Abstract
本文考虑了一个称为SoftGroup的网络,用于准确和可扩展的3D实例分割。现有的最先进方法会产生硬语义预测,然后进行分组以获得实例分割结果。然而,源于硬决策的错误会传播到分组中,导致预测实例与ground truth的低重叠和大量误报。为了解决上述问题,SoftGroup允许每个点与多个类相关联,以减轻语义预测错误引起的问题,并通过学习将它们分类为背景来抑制误报实例。在可扩展性方面,现有的快速方法在大规模场景上需要数十秒的计算时间,这不能令人满意并且远不适用于实时。我们的发现是作为分组先决条件的k最近邻(k-NN)模块引入了计算瓶颈。SoftGroup就是为了解决这个计算瓶颈而扩展的,简称SoftGroup++。提出的SoftGroup++使用八叉树k-NN降低了时间复杂度,并通过类感知(class-aware)金字塔缩放和后期去体素化(late devoxelization)减少了搜索空间。在各种室内和室外数据集上的实验结果证明了所提出的SoftGroup和SoftGroup++的有效性和通用性。就 A P 50 \mathrm{AP}_{50} AP50而言,他们的表现大大超过了最强的基线(6%∼16%)。在具有大规模场景的数据集上,与SoftGroup相比,SoftGroup++平均实现了6倍的速度提升。此外,SoftGroup可以扩展到执行目标检测和全景分割,并对现有方法进行重大改进。
索引词——点云、点分组(point grouping)、八叉树分组、实例分割、目标检测、全景分割
1 INTRODUCTION
随着3D传感器的快速发展和大规模3D数据集的可用性,对3D数据的场景理解越来越受到关注。点云上的实例分割是一项3D感知任务,是自动驾驶、虚拟现实和机器人导航等广泛应用的基础。实例分割处理点云以输出类别和每个检测到的实例掩码目的。
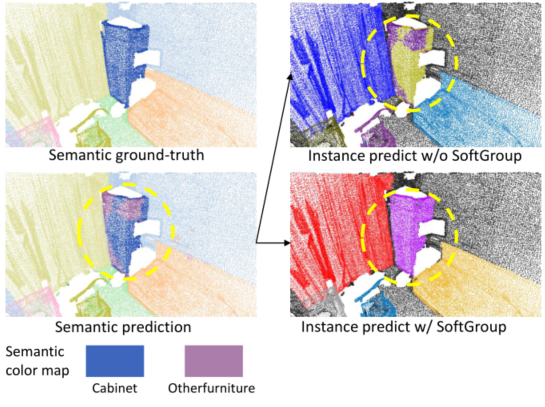
图 1:使用和不使用来自相同语义预测结果的SoftGroup的实例分割。最后一行仅显示语义预测的调色板。实例预测由不同目标的不同随机颜色说明。在语义预测结果中,橱柜的某些区域被错误地预测为其他家具。如果没有SoftGroup,这些错误会传播到实例预测。SoftGroup解决了这个问题并生成了更准确的实例掩码。
本文提出了一种称为SoftGroup的网络架构,用于准确和可扩展的点云实例分割。为了获得高精度,现有的最先进方法[1]、[2]、[3]将3D实例分割视为自下而上的管道。这些方法首先预测逐点语义标签和中心偏移向量,然后将具有小几何距离的相同预测标签的点分组为实例。这些分组算法是基于硬语义预测执行的,其中一个点与单个类相关联。然而,目标通常是局部模糊的,语义分割通常是嘈杂的,不同的目标部分预测不同,因此使用硬语义预测进行实例分组会导致两个问题:(1)预测实例与ground truth的低重叠和(2)来自错误语义区域的额外假阳性实例。图1显示了一个可视化示例。这里,在语义预测结果中,橱柜的某些部分被错误地预测为其他家具。当硬语义预测用于执行分组时,语义预测错误被传播到实例预测。结果,预测的橱柜实例与真实情况的重叠度很低,而另一个家具实例是误报。
所提出的SoftGroup通过考虑软语义分数来执行分组而不是硬的单热语义预测来克服这些问题。SoftGroup的直觉如图2所示。我们的观察是,语义预测不正确的目标部分对于真实语义类仍然具有合理的分数。SoftGroup依靠分数阈值而不是参数最大值来确定目标属于哪个类别。对软语义分数进行分组会产生更准确的真实语义类实例。具有错误语义预测的实例将通过学习将其归类为背景来抑制。为此,我们将实例proposal(即分组的输出)视为正样本或负样本,具体取决于其与ground truth的最大交并比(IoU)。接下来是自上而下的细化阶段,以细化正样本并抑制负样本。如图1所示,SoftGroup可以从不完美的语义预测中生成准确的实例掩码。
SoftGroup进一步扩展了可扩展性,以在大规模场景上保持快速的推理速度。这种先进的架构今后将被称为SoftGroup++。图3a显示现有方法的运行时间随着点数的增加而快速增长。例如,现有方法需要~20s到~50s来处理具有~4.5M点的场景。如图3b所示,进一步分析了该场景的每个网络组件的处理时间。结果表明,k-NN是计算瓶颈,导致HAIS[3]和SoftGroup中关于输入大小的推理时间快速增长。这些方法执行普通k-NN,需要测量所有点的成对距离,导致 O ( n 2 ) \mathcal{O}\left(n^2\right) O(n2)的时间复杂度,这是不可扩展的。
为了能够在大规模场景上进行快速推理,SoftGroup++引入了一种具有低时间复杂度和搜索空间的推理算法。SoftGroup++执行八叉树k-NN而不是vanilla k-NN以将时间复杂度从 O ( n 2 ) \mathcal{O}\left(n^2\right) O(n2)降低到 O ( n log n ) \mathcal{O}(n \log n) O(nlogn)。为了在GPU上有效地并行化八叉树k-NN,提出了一种展开八叉树递归结构的策略,以便可以基于简单的算术过程执行树遍历。为了减少搜索空间,SoftGroup++依赖类感知金字塔缩放和后期去体素化,它们分别对骨干输出特征执行自适应下采样,并延迟从体素到点的转换,直到模型结束。图3a显示,随着输入大小的增加,SoftGroup++仍然保持较快的推理速度。k-NN的计算瓶颈也得到解决,如图3b所示。
SoftGroup和SoftGroup++在概念上都很简单并且易于实现。例如分割任务,它们在不同室内和室外数据集上的AP50方面大大优于以前的最先进方法,范围从6%到16%。SoftGroup++在具有6倍推理速度的大型场景的S3DIS上显示出可扩展性优势。SoftGroup的多功能性还通过扩展到目标检测和全景分割以及对现有方法的重要改进来证明。
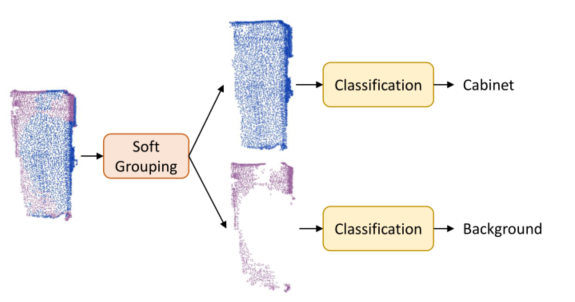
图 2:提取图1中的机柜以说明我们方法的高级管道。soft grouping模块是基于soft semantic score来输出更准确的instance(上图)。分类器处理每个实例并抑制来自错误语义预测的实例(较低的实例)。

图 3:(a)总运行时间。随着点数的增加,现有方法的运行时间显着增加。(b)组件时间。我们测量了处理约450万个点的大场景的组件时间。测量将k-NN暴露为计算瓶颈。
与我们的会议论文不同。这份手稿是我们会议版本的重要扩展,该版本之前发表于[5]。在这个更新版本中,我们进一步研究了最近3D实例分割方法的可扩展性,并揭示了k-NN的计算瓶颈。为了高效处理大规模场景,我们提出了旨在降低时间复杂度和搜索空间的SoftGroup++。Octree k-NN取代了vanilla k-NN,将时间复杂度从 O ( n 2 ) \mathcal{O}\left(n^2\right) O(n2)降低到 O ( n log n ) \mathcal{O}(n \log n) O(nlogn)。Classa-ware金字塔缩放和后期devoxelization减少了中间网络组件的搜索空间和运行时间。我们提出的方法在各种任务和数据集上进行了广泛的基准测试,证明了它的多功能性和通用性。源代码和经过训练的模型可在https://github.com/thangvubk/SoftGroup获得。
2 RELATED WORK
Deep Learning on 3D Point Clouds. 点云表示是3D场景理解的常用数据格式。为了处理点云,早期的方法[6]、[7]、[8]、[9]根据点的统计特性提取手工制作的特征。最近的深度学习方法学习从点中提取特征。基于PointNet的方法[10]、[11]提出通过共享的多层感知器(MLP)处理点,然后从对称函数(例如最大池化)聚合区域和全局特征。积极探索用于点云处理的卷积方法.连续卷积方法[12]、[13]、[14]、[15]学习与局部点的空间分布相关的内核。离散卷积方法[16]、[17]、[18]、[19]、[20]、[21]学习从点量化获得的规则网格核。还提出了Transformers[22]、[23]、[24]和基于图的方法[25]、[26]、[27]来解决点云数据的不规则性。
proposal-based Instance Segmentation. 基于proposal的方法考虑了一种自上而下的策略,该策略生成区域proposal,然后在每个proposal中分割目标。现有的基于proposal的3D点云方法在很大程度上受到Mask-R CNN[28]对2D图像的成功的影响。为了处理点云的数据不规则性,Li等人[29]提出了GSPN,它采用边分析边合成的策略来生成高目标性3Dproposal,这些proposal由基于区域的PointNet进行细化。Hou等人[30]提出了3DSIS,它将多视图RGB输入与3D几何相结合来预测边界框和实例掩码。Yang等人[4]提出了3D-BoNet,它直接输出一组没有锚点生成和非最大抑制的边界框,然后通过逐点二元分类器对目标进行分割。Liu等人[31]提出GICN将每个目标的实例中心近似为高斯分布,对其进行采样以获得目标候选,然后生成边界框和实例掩码。
Grouping-based Instance Segmentation. 基于分组的方法依赖于自下而上的管道,该管道产生每个点的预测(例如语义映射、几何位移或潜在特征),然后将点分组到实例中。Wang等人[32]提出SGPN来构建特征相似度矩阵所有点,然后将相似特征的点分组到实例中。Pham等人[33]提出了JSIS3D,它通过多值条件随机场模型结合了语义和实例标签,并联合优化标签以获得目标实例。Lahoud等人[34]提出MTML来学习特征和方向嵌入,然后对特征嵌入进行均值漂移聚类以生成目标片段,根据它们的方向特征一致性进行评分。Han等人[35]介绍了OccuSeg,它执行由目标占用信号引导的基于图的聚类,以获得更准确的分割输出。Zhang等人[36]考虑了一种概率方法,将每个点表示为三变量正态分布,然后是聚类步骤以获得目标实例。Jiang等人[1]提出PointGroup来分割原始点集和偏移偏移点集上的目标,依赖于一种简单而有效的算法,该算法将同一标签的附近点分组并逐步扩展该组。Chen等人[3]扩展了PointGroup并提出了HAIS,它进一步吸收周围的实例片段,然后基于实例内预测改进实例。Liang等人[2]SSTNet从预先计算的超点构建树网络,然后遍历树并拆分节点以获得目标实例。
Efficient Point Cloud Processing. 由于数据不规则,高效的点云处理对于从识别到压缩和重建的各种任务至关重要。Riegler等人[21]提出了一种基于八叉树的卷积网络,该网络对空间进行分层划分,以专注于具有低内存分配和计算的相关区域。Fu等人[37]提出了一种用于点云压缩的基于八叉树的注意力网络,它扩展了上下文的接受域,并利用兄弟节点及其祖先的特征来模拟大规模上下文中节点的依赖性。Xu等人[38]介绍了一种网格图卷积网络(Grid-GCN),它利用体积模型和基于点的模型的优点同时实现高效的数据结构和高效的计算。Rosu等人[39]提出了用于3D语义分割的LatticeNet,它将点特征嵌入到稀疏的全面体晶格中以实现快速卷积,同时保持低内存占用。Lombardi等人[40]还利用层级点云特征上的permutohedral lattice进行有效的点云重建。Park等人[24]提出了具有轻量级自注意力层和基于哈希的架构的Fast Point Transformer。
proposal的SoftGroup和SoftGroup++利用了基于proposal和基于分组的方法的优点。它们被构造为两阶段管道,其中自下而上阶段通过对软语义分数进行分组来生成高质量的目标proposal,然后自上而下阶段处理每个proposal以细化正样本并抑制负样本。为了有效处理大规模场景,SoftGroup++提出使用八叉树k-NN、类感知金字塔缩放和后期去体素化来降低时间复杂度和搜索空间。
3 SOFTGROUP FOR ACCURATE POINT CLOUD INSTANCE SEGMENTATION
本小节介绍SoftGroup,重点是准确性。SoftGroup的整体架构如图4所示,分为两个阶段。在自底向上分组阶段,逐点预测网络以点云为输入,产生逐点语义标签和偏移向量。软分组模块处理这些输出以产生初步的实例proposal。在自上而下的细化阶段,基于proposal,从骨干中提取相应的特征,并将其用于预测类、实例掩码和掩码分数作为最终结果。
3.1 Point-wise Prediction Network
逐点预测网络的输入是一组N个点,每个点都由其坐标和颜色表示。点集被体素化以将点转换为稀疏的体积网格,这些网格被用作U-Net风格主干[41]的输入以获得点特征。采用子流形稀疏卷积[18]来实现3D点云的U-Net。从输出骨干特征,应用输入体素化步骤的逆映射来获得点特征。然后,构造两个分支以产生逐点语义分数和偏移向量。
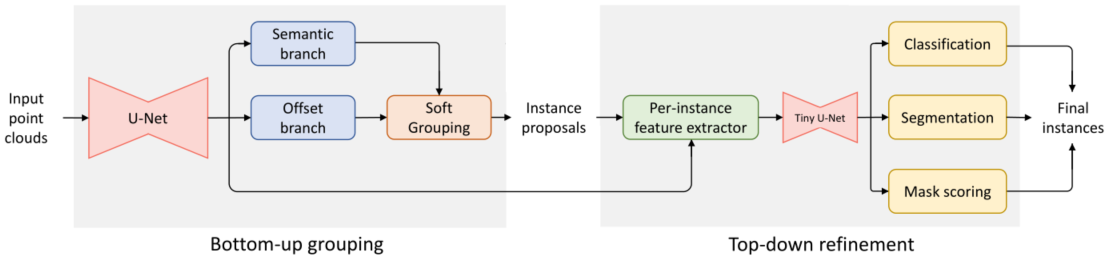
图 4:所提出方法的架构由自下而上的分组和自上而下的细化阶段组成。U-Net backbone从输入的点云中提取点特征。然后语义和偏移分支预测语义分数和偏移向量,然后是一个软分组模块来生成实例proposal。特征提取器层从实例proposal中提取骨干特征。每个proposal的特征被送入一个微型U-Net,然后是分类、分割和掩码评分分支以获得最终实例。
Semantic Branch. 语义分支由双层MLP构建,它学习输出语义分数 S = { s 1 , … , s N } ∈ R N × N class \boldsymbol{S}=\left\{\boldsymbol{s}_1, \ldots, \boldsymbol{s}_N\right\} \in \mathbb{R}^{N \times N_{\text {class }}} S={s1,…,sN}∈RN×Nclass 对于 N class N_{\text {class }} Nclass 类上的N个点。与现有方法不同[1],[3]],我们直接对语义分数进行分组,而不将它们转换为one-hot语义预测。
Offset Branch. 与语义分支并行,我们应用双层MLP来学习偏移向量 O = { o 1 , … , o N } ∈ R N × 3 \mathbf{O}=\left\{\boldsymbol{o}_1, \ldots, \boldsymbol{o}_N\right\} \in \mathbb{R}^{N \times 3} O={o1,…,oN}∈RN×3,它表示从每个点到实例几何中心的向量点所属。基于学习到的偏移向量,我们将点移动到相应实例的中心以更有效地执行分组。
交叉熵损失和 ℓ 1 \ell_1 ℓ1回归损失分别用于训练语义和偏移分支。
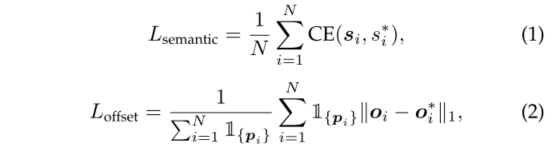
其中 s ∗ s^* s∗是语义标签, o ∗ \boldsymbol{o}^* o∗是偏移标签,表示从一个点到该点所属实例的几何中心的向量(类似于[1]、[2]、[3]),并且 1 { p i } \mathbb{1}_{\left\{\boldsymbol{p}_i\right\}} 1{pi}是指示点 p i p_i pi是否属于任何实例的指示函数。
3.2 Soft Grouping
软分组模块接收语义分数和偏移向量作为输入并生成实例proposal。首先,偏移向量用于将点移向相应的实例中心。为了使用语义分数进行分组,我们定义了一个分数阈值τ来确定一个点属于哪个语义类,允许该点与多个类相关联。给定语义分数 S ∈ R N × N class \boldsymbol{S} \in \mathbb{R}^{N \times N_{\text {class }}} S∈RN×Nclass ,我们遍历 N class N_{\text {class }} Nclass 类,并在每个类索引处切分整个场景的一个点子集,该点子集的分数(w.r.t.类索引)高于阈值 τ \tau τ。我们按照[1]、[3]对每个点子集进行分组。由于每个子集中的所有点都属于同一类,我们简单地遍历子集中的所有点并在几何距离小于分组半径r的点之间创建链接以获得实例proposal。对于每次迭代,对整个扫描的点子集执行分组,确保快速推理。整体实例proposal是来自所有子集的proposal的联合。
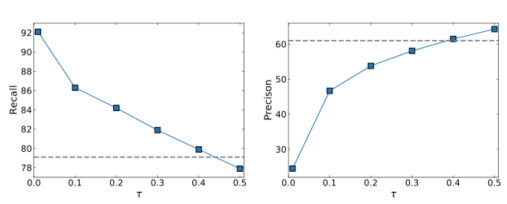
图 5:具有不同分数阈值 τ \tau τ的语义预测的召回率和准确率。虚线表示具有硬语义预测的召回率和准确率。
我们注意到现有的基于proposal的方法[4]、[30]、[31]通常将边界框视为目标proposal,然后在每个proposal中执行分割。直观上,与实例大部分重叠的边界框应该具有靠近目标中心的中心。然而,在3D点云中生成高质量的边界框proposal具有挑战性,因为该点仅存在于物体表面。相反,SoftGroup依赖于更准确的点级proposal,并且自然地继承了点云的分散特性。
我们注意到现有的基于proposal的方法[4]、[30]、[31]通常将边界框视为目标proposal,然后在每个proposal中执行分割。直观上,与实例大部分重叠的边界框应该具有靠近目标中心的中心。然而,在3D点云中生成高质量的边界框proposal具有挑战性,因为该点仅存在于物体表面。相反,SoftGroup依赖于更准确的点级proposal,并且自然地继承了点云的分散特性。
由于来自分组的实例proposal的质量高度依赖于语义分割的质量,我们定量分析了τ对语义预测的召回率和精度的影响。类j的召回率和精度定义如下。
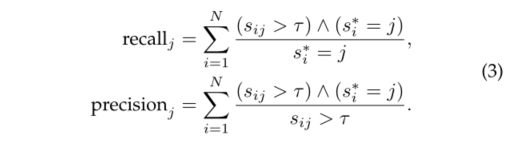
图5显示了与硬语义预测相比,具有不同分数阈值τ的召回率和精度(在类别上平均)。使用硬语义预测,召回率为79.1%,表明超过20%的点数没有被预测覆盖。当使用分数阈值时,召回率随着分数阈值的降低而增加。但是,分数阈值小也导致精度不高。我们提出了一个自上而下的细化阶段来缓解低精度问题。精度可以解释为目标实例的前景点和背景点之间的关系。我们将阈值设置为0.2,精度接近50%,从而使确保阶段的前景点和背景点之间的比例保持平衡。
3.3 Top-Down Refinement
自上而下的细化阶段对来自自下而上的分组阶段的实例proposal进行分类和细化。特征提取器层处理每个proposal以提取其相应的骨干特征。提取的特征被送入一个微型U-Net网络(具有少量层的U-Net样式网络),然后在随后的分支预测分类分数、实例掩码和掩码分数。
Classification Branch. 分类分支从一个全局平均池化层开始,聚合实例中所有点的特征,然后是一个MLP来预测分类分数 C = { c 1 , … , c K } ∈ R K × ( N class + 1 ) \boldsymbol{C}=\left\{\boldsymbol{c}_1, \ldots, \boldsymbol{c}_K\right\} \in \mathbb{R}^{K \times\left(N_{\text {class }}+1\right)} C={c1,…,cK}∈RK×(Nclass +1),其中 K K K是实例数, N class + 1 N_{\text {class }}+1 Nclass +1表示具有额外背景的 N class N_{\text {class }} Nclass 前景类。我们直接从分类分支的输出中推导出目标类别和分类置信度分数。
我们注意到现有的基于分组的方法通常从语义预测中得出目标类别。然而,实例可能来自具有嘈杂语义预测的目标。所提出的方法直接使用分类分支的输出作为实例类。分类分支聚合实例的所有点特征,并使用单个标签对实例进行分类,从而产生更可靠的预测。
Segmentation Branch. 如第3.2节所示,实例proposal包含前景点和背景点,我们构建了一个分割分支来预测每个proposal中的实例掩码。分割分支是两层的逐点MLP,它为每个实例 k k k输出一个实例掩码 m k \boldsymbol{m}_k mk。
Mask Scoring Branch. Mask评分分支与分类分支具有相同的结构。该分支输出掩码分数 E = { e 1 , … , e K } ∈ R K × N class \boldsymbol{E}=\left\{\boldsymbol{e}_1, \ldots, \boldsymbol{e}_K\right\} \in \mathbb{R}^{K \times N_{\text {class }}} E={e1,…,eK}∈RK×Nclass ,它估计预测掩码与ground truth IoU。Mask分数与分类分数相乘得到最终的置信度分数。
Learning Targets. 训练自上而下的细化分支需要每个分支的目标标签。为此,我们遵循现有2D目标检测和分割方法[28]、[42]中的逻辑。我们将所有具有IoU且ground-truth实例高于50%的instance proposals视为正样本,其余为负样本。每个正样本都被分配给具有最高IoU的ground-truth实例。正样本的分类目标是对应的groundtruth实例的分类标签。分割和掩码评分分支仅在正样本上进行训练。正样本的掩码目标是分配的地面实况实例的掩码。Mask分数目标是预测Mask和ground truth之间的IoU。这些分支的训练损失是交叉熵、二元交叉熵和 ℓ 2 \ell_2 ℓ2回归损失的组合,遵循[28]、[43]。
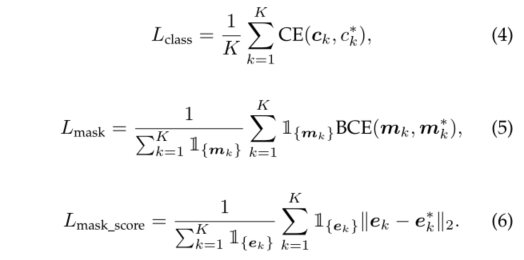
这里, c ∗ , m ∗ , e ∗ c^*, m^*, e^* c∗,m∗,e∗分别是分类、分割和掩码评分目标。 K是proposal的总数, 1 { . } \mathbb{1}_{\{.\}} 1{.}表示proposal是否是正样本。
3.4 Multi-task Learning
整个网络可以使用多任务损失以端到端的方式进行训练。
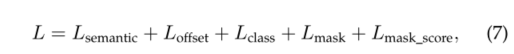
其中 L semantic L_{\text {semantic }} Lsemantic 和 L offset L_{\text {offset }} Loffset 是第3.1节中定义的语义和偏移损失,而 L class, L mask L_{\text {class, }} L_{\text {mask }} Lclass, Lmask 和KaTeX parse error: Expected 'EOF', got '_' at position 15: L_{\text {mask_̲score }}分数是第3.3节中定义的分类、分割和掩码分数损失。
4 SOFTGROUP++ FOR SCALABLE POINT CLOUD INSTANCE SEGMENTATION
为了在大规模场景上进行快速推理,SoftGroup++对SoftGroup进行了两大改进:时间复杂度和搜索空间缩减。SoftGroup++与SoftGroup的整体架构如图6所示。为了突出这两种架构之间的差异,显示了用于比较SoftGroup的相关组件(即devoxelization和vanilla k-NN)。SoftGroup++将vanilla k-NN替换为八叉树kNN,以将时间复杂度从 O ( n 2 ) \mathcal{O}\left(n^2\right) O(n2)降低到 O ( n log n ) \mathcal{O}(n \log n) O(nlogn)。此外,还提出了类感知金字塔缩放(CAPS)和后期去素化以减少搜索空间。这些改进组件是无参数的,因此可以从相同的训练模型对SoftGroup和SoftGroup++进行推理。重要的是,由于每个组件都可以接收点或体素输入,因此下一小节中的演示文稿假定使用点输入以简单起见。
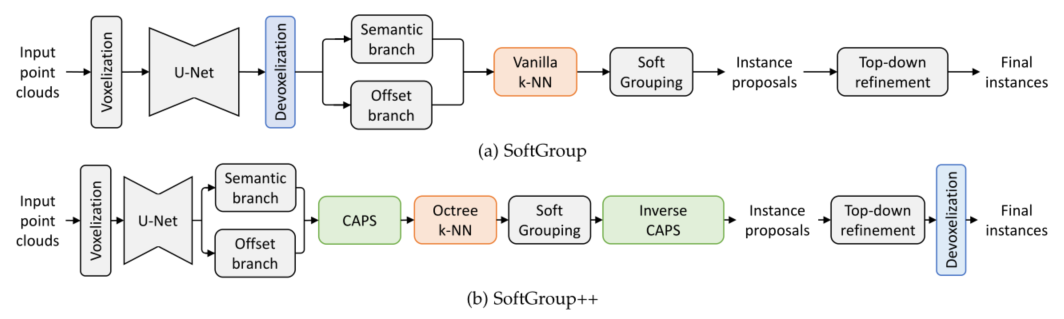
图 6:SoftGroup和SoftGroup++的架构比较。为了突出它们之间的差异,展示了SoftGroup的去体素化和香草k-NN。SoftGroup++用八叉树k-NN替换了vanilla k-NN,引入了类感知金字塔缩放(CAPS),并将体素化延迟到网络末端。
4.1 Time Complexity Reduction
Octree k-NN. 在最近的基于分组的实例分割方法[1]、[3]中,k-NN构造点邻接矩阵,作为分组的前提。为了应对变化的点密度,添加了半径约束r,使得有效邻居到查询点的距离应小于r。现有方法采用vanilla k-NN算法,需要在整个点集上评估pair-wise距离,因此该算法相对于点数的时间复杂度为 O ( n 2 ) \mathcal{O}\left(n^2\right) O(n2)。由于这种二次时间复杂度不可扩展,我们提出了时间复杂度为 O ( n log n ) \mathcal{O}(n \log n) O(nlogn)的八叉树 k-NN。
Constructing Octree. 八叉树是一种数据结构,它通过递归地将3D空间细分为八个八分圆来划分3D空间。给定一组点,我们首先导出其紧密轴对齐的边界框。然后我们递归地将3D框划分为八个子框(八分圆)。为了平衡构建和遍历时间,我们将树级别M的数量限制为一个较小的值(例如3),并将点存储在最后一个树级别(叶节点)中。
k-Nearest Neighbor Search on Octree. 给定查询点q和构造的八叉树,我们准备好使用半径搜索r对查询q执行kNN。细节在算法1中给出。该算法的核心思想是在查询附近找到一个小点子集,然后对子集而不是整个集执行vanilla k-NN。该算法从根节点开始,递归地遍历树。如果与当前节点关联的框与球体S(q,r)相交,则当前节点存在与球体S(q,r)相交的八分圆。这些八分圆被排队,然后在下一次迭代中检查。重复该过程直到叶节点。点列表P用于存储与球体S(q, r)相交的叶节点相关联的所有点。图7a说明了该算法在两层树上的结果。为了简洁起见,我们考虑四叉树,它是八叉树的二维版本。查询球体与4个叶节点框相交,其中的点被用来与查询进行k-NN。

为了构建所有点的邻接矩阵,该算法对点集的每个点执行,这需要GPU并行化以提高速度。并行化的主要挑战之一是在CUDA内核上实现递归树遍历是非常重要的。受[21]、[44]的启发,我们提出了一种使用直接索引展开和遍历树的简单策略,这样算法在每个CUDA内核上针对每个点有效地执行。为此,在构建树时,我们按照广度优先顺序对树节点进行索引,如图7b所示,给定父节点索引i,我们可以通过简单的算法直接访问其子节点:

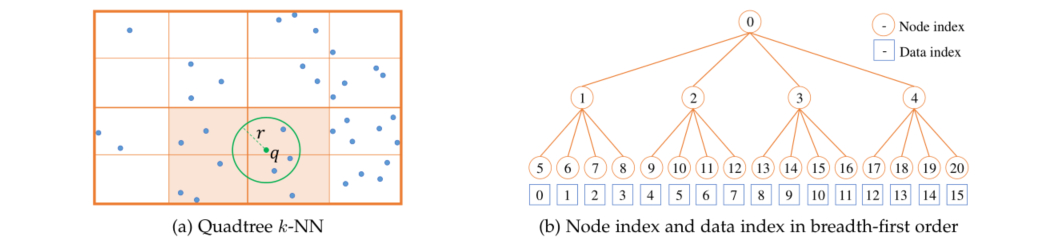
图 7:四叉树k-NN和广度优先索引的可视化。为了简洁的呈现,我们考虑二维数据的四叉树。(a)具有搜索半径r的查询q上的2级四叉树k-NN图示。有4个叶节点(以橙色背景突出显示)与查询圆相交。四叉树k-NN仅测量从查询到这些叶节点中的点的距离,而不是整个点集。(b)以广度优先顺序说明节点和数据索引。从广度优先顺序,可以展开树的递归结构,其中子节点和数据索引可以通过方程式中给出的简单算术检索。8和9使得基于树的搜索算法可以在GPU上有效地并行化。

其中chj(i)是第j个子节点的索引,d是维度(d在八叉树中为3,在四叉树中为2)。与[21]、[44]不同,我们构造了一棵完整的树,因此不需要对树结构进行编码。访问与叶节点i关联的点的数据索引可以导出为:
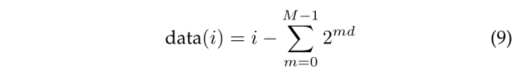
由于节点和数据索引是通过简单的算法得出的,我们可以展开递归结构并并行化八叉树k-NN,以便每个CUDA内核执行查询的算法。
4.2 Search Space Reduction
Class-Aware Pyramid Scaling. 类感知金字塔缩放(CAPS)被提出来减少k-NN和软分组模块的搜索空间。在点云处理中,常见的搜索空间缩减方法是点采样(例如,随机采样、最远点采样)和体素化。在这项工作中,采用体素化,因为使用体素化的逆映射可以简单地获得点级结果。重要的是要注意CAPS的体素化步骤独立于网络开始时的输入体素化。在深入研究所提出的CAPS之前,我们提出了一种用于减少搜索空间的朴素缩放策略。特别是,朴素的缩放策略直接对具有单个体素大小的整个场景的语义和偏移预测进行体素化。体素内点的分数/特征被平均以获得相应的体素分数/特征。该策略存在两个主要局限性:(1)由于体素化中的平均得分,一个类的分数可能会干扰其他类的分数;(2)由于不同的目标,很难选择固定的体素大小来缩小整个场景类可能有不同的目标大小。正如我们的实验(第5.4节)所表明的那样,这种策略会严重降低预测准确性。
拟议的CAPS解决了朴素缩放策略的局限性。为了避免类之间的分数干扰,所提出的CAPS是类感知的,因此对给定类的点子集执行缩减。为了应对不同类别的目标大小的变化,CAPS自适应地选择降尺度级别,使得具有更多点的目标具有更高的降尺度级别。CAPS的细节在算法2中给出。该算法遍历C类并为第i类提取语义Si和偏移量Oi子集。金字塔级别l是通过将Si中的点数与预定义阈值t进行比较来计算的。然后,Si和Oi被缩小为l × V的体素大小,其中V是基础体素大小。所有类别的缩小语义和偏移预测被聚合并用作k-NN和软分组的输入。由于自上而下的细化阶段需要相同比例的实例proposal,因此应用了称为逆CAPS的模块,其中使用CAPS中体素化的逆映射来执行逆缩放。
Late Devoxelization. 在基于体素的网络中,体素的数量通常比点的数量少得多。图8说明了不同数据集中体素和点之间的比率。体素的数量是根据表1的体素大小计算的。现有方法[1]、[2]、[3]通常执行早期去体素化,其中从体素到点的转换是在U-Net主干之后立即执行的。值得注意的是,体素内的所有点在去体素化后共享相同的值。早期去体素化导致对相同输入的重复计算,因此随后的模块以高计算成本运行。为了解决这个问题,这项工作建议延迟从体素到点的转换,直到网络结束,这被称为后期去体素化。后期去素化消除了计算重复并减少了中间网络组件的输入大小,从而提高了速度。后期去素化的有效性可以通过体素点比来预测。图8表明后期devoxelization在S3DIS上最有效。
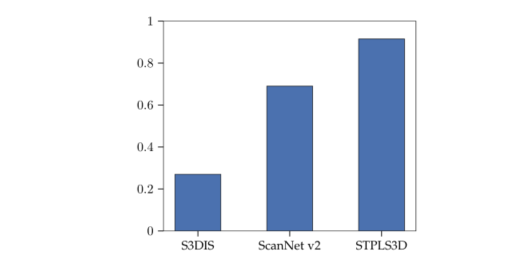
图 8:体素和点之间的比率。
6 CONCLUSION
我们展示了SoftGroup及其扩展的SoftGroup++,用于在 3D 点云上进行准确且可扩展的实例分割。SoftGroup对软语义分数进行分组,以解决源于对局部模糊目标的硬分组的问题。然后构造一个自上而下的细化阶段来细化正样本并抑制负样本。为了高效处理大规模场景,引入了SoftGroup++以实现低时间复杂度和搜索空间。 Octree k-NN取代了vanilla k-NN,将时间复杂度从
O
(
n
2
)
\mathcal{O}\left(n^2\right)
O(n2)降低到
O
(
n
log
n
)
\mathcal{O}(n \log n)
O(nlogn)。
类感知金字塔缩放和后期去素化减少了中间组件的搜索空间和运行时间。
在各种数据集上进行的大量实验证明了我们方法的优越性和通用性。
原文链接:https://arxiv.org/pdf/2209.08263.pdf

[47] M. Chen, Q. Hu, T. Hugues, A. Feng, Y . Hou, K. McCullough, and L. Soibelman, “Stpls3d: A large-scale synthetic and real aerial photogrammetry 3d point cloud dataset,” arXiv:2203.09065, 2022.
[48] J. Behley , M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 9297–9307.
[49] A. Kirillov , K. He, R. Girshick, C. Rother, and P . Dollár, “Panoptic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[50] L. Porzi, S. R. Bulo, A. Colovic, and P . Kontschieder, “Seamless scene segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[51] A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differentiation in pytorch,” in Neural Information Processing Systems (NeurIPS)-W, 2017.
[52] D. P . Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations (ICLR), 2015.
[53] I. Loshchilov and F. Hutter, “Sgdr: Stochastic gradient descent with warm restarts,” in International Conference on Learning Representations (ICLR), 2017.
[54] C. Liu and Y . Furukawa, “Masc: Multi-scale affinity with sparse convolution for 3d instance segmentation,” arXiv:1902.04478, 2019.
[55] G. Narita, T. Seno, T. Ishikawa, and Y . Kaji, “Panopticfusion: Online volumetric semantic mapping at the level of stuff and things,” arXiv:1903.01177, 2019.
[56] F. Engelmann, M. Bokeloh, A. Fathi, B. Leibe, and M. Nießner, “3d-mpa: Multi-proposal aggregation for 3d semantic instance segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[57] T. He, C. Shen, and A. van den Hengel, “Dyco3d: Robust instance segmentation of 3d point clouds through dynamic convolution,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[58] B. Zhang and P . Wonka, “Point cloud instance segmentation using probabilistic embeddings,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[59] X. Wang, S. Liu, X. Shen, C. Shen, and J. Jia, “Associatively segmenting instances and semantics in point clouds,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[60] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[61] C. R. Qi, O. Litany , K. He, and L. J. Guibas, “Deep hough voting for 3d object detection in point clouds,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[62] A. Milioto, I. Vizzo, J. Behley , and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
[63] A. H. Lang, S. V ora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
[64] S. Shi, C. Guo, L. Jiang, Z. Wang, J. Shi, X. Wang, and H. Li, “Pvrcnn: Point-voxel feature set abstraction for 3d object detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
[65] A. Milioto, J. Behley , C. McCool, and C. Stachniss, “Lidar panoptic segmentation for autonomous driving,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020.
[66] S. Gasperini, M.-A. N. Mahani, A. Marcos-Ramiro, N. Navab, and F. Tombari, “Panoster: End-to-end panoptic segmentation of lidar point clouds,” IEEE Robotics and Automation Letters, 2021.
[67] M. Aygun, A. Osep, M. Weber, M. Maximov , C. Stachniss, J. Behley , and L. Leal-Taixé, “4d panoptic lidar segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[68] Z. Zhou, Y . Zhang, and H. Foroosh, “Panoptic-polarnet: Proposalfree lidar point cloud panoptic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[69] F. Hong, H. Zhou, X. Zhu, H. Li, and Z. Liu, “Lidar-based panoptic segmentation via dynamic shifting network,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[70] A. Kirillov , R. Girshick, K. He, and P . Dollár, “Panoptic feature pyramid networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.