绪论
机遇对于有准备的头脑有特别的亲和力。本章将讲写到链表其中主要将写到单链表和带头双向循环链表的如何实现。
话不多说安全带系好,发车啦(建议电脑观看)。

附:红色,部分为重点部分;蓝颜色为需要记忆的部分(不是死记硬背哈,多敲);黑色加粗或者其余颜色为次重点;黑色为描述需要
目录
链表
1.单链表
1.1.单链表的结构
1.2放入数据到单链表中
1.3 删除单链表中的数据
1.4 摧毁单链表
1.5单链表的打印
2.带头双向循环列表
2.1带头双向链表的结构
2.2双向链表的初始化
2.3双向链表中放入数据
2.4双向链表中的删除数据
2.5双向链表的摧毁
2.6打印双向链表中的各个数据
3.如何快速的实现一个链表
链表
知识点:
链表是一个在逻辑上连续的线性结构,但在物理结构上他的地址并不是连续的,是通过指针的形式链接而成的一个非顺序的存储结构。

细节:
链表的属性:
单向/双向、循环/不循环、带头/不带头
对此就能有多种排列组合,但我们主要学的是:单链表(单向、不带头、不循环)、带头双向循环链表(因为这两个链表最具代表性且常用,当我们学会这两种链表后其他的链表基本也不在话下)
对于上面的属性其实也很好理解下面通过一张图片具体展示:
其中节点表示的就是每个数据的每个小空间(图中的矩形)

1.单链表
单链表是我们在链表中最简单的一种链表形式,因为过于简单所以其一般并不会用于存储数据,但却经常出现于习题以及笔试面试题中,并且还会作为一些数据结构的子结构(如:图的领接表、哈希桶中)。
单链表的基本框架:
1. 单链表的结构
1.一个数剧date(存储当前位置的数据)
2.一个指针next(指向下一个数据)
2. 所要实现的功能
1.将数据放入结构中
2.查找单链表中的某个的数据
3.将数据从结构中删除(删除节点,前提是要先找到该节点所在的位置)
4.将数据展现打印出来
5.摧毁单链表
1.1.单链表的结构
单链表的是由数据、指针组成:
typedef struct SListNode
{
SLDateType data;//SLDateType typedef定义类型和顺序表一样都是为了更加方便去改变结构中的存的类型
struct SListNode* next;//定义一个结构体类型的指针,因为到时候next指向一个结构体类型
}SListNode;//用typedef将struct SListNode改变成SListNode这样更方便于我们后面使用(可以不用加上struct,直接用代替的就好)
//typedef int SLDateType; int重命名为SLDateType1.2放入数据到单链表中
在插入数据之前需要先开辟好空间(也就是创建节点):
SListNode* BuySListNode(SLDateType x) {//接收传进来的数据
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));//用malloc开辟一个结构体大小的空间给新节点
if (newnode == NULL)//熟系的判断是否申请成功
{
perror("malloc failed");
return NULL;
}
newnode->data = x;//在申请的结构体空间中放入数据
newnode->next = NULL;//将其下一个位置暂时指向NULL
return newnode;//返回这个节点,返回类型是个指针类型也就是newnode的地址
}申请好空间后就可以进行插入数据(并且链接了)
- 尾插:从尾部插入,分析尾部的特征是其下一个指向的是NULL对此就能找到最后一个数据的位置,将其指向的NULL改成新节点的位置即可。
动图展示具体步骤:void SListPushBack(SListNode** pphead, SLDateType x) {//注意此处用二级指针是因为可能要修改结构体变量(或理解成传进来的是一级指针类型为了修改他就需要用二级指针) assert(pphead);//判空,注意此处的判空是判的pphead 而不是 STL(*pphead) SListNode* newnode = BuySListNode(x);//先创建一个新节点,调用创建节点的函数 SListNode* tail = *pphead;//一个指针指向链表开始(可能为NULL) if (*pphead == NULL)//此处就是一个类似初始化的步骤 { *pphead = newnode;//此处修改了了结构体变量,即修改了STL的指向指向新创建的链表的开始 } else {//当不是最开始时就正常的进行尾插 while (tail->next) {//找尾部的NULL tail = tail->next;//没找到就改变tail 让其变成next 继续往后找 } tail->next = newnode;//找到后把最后一个位置的数据的next 变成 新节点即可 } }- 头插,比较简单直接看注释就能理解
//头插就会简单很多 void SListPushFront(SListNode** pphead, SLDateType x){//同样用到二级指针,因为需要改变链表结构体变量 assert(pphead); SListNode* newnode = BuySListNode(x);//创建节点 newnode->next = *pphead;//将新开辟的空间的地址指向链表原本第一个元素的 地址 *pphead = newnode;//改变链表的起始地址 }
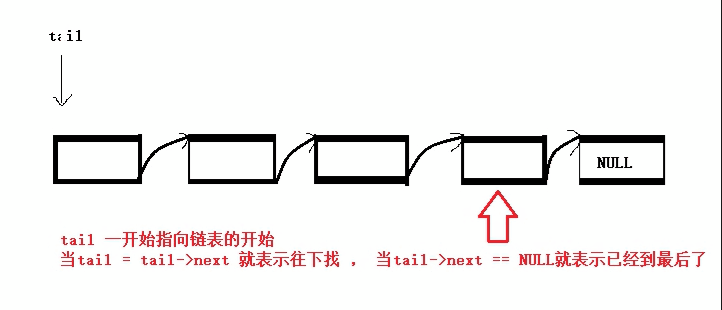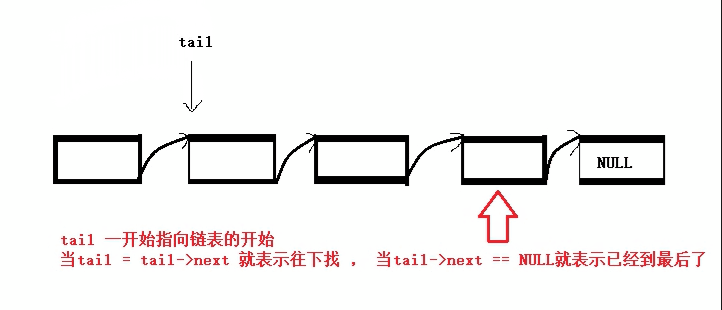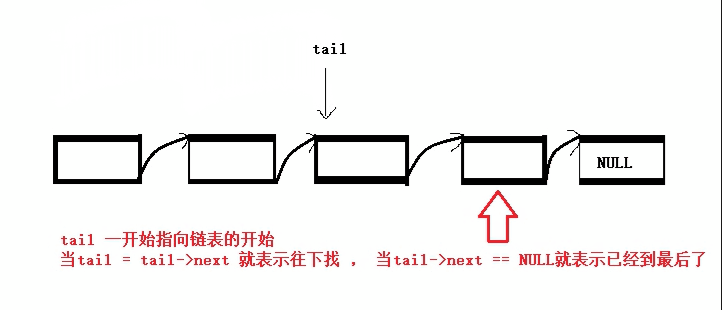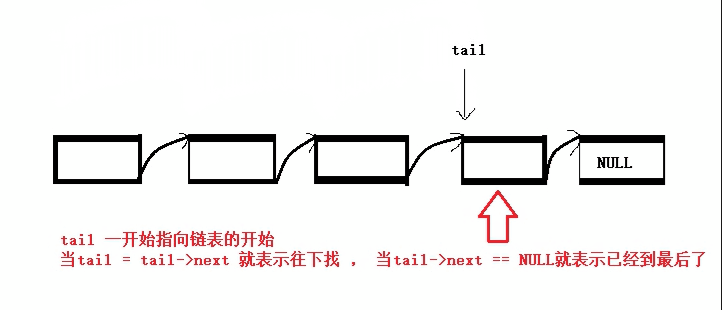
从指定位置插入数据:
单独拎出来是因为其比较特殊,它可以分为在pos位置前插入数据和在pos位置后插入数据两种,并且我们在使用前需要先找到指定的位置后才能进行数据的插入(所以还需要先写一个查找数据的函数接口)。查找单链表中的某个数据(思路类似于尾插):
SListNode* SListFind(SListNode* phead, SLDateType x) {//指针接收结构体 SListNode* find = phead; while (find)//一个循环来找想要的数据 { if (find->data == x)//当找到时 { return find;//返回此处的地址 } find = find->next;//不断往后找和找尾方法一样 } printf("找不到\n"); return NULL;//若找不到返回NULL }有了之后我们就可以利用这个查找函数还进行对该数据的前/后插入数据了:
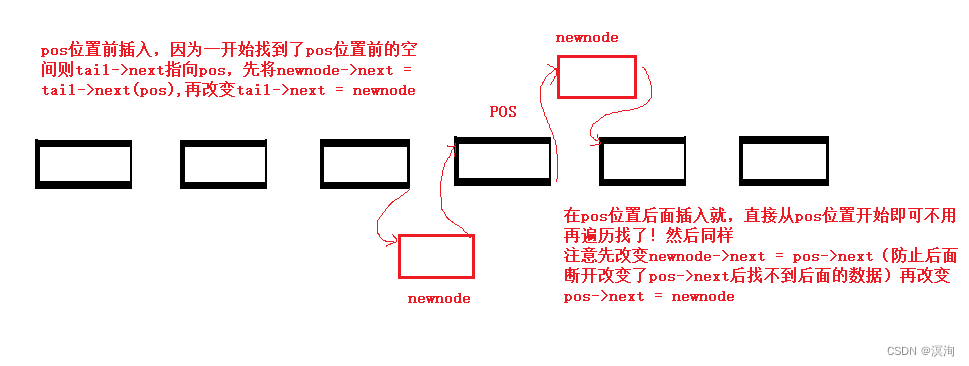
- 先向pos位置前插入(一般不考虑这种,因为比较麻烦且效率低,多在后面插入数据):
void SListInsertFront(SListNode** pphead,SListNode* pos, SLDateType x) {//当是在pos位置前面插入时就要考虑头插了所以可能会改变链表的开始就需要用到二级指针 assert(pphead); assert(pos); if (pos == *pphead)//如果pos位置在第一个那就等于在第一个位置前面插入数据也就是头插 { SListPushFront(pphead, x);//此处用pphead因为pphead已经是一个二级指针了 } else { SListNode* tail = *pphead; while (tail->next != pos)//找到pos位置的前一个位置 { tail = tail->next; } SListNode* newnode = BuySListNode(x);//申请一个节点 newnode->next = tail->next;//先把newnode的指针改变,这样避免当tail改变后找不到tail->next的情况 tail->next = newnode;//再将tail->next 指向改变成 newnode } }- 先pos位置之后插入数据:
void SListInsertAfter(SListNode* pos, SLDateType x) {//此处把链表的地址传给了pos assert(pos); SListNode* newnode = BuySListNode(x);//创建新节点 newnode->next = pos->next;//先改变newnode的节点 pos->next = newnode;//再把pos->next改成newnode }附:当不给头怎么才能在pos位置前面的插入数据,有一种思路现在其pos位置后面插入一个数据然后再将pos位置的值和后面插入的值进行交换就相当于在pos位置前插入数据了。
1.3 删除单链表中的数据
- 尾删:找到倒数第二个数据的位置后再把最后一个位置的空间进行释放即可,然后把倒数第二个位置的next指向NULL。
void SListPopBack(SListNode** pphead) {//可能会修改外部数据所以用二级指针 assert(pphead);//判空 assert(*pphead);//判空,防止第一个位置都没有 if ((*pphead)->next == NULL)//查看第一个数据位置是不是最后一个数据如果是的话 { free(*pphead);//直接释放第一个位置的数据即可 *pphead = NULL;//把没用的指针置为NULL } else { SListNode* tail = *pphead;//用tail代替*pphead,使*pphead不被改变 while (tail->next->next) {//往后看两位,当为空时,就表示到了倒数第二的位置 tail = tail->next;//一步一步走 } free(tail->next);//找到后,tail表示的是倒数第二,而tail->next就是尾,free释放尾即可 tail->next = NULL;//tail->next改变成NULL,因为此时tail变成了最后一个数据 } }头删:分析首先我们肯定是需要一个二级指针接收来改变链表的开始,其次就是要用一个临时指针指向头的位置,先把头改成下一个位置,然后把临时变量指向的原本的头的空间释放。
void SListPopFront(SListNode** pphead) { assert(pphead);//防止pphead为空 assert(*pphead);//查看是否有第一个数据 SListNode* frist = *pphead;//记录第一个数据的位置 *pphead = frist->next;//改变链表的头,改成下一个位置(可能为空当只有一个数据的时候) free(frist);//(释放第一个数据的位置) frist = NULL;//没有的指针置为空 }

在pos位置/pos位置后删除数据
在前面已经提过在pos位置前面插入基本不会用到所以此处就不再写了
- 在pos位置处删除,需要先找到pos位置前面的数据然后后才能改变链接关系
void SListErase(SListNode** pphead,SListNode* pos) { assert(pos);//不用再对*pphead进行检查了因为pos已经间接的检查了*pphead 检查的是是否链表中是否有数据假如没有的话pos也会报错 assert(pphead);//判空 SListNode* tail = *pphead; if (*pphead == pos)//若是第一个元素 { SListPopFront(pphead);//那就直接头删 } else { while (tail->next != pos)//找到pos位置的前一个位置 { tail = tail->next; } tail->next = pos->next;//将前面位置的next改变成pos位置的next,这样就把pos位置给断开了 free(pos);//把pos位置处的空间给释放 } }- 把pos位置后面的数据删除,方法很简单同样就是改变链接关系即可即吧pos->next = pos->next->next(即先找到pos位置后面的数据,然后把pos的next改成后面数据的next即可思想和上面的是一样的)
void SListEraseAfter(SListNode* pos) { assert(pos); if (pos->next == NULL)//注意查看pos位置后面是否还有数据 { return;//若没有则直接返回了 } else { SListNode* del = pos->next;//记录pos后面的位置 pos->next = pos->next->next;//改变链接关系让pos的后面位置指向pos位置后的后面位置 free(del);//释放del del = NULL; } }若没给头怎么删除pos位置处的数据呢?可以先存一份pos位置后面的数据再将后面的数据给赋给pos位置再把pos位置后面的数据给删除即可。

1.4 摧毁单链表
从前往后的依次free(单链表不能从后往前是因为找不到是前面的数据的),并且注意还需要一个指针来在后面,才能保证释放前面数据后能找到后面的数据。
void SListDestroy(SListNode* plist) { assert(plist); SListNode* prev, * tail;//双指针 prev = plist;//指向头 tail = plist->next;//指向第二个数据的位置 while (prev)//当prve==NULL就不用进循环了也表示释放完了 { free(prev);//释放prev出的空间 prev = tail;//将prve指向tail if(tail != NULL)//判断tail是不是NULL tail = tail->next;//若是NULL就不能再往后了 } plist = NULL;//将没用的指针赋成空指针 }

1.5单链表的打印
直接遍历整个数组然后找到其数据进行打印
void SListPrint(SListNode* phead) { SListNode* tail = phead;//用一个指针来指向开始 while (tail != NULL)//只要tail不到NULL都要进群 { printf("%d->", tail->data);//进来打印tail的date tail = tail->next;//往后走 } printf("NULL\n");//打印一下最后的NULL }
附:为什么要用二级指针?
因为如果不用二级指针的话就无法改变传进来的参数(只是传调用无法改变参数),所以只有用传址调用能改变形参,而传递进来的是一个一级指针类型,所以我们就需要二级指针类型来接收他的地址(接收指针类型的指针三步法)。
2.带头双向循环列表
知识点:
本质还是一个链表所以还是一样的通过指针的方法链接,但是需要我们去改变一下结构,增加了一个prev指针指向前面的数据。
结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
细节:
带头双向循环链表的基本框架:
- 带头双向循环链表的结构
- 一个变量存数据
- 一个指针指向前面的数据
- 一个指针指向后面的数据
- 带头双向循环链表所要实现的功能
- 初始化结构
- 将数据放进结构中
- 将数据从结构中删除
- 在指定位置处插入/删除数据
2.1带头双向链表的结构
它的结构是由存数据的变量、两个分别指向前后的指针组成的
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;//数据
struct ListNode* next;//指向后面的数据
struct ListNode* prev;//指向前面的数据
//struct ListNode结构体类型,这里要加上struct因为类型重命名是在后面的
}ListNode;//typedef类型重命名2.2双向链表的初始化
在那之前还需要去写一个申请空间的接口
ListNode* BuyMemory(LTDataType x)//申请空间的函数
{
ListNode* node = (ListNode*)malloc(sizeof(ListNode));//malloc申请一个大小为一个结构体(一个节点的)空间
if (node== NULL)//若申请失败
{
perror("malloc::BuyMemory");//报错
//return NULL;
exit(-1);//直接退出程序
}
node->data = x;//将申请中的空间数据置为给定的x
node->next = NULL;//将next先置为NULL
node->prev = NULL;//将prev先置为NULL
return node;//返回借号的空间
}因为是带头的链表所以需要去先申请一个空间给头
ListNode* ListCreate()//给头申请空间并且返回头指针的地址
{
ListNode* head = BuyMemory(-1);//申请空间并且将其数据置为-1
head->next = head;//将next指向head
head->prev = head;//prev也是指向头的
return head;//返回头申请好的空间
}此处因为有了头,那就不再需要先去创建一个链表的结构(ListNode *STL = NULL )来确定链表的头了(不用传STL/&STL、而是直接传head即可找到链表并且修改链表(即使是改变链表的开始也不用再使用二级指针了))。
下面的头插、头删中的头并不是头而是表示插入/删除第一个节点
2.3双向链表中放入数据
- 头插思路:先记录通过head找到的原本的头再创建一个新节点改变链接关系即可完成
void ListPushFront(ListNode* pHead, LTDataType x) { assert(pHead);//判空 ListNode* newnode = BuyMemory(x);//创建新节点 ListNode* frist = pHead->next;//记录原本的链表的第一个数据 //改变链接关系 // phead <-> first // phead <-> newnode <-> first //先改变newnode与第一个数据间的关系, // newnode <-> firest newnode->next = frist; frist->prev = newnode; //再改变新节点个head的链接关系 // head <-> newnode newnode->prev = pHead; pHead->next = newnode; //改完后 :phead <-> newnode <-> frist }- 尾插方法和头插类似,先记录尾部数据,然后新建一个节点,改变head、尾部数据、新节点三者的链接关系
void ListPushBack(ListNode* pHead, LTDataType x) { assert(pHead); ListNode* newnode = BuyMemory(x);//创建新节点 ListNode* tail = pHead->prev;//记录原本的尾部数据结构 //原本的链接顺序:tail <-> head //改变后的链接顺序:tail <-> newnode <-> head //先改变 tail <-> newnode tail->next = newnode; newnode->prev = tail; //再把newnode和head链接起来:newnode<->head newnode->next = pHead; pHead->prev = newnode; }在在pos位置插入数据,因为这是一个双向且循环的链表,所以我们只需要写一个插入接口即可实现所有想要的结果(此处实现在pos位置前面插入数据,其实现方法和上面的都几乎一样)。
void ListInsert(ListNode* pos, LTDataType x) { assert(pos);//判空 ListNode* prev = pos->prev;//记录前面的数据 ListNode* newnode = BuyMemory(x);//创建新节点 //改变链接关系 // prev pos // prev newnode pos // prev newnode prev->next = newnode; newnode->prev = prev; // newnode pos newnode->next = pos; pos->prev = newnode; // prev newnode pos }同样的为了获取pos的结构的空间地址,我们需要写一个查找的接口
ListNode* ListFind(ListNode* pHead, LTDataType x) { assert(pHead); ListNode* tail = pHead;//tail指向链表 while (tail)//通过tail指针来找 { if (tail->data == x)//找结构中的值是不是等于x { return tail;//找到后返回节点的地址 } tail = tail->next;//往后走 } printf("不存在,找不到\n"); //若到了此处就表示链表中的数据没有x return NULL;//此时返回NULL表示不存在该数据的节点 }
2.4双向链表中的删除数据
在我们删除数据的前提是得链表中有数据所以就需要一个判断是否有数据的接口:
bool If_DTLEmpty(ListNode* pHead)//返回bool值,即返回真或假
{
if (pHead->next == pHead)//就判断phead的->是不是自己即可,因为如果不是则表示是有数据的,反之因为是循环链表没数据就会指向自己了
{
return true;//若指向自己则是真 空的
}
else
{
return false;//反之则非空
}
}
- 头删,记录第一、二个节点,改变链接关系即可
void ListPopFront(ListNode* pHead) { assert(pHead); assert(!If_DTLEmpty(pHead));//判断是否为空 ListNode* front = pHead->next;//记录第一个节点 ListNode* frist = pHead->next->next;//记录第二个节点 //改变链接关系 // head <-> front <-> frist == head <-> first pHead->next = frist; frist->prev = pHead; free(front);//改变链接关系后把第一个节点释放 front = NULL; }- 尾删,记录倒数第一、二个节点,改变链接关系即可
void ListPopBack(ListNode* pHead) { assert(pHead); assert(!If_DTLEmpty(pHead));//判断是否为空 ListNode* new_tail = pHead->prev->prev;//记录倒数第二个节点 ListNode* old_tail = pHead->prev;//记录倒数第一个节点 //改变链接关系 new_tail->next = pHead; pHead->prev = new_tail; free(old_tail);//释放倒数第一个节点 old_tail = NULL; }- 删除指定pos位置处的数据,记录pos位置的next和prev节点然后改变链接关系即可
void ListErase(ListNode* pos) { assert(pos);//判空 ListNode* prev = pos->prev;//记录pos前面节点 ListNode* tail = pos->next;//记录pos后面的节点 //改变链接关系 prev->next = tail; tail->prev = prev; //释放pos free(pos); }
2.5双向链表的摧毁
其摧毁的方法和单链表很像,但要注意他是一个循环的链表,区别在于多了个头所以就可以以这个头为结束,从第一个节点开始,当遇到头时就表示走完一遍链表了就跳出循环,最后再把head释放一下即可
void ListDestory(ListNode* pHead) { assert(pHead); ListNode* tail = pHead->prev;//从第一个节点开始 while (tail != pHead)//当没遇到头前就不断释放再往前走 { ListNode* destroy = tail;//记录要释放的节点地址 tail = tail->next;//tail往后走 free(destroy);//释放空间 } free(pHead);//最后当把链表中的数据释放完后,再释放头 }
2.6打印双向链表中的各个数据
从第一个节点开始遍历链表,当循环回来到head时就退出
void ListPrint(ListNode* pHead) { assert(pHead); ListNode* cur = pHead->next;//从第一个节点开始 printf("《=》head《=》"); while (cur != pHead)//当不是pHead就进去 { printf("%d《=》", cur->data);//打印 cur = cur->next;//往后走 } printf("\n"); }
3.如何快速的实现一个链表
其实如果要快速的实现一个链表的话,用到的就是双向循环链表,因为其是双向的这样就可以直接通过在pos位置插入/删除,这样我们就能剩下写头插、删、尾插、删的时间直接通过插入/删除接口间接实现。
ListNode* BuyMemory(LTDataType x)//申请空间的函数 { ListNode* node = (ListNode*)malloc(sizeof(ListNode));//malloc申请一个大小为一个结构体(一个节点的)空间 if (node== NULL)//若申请失败 { perror("malloc::BuyMemory");//报错 //return NULL; exit(-1);//直接退出程序 } node->data = x;//将申请中的空间数据置为给定的x node->next = NULL;//将next先置为NULL node->prev = NULL;//将prev先置为NULL return node;//返回借号的空间 } ListNode* ListCreate()//给头申请空间并且返回头指针的地址 { ListNode* head = BuyMemory(-1);//申请空间并且将其数据置为-1 head->next = head;//将next指向head head->prev = head;//prev也是指向头的 return head;//返回头申请好的空间 } void ListPushBack(ListNode* pHead, LTDataType x) { assert(pHead); ListInsert(pHead,x); } void ListPrint(ListNode* pHead) { assert(pHead); ListNode* cur = pHead->next;//从第一个节点开始 printf("《=》head《=》"); while (cur != pHead)//当不是pHead就进去 { printf("%d《=》", cur->data);//打印 cur = cur->next;//往后走 } printf("\n"); } bool If_DTLEmpty(ListNode* pHead)//返回bool值,即返回真或假 { if (pHead->next == pHead)//就判断phead的->是不是自己即可,因为如果不是则表示是有数据的,反之因为是循环链表没数据就会指向自己了 { return true;//若指向自己则是真 空的 } else { return false;//反之则非空 } } void ListPopBack(ListNode* pHead) { assert(pHead); assert(!If_DTLEmpty(pHead));//判断链表是否为空 ListErase(pHead->prev); } void ListPushFront(ListNode* pHead, LTDataType x) { assert(pHead);//判空 ListInsert(pHead->next,x); } void ListPopFront(ListNode* pHead) { assert(pHead); assert(!If_DTLEmpty(pHead));//判断是否为空 ListErase(pHead->next); } ListNode* ListFind(ListNode* pHead, LTDataType x) { assert(pHead); ListNode* tail = pHead;//tail指向链表 while (tail)//通过tail指针来找 { if (tail->data == x)//找结构中的值是不是等于x { return tail;//找到后返回节点的地址 } tail = tail->next;//往后走 } printf("不存在,找不到\n"); //若到了此处就表示链表中的数据没有x return NULL;//此时返回NULL表示不存在该数据的节点 } void ListInsert(ListNode* pos, LTDataType x) { assert(pos);//判空 ListNode* prev = pos->prev;//记录前面的数据 ListNode* newnode = BuyMemory(x);//创建新节点 //改变链接关系 // prev pos // prev newnode pos // prev newnode prev->next = newnode; newnode->prev = prev; // newnode pos newnode->next = pos; pos->prev = newnode; // prev newnode pos } void ListErase(ListNode* pos) { assert(pos);//判空 ListNode* prev = pos->prev;//记录pos前面节点 ListNode* tail = pos->next;//记录pos后面的节点 //改变链接关系 prev->next = tail; tail->prev = prev; //释放pos free(pos); } void ListDestory(ListNode* pHead) { assert(pHead); ListNode* tail = pHead->prev;//从第一个节点开始 while (tail != pHead)//当没遇到头前就不断释放再往前走 { ListNode* destroy = tail;//记录要释放的节点地址 tail = tail->next;//tail往后走 free(destroy);//释放空间 } free(pHead);//最后当把链表中的数据释放完后,再释放头 }
如果有任何问题欢迎讨论哈!
如果觉得这篇文章对你有所帮助的话点点赞吧!
持续更新大量数据结构细致内容,早关注不迷路。