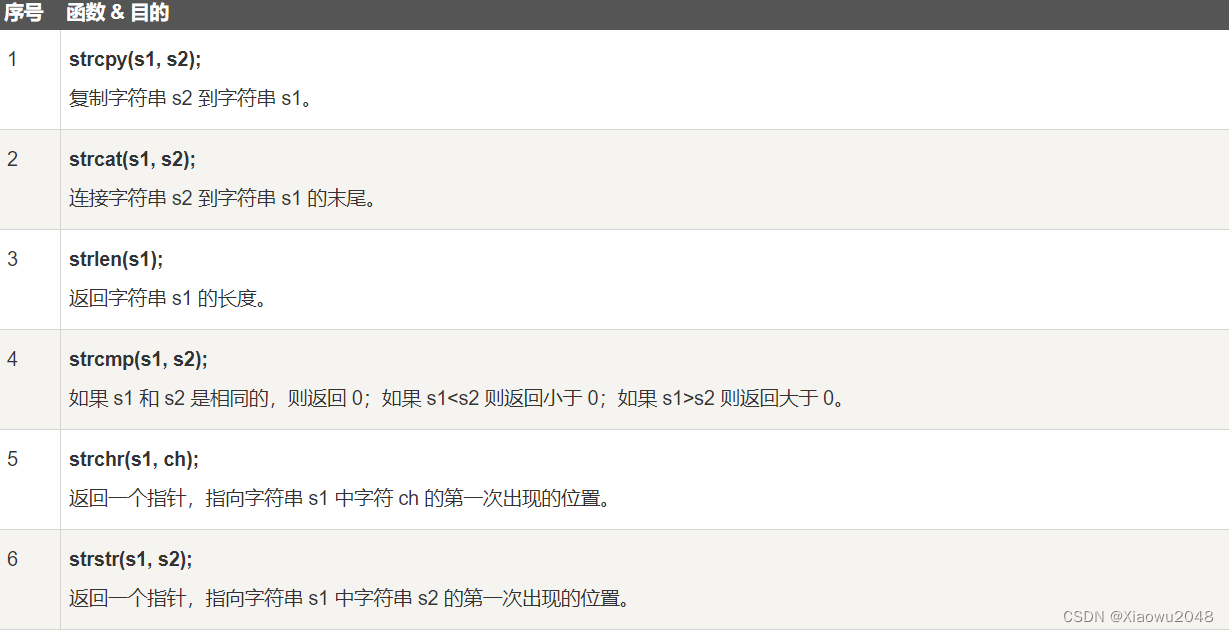
Spark AQE
- AQE/RBO/CBO
- AQE
- AQE特点
- Join 策略调整
- 自动分区合并
- 自动倾斜处理
Spark 3.0 添加了自适应查询执行(AQE)、动态分区剪裁(DPP)、扩展的 Join Hints
AQE/RBO/CBO
Spark SQL 2.0前,仅支持启发式、静态的优化过程。RBO (Rule Based Optimization,基于规则的优化,启发式的优化):基于一些规则和策略实现(谓词下推、列剪枝),这些规则和策略来源于数据库领域已有的应用经验。即:启发式的优化是一种经验主义
Spark SQL 2.2 后,推出 CBO (Cost Based Optimization,基于成本的优化)
CBO 特点 : “实事求是”,基于数据表的统计信息(如表大小、数据列分布)来选择优化策略。一般 CBO 优于 RBO
RBO/CBO 缺点 : 窄、慢、静
- 窄: 适用面太窄,CBO 仅支持注册到 Hive Metastore 的数据表,但很多数据源是存储在分布式文件系统的各类文件(Parquet、ORC、CSV)
- 慢: 统计信息的搜集效率较低。对注册到 Hive Metastore 的数据表,用户需要调用
ANALYZE TABLE COMPUTE STATISTICS来收集统计信息,而各类信息的收集会消耗大量时间 - 静: 静态优化。CBO 会结合各类统计信息制定执行计划,CBO只执行计划交付运行。即:运行时数据分布发生动态变化,CBO 执行计划并不会跟着调整
AQE
Spark 3.0 推出了 AQE (Adaptive Query Execution,自适应查询执行)
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化
- AQE 优化机制触发的时机是 Shuffle Map 阶段执行完毕。即:AQE 次数与Shuffle 的次数一致。无 Shuffle , AQE 就不会触发。
- AQE 依赖优化 Shuffle Map 阶段输出的中间文件的统计信息(每个 data 文件的大小、空文件数量与占比、每个 Reduce Task 对应的分区大小)
- Shuffle 的每个 Map Task 会输出中间文件(data 的数据文件/index 的索引文件)

AQE 的优化决策分别作用:逻辑计划/物理计划,AQE 分:1 个逻辑优化规则/ 3 个物理优化策略:
| 优化类型 | 规则与策略 | AQE特性 | 统计信息 |
|---|---|---|---|
| 逻辑计划 | DemoteBroadcastHashJoin | Join策略调整 | Map 阶段中间文件总大小 |
| 物理计划 | OptimizeLocalShuffleReader | Join策略调整 | 中间文件空文件占比 |
| 物理计划 | CoalesceShufflePartitions | 自动分区合并 | 每个 Reduce Task 分区大小 |
| 物理计划 | OptimizeSkewedJoin | 自动倾斜处理 | 每个 Reduce Task 分区大小 |
AQE特点
AQE 的三大特性:
- Join 策略调整:当某张表过滤后,尺寸小于广播变量阈值,该表参与的数据关联就会从 Shuffle Sort Merge Join 到 Broadcast Hash Join
- 自动分区合并:Shuffle 后,Reduce Task 数据分布过小,AQE 会自动合并过小的数据分区
- 自动倾斜处理:AQE 自动拆分 Reduce 过大的数据分区,降低单个 Reduce Task 的工作负载
Join 策略调整
Join 策略调整涉及1个逻辑规则/1个物理策略,分别是 DemoteBroadcastHashJoin /OptimizeLocalShuffleReader
DemoteBroadcastHashJoin 的作用:把 Shuffle Joins 降为 Broadcast Joins。注意:仅适用 Shuffle Sort Merge Join。
Join 的两个表分别完成 Shuffle Map 后, DemoteBroadcastHashJoin 会判断该中间文件是否满足如下条件:
- 中间文件尺寸总和小于广播阈值: spark.sql.autoBroadcastJoinThreshold
- 空文件占比小于配置项 : spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin
- 只要一张表的统计信息满足这两个条件, Shuffle Sort Merge Join 就会降为 Broadcast Hash Join
当两张表都超过了广播阈值时,Spark SQL 最初的执行计划会选择 Sort Merge Join。AQE 会判断Shuffle Map 的中间文件,是否能降为 Broadcast Join。为了避免 Reduce 数据在网络中的全量分发,采取 OptimizeLocalShuffleReader :Reduce Task 从读取本地节点(Local)的中间文件,完成与广播小表的关联操作
OptimizeLocalShuffleReader 物理策略的生效配置: spark.sql.adaptive.localShuffleReader.enabled=True
自动分区合并
分区合并的原理:当 Reduce Task 从全网把数据分片拉回,AQE 按照分区编号的顺序,依次把小于目标尺寸的分区合并在一起
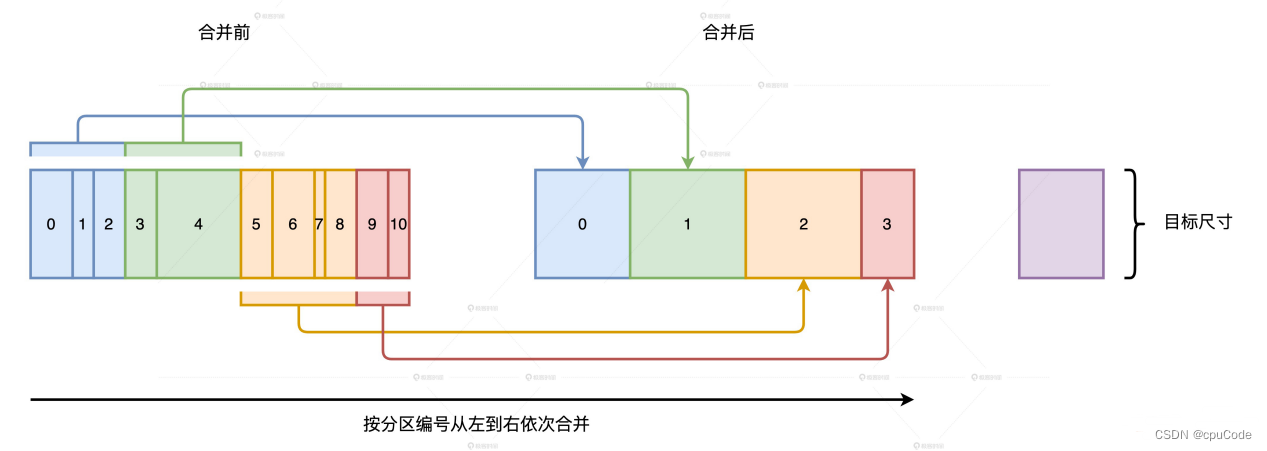
目标分区尺寸的两个参数:
- 分区合并后的推荐尺寸:spark.sql.adaptive.advisoryPartitionSizeInBytes
- 分区合并后,分区数不能低于该值:spark.sql.adaptive.coalescePartitions.minPartitionNum
在 Shuffle Map 完成后, AQE 触发, CoalesceShufflePartitions 策略会添加到物理计划中
自动倾斜处理
自动倾斜处理的原理:当 Reduce Task 的分区大于一定阈值时,利用 OptimizeSkewedJoin 策略,AQE 会把大分区拆成多个小分区
倾斜分区/拆分粒度的决定配置项:
- 倾斜的膨胀系数:spark.sql.adaptive.skewJoin.skewedPartitionFactor
- 倾斜的最低阈值:spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
- 拆分粒度,以字节为单位:spark.sql.adaptive.advisoryPartitionSizeInBytes
自动倾斜处理的局限:在同一 Executor 内,由一个 Task 处理的大分区,被 AQE 拆成多个小分区并交给多个 Task 计算。Task 之间的计算负载就能平衡。但是不能解决不同 Executors 之间的负载均衡问题
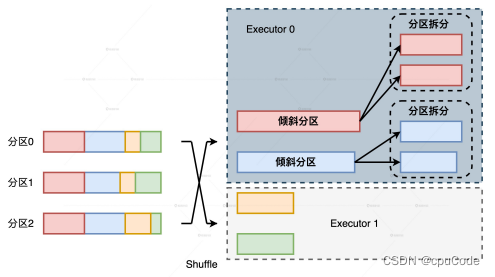
例子:Shuffle的 Map 阶段有 3 个分区,Reduce 阶段有 4 个分区。但4 个分区中有两个都是倾斜的大分区,而且这两个倾斜的大分区刚好都分发到了 Executor 0。
尽管两个大分区被拆分,但整个作业的主要负载还在 Executor 0 上。Executor 0 的计算能力依然是整个作业的瓶颈,这点并没有因为分区拆分而解决
例子:Join 的两张表(表1/表2),如果表 1 有数据倾斜,表 2 无倾斜,关联时,AQE 要对表1拆分,还要对表2的数据分区做复制,来保证关联关系不被破坏
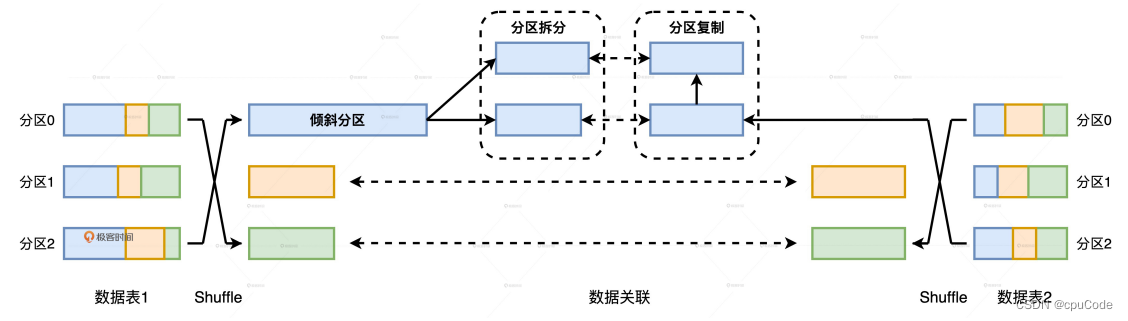
如果表1/表 2都有数据倾斜,为了不破坏逻辑上的关联关系,表1/表2 拆分出的分区还要各自复制一份,左表拆出 M 个分区,右表拆出 N 个分区,那每张表都需要M x N 个分区数据,才能保证关联逻辑的一致性。当 M/N 逐渐变大时, AQE 处理数据倾斜的计算开销会很大
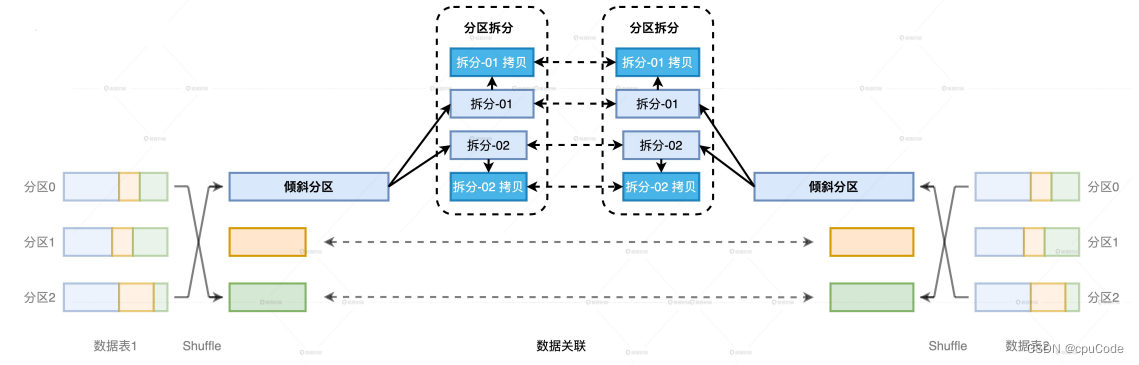
- 当简单的数据倾斜(如: 有倾斜但数据分布均匀/只有一边倾斜),完全可以依赖 AQE 的自动倾斜处理机制
- 但当数据倾斜变得复杂(如: 数据的不同 Key 的分布悬殊/两表有大量的倾斜),就需要衡量 AQE 的自动化机制或手工处理倾斜




![[golang]Go语言从入门到实践-反射](https://img-blog.csdnimg.cn/76c88bb3476c461caec52f9c4ec5cc46.png)