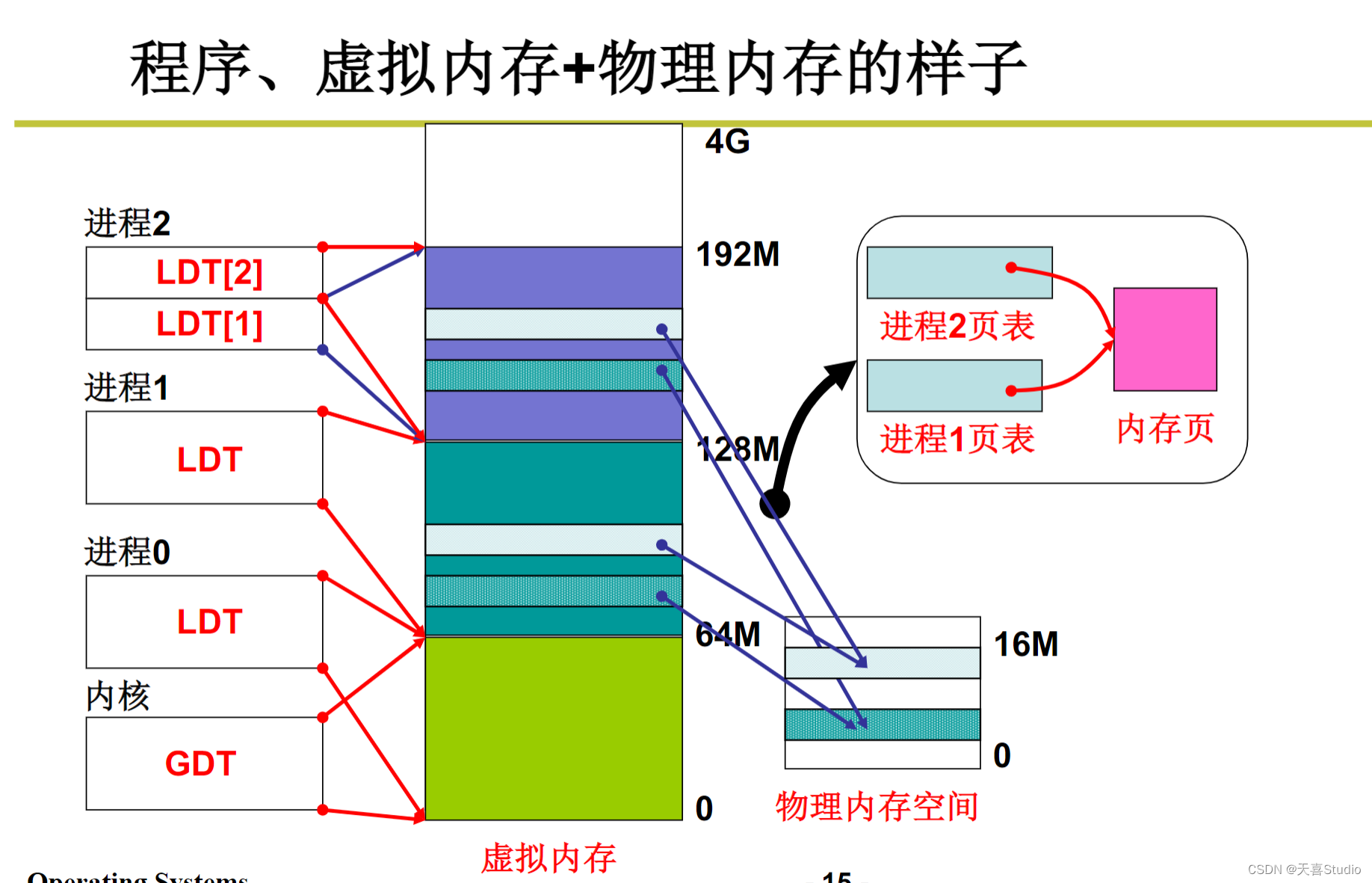
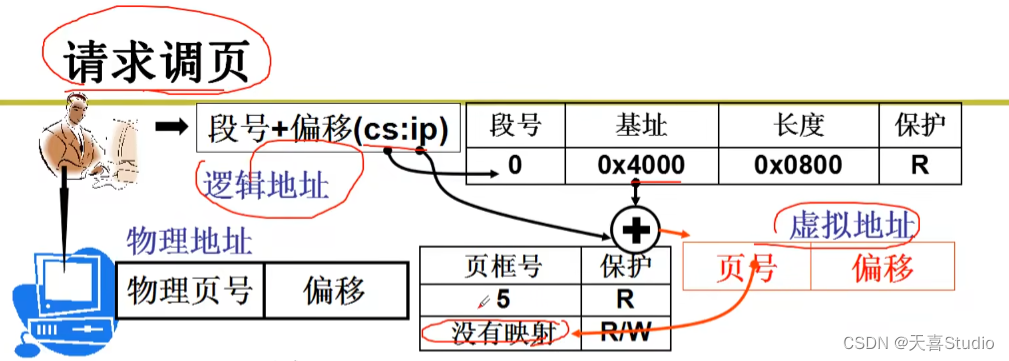
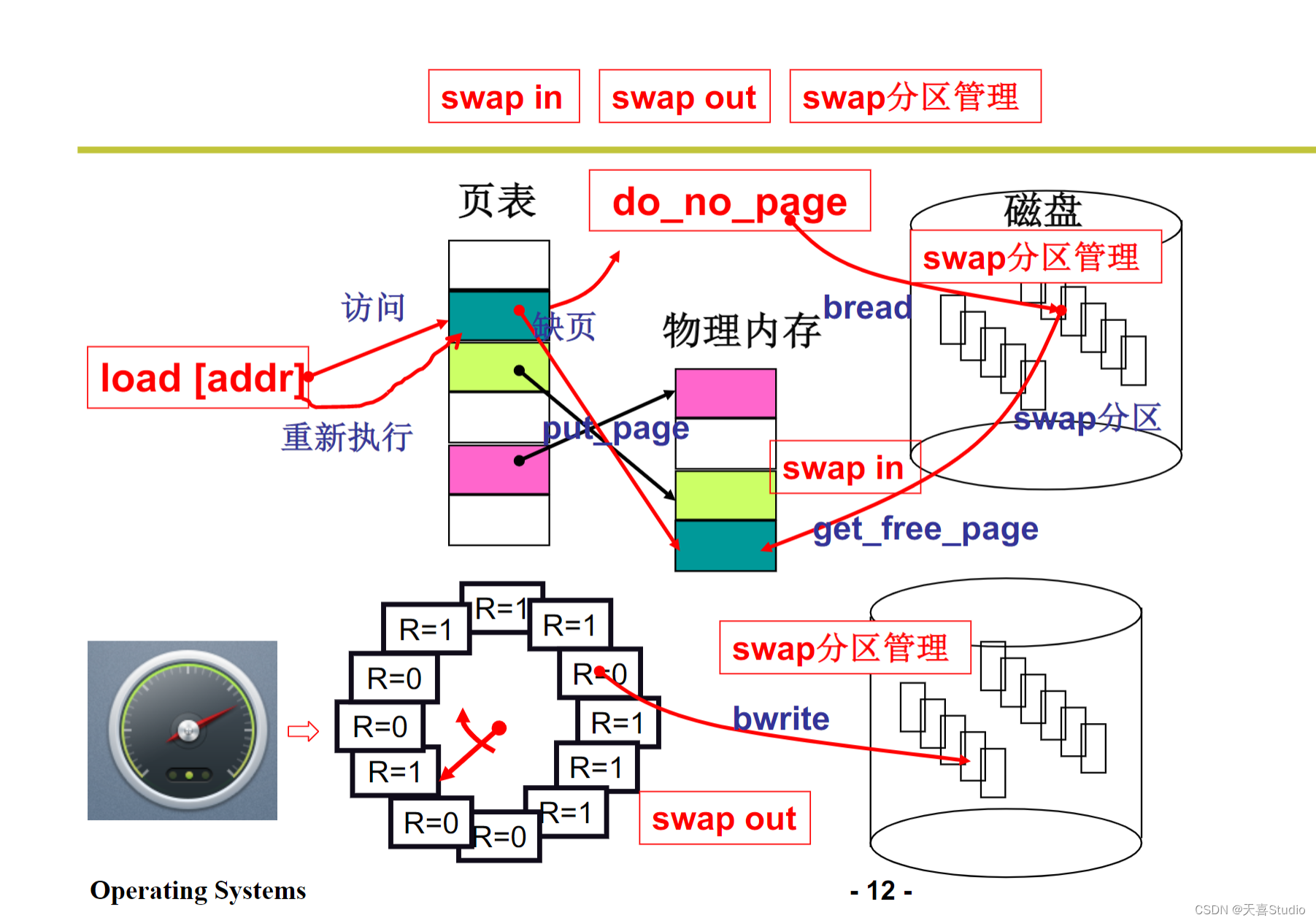
五、内存换入—请求调页
为了实现虚拟内存,引出了换入换出机制
用户眼中的内存:
4GB(大且规整)的“内存”,可供用户使用,如char*p,p=3G,实际上就是用地址
用户可随意使用该“内存”,就象单独拥有4G内存
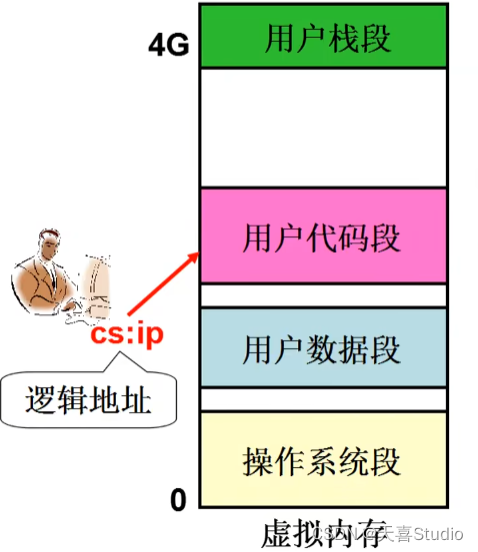
这个“内存”怎么映射到物理内存,用户全然不知
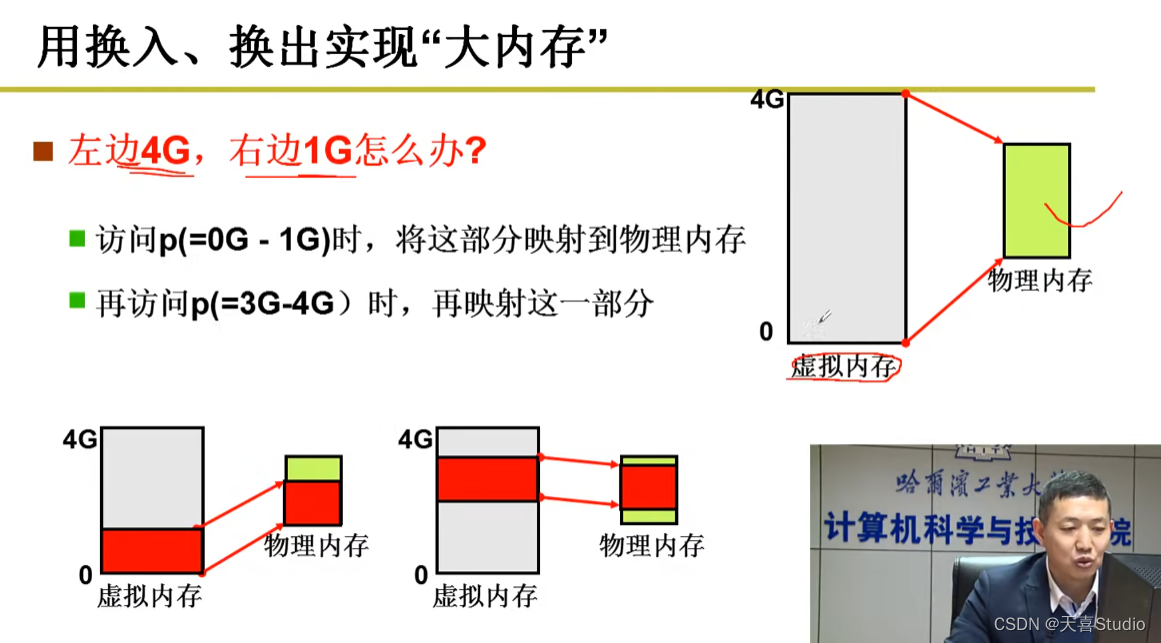
由于程序的不连续,读取哪一段数据,哪一段就换入cpu中,用完了从cpu换出
请求的时候才映射!
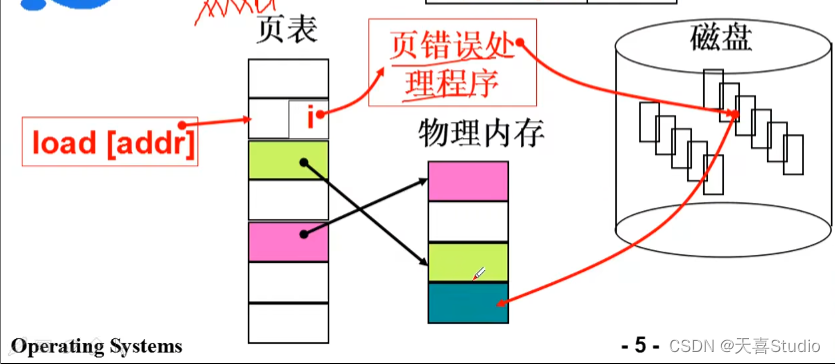
如果出现缺页,就会产生中断,进行中断处理程序
PC指针不动,映射之后在执行本条指令
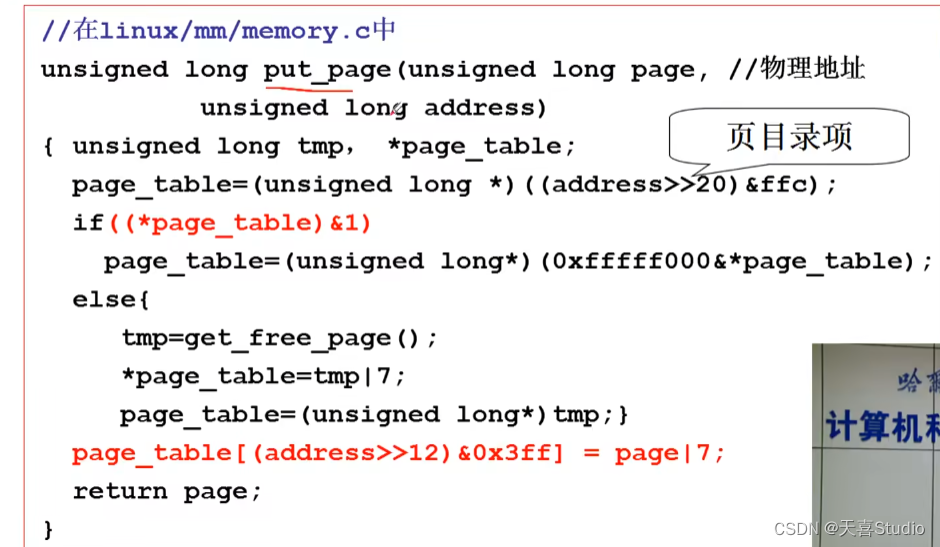
代码实现

处理中断page fault:

do_no_page:

put_page:
六、内存换出
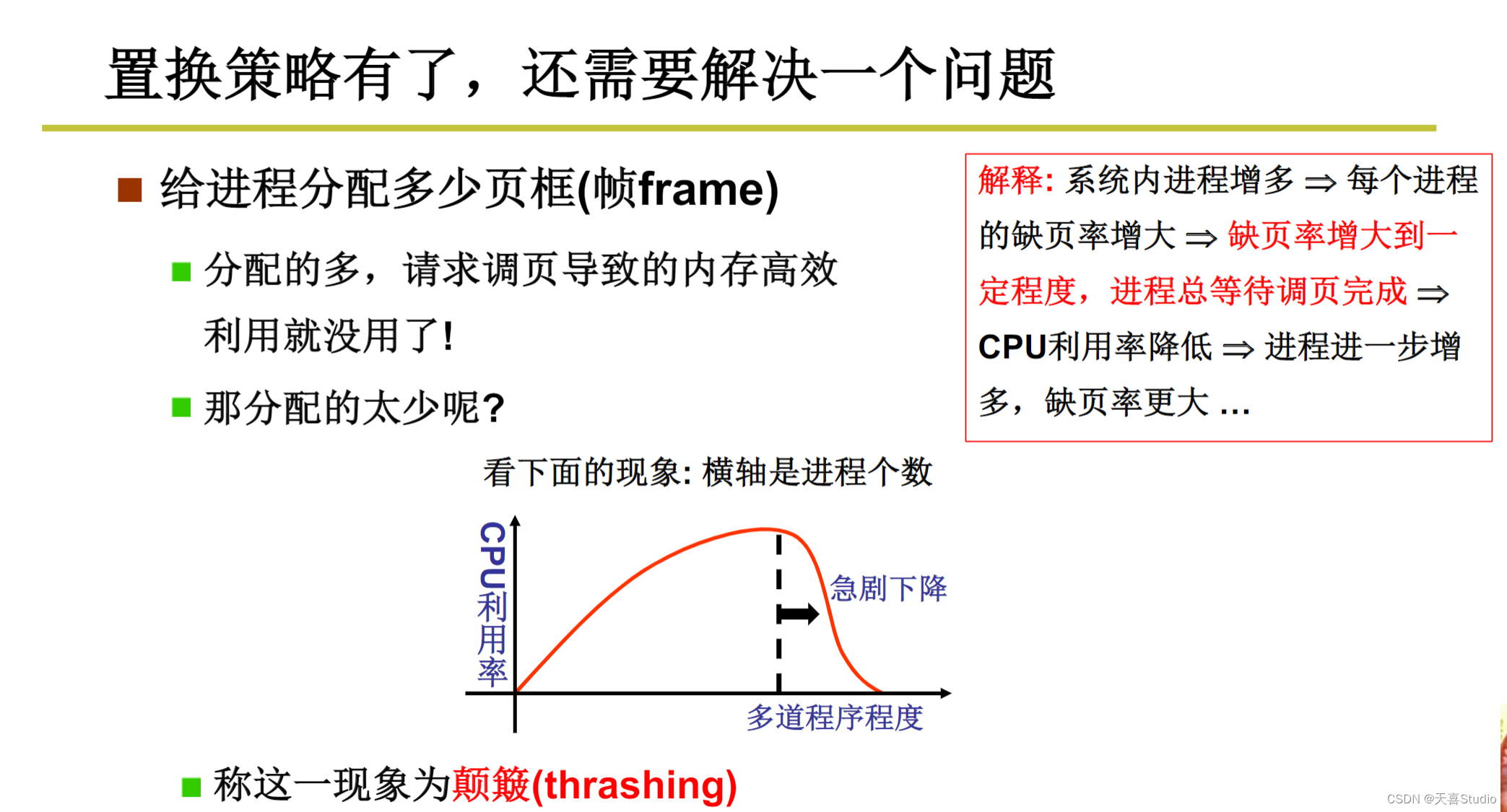
并不能总是获得新的页,内存是有限的
需要选择一页淘汰,换出到磁盘,选择哪一页?

1.FIFO页面置换
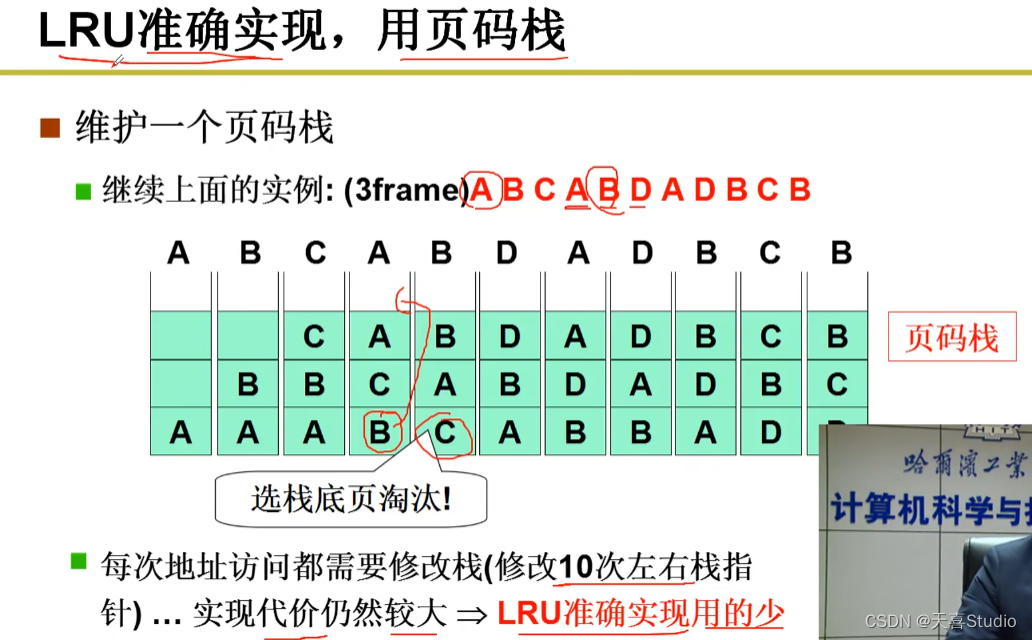
一实例:分配了3个页框(frame),页面引用序列为
A B C A B D A D B C B
当D到达,页框没有位置了,A最先换入,第一个换出
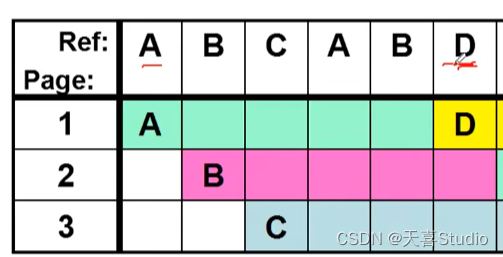
以此类推:
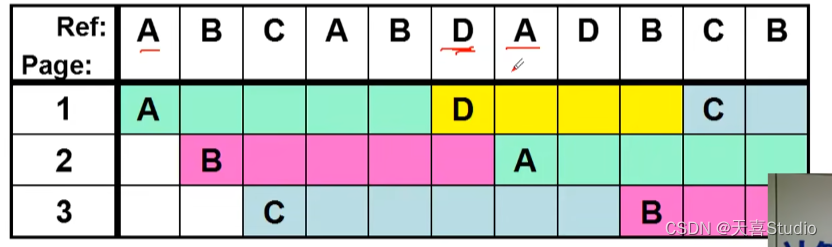
评价准则:缺页次数:本实例,FIFO导致7次缺页
A刚换出下一次又被换入,C用的最少,换出C最合适
2.MIN页面置换
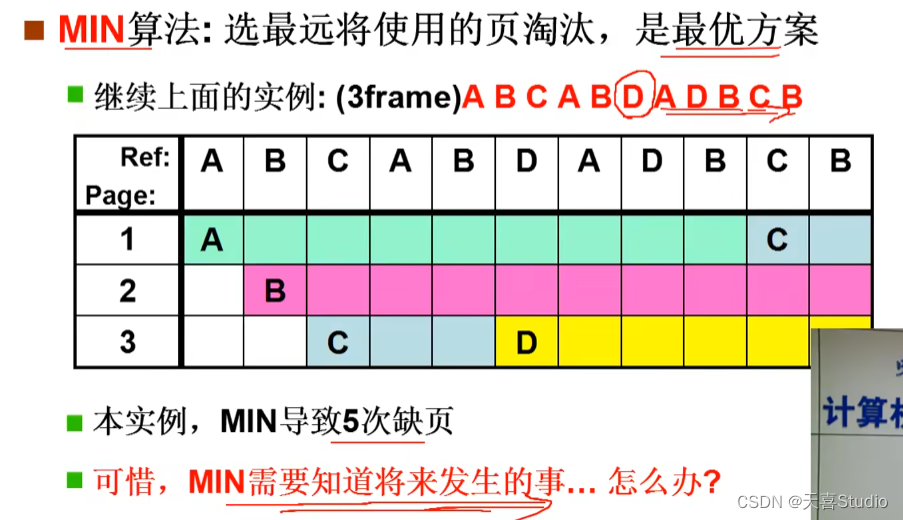
理论上本算法合适,但是无法预测将来的事
3.LRU页面置换
用过去的历史预测将来 局部性
LRU算法: 选最近最长一段时间没有使用的页淘汰(最近最少使用)。
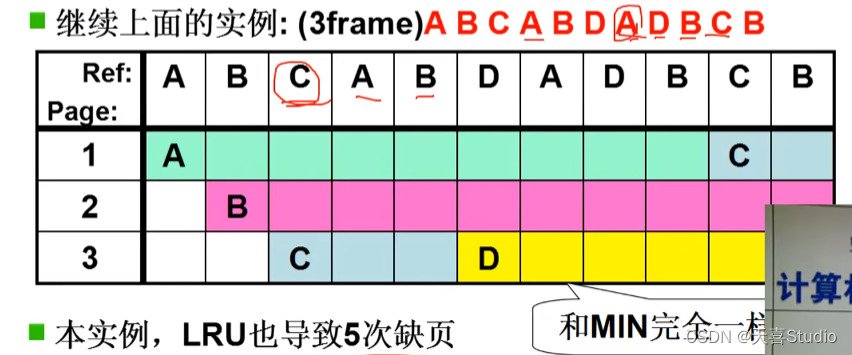
代码实现:
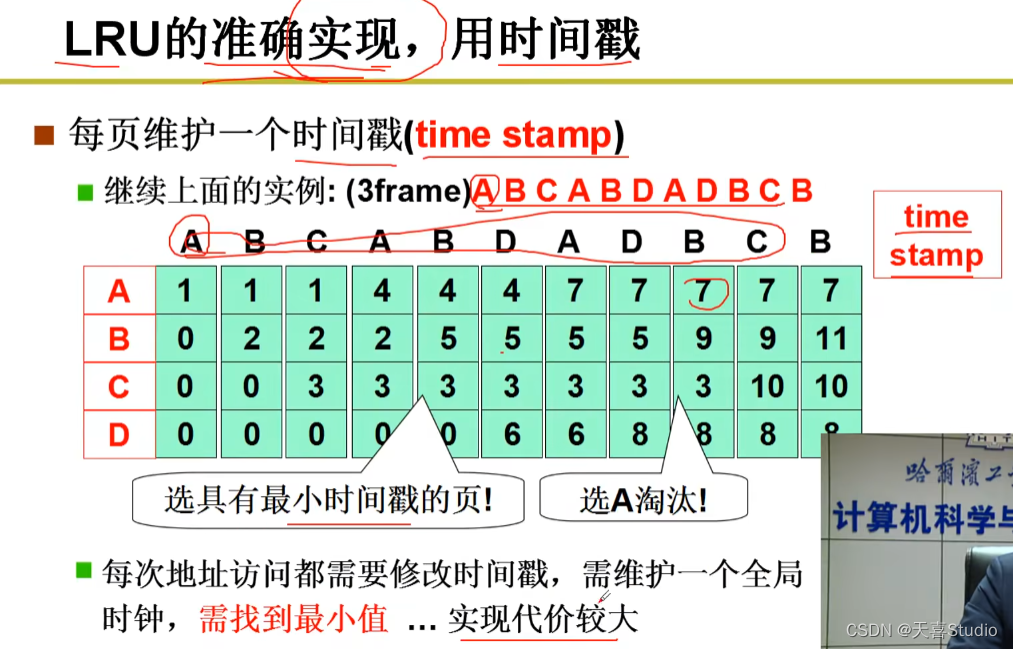
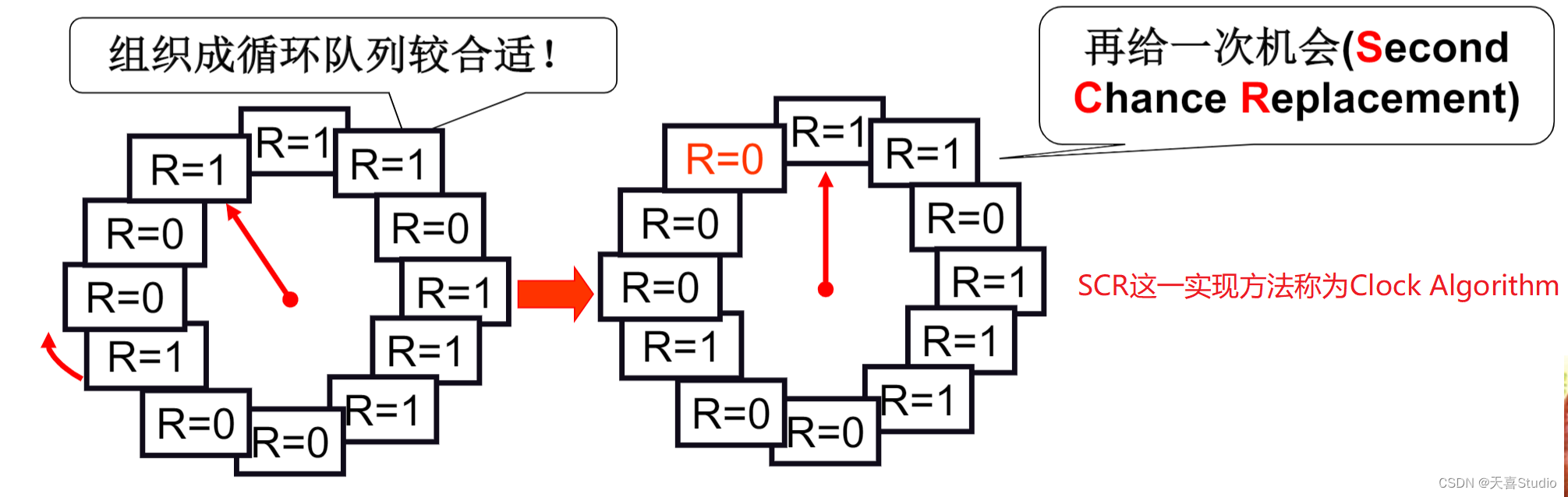
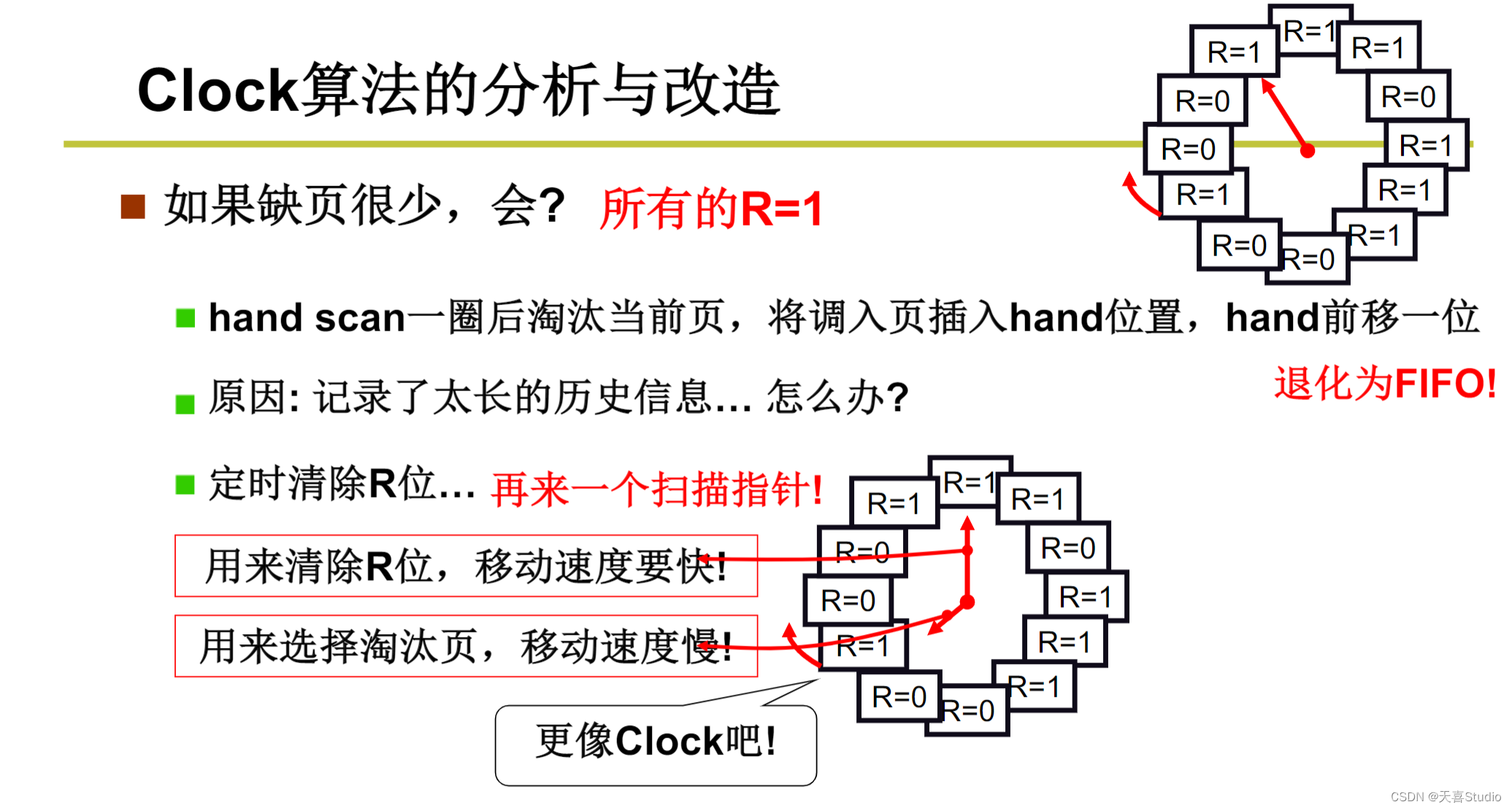
LRU近似实现一将时间计数变为是和否
每个页加一个引用位(reference bit)
每次访问一页时,硬件自动设置该位
选择淘汰页:扫描该位,是1时清0,并继续扫描;是0时淘汰该页
内存换入和换出总结
更多操作系统笔记:【哈工大李治军老师】操作系统笔记专栏汇总
| 大家的点赞、收藏、关注将是我更新的最大动力! 欢迎留言或私信建议或问题。 |
| 大家的支持和反馈对我来说意义重大,我会继续不断努力提供有价值的内容! |