使用Quickwit、Jaeger和Grafana监控您的Rust应用程序
你可能已经看过了Lucas Palmieri的博客文章Are we observable yet? An introduction to Rust telemetry。如果你还没有看过,我们建议阅读一下,因为它提供了一个全面的介绍,介绍了如何处理 Rust 代码中的日志。
然而,仅仅记录日志可能是不够的,特别是在分布式架构中。在 Quickwit 中,我们经常使用跟踪来理解性能瓶颈并提高速度。当我们遇到 Quickwit 的搜索响应缓慢时,我们经常会问自己:是什么导致了减速?是网络相关的问题,磁盘 I/O 还是过多的 CPU 使用?
在本博客文章中,我们将展示如何为 Rust 应用程序进行测量,并生成跟踪数据,从 DevOps 视角利用它们。我们的目标将是双重的:
使用广泛认可的 Jaeger UI 分析跟踪,以获取有关应用程序行为的见解。
从这些跟踪数据中派生 RED(速率、错误和持续时间)指标,并在 Grafana 中监视它们。如果您想进一步了解,我们建议参考以下资源:Weaveworks 的 RED 方法和 Google SRE 书籍中有关监控分布式系统的部分。
现在,让我们深入介绍步骤,其中我们将涵盖以下关键方面:
为使用 Actix 构建的简单 Web API 进行测量。
将您的跟踪和指标数据推送到 Quickwit。
在 Jaeger UI 中检测、诊断和解决问题。
在 Grafana 中监视您的应用程序的 RED 指标(速率、错误、持续时间)。
在深入了解之前,请确保您的系统上已安装并正确运行以下软件:
Rust 1.68+Docker如果您仍在运行旧版本的 Docker,则需要安装
docker-compose。
构建并测量 Rust 应用
我们将使用 Actix Web 框架创建一个基本的 Rust 应用程序。这个应用程序是一个包含单个端点的 Web API。它将从受欢迎的 JSONPlaceholder 公共 Web API 获取帖子及其评论,并将它们显示为 JSON。为了更好地了解我们的应用程序生命周期并可能优化它,我们将确保测量以下例程:
从 /posts 获取帖子。
获取每个帖子的评论 /posts/1/comments
创建一个名为 rust-app-tracing 的新目录。在终端中切换到该目录,并运行以下命令初始化一个新的 Rust 项目。
cargo new web-api让我们还要确保在 web-api/Cargo.toml 文件中拥有所需的依赖项。
actix-web:用于在 Rust 中构建 Web 应用程序的快速 Web 框架。actix-web-opentelemetry:actix-web框架的 open-telemetry 扩展。opentelemetry:Rust 的核心 open-telemetry SDK,包括跟踪和指标。opentelemetry-otlp:提供各种 open-telemetry 导出器的 crate。reqwest:提供一个直观的 API 来进行 HTTP 请求。tokio:为我们的应用程序提供异步运行时。
Web API 应用程序代码
首先,让我们通过创建一个名为 telemetry.rs 的文件来配置应用程序跟踪,我们将在其中处理所有跟踪配置。
// telemetry.rs
...
const SERVICE_NAME: &'static str = "quickwit-jaeger-demo";
pub fn init_telemetry(exporter_endpoint: &str) {
// Create a gRPC exporter
let exporter = opentelemetry_otlp::new_exporter()
.tonic()
.with_endpoint(exporter_endpoint);
// Define a tracer
let tracer = opentelemetry_otlp::new_pipeline()
.tracing()
.with_exporter(exporter)
.with_trace_config(
trace::config().with_resource(Resource::new(vec![KeyValue::new(
opentelemetry_semantic_conventions::resource::SERVICE_NAME,
SERVICE_NAME.to_string(),
)])),
)
.install_batch(opentelemetry::runtime::Tokio)
.expect("Error: Failed to initialize the tracer.");
// Define a subscriber.
let subscriber = Registry::default();
// Level filter layer to filter traces based on level (trace, debug, info, warn, error).
let level_filter_layer = EnvFilter::try_from_default_env().unwrap_or(EnvFilter::new("INFO"));
// Layer for adding our configured tracer.
let tracing_layer = tracing_opentelemetry::layer().with_tracer(tracer);
// Layer for printing spans to stdout
let formatting_layer = BunyanFormattingLayer::new(
SERVICE_NAME.to_string(),
std::io::stdout,
);
global::set_text_map_propagator(TraceContextPropagator::new());
subscriber
.with(level_filter_layer)
.with(tracing_layer)
.with(JsonStorageLayer)
.with(formatting_layer)
.init()
}Copy 接下来,我们将实现我们的 API 端点,并在处理程序函数中添加一些测量代码。重要的是要注意,我们的重点不在于此应用程序的功能,而在于从应用程序生成有意义且可利用的跟踪数据。
首先,我们有一些模型文件,允许我们对 post 和 comment 进行序列化和反序列化。
//models.rs
...
#[derive(Debug, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct Post {
pub user_id: i64,
pub id: i64,
pub title: String,
pub body: String,
#[serde(default)]
pub comments: Vec<Comment>,
}
#[derive(Debug, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
pub struct Comment {
pub post_id: i64,
pub id: i64,
pub name: String,
pub email: String,
pub body: String,
}接下来,让我们处理 API 端点处理程序。请注意,某些函数上装饰有 instrument 属性。这是我们如何在处理程序函数和它用于执行任务的后续函数上启用跟踪的方法。
// lib.rs
...
const BASE_API_URL: &'static str = "https://jsonplaceholder.typicode.com";
// The get_post handler
#[instrument(level = "info", name = "get_posts", skip_all)]
#[get("")]
async fn get_posts() -> Result<HttpResponse, Error> {
// Randomly simulate errors in request handling
let choices = [200, 400, 401, 200, 500, 501, 200, 500];
let mut rng = rand::thread_rng();
let choice = choices.choose(&mut rng)
.unwrap()
.clone();
match choice {
400..=401 => Ok(HttpResponse::new(StatusCode::from_u16(choice).unwrap())),
500..=501 => Ok(HttpResponse::new(StatusCode::from_u16(choice).unwrap())),
_ => {
let posts = fetch_posts(20)
.await
.map_err(actix_web::error::ErrorInternalServerError)?;
Ok(HttpResponse::Ok().json(posts))
}
}
}
// Fetching posts with a limit.
#[instrument(level = "info", name = "fetch_posts")]
async fn fetch_posts(limit: usize) -> anyhow::Result<Vec<Post>> {
let client = Client::new();
let url = format!("{}/posts", BASE_API_URL);
let mut posts: Vec<Post> = request_url(&client, &url).await?;
posts.truncate(limit);
let post_idx_to_ids: Vec<(usize, i64)> = posts.iter().enumerate().map(|(idx, post)| (idx, post.id)).collect();
// fetch post comments one after another.
for (index, post_id) in post_idx_to_ids {
let comments = fetch_comments(&client, post_id).await?;
posts[index].comments = comments
}
Ok(posts)
}
...在上面的片段中,我们仅发送跟踪。也可以使用可靠的日志收集器来收集日志并将其发送到 Quickwit 或其他后端。
使用 Quickwit 收集跟踪数据
现在我们已经构建了应用程序。让我们与 Quickwit 一起运行,并确保生成的跟踪被 Quickwit 索引。
与我们在之前的博客文章中所做的不同,我们将创建一个 docker-compose 文件来简化 Quickwit、Jaeger 和 Grafana 之间的设置。以下 docker-compose 文件包含所有必要的配置。
QW_ENABLE_OTLP_ENDPOINT:允许 Quickwit 接受和摄取跟踪和日志数据。SPAN_STORAGE_TYPE、GRPC_STORAGE_SERVER、QW_ENABLE_JAEGER_ENDPOINT:允许 Jaeger 从 Quickwit 拉取跟踪和日志以进行分析。GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS:允许我们在 Grafana 中加载特定的插件。
# docker-compose.yaml
version: '3'
services:
quickwit:
image: quickwit/quickwit:latest
command: run
restart: always
environment:
QW_ENABLE_OTLP_ENDPOINT: true
QW_ENABLE_JAEGER_ENDPOINT: true
ports:
- '7280:7280'
- '7281:7281'
volumes:
- ./qwdata:/quickwit/qwdata
jaeger:
image: jaegertracing/jaeger-query:latest
restart: always
depends_on:
- quickwit
environment:
SPAN_STORAGE_TYPE: 'grpc-plugin'
GRPC_STORAGE_SERVER: 'quickwit:7281'
ports:
- '16686:16686'
grafana:
image: grafana/grafana-enterprise:latest
restart: always
user: root
depends_on:
- quickwit
environment:
GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS: 'quickwit-quickwit-datasource'
ports:
- '3000:3000'
volumes:
- ./grafana-storage:/var/lib/grafana有了这个 docker-compose 文件,让我们在项目目录中创建所需的目录以使服务正确运行。创建 qwdata 目录以存储 Quickwit 数据。
然后,下载并将 Quickwit Grafana 数据源插件放置在预期位置。
wget https://github.com/quickwit-oss/quickwit-datasource/releases/download/v0.2.0/quickwit-quickwit-datasource-0.2.0.zip \
&& mkdir -p grafana-storage/plugins \
&& unzip quickwit-quickwit-datasource-0.2.0.zip -d grafana-storage/plugins现在让我们通过运行以下命令启动所有服务(Quickwit、Jaeger、Grafana):
如果没有问题,现在我们可以运行 Web 应用程序并使用 cURL 几次命中 http://localhost:9000/post 端点,以生成一些跟踪。
curl -X GET http://localhost:9000/post等待约 10 秒钟,新的跟踪将被索引并可供搜索。
您现在可以通过使用 cURL 搜索 otel-traces-v0_6 索引来检查 Quickwit 是否已索引跟踪数据。
curl -X POST http://localhost:7280/api/v1/otel-traces-v0_6/search -H 'Content-Type: application/json' -d '{ "query": "service_name:quickwit-jaeger-demo" }'您也可以使用 Quickwit UI http://localhost:7280/ui/search 查看数据。
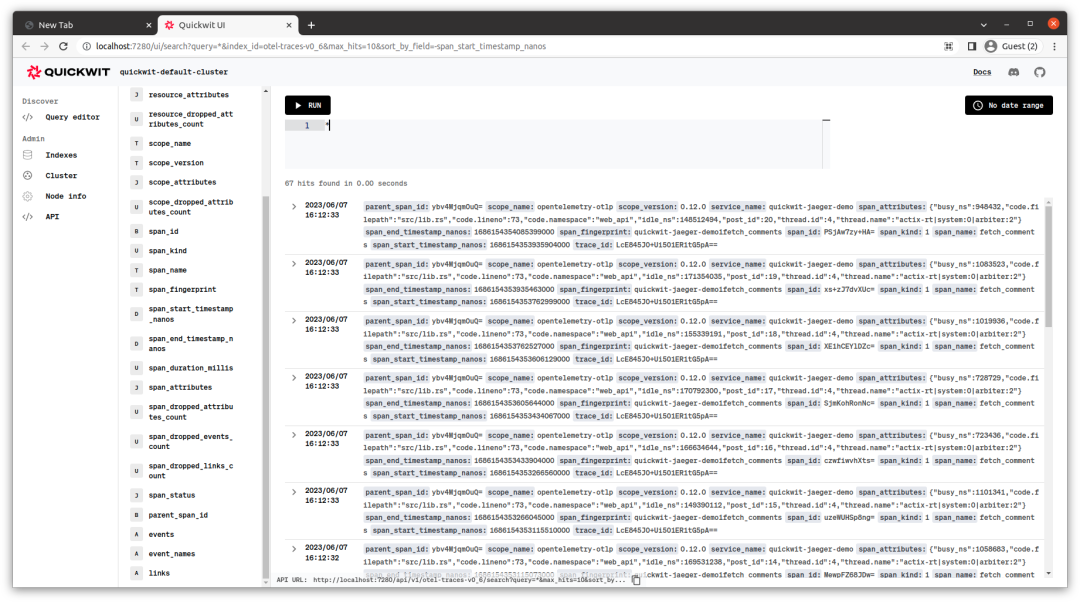
Jaeger 容器已经在运行中了,可以转到 http://localhost:16686 查看我们的应用程序跟踪。
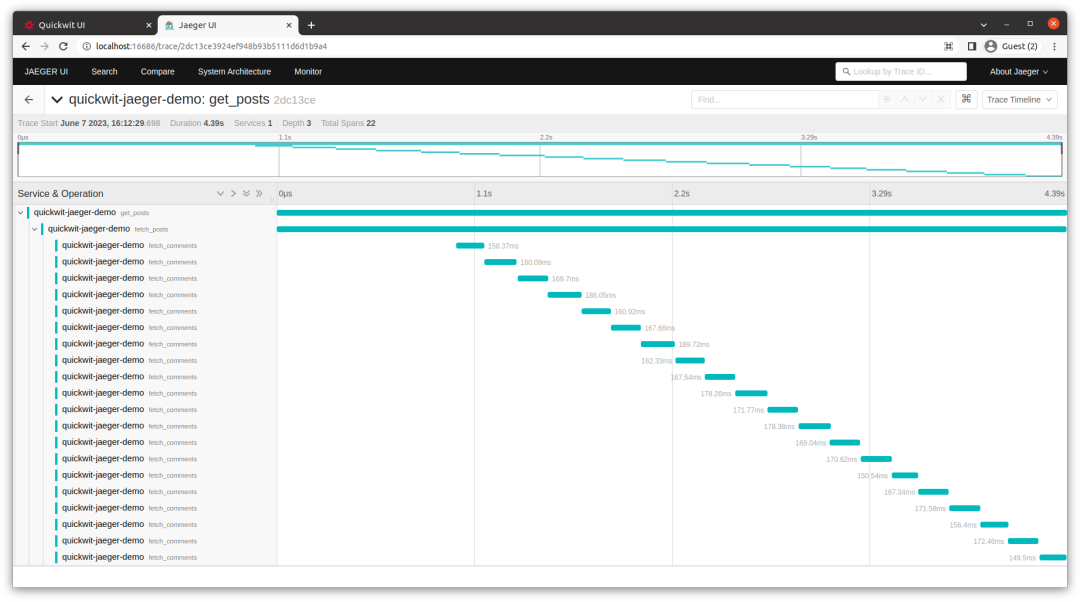
从上面的截图可以看出,我们依次为每个帖子获取评论。也就是说,我们一个接一个地进行了二十次请求。这使得整个请求处理时间更长(上面为 4.39s)。
但我们能不能更好地做?
在 Rust 开发人员拥有的所有优秀工具中,答案是显而易见的 "是的!"。让我们利用 Tokio 和 Rust futures crate 的异步流特性,通过并行获取评论。
让我们更新我们的 fetch_posts 函数,以批量并行运行请求,每次同时进行十个请求。这应该可以进一步加速事情。
// Fetching posts with a limit.
#[instrument(level = "info", name = "fetch_posts")]
async fn fetch_posts(limit: usize) -> anyhow::Result<Vec<Post>> {
...
// fetch post comments concurrently.
let tasks: Vec<_> = post_idx_to_ids
.into_iter()
.map(|(index, post_id)| {
let moved_client = client.clone();
async move {
let comments_fetch_result = fetch_comments(&moved_client, post_id).await;
(index, comments_fetch_result)
}
})
.collect();
let mut stream = futures::stream::iter(tasks)
.buffer_unordered(10); // batch of 10 request at a time
while let Some((index, comments_fetch_result)) = stream.next().await {
let comments = comments_fetch_result?;
posts[index].comments = comments;
}
...
}通过这个改变,你会注意到我们现在处理请求的时间大约为2.46秒,同时你也可以直观地看到我们的请求处理程序在运行期间最多同时运行了十个fetch_comments请求。
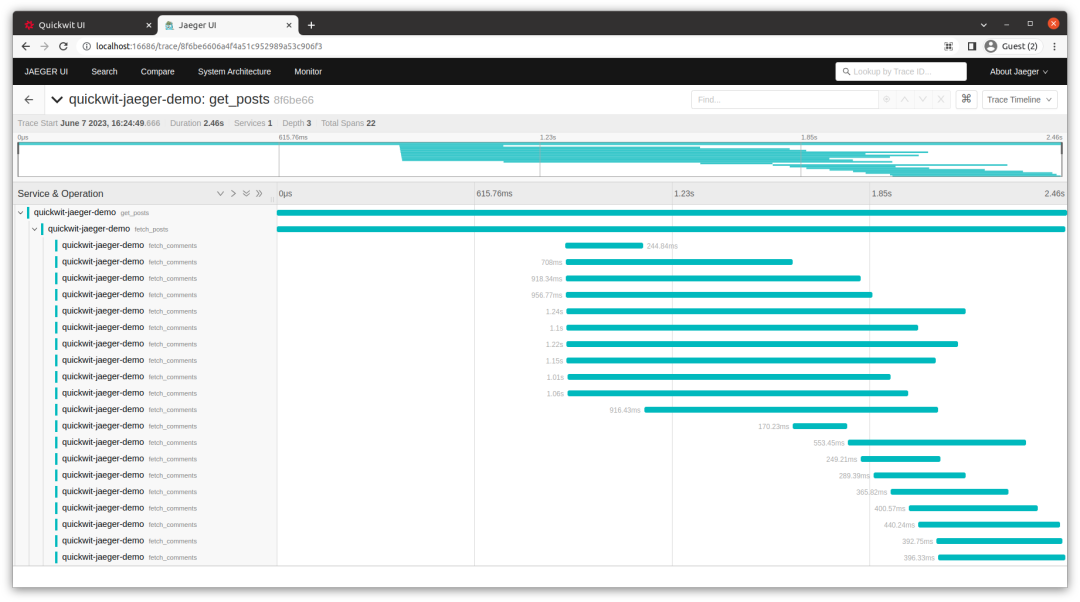
Jaeger 适用于对单个跟踪进行专注检查。但如果我们想要监视服务的延迟呢?如果我们想要计算具有给定跟踪元数据的错误或请求的数量呢?
这就是 Grafana 仪表板的用处。我们想要从我们的跟踪构建 RED 指标并在 Grafana 中可视化它们。
转到 http://localhost:3000/login,使用admin作为用户名和密码登录。
登录后,我们可以使用新发布的 Quickwit 数据源插件 连接到 Quickwit 并查询我们的应用程序跟踪。
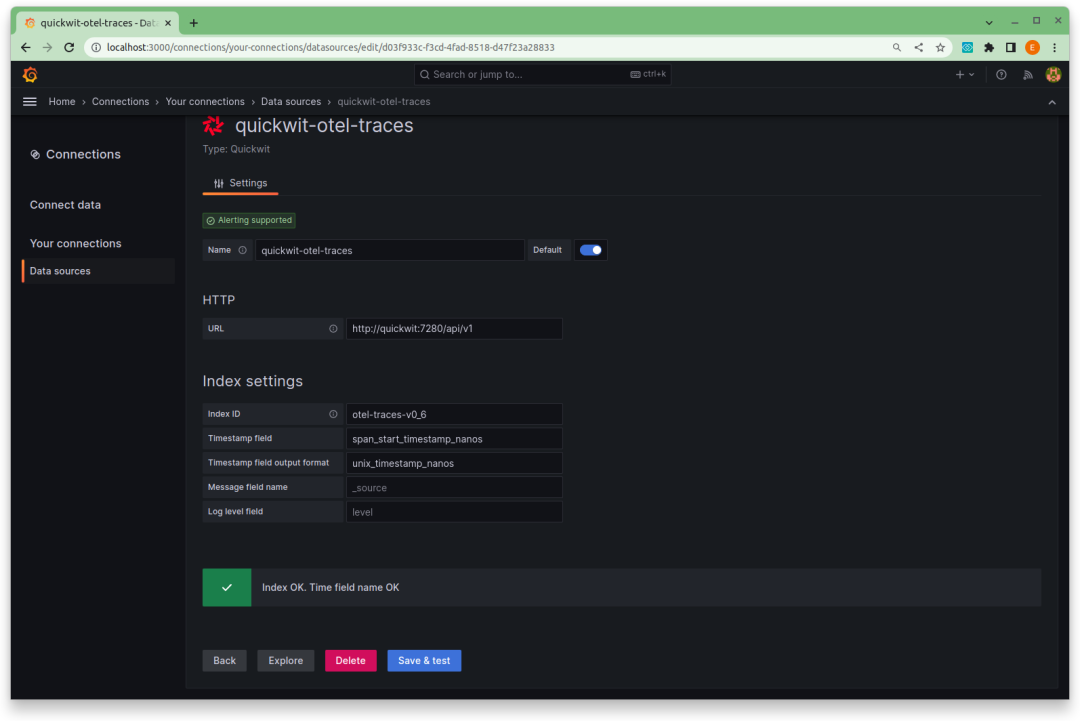
为了使 RED 指标监控过程更加方便,我们准备了一个预配置的 Grafana 仪表板供您下载并导入到您的 Grafana 实例中。
该仪表板作为一种强大的工具,用于可视化和理解性能。它包括三个面板:
第一个面板显示每分钟的请求数量。
第二个面板显示每分钟的错误数量。
第三个面板呈现每分钟请求的持续时间百分位数。
为了观察这些指标的运行情况,您可以使用 HTTP 基准测试工具,甚至可以使用本教程提供的 此脚本发送多个并发请求到您的 Rust 应用程序。
现在让我们来看一下 Grafana 仪表板的截图,展示了运行脚本后的指标情况。
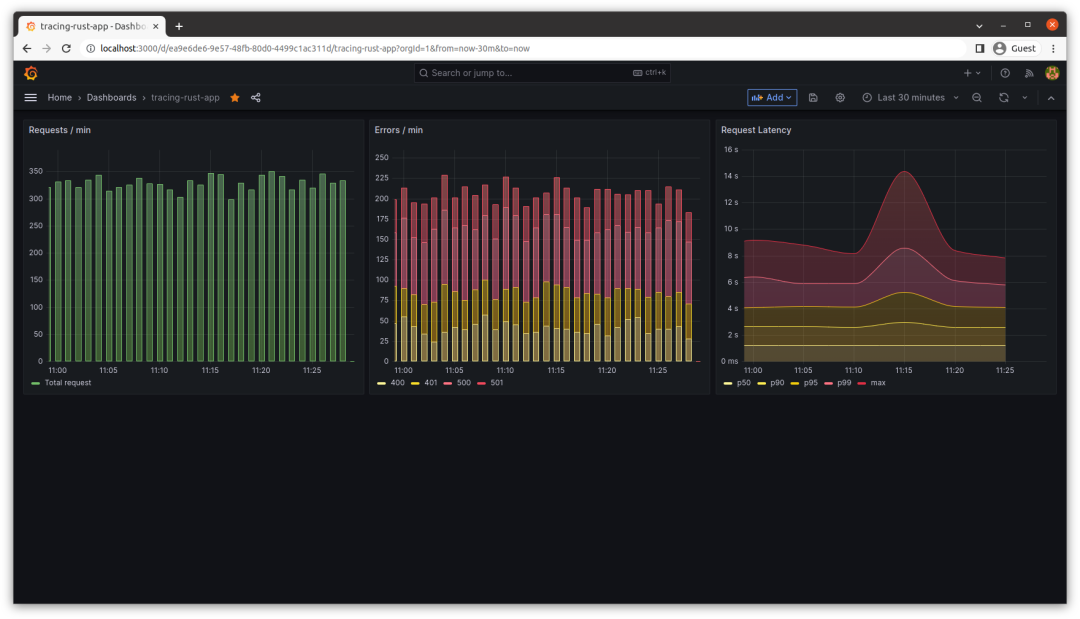
就是这样!在这篇博客文章中,我们超越了基本的日志记录,深入了解了分布式跟踪以及如何使用它来监视应用程序性能。
我们构建 Quickwit 的经验告诉我们,分布式跟踪对于了解由于调用 S3 或在本地磁盘上读取数据而失去时间的位置非常重要。我们希望它对您也有所帮助 :)
愉快的编码和观察!
更多阅读
我们有一堆教程,教您如何使用 Quickwit 进行可观察性。以下是一些快速入门的链接:
快速入门指南。
使用 OTEL 收集器在 Quickwit 中发送跟踪。
将日志发送到 Quickwit。
ReadMore: https://quickwit.io/blog/observing-rust-app-with-quickwit-jaeger-grafana
From 日报小组 Koalr
社区学习交流平台订阅:
Rustcc论坛: 支持rss
微信公众号:Rust语言中文社区
Rust语言中文社区视频号live上线啦,以后会不定时直播Rust活动,欢迎关注