【Kafka】Java实现数据的生产和消费
Kafka介绍
Kafka 是由 Linkedin 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
Kafka 有如下特性:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能;
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输;
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输;
- 同时支持离线数据处理和实时数据处理;
- Scale out:支持在线水平扩展。
Kafka术语
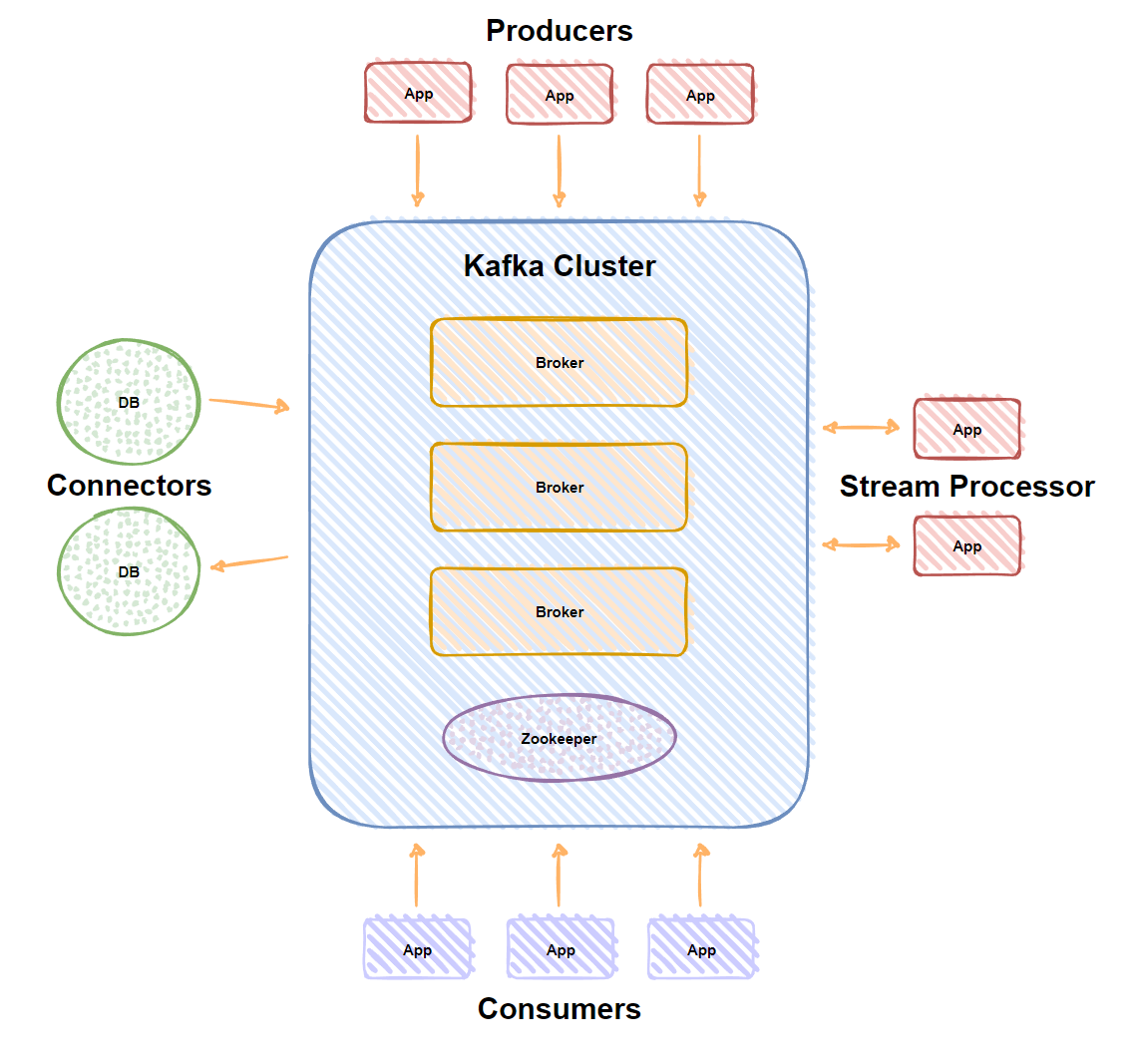
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker;
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处);
- Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition;
- Producer:负责发布消息到Kafka broker;
- Consumer:消息消费者,向Kafka broker读取消息的客户端;
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Kafka特性
高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒;高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 的数据能够持久存储;容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;高并发: 支持数千个客户端同时读写。
Kafka应用场景
- 活动跟踪:Kafka 可以用来
跟踪用户行为,比如你经常回去App购物,你打开App的那一刻,你的登陆信息,登陆次数都会作为消息传输到 Kafka ,当你浏览购物的时候,你的浏览信息,你的搜索指数,你的购物爱好都会作为一个个消息传递给 Kafka ,这样就可以生成报告,可以做智能推荐,购买喜好等; - 传递消息:Kafka 另外一个基本用途是
传递消息,应用程序向用户发送通知就是通过传递消息来实现的,这些应用组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何发送的; - 度量指标:Kafka也经常
用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告; - 日志记录:Kafka 的基本概念来源于提交日志,比如可以把数据库的更新发送到 Kafka 上,用来记录数据库的更新时间,通过Kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等;
- 流式处理:流式处理是有一个能够提供多种应用程序的领域;
- 限流削峰:Kafka 多用于互联网领域某一时刻请求特别多的情况下,可以把请求写入Kafka 中,避免直接请求后端程序导致服务崩溃。
以上介绍参考Kafka官方文档。
Kafka核心Api
Kafka有4个核心API
- 应用程序使用producer API发布消息到
1个或多个topic中; - 应用程序使用consumer API来订阅
1个或多个topic,并处理产生的消息; - 应用程序使用streams API充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个topic,有效地将输入流转换到输出流;
- connector API允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。
Kafka为何如此之快
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费。
总结一下其实就是四个要点:
- 顺序读写
- 零拷贝
- 消息压缩
- 分批发送
案例
项目创建:
dependencies:

构建工具为Maven,Maven的依赖如下:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.0.0</version>
</dependency>
Kafka Producer
package cn.com.codingce.module;
import java.util.Properties;
import java.util.Random;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
public class Producer {
// 定义主题
public static String topic = "codingce_test";
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
// bootstrap.servers: kafka的地址, 多个地址用逗号分割
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.150:9092");
// acks:消息的确认机制,默认值是0. acks=0: 如果设置为0,生产者不会等待kafka的响应; acks=1: 这个配置意味着kafka会把这条消息写到本地日志文件中,但是不会等待集群中其他机器的成功响应
// acks=all: 这个配置意味着leader会等待所有的follower同步完成. 这个确保消息不会丢失, 除非kafka集群中所有机器挂掉. 这是最强的可用性保证.
p.put("acks", "all");
// retries: 配置为大于0的值的话, 客户端会在消息发送失败时重新发送.
p.put("retries", 0);
// batch.size: 当多条消息需要发送到同一个分区时,生产者会尝试合并网络请求. 这会提高client和生产者的效率.
p.put("batch.size", 16384);
// key.serializer: 键序列化,默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// value.deserializer:值序列化,默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p);
try {
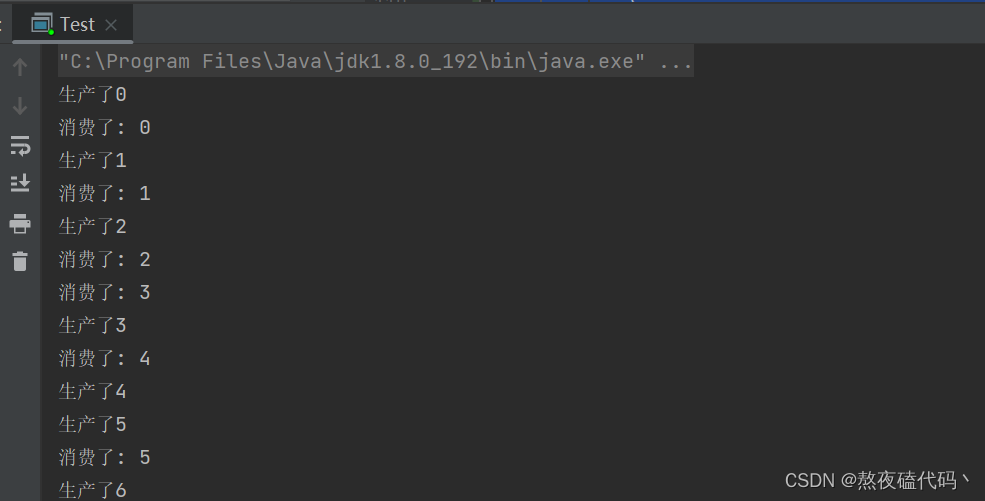
do {
String msg = "后端码匠, " + new Random().nextInt(100);
ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg);
kafkaProducer.send(record);
System.out.println("======消息发送成功: " + msg + " ======");
Thread.sleep(1000L);
} while (true);
} finally {
kafkaProducer.close();
}
}
}
Kafka Consumer
package cn.com.codingce.module;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.util.Collections;
import java.util.Properties;
public class Consumer {
private static final String GROUPID = "codingce_consumer_a";
public static void main(String[] args) {
Properties p = new Properties();
// bootstrap.servers: kafka的地址, 多个地址用逗号分割
p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.150:9092");
// 消费者所属的分组id, 组名 不同组名可以重复消费.例如你先使用了组名A消费了Kafka的1000条数据, 但是你还想再次进行消费这1000条数据,
// 并且不想重新去产生, 那么这里你只需要更改组名就可以重复消费了.
p.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);
// 是否自动提交, 默认为true.
p.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 从poll(拉)的回话处理时长
p.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 超时时间
p.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
// 一次最大拉取的条数
p.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);
// 消费规则, 默认earliest
p.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// key.serializer: 键序列化, 默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// value.deserializer:值序列化, 默认org.apache.kafka.common.serialization.StringDeserializer.
p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(p);
// 订阅消息
kafkaConsumer.subscribe(Collections.singletonList(Producer.topic));
do {
// 订阅之后, 再从kafka中拉取数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("-----topic:%s, offset:%d, 消息:%s-----\n", record.topic(), record.offset(), record.value());
}
} while (true);
}
}
本次采用Docker 搭建的单机 Kafka、Zookeeper,Kafka介绍参考官方文档:http://kafka.apache.org/intro