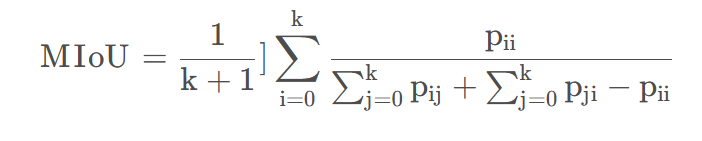目录:语义分割
- 一、什么是语义分割
- 二、什么是图像中的语义信息?
- 三、语义分割中的上下文信息
- 四、语义分割方法
- 五、语义分割神经网络
- 六、目前比较经典的网络
- 七、评价指标
一、什么是语义分割
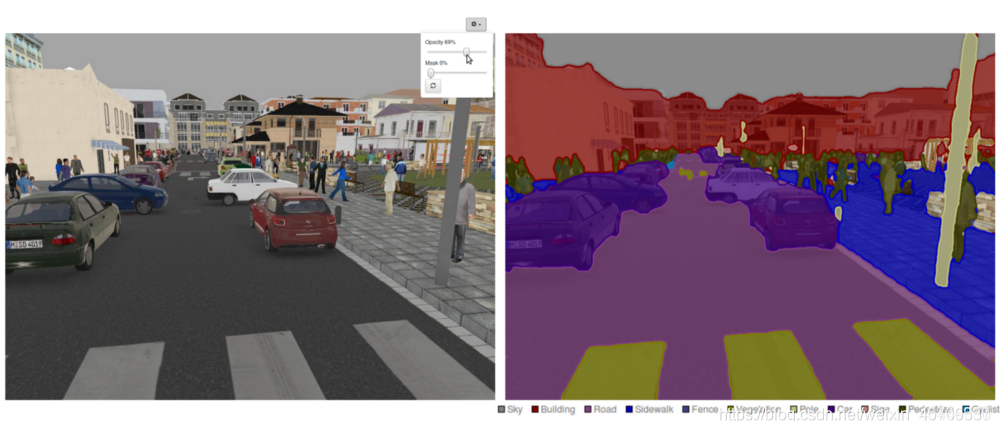
语义分割,也称为像素级分类问题,其输出和输入分辨率相同(如题图中,左边为2048x1024分辨率的Cityscapes街景图像,输入模型,得到右边同样分辨率的语义图)。
由此,语义分割具有两大需求,即高分辨率和高层语义,而这两个需求和卷积网络设计是矛盾的。
语义分割通过对输入图像中每个像素的标签进行预测,给出了较好的推理,例如是前景还是背景。每个像素都根据其所在的对象类进行标记。
通俗且具体到实际图像上来说,语义分割其实就是对于细化版的分类,就是对于一张图像上说,传统的图像分类是把图像中出现的物体进行检测并识别是属于什么类别的,也就是对于一整张图片进行分类。那么现在就有人想对于图中每一个像素点都进行分类。
与分类不同的是,深度网络的最终结果是唯一重要的,语义分割不仅需要在像素级别上进行区分,而且还需要一种机制将编码器不同阶段学习到的区分特征投影到像素空间上。
二、什么是图像中的语义信息?
处理的那个单元和周围单元的意思。
从自然语言处理的角度,上下文就是指一个单词与其周围单词之间的关联。
图像的语义分为视觉层、对象层和概念层。
视觉层即通常所理解的底层,即颜色、纹理和形状等等,这些特征都被称为底层特征语义;对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;概念层是高层,是图像表达出的最接近人类理解的东西。
通俗点说,比如一张图上有沙子,蓝天,海水等,视觉层是一块块的区分,对象层是沙子、蓝天和海水这些,概念层就是海滩,这是这张图表现出的语义。
三、语义分割中的上下文信息
上下文信息也可以被叫做上下文特征。
上下文这个概念听起来有点像是在自然语言处理的时候会用到的一个概念,我们平时在做文章阅读的时候也会遇到这个单词。
但是,随着深度学习领域不断地发展,许多深度学习研究者都尝试着把NLP的处理方式应用到CV的处理上,同时CV的处理方式也应用到NLP上,所以图像和语言处理两家的边界能够被一些理论所连接起来。
故我们可以把一些NLP中的概念代入到CV领域中能够帮助我们去解释一些现象。
上下文: 上下文指的是图像中的每一个像素点不可能是孤立的,一个像素一定和周围像素是有一定的关系的,大量像素的互相联系才产生了图像中的各种物体,所以上下文特征就指像素以及周边像素的某种联系。
具体到图像语义分割,一般论文会说我们的XXX算法充分结合了上下文信息,意思也就是在判断某一个位置上的像素属于哪种类别的时候,不仅考察到该像素的灰度值,还充分考虑和它临近的像素。
对其再次解释可以理解为图像中该像素点的像素值与它周围的一些像素是具有一定的关系的,也就是说分割领域中是靠上下文信息来联系像素点之间的关系。因为图像是由像素点组成的,当图像上某个特定区域上的像素点产生了联系,这个区域在图像上就突出出来了,这个区域现在就是这个图像上独一为二的区域,也相当于从图像上分割出来了。
所以上下文信息其实就是描述像素点之间的关联/关系的。所以我们对每个像素点进行分类之后根据像素点的类别去找这样的上下文信息,而类别信息就是作为图像上的语义信息。
其实感觉这样说还是有点模糊,毕竟个人认为上下文是一个没有公式定义的东西,更多的还是一种理念,像条件随机场,就是一种充分考虑了上下文信息的代表,局部连接的CRF只考虑局部上下文,全连接CRF考虑了全局上下文。
四、语义分割方法
常用的深度学习的语义分割主要有两种方法:
深度学习方法一般都是在分类网络上进行精调,分类网络为了能获取更抽象的特征分层,采取了Conv+pool堆叠的方式,这导致了分辨率降低,丢失了很多信息,这对分割任务来说肯定是不好的,因为分割是对每一个像素进行分类,会造成定位精度不高。但同时更高层的特征对于分类又很重要。
encoder-decoder方法:与经典的FCN中的skip-connection思想类似,encoder为分类网络,用于提取特征,而decoder则是将encoder的先前丢失的空间信息逐渐恢复,decoder的典型结构有U-Net/segnet/refineNet,该类方法虽然有一定的效果,能恢复部分信息,但毕竟信息已经丢失了,不可能完全恢复。dialed FCN方法:deeplabv1提出的方法,将vgg的最后的两个pool层步长置为1,这样网络的输出分辨率从1/32变为1/8。可以保留更多的细节信息,同时也丢掉了复杂的decoder结构,但这种方法计算量大。
五、语义分割神经网络
对于语义分割而言,正如开头所说,输入和输出的图像分辨率必须相同,所以一般流程先会是先经过多个下采样层(一般为5个,输出原图1/32的特征图),从而逐步扩大视野获取高层语义特征 ,高层语义特征靠近输出端但分辨率低,高分率特征靠近输入端但语义层次低。
高层特征和底层特征都有各自的弱点,各自的分割问题如下图所示,第二行高层特征的分割结果保持了大的语义结构,但小结构丢失严重;第三行低层特征的分割结果保留了丰富的细节,但语义类别预测的很差。
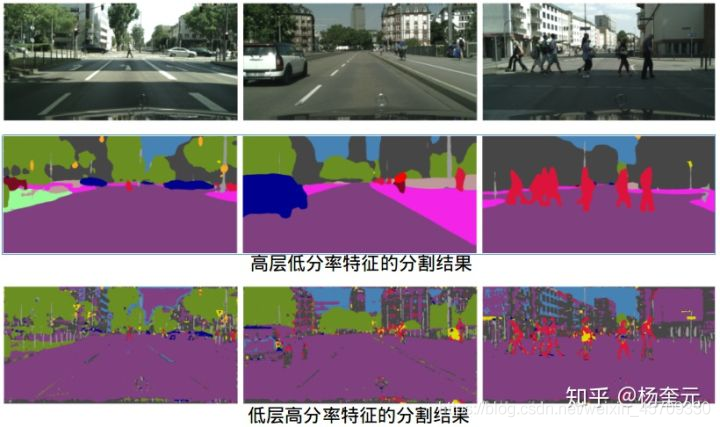
所以,我们就很自然可以想到将不同层的特征进行融合,取长补短,分割经典工作FCN和U-Net均采用了这个策略,目标检测中常用的特征金字塔网络(FPN) 也是采用了该策略。
目前比较主流的特征融合方式主要有两类:
- 一类是FPN(先自下而上获取高层语义特征,再自上而下逐步采样高层语义特征,并融合对应分辨率的下层特征。)
- 另一类是HRNet(自下而上包含多个分辨率通路,不同分辨率特征在自下而上过程中及时进行融合。)
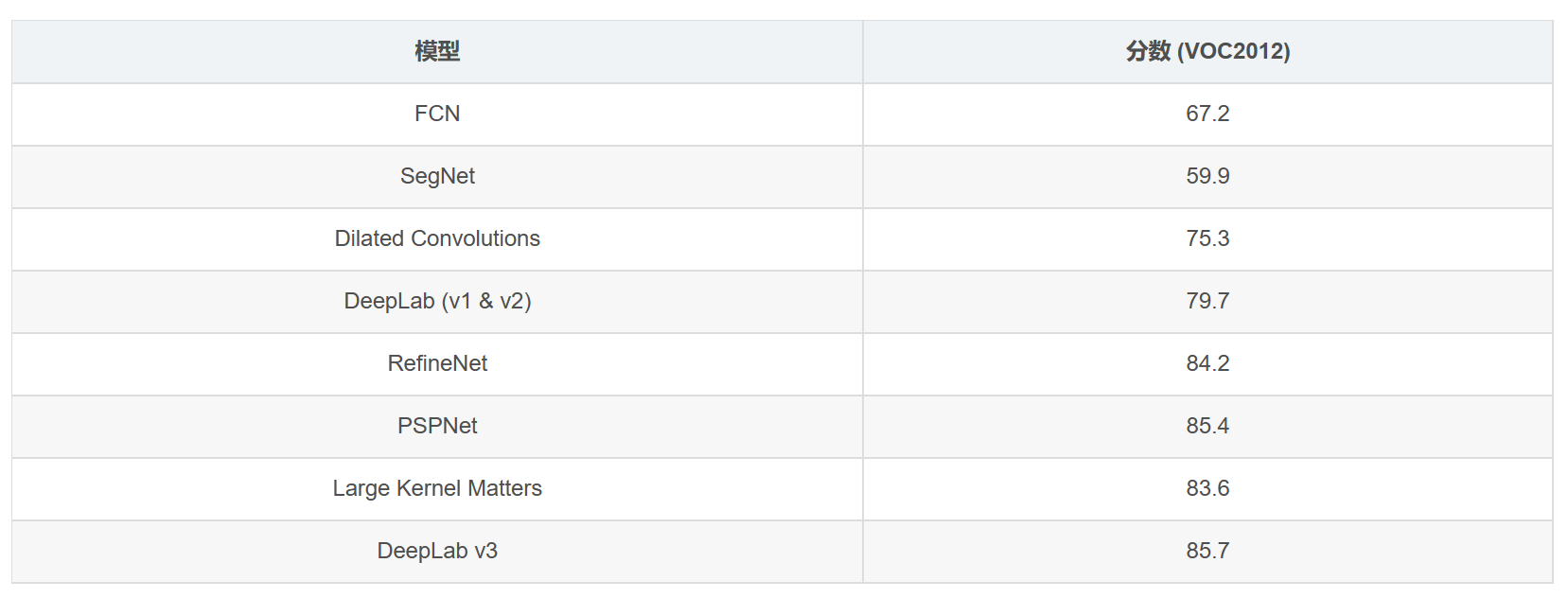
六、目前比较经典的网络
七、评价指标
可以从以下几个指标评价某个分割算法的好坏:
- mIoU:这个指标是应用最多的,也是目前排名分割算法的依据。IoU就是每一个类别的交集与并集之比,而mIoU则是所有类别的平均IoU。论文均使用这一指标比较。
- speed:由于有些分割算法是针对实时语义分割设计的,所以速度也是一个很重要的评价指标,当然评价速度需要公平比较,包括使用的图像大小、电脑配置一致。
- 当然还有其他指标,如pixel accuracy(PA)、mean accuraccy(MA) 等。
MIOU: