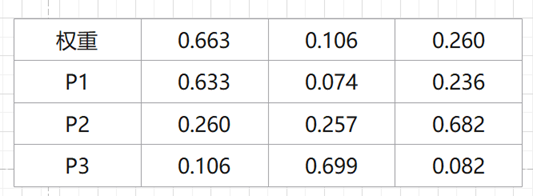
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、kube-proxy三种服务负载模式
- 1.1 userspace 模式
- 1.2 iptables 模式
- 1.3 ipvs 模式
- 二、kube-proxy 启动参数
- 基本参数
- 目录挂盘
- kubeproxy配置项(ConfigMap)
- kube-proxy 启动参数
- 三、kube-proxy 常用命令
- 四、宿主机上的iptables规则(Kube-Proxy)
- 4.1 给定K8S集群
- 4.2 DNS Service将流量发送给两个Pod
- 4.2 Kubernetes Service将流量发送给APIServer的6443端口
- 总结
前言
在前面我们讲解过提供相同服务的一组 Pod 可以抽象成为一个 Service,通过 Service 提供的统一入口(一个虚拟的 Cluster IP 地址)来提供服务,Service 在这里起到了负载均衡器的作用,它会将接收到的请求转发给后端的 Pod。在大部分情况下,Service 只是一个概念,而真正起作用的是在各个 Node 节点上运行的 kube-proxy 服务进程。本实验将会介绍 kube-proxy 的原理和机制,方便大家能够更加深入的理解 Service 背后的实现逻辑。
在 Kubernetes 集群中的每个 Node 节点上都会运行一个 kube-proxy 服务进程,可以把这个进程看作是 Service 的透明代理兼负载均衡器,它的核心功能是将到某个 Service 的访问请求转发到后端的多个 Pod 实例上。
kube-proxy 提供了三种服务负载模式(按时间顺序):
第一代模式,基于用户态的 userspace 模式:早期的代理模式
第二代模式,iptables 模式:默认内核级代理模式
第三代模式,ipvs 模式:处于实验性阶段的代理模式
学习 kubeProxy ,首先要明确这个组件的功能,就是将 svc 的流量转到 Pod ,所以,与其相关的所有的知识点都是围绕这个功能来的。
一、kube-proxy三种服务负载模式
kube-proxy是什么? kube-proxy是Kubernetes中的一个网络代理组件,主要用于负责维护Kubernetes集群中各个节点之间的网络通信,包括负责实现Service的负载均衡、端口转发、IP地址转发等功能。
kube-proxy的作用? kube-proxy的作用主要是保证Pod可以与Service进行通信,通过负载均衡功能将请求分发到后端的多个Pod中,同时也可以实现Service与外部网络的通信。kube-proxy还可以通过ipvs和iptables两种方式实现Service的负载均衡功能。
kube-proxy的实现原理? kube-proxy实现Service的负载均衡主要有两种方式,一种是基于iptables,另一种是基于ipvs。
基于iptables:kube-proxy通过监听Kubernetes API Server的Service对象的变化,根据Service中配置的Labels来动态地生成iptables规则,实现Service的负载均衡。
基于ipvs:kube-proxy通过监听Kubernetes API Server的Service对象的变化,根据Service中配置的Labels来动态地生成ipvs规则,实现Service的负载均衡。相比于iptables,ipvs具有更高的性能和更强大的负载均衡能力。
1.1 userspace 模式
userspace 模式是 kube-proxy 使用的第一代模式,该模式在 kubernetes v1.0 版本开始支持使用。userspace 模式的实现原理图示如下:
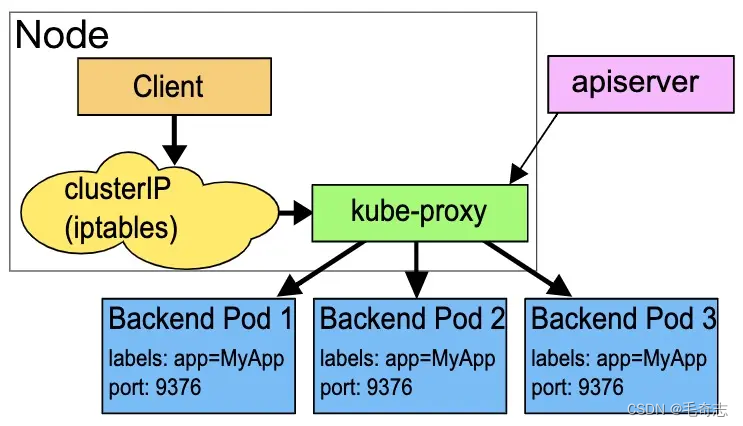
kube-proxy 会为每个 Service 随机监听一个端口(proxy port),并在宿主机上增加一条 iptables 规则。所以通过 ClusterIP:Port 访问 Service 的报文都 redirect 到 proxy port,kube-proxy 从它监听的 proxy port 收到报文以后,走 round robin(默认) 或是 session affinity(会话亲和力,即同一 client IP 都走同一链路给同一 pod 服务),分发给对应的 pod。
由于 userspace 模式会造成所有报文都走一遍用户态(也就是 Service 请求会先从用户空间进入内核 iptables,然后再回到用户空间,由 kube-proxy 完成后端 Endpoints 的选择和代理工作),需要在内核空间和用户空间转换,流量从用户空间进出内核会带来性能损耗,所以这种模式效率低、性能不高,不推荐使用。了解即可。
1.2 iptables 模式
iptables 模式是 kube-proxy 使用的第二代模式,该模式在 kubernetes v1.1 版本开始支持,从 v1.2 版本开始成为 kube-proxy 的默认模式。
iptables 模式的负载均衡模式是通过底层 netfilter/iptables 规则来实现的,通过 Informer 机制 Watch 接口实时跟踪 Service 和 Endpoint 的变更事件,并触发对 iptables 规则的同步更新。
iptables 模式的实现原理图示如下:
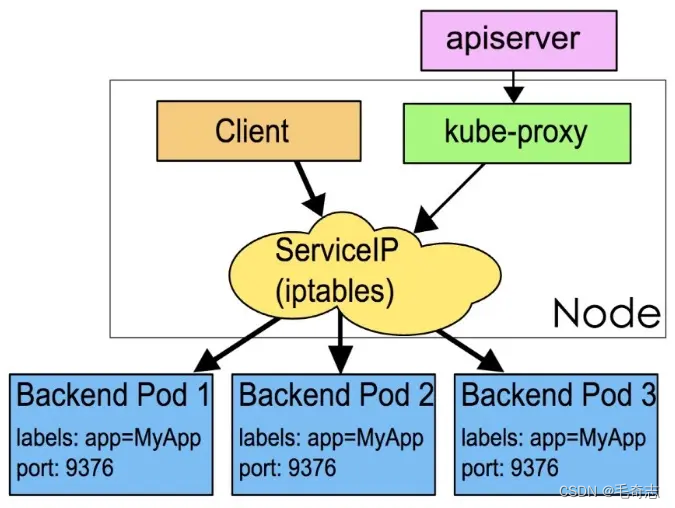
通过图示我们可以发现在 iptables 模式下,kube-proxy 只是作为 controller,而不是 server,真正服务的是内核的 netfilter,体现用户态的是 iptables。所以整体的效率会比 userspace 模式高。
1.3 ipvs 模式
ipvs 模式被 kube-proxy 采纳为第三代模式,模式在 kubernetes v1.8 版本开始引入,在 v1.9 版本中处于 beta 阶段,在 v1.11 版本中正式开始使用。
ipvs(IP Virtual Server) 实现了传输层负载均衡,也就是 4 层LAN交换,作为 Linux 内核的一部分。ipvs运行在主机上,在真实服务器前充当负载均衡器。ipvs 可以将基于 TCP 和 UDP 的服务请求转发到真实服务器上,并使真实服务器上的服务在单个 IP 地址上显示为虚拟服务。
ipvs 模式的实现原理图示如下:
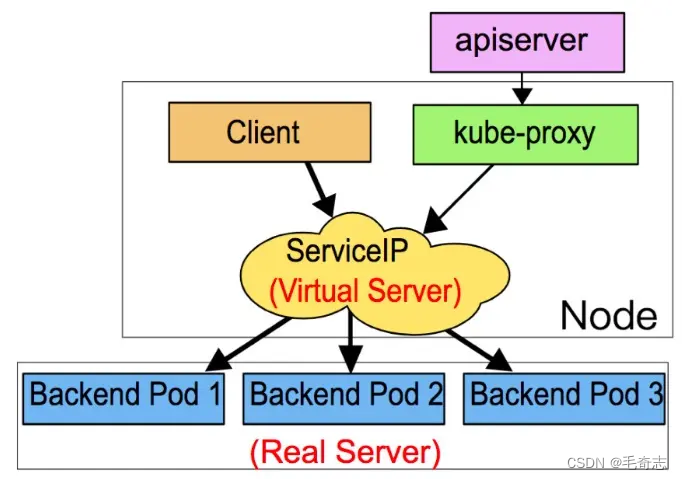
ipvs 和 iptables 都是基于 netfilter 的,那么 ipvs 模式有哪些更好的性能呢?
- ipvs 为大型集群提供了更好的可拓展性和性能
- ipvs 支持比 iptables 更复杂的负载均衡算法(包括:最小负载、最少连接、加权等)
- ipvs 支持服务器健康检查和连接重试等功能
- 可以动态修改 ipset 的集合,即使 iptables 的规则正在使用这个集合
ipvs 依赖于 iptables。ipvs 会使用 iptables 进行包过滤、airpin-masquerade tricks(地址伪装)、SNAT 等功能,但是使用的是 iptables 的扩展 ipset,并不是直接调用 iptables 来生成规则链。通过 ipset 来存储需要 DROP 或 masquerade 的流量的源或目标地址,用于确保 iptables 规则的数量是恒定的,这样我们就不需要关心有多少 Service 或是 Pod 了。
使用 ipset 相较于 iptables 有什么优点呢?iptables 是线性的数据结构,而 ipset 引入了带索引的数据结构,当规则很多的时候,ipset 依然可以很高效的查找和匹配。我们可以将 ipset 简单理解为一个 IP(段) 的集合,这个集合的内容可以是 IP 地址、IP 网段、端口等,iptables 可以直接添加规则对这个“可变的集合进行操作”,这样就可以大大减少 iptables 规则的数量,从而减少性能损耗。
举一个例子,如果我们要禁止成千上万个 IP 访问我们的服务器,如果使用 iptables 就需要一条一条的添加规则,这样会在 iptables 中生成大量的规则;如果用 ipset 就只需要将相关的 IP 地址(网段)加入到 ipset 集合中,然后只需要设置少量的 iptables 规则就可以实现这个目标。
小结:
(1) 从userspace模式到iptables模式,减少了用户空间和内核空间切换,减少了消耗;
(2) 从iptables模式到ipvs模式,减少了iptables规则条数。
二、kube-proxy 启动参数
[root@w1 kubernetes]# kubectl get ds kube-proxy -o yaml -n kube-system
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: kube-system
spec:
revisionHistoryLimit: 10
selector:
matchLabels:
k8s-app: kube-proxy
template:
metadata:
creationTimestamp: null
labels:
k8s-app: kube-proxy
spec:
containers:
- command:
- /usr/local/bin/kube-proxy
- --config=/var/lib/kube-proxy/config.conf
- --hostname-override=$(NODE_NAME)
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
image: k8s.gcr.io/kube-proxy:v1.21.0
imagePullPolicy: IfNotPresent
name: kube-proxy
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/lib/kube-proxy
name: kube-proxy
- mountPath: /run/xtables.lock
name: xtables-lock
- mountPath: /lib/modules
name: lib-modules
readOnly: true
dnsPolicy: ClusterFirst
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kube-proxy
serviceAccountName: kube-proxy
terminationGracePeriodSeconds: 30
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- operator: Exists
volumes:
- configMap:
defaultMode: 420
name: kube-proxy
name: kube-proxy
- hostPath:
path: /run/xtables.lock
type: FileOrCreate
name: xtables-lock
- hostPath:
path: /lib/modules
type: ""
name: lib-modules
updateStrategy:
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
基本参数
spec:
containers:
- command:
- /usr/local/bin/kube-proxy # (容器中的)启动二进制文件和两个参数
- --config=/var/lib/kube-proxy/config.conf # 使用容器中的配置文件
- --hostname-override=$(NODE_NAME) # 使用这个yaml中定义的env NODE_NAME
env:
- name: NODE_NAME # 定义一个名为NODE_NAME的环境变量,其值来源spec.nodeName,这个环境变量会刷到Pod容器里面
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
name: kube-proxy
resources: {} # 资源对 cpu memory disk 的下限request和上限limit
securityContext: # 容器里的安全上下文,可以使用特权容器
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst # 不使用 CluterFirstWithNet 的话,无法解析 servicename.ns
hostNetwork: true # 用来实现ds的Pod直接使用宿主机的ip和端口
nodeSelector: # Pod选择Node,实现每个Node上一个Pod
kubernetes.io/os: linux
priorityClassName: system-node-critical # Node上资源不够,这个Pod优先使用
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {} # Pod的安全上下文
serviceAccount: kube-proxy # Pod要访问apiserver需要通过sa认证,然后 sa - binding - role,这里指定使用哪个sa
serviceAccountName: kube-proxy
terminationGracePeriodSeconds: 30
tolerations: # Pod里面的容忍是应对Node上的污点
- key: CriticalAddonsOnly
operator: Exists
- operator: Exists
updateStrategy: # 部署策略包括滚动和重新创建两种,这里是滚动
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
type: RollingUpdate
目录挂盘
volumeMounts:
- mountPath: /var/lib/kube-proxy # 这个目录下面的config.conf文件就是kube-proxy进程的配置文件
name: kube-proxy
- mountPath: /run/xtables.lock
name: xtables-lock
- mountPath: /lib/modules
name: lib-modules
readOnly: true
volumes:
- configMap:
defaultMode: 420
name: kube-proxy
name: kube-proxy # 配置文件通过configmap引入进来的
- hostPath: # 这里使用hostPath表示仅对Pod所在宿主机有效,因为ds,每个Node上一个Pod,所以可以这样用
path: /run/xtables.lock # 这两个目录暂时不知道干什么的
type: FileOrCreate
name: xtables-lock
- hostPath:
path: /lib/modules
type: ""
name: lib-modules
kubeproxy配置项(ConfigMap)
[root@w1 kubernetes]# kubectl get configmap kube-proxy -o yaml -n kube-system
apiVersion: v1
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: 10.244.0.0/16
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables: # iptables 属性
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs: # ipvs 属性
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration # 资源种类
metricsBindAddress: ""
mode: ""
nodePortAddresses: null
oomScoreAdj: null
portRange: ""
showHiddenMetricsForVersion: ""
udpIdleTimeout: 0s
winkernel:
enableDSR: false
networkName: ""
sourceVip: ""
kubeconfig.conf: |- # kube-proxy访问apiserver所用到的kubeconfig, 通过配置项刷入到Pod里面
apiVersion: v1 # 这个kubeconfig,由 cluster user 构成,然后两者组成 context
kind: Config
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://192.168.100.151:6443
name: default
contexts:
- context:
cluster: default
namespace: default
user: default
name: default
current-context: default
users:
- name: default
user:
tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
kind: ConfigMap
metadata:
labels:
app: kube-proxy
name: kube-proxy
namespace: kube-system
kube-proxy 启动参数
kube-proxy 启动参数包括
–config:kube-proxy 的主配置文件
–hostname-override:设置本 Node 在集群中的主机名,不设置时将使用本机 hostname
[root@w1 kubernetes]# netstat -ntlp | grep kube-proxy
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 2627/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 2627/kube-proxy
如上,PID相同,表示只有一个进程,但是占用了两个端口,第一个是metrics server监听的端口,仅适用于统计本机,另一个是健康服务监听的端口,都是使用默认值
–metrics-bind-address:Metrics Server 的监听地址,设置为 0.0.0.0 表示使用所有 IP 地址,默认值为 127.0.0.1:10249
–healthz-bind-address:healthz 服务绑定主机 IP 地址,设置为 0.0.0.0 表示使用所有 IP 地址,默认值为 0.0.0.0:10256
–healthz-port:healthz 服务监听的主机端口号,设置为 0 表示不启用,默认值为 10256
–bind-address:kube-proxy 绑定主机的 IP 地址,默认值为 0.0.0.0,表示绑定所有 IP 地址
–cleanup:设置为 true 表示在清除 iptables 规则和 ipvs 规则后退出
–cluster-cidr:集群中 Pod 的 CIDR 地址范围,用于桥接集群外部流量到内部
–config-sync-period:从 API Server 更新配置的时间间隔,必须大于 0,默认值为 15m0s
–conntrack-max-per-core:跟踪每个 CPU core 的 NAT 连接的最大数量(设置为 0 表示无限制,并忽略 conntrack-min 的值),默认值为 32768
–conntrack-min:最小 conntrack 条目的分配数量,默认值为 131072
–conntrack-tcp-timeout-close-wait:当 TCP 连接处于 CLOSE_WAIT 状态时的 NAT 超时时间,默认值为 1h0m0s
–conntrack-tcp-timeout-established:建立 TCP 连接的超时时间,设置为 0 表示无限制,默认值为 24h0m0s
–kube-api-burst:每秒发送到 API Server 的请求的数量,默认值为 10
–kubeconfig:kubeconfig 配置文件路径,在配置文件中包括 Master 地址信息及必要的认证信息
–masquerade-all:设置为 true 表示使用纯 iptables 代理,所有网络包都将进行 SNAT 转换
–master:API Server 的地址
–proxy-mode:代理模式,可选项为 userspace、iptables、ipvs,默认值为 iptables,当操作系统内核版本或 iptables 版本不够新时,将自动降级为 userspace 模式
三、kube-proxy 常用命令
kube-proxy的配置方法? kube-proxy的配置方法主要有两种,一种是通过kube-proxy配置文件进行配置,另一种是通过kube-proxy的命令行参数进行配置。通过配置文件进行配置可以使用yaml或json格式,而通过命令行参数进行配置则更为灵活,可以在启动kube-proxy时指定相关参数,达到定制化的效果。
kube-proxy的常用命令?
kubectl proxy 启动kube-proxy
kube-proxy --version 查看kube-proxy的版本信息
kube-proxy --config 查看kube-proxy的配置信息
kube-proxy --cleanup-iptables 清理iptables规则等
kubectl proxy --help
### 以下为打印帮助内容
Creates a proxy server or application-level gateway between localhost and the Kubernetes API Server. It also allows
serving static content over specified HTTP path. All incoming data enters through one port and gets forwarded to the
remote kubernetes API Server port, except for the path matching the static content path.
Examples:
# To proxy all of the kubernetes api and nothing else.
kubectl proxy --api-prefix=/
# To proxy only part of the kubernetes api and also some static files.
# You can get pods info with 'curl localhost:8001/api/v1/pods'
kubectl proxy --www=/my/files --www-prefix=/static/ --api-prefix=/api/
# To proxy the entire kubernetes api at a different root.
# You can get pods info with 'curl localhost:8001/custom/api/v1/pods'
kubectl proxy --api-prefix=/custom/
# Run a proxy to kubernetes apiserver on port 8011, serving static content from ./local/www/
kubectl proxy --port=8011 --www=./local/www/
# Run a proxy to kubernetes apiserver on an arbitrary local port.
# The chosen port for the server will be output to stdout.
kubectl proxy --port=0
# Run a proxy to kubernetes apiserver, changing the api prefix to k8s-api
# This makes e.g. the pods api available at localhost:8001/k8s-api/v1/pods/
kubectl proxy --api-prefix=/k8s-api
Options:
--accept-hosts='^localhost$,^127\.0\.0\.1$,^\[::1\]$': Regular expression for hosts that the proxy should accept.
--accept-paths='^.*': Regular expression for paths that the proxy should accept.
--address='127.0.0.1': The IP address on which to serve on.
--api-prefix='/': Prefix to serve the proxied API under.
--disable-filter=false: If true, disable request filtering in the proxy. This is dangerous, and can leave you
vulnerable to XSRF attacks, when used with an accessible port.
--keepalive=0s: keepalive specifies the keep-alive period for an active network connection. Set to 0 to disable
keepalive.
-p, --port=8001: The port on which to run the proxy. Set to 0 to pick a random port.
--reject-methods='^$': Regular expression for HTTP methods that the proxy should reject (example
--reject-methods='POST,PUT,PATCH').
--reject-paths='^/api/.*/pods/.*/exec,^/api/.*/pods/.*/attach': Regular expression for paths that the proxy should
reject. Paths specified here will be rejected even accepted by --accept-paths.
-u, --unix-socket='': Unix socket on which to run the proxy.
-w, --www='': Also serve static files from the given directory under the specified prefix.
-P, --www-prefix='/static/': Prefix to serve static files under, if static file directory is specified.
Usage:
kubectl proxy [--port=PORT] [--www=static-dir] [--www-prefix=prefix] [--api-prefix=prefix] [options]
Use "kubectl options" for a list of global command-line options (applies to all commands).
kubectl proxy 就是启动一个服务器,其他所有的参数都是服务这个功能的
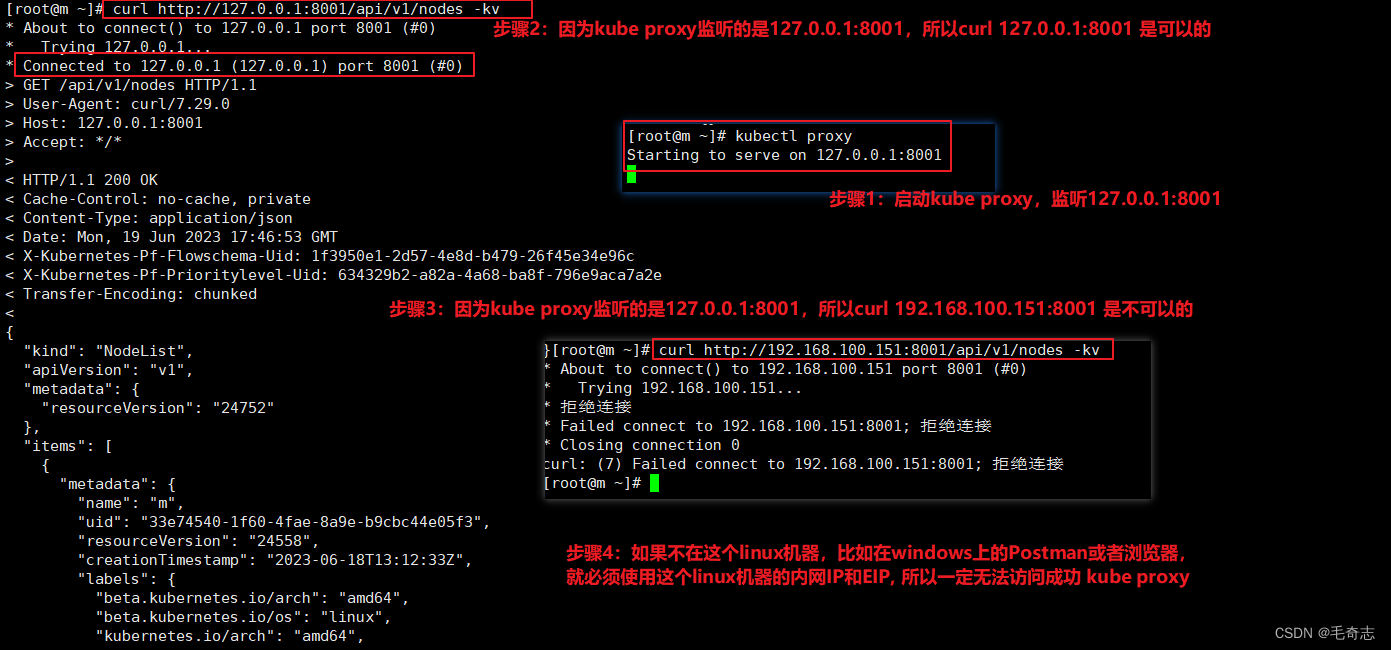
四、宿主机上的iptables规则(Kube-Proxy)
kube-proxy三种模式中,现在使用的就是只有 iptables 模式 或者 ipvs 模式,不管哪种,这两个模式都是依赖 node 节点上的 iptables 规则,所以,要学好 kube-proxy 其中一个重要点就是看懂当前 k8s 集群的 iptables 规则。
4.1 给定K8S集群
假设当前整个 k8s 集群所有的 pod 和 svc 如下:
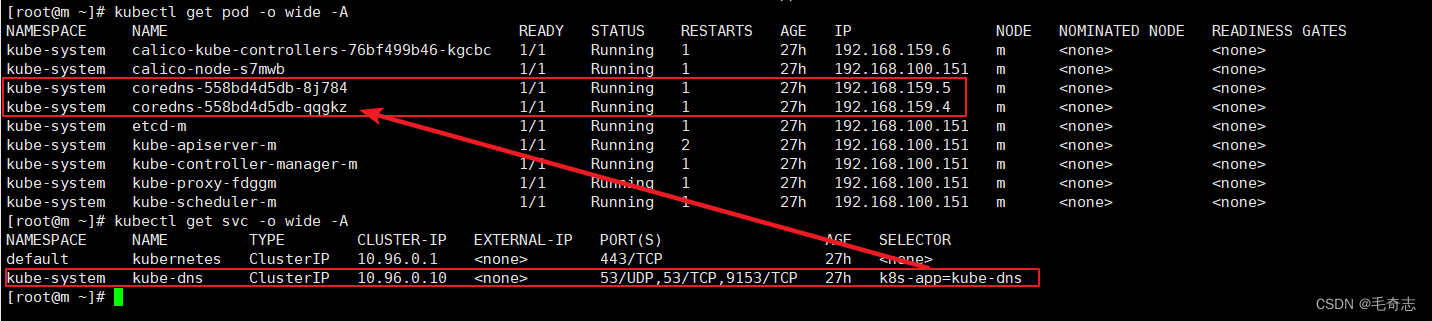
kube-proxy 的功能是将 svc 上的请求转发的 pod 上,无论是 iptables 模式还是 ipvs 模式,这个功能都是通过 iptables 链来完成的,使用三条命令中的任何一条,就可以打印出 kube-proxy 相关的链
iptables -t nat -L
iptables-save -t nat > iptables_rules.txt # 这里使用这一条
iptables-save | grep KUBE > kube_rules.txt
打印出来的东西,KUBE-SVC 是代表 service,KUBE-SEP 是代表 Pod,我们的目的是要查看 kube-proxy 底层如何将 svc 转给Pod,就只要看带有 KUBE-SVC 和 KUBE-SEP 前缀的就好了
4.2 DNS Service将流量发送给两个Pod
从 service 出发,看 coredns 的两个 Pod
(1) 从service出发
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.96.0.10/32 -p tcp -m tcp --dport 9153 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.96.0.10/32 -p tcp -m tcp --dport 9153 -j KUBE-SVC-JD5MR3NA4I4DYORP
ChatGPT解析:这是Kubernetes生成的iptables规则的一部分,用于Service之间的通信。
第一条规则匹配所有源IP地址不在10.244.0.0/16网段内且目标IP地址为10.96.0.10/32(即Kubernetes服务IP地址)以及目标端口为9153的TCP流量,并将其标记为MASQUERADE。这个规则确保返回流量可以正确地返回到源Service。
第二条规则匹配所有目标IP地址为10.96.0.10/32(即Kubernetes服务IP地址)以及目标端口为9153的TCP流量,并将其转发到名为"KUBE-SVC-JD5MR3NA4I4DYORP"的Service上。这个规则完成了Service之间的端口转发,确保了Service之间的通信。
(2) 来看一下这个 KUBE-SVC-JD5MR3NA4I4DYORP 规则,如下:
-A KUBE-SVC-JD5MR3NA4I4DYORP -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-JHFPANVLGNVDZUQD
-A KUBE-SVC-JD5MR3NA4I4DYORP -j KUBE-SEP-VIW7FEYKGV27ZZL4
ChatGPT解析:这是Kubernetes生成的iptables规则的一部分,用于服务发现和负载均衡。
第一条规则匹配名为"KUBE-SVC-JD5MR3NA4I4DYORP"的服务,并将其分发到名为"KUBE-SEP-JHFPANVLGNVDZUQD"的后端Pod。这个规则使用了统计模式的随机方式,设置了50%的概率将流量转发到该后端Pod。这个规则保证了流量的负载均衡,避免了某个后端Pod过度负载的情况。
第二条规则匹配名为"KUBE-SVC-JD5MR3NA4I4DYORP"的服务,并将其分发到名为"KUBE-SEP-VIW7FEYKGV27ZZL4"的后端Pod。这个规则没有使用任何负载均衡的技术,所以它假定流量的分发已经由其他负载均衡机制处理过了。这个规则通常用于具有自己负载均衡功能的应用程序,如MySQL Cluster和HAProxy等。
所以,50% 发送到 KUBE-SEP-JHFPANVLGNVDZUQD,则另外其他所有的流量 (100%-50%=50%) 发送到了 KUBE-SEP-VIW7FEYKGV27ZZL4。
(3) 两个Pod,先看一下前面这个 KUBE-SEP-JHFPANVLGNVDZUQD ,如下:
-A KUBE-SEP-JHFPANVLGNVDZUQD -s 192.168.159.2/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-JHFPANVLGNVDZUQD -p tcp -m tcp -j DNAT --to-destination 192.168.159.2:9153
ChatGPT解析:这是Kubernetes生成的iptables规则的一部分,用于Pod内部通信。
第一条规则匹配名为"KUBE-SEP-JHFPANVLGNVDZUQD"的后端Pod,并将来自IP地址为192.168.159.2的流量标记为MASQUERADE。这个规则确保返回流量可以正确地返回到源Pod。
第二条规则匹配名为"KUBE-SEP-JHFPANVLGNVDZUQD"的后端Pod,并将TCP流量DNAT到IP地址为192.168.159.2、端口为9153的目标Pod上。这个规则完成了Pod之间的端口转发,确保了Pod之间的通信。
(4) 再看后面这个 KUBE-SEP-VIW7FEYKGV27ZZL4 ,如下:
-A KUBE-SEP-VIW7FEYKGV27ZZL4 -s 192.168.159.3/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-VIW7FEYKGV27ZZL4 -p tcp -m tcp -j DNAT --to-destination 192.168.159.3:9153
不用说,剩下50%的流量转发给了另外一个Pod 192.168.159.3 .
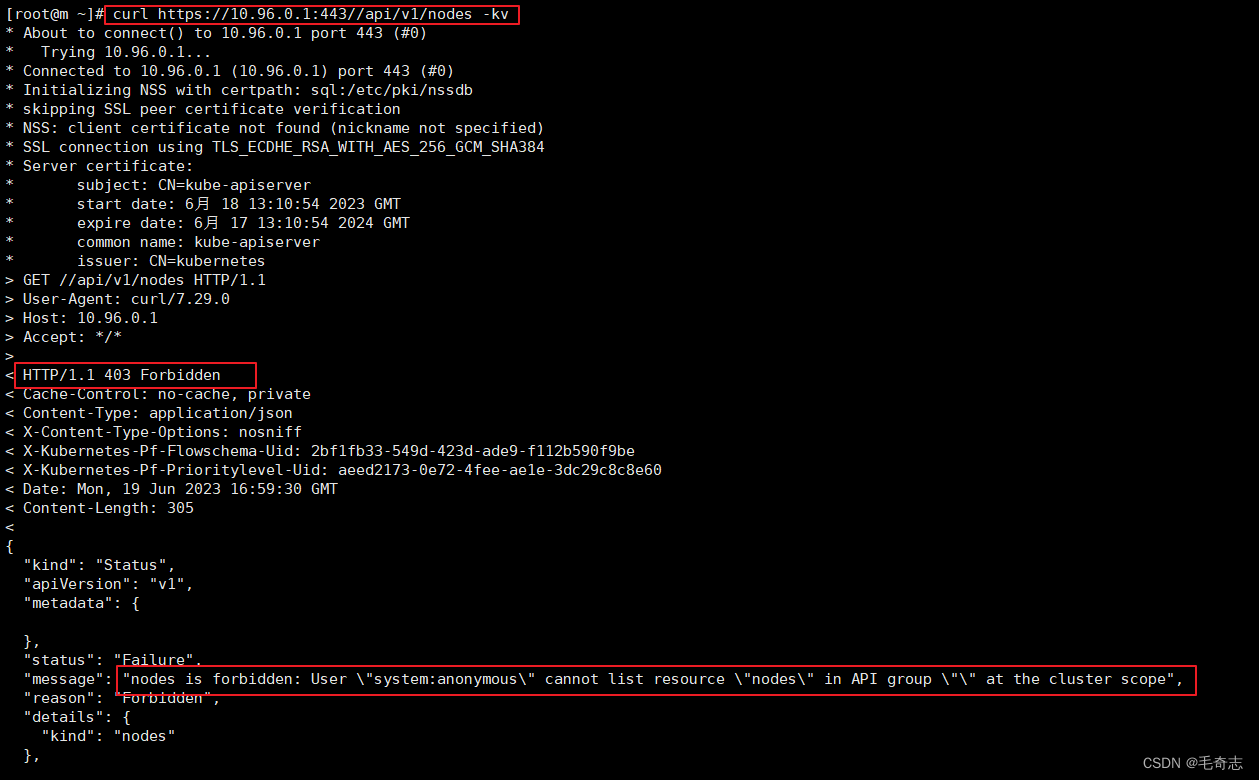
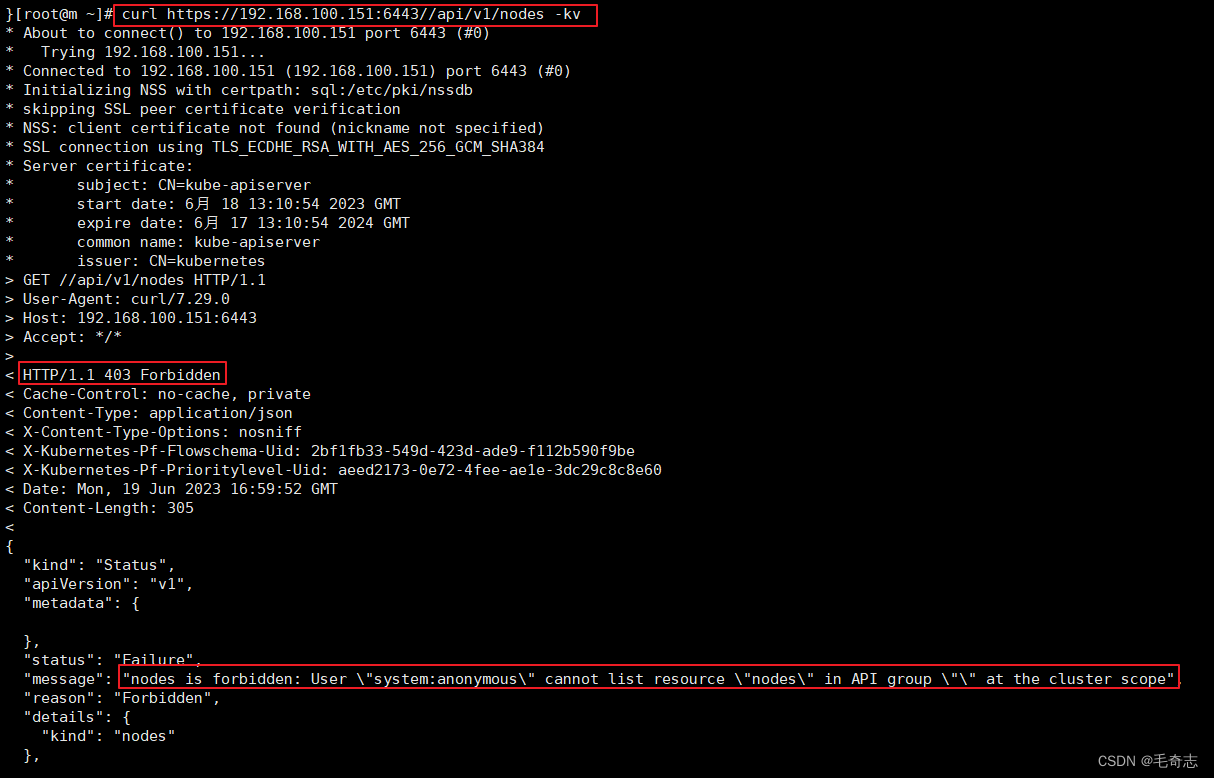
4.2 Kubernetes Service将流量发送给APIServer的6443端口
还有一个 svc kubernetes ,看一下
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.96.0.1/32 -p tcp -m tcp --dport 443 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
ChatGPT解释:第一句命令将TCP流量标记为KUBE-MARK-MASQ,这个标记表示应用NAT规则以将源IP地址转换为主机地址。同时,这个规则还排除了IP地址为10.244.0.0/16的源地址,意味着匹配的流量是除Kubernetes集群外的所有流量。
第二句命令使用KUBE-SVC-NPX46M4PTMTKRN6Y链将TCP流量路由到kubernetes服务的HTTPS端口(默认是443端口)。这个链指示Kubernetes服务网络代理(kube-proxy)重定向流量到后端的Service或Endpoint对象,以便流量可以到达相应的Pod。
看一下这个 KUBE-MARK-MASQ,如下:
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
ChatGPT解释:这个命令将匹配的TCP流量标记为0x4000,即第14位为1的十六进制数。这个标记告诉iptables应用NAT规则以将源IP地址转换为主机地址,这对于使流量从Kubernetes集群外部发出并且需要保护Pod IP地址的私密性非常重要。在Kubernetes中,当节点发出流量时,它不会直接使用Pod的IP地址,而是使用主机IP地址并且Kubernetes代理为其执行NAT。
看一下 KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SVC-NPX46M4PTMTKRN6Y -j KUBE-SEP-XZ7UW2RNYK4JTL7X
解释:这个SVC直接跳转到了Pod KUBE-SEP-XZ7UW2RNYK4JTL7X,那就看一下这个Pod吧
-A KUBE-SEP-XZ7UW2RNYK4JTL7X -s 192.168.100.151/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-XZ7UW2RNYK4JTL7X -p tcp -m tcp -j DNAT --to-destination 192.168.100.151:6443
ChatGPT解释:这两个命令是Kubernetes生成的iptables规则的一部分,用于Pod之间的通信。
第一条规则匹配源IP地址为192.168.100.151的数据包,并在后续处理中将其标记为需要进行NAT处理。这通常用于使Pod连接到外部网络时,通过节点进行网络地址转换以保护Pod的IP地址不被外部知晓。
第二条规则匹配TCP流量,并将其目标IP地址转换为192.168.100.151:6443。这通常用于将流量从一个Pod重定向到另一个Pod或服务,以实现负载均衡和高可用性。在这个例子中,它将流量重定向到一个Pod,该Pod提供Kubernetes API服务器的服务,该服务通常需要通过这个端口进行访问。

总结
参考资料:kube-proxy 组件详解