CPM-Bee大模型微调
- CPM-Bee
- 简介:
- 环境配置:
- 应用场景:
- 模型
- 训练参数
- 训练命令:
- 推理:
- 评估:
- 结论:
CPM-Bee
简介:
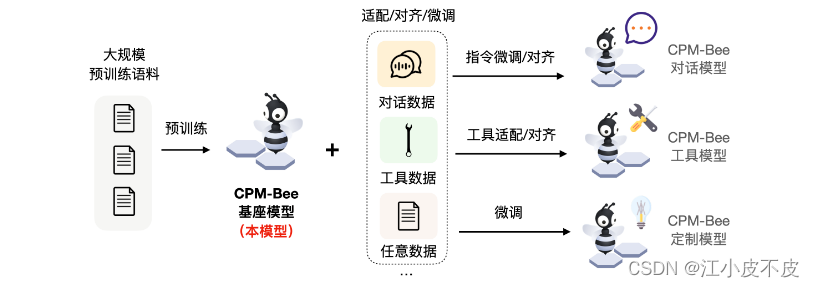
CPM-Bee是一个完全开源、允许商用的百亿参数中英文基座模型,也是CPM-Live训练的第二个里程碑。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。开发者和研究者可以在CPM-Bee基座模型的基础上在各类场景进行适配来以创建特定领域的应用模型。
环境配置:
您需要克隆该仓库:
$ git clone -b main --single-branch https://github.com/OpenBMB/CPM-Bee.git
最好使用pytorch的官方docker
docker pull pytorch/pytorch:1.13.1-cuda11.6-cudnn8-devel
应用场景:
CPM-Bee的基座模型可以准确地进行语义理解,高效完成各类基础任务,包括:
- 文字填空、
- 文本生成、
- 翻译、
- 问答、
- 评分预测、
- 文本选择题等等。
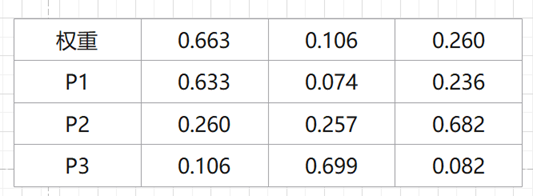
模型
| 模型 | 推理内存占用 | 推荐硬件 |
|---|---|---|
| CPM-Bee-10B | 20GB | RTX 3090(24 GB) |
| CPM-Bee-5B | 11 GB | RTX 3090(24 GB) |
| CPM-Bee-2B | 6.7 GB | GTX 1080(8 GB) |
| CPM-Bee-1B | 4.1 GB | GTX 1660(6 GB) |
训练参数
- 模式:增量微调
- 模型:CPM-Bee-1B | 2.11G
- 增量参数:3.2M
- 训练轮次:5
- 批次:5
- 最大长度:2048
- 数据集:训练集:21778条 验证集:2720条 (古诗选择)
- GPU占用:19G
例子:
{"input": "昏暗的灯熄灭了又被重新点亮。", "options": {"<option_0>": "渔灯灭复明", "<option_1>": "残灯灭又然", "<option_2>": "残灯暗复明", "<option_3>": "残灯灭又明"}, "question": "这段话形容了哪句诗的意境?", "<ans>": "<option_3>"}
训练命令:
修改模型微调脚本scripts/finetune_cpm_bee.sh为:
模型配置文件根据选择的模型进行修改,这里用得是cpm-bee-1b.json
# 四卡微调
# export CUDA_VISIBLE_DEVICES=0,1,2,3
# GPUS_PER_NODE=4
# 单卡微调
export CUDA_VISIBLE_DEVICES=0
GPUS_PER_NODE=1
NNODES=1
MASTER_ADDR="localhost"
MASTER_PORT=12346
OPTS=""
OPTS+=" --use-delta" # 使用增量微调(delta-tuning)
OPTS+=" --model-config config/cpm-bee-1b.json" # 模型配置文件
OPTS+=" --dataset ../tutorials/basic_task_finetune/bin_data/train" # 训练集路径
OPTS+=" --eval_dataset ../tutorials/basic_task_finetune/bin_data/eval" # 验证集路径
OPTS+=" --epoch 5" # 训练epoch数
OPTS+=" --batch-size 5" # 数据批次大小
OPTS+=" --train-iters 100" # 用于lr_schedular
OPTS+=" --save-name cpm_bee_finetune" # 保存名称
OPTS+=" --max-length 2048" # 最大长度
OPTS+=" --save results/" # 保存路径
OPTS+=" --lr 0.0001" # 学习率
OPTS+=" --inspect-iters 100" # 每100个step进行一次检查(bmtrain inspect)
OPTS+=" --warmup-iters 1". # 预热学习率的步数为1
OPTS+=" --eval-interval 50" # 每50步验证一次
OPTS+=" --early-stop-patience 5" # 如果验证集loss连续5次不降,停止微调
OPTS+=" --lr-decay-style noam" # 选择noam方式调度学习率
OPTS+=" --weight-decay 0.01" # 优化器权重衰减率为0.01
OPTS+=" --clip-grad 1.0" # 半精度训练的grad clip
OPTS+=" --loss-scale 32768" # 半精度训练的loss scale
OPTS+=" --start-step 0" # 用于加载lr_schedular的中间状态
OPTS+=" --load ckpts/pytorch_model.bin" # 模型参数文件
CMD="torchrun --nnodes=${NNODES} --nproc_per_node=${GPUS_PER_NODE} --rdzv_id=1 --rdzv_backend=c10d --rdzv_endpoint=${MASTER_ADDR}:${MASTER_PORT} finetune_cpm_bee.py ${OPTS}"
echo ${CMD}
$CMD
修改/src/config/cpm-bee-1b.json
{
"vocab_size": 86583,
"dim_model": 4096,
"dim_ff" : 1024,
"num_layers" : 48,
"num_heads": 32,
"dim_head" : 40,
"dropout_p" : 0.0,
"position_bias_num_buckets" : 256,
"position_bias_num_segment_buckets": 256,
"position_bias_max_distance" : 2048,
"eps" : 1e-6,
"half" : true,
"mask_modules": [[false, false], [true, false], [false, false], [true, false], [true, true], [true, false], [true, true], [true, true], [false, false], [false, false], [true, true], [true, false], [true, false], [true, true], [false, false], [true, true], [false, false], [false, true], [true, false], [true, true], [false, false], [false, true], [true, true], [true, true], [false, false], [true, true], [false, false], [true, true], [true, true], [false, false], [true, true], [false, false], [true, true], [false, false], [true, true], [true, false], [true, true], [true, true], [true, true], [false, false], [true, true], [false, false], [true, true], [true, true], [false, false], [true, true], [false, false], [false, false]]
}
直接运行脚本即可开始微调:
$ cd ../../src
$ bash scripts/finetune_cpm_bee.sh
推理:
src/text_generation.py
from cpm_live.generation.bee import CPMBeeBeamSearch
from cpm_live.models import CPMBeeTorch, CPMBeeConfig
from cpm_live.tokenizers import CPMBeeTokenizer
from opendelta import LoraModel
import torch
if __name__ == "__main__":
data_list = [
{"input": "昏暗的灯熄灭了又被重新点亮。", "options": {"<option_0>": "渔灯灭复明", "<option_1>": "残灯灭又然", "<option_2>": "残灯暗复明", "<option_3>": "残灯灭又明"}, "question": "这段话形容了哪句诗的意境?", "<ans>": ""},
{"input": "涤荡万里,威名远扬。", "options": {"<option_0>": "万里静氛埃", "<option_1>": "万里绝氛埃", "<option_2>": "万里绝风烟", "<option_3>": "万里绝妖氛"}, "question": "这段话形容了哪句诗的意境?", "<ans>": ""}
]
config = CPMBeeConfig.from_json_file("config/cpm-bee-1b.json")
ckpt_path = "ckpts/pytorch_model.bin"
tokenizer = CPMBeeTokenizer()
model = CPMBeeTorch(config=config)
#insert LoRA if your model has been finetuned in delta-tuning.
delta_model = LoraModel(backbone_model=model, modified_modules=["project_q", "project_v"], backend="hf")
lora_ckpt_path = "results/cpm_bee_finetune-delta-best.pt"
model.load_state_dict(torch.load(lora_ckpt_path), strict=False)
model.load_state_dict(torch.load(ckpt_path), strict=False)
model.cuda().eval()
# use beam search
beam_search = CPMBeeBeamSearch(
model=model,
tokenizer=tokenizer,
)
inference_results = beam_search.generate(data_list, max_length=100, repetition_penalty=1.1)
for res in inference_results:
print(res)
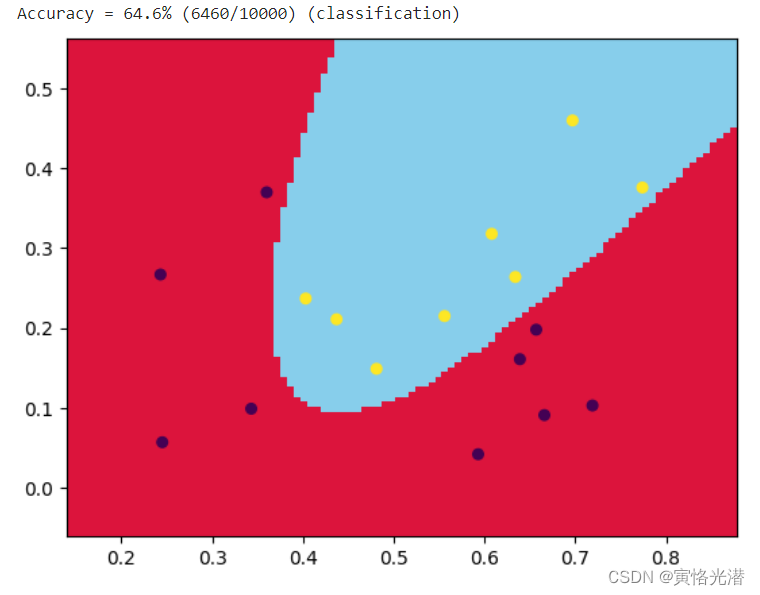
评估:
| 准确率 | 基础大模型 | 微调大模型 |
|---|---|---|
| 验证集10条 | 40% | 90% |
| chatgpt10条 | 30% | 50% |
| claude10条 | 60% | 60% |
结论:
目前来看,微调大模型在训练集和测试集上的表现较好,但是在额外数据集上的表现和基础大模型差异性不大,可能有以下几个原因:
- 过拟合。微调过程中模型过度适应训练集,对测试集和额外数据集的泛化能力较差。
- 微调的epoch数过少。有些情况下,微调仅仅5-10个epoch难以学习到额外数据集的特征,需要设置更长的训练轮数。但epoch过长也会带来过拟合风险。
- 微调训练的参数量过少,模型并没有真正学到知识,需要进行全量重新训练。