一、视图
1.1 简介
Hive 中的视图和 RDBMS 中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条 SELECT 语句的结果集。视图是纯粹的逻辑对象,没有关联的存储 (Hive 3.0.0 引入的物化视图除外),当查询引用视图时,Hive 可以将视图的定义与查询结合起来,例如将查询中的过滤器推送到视图中。
1.2 创建视图
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name -- 视图名称
[(column_name [COMMENT column_comment], ...) ] --列名
[COMMENT view_comment] --视图注释
[TBLPROPERTIES (property_name = property_value, ...)] --额外信息
AS SELECT ...;
在 Hive 中可以使用 CREATE VIEW 创建视图,如果已存在具有相同名称的表或视图,则会抛出异常,建议使用 IF NOT EXISTS 预做判断。在使用视图时候需要注意以下事项:
-
视图是只读的,不能用作 LOAD / INSERT / ALTER 的目标;
-
在创建视图时候视图就已经固定,对基表的后续更改(如添加列)将不会反映在视图;
-
删除基表并不会删除视图,需要手动删除视图;
-
视图可能包含 ORDER BY 和 LIMIT 子句。如果引用视图的查询语句也包含这类子句,其执行优先级低于视图对应字句。例如,视图
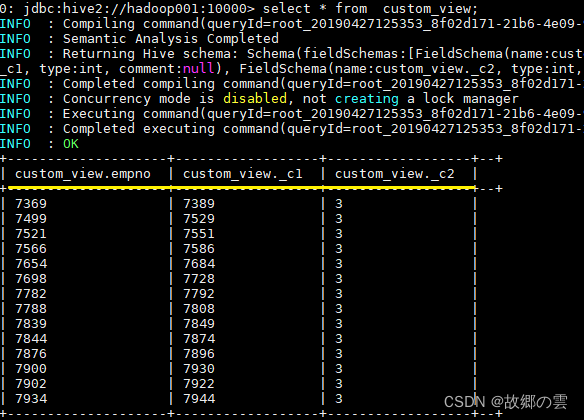
custom_view指定 LIMIT 5,查询语句为select * from custom_view LIMIT 10,此时结果最多返回 5 行。 -
创建视图时,如果未提供列名,则将从 SELECT 语句中自动派生列名;
-
创建视图时,如果 SELECT 语句中包含其他表达式,例如 x + y,则列名称将以_C0,_C1 等形式生成;
CREATE VIEW IF NOT EXISTS custom_view AS SELECT empno, empno+deptno , 1+2 FROM emp;
1.3 查看视图
-- 查看所有视图: 没有单独查看视图列表的语句,只能使用 show tables
show tables;
-- 查看某个视图
desc view_name;
-- 查看某个视图详细信息
desc formatted view_name;
1.4 删除视图
DROP VIEW [IF EXISTS] [db_name.]view_name;
删除视图时,如果被删除的视图被其他视图所引用,这时候程序不会发出警告,但是引用该视图其他视图已经失效,需要进行重建或者删除。
1.5 修改视图
ALTER VIEW [db_name.]view_name AS select_statement;
被更改的视图必须存在,且视图不能具有分区,如果视图具有分区,则修改失败。
1.6 修改视图属性
语法:
ALTER VIEW [db_name.]view_name SET TBLPROPERTIES table_properties;
table_properties:
: (property_name = property_value, property_name = property_value, ...)
示例:
ALTER VIEW custom_view SET TBLPROPERTIES ('create'='heibaiying','date'='2019-05-05');
二、索引
2.1 简介
Hive 在 0.7.0 引入了索引的功能,索引的设计目标是提高表某些列的查询速度。如果没有索引,带有谓词的查询(如’WHERE table1.column = 10’)会加载整个表或分区并处理所有行。但是如果 column 存在索引,则只需要加载和处理文件的一部分。
2.2 索引原理
在指定列上建立索引,会产生一张索引表(表结构如下),里面的字段包括:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的 HDFS 文件路径及偏移量,这样就避免了全表扫描。
+--------------+----------------+----------+--+
| col_name | data_type | comment |
+--------------+----------------+----------+--+
| empno | int | 建立索引的列 |
| _bucketname | string | HDFS 文件路径 |
| _offsets | array<bigint> | 偏移量 |
+--------------+----------------+----------+--+
2.3 创建索引
CREATE INDEX index_name --索引名称
ON TABLE base_table_name (col_name, ...) --建立索引的列
AS index_type --索引类型
[WITH DEFERRED REBUILD] --重建索引
[IDXPROPERTIES (property_name=property_value, ...)] --索引额外属性
[IN TABLE index_table_name] --索引表的名字
[
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
] --索引表行分隔符 、 存储格式
[LOCATION hdfs_path] --索引表存储位置
[TBLPROPERTIES (...)] --索引表表属性
[COMMENT "index comment"]; --索引注释
2.4 查看索引
--显示表上所有列的索引
SHOW FORMATTED INDEX ON table_name;
2.4 删除索引
删除索引会删除对应的索引表。
DROP INDEX [IF EXISTS] index_name ON table_name;
如果存在索引的表被删除了,其对应的索引和索引表都会被删除。如果被索引表的某个分区被删除了,那么分区对应的分区索引也会被删除。
2.5 重建索引
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD;
重建索引。如果指定了 PARTITION,则仅重建该分区的索引。
三、索引案例
3.1 创建索引
在 emp 表上针对 empno 字段创建名为 emp_index,索引数据存储在 emp_index_table 索引表中
create index emp_index on table emp(empno) as
'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
with deferred rebuild
in table emp_index_table ;
此时索引表中是没有数据的,需要重建索引才会有索引的数据。
3.2 重建索引
alter index emp_index on emp rebuild;
Hive 会启动 MapReduce 作业去建立索引,建立好后查看索引表数据如下。三个表字段分别代表:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。

3.3 自动使用索引
默认情况下,虽然建立了索引,但是 Hive 在查询时候是不会自动去使用索引的,需要开启相关配置。开启配置后,涉及到索引列的查询就会使用索引功能去优化查询。
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
SET hive.optimize.index.filter=true;
SET hive.optimize.index.filter.compact.minsize=0;
3.4 查看索引
SHOW INDEX ON emp;

四、索引的缺陷
索引表最主要的一个缺陷在于:索引表无法自动 rebuild,这也就意味着如果表中有数据新增或删除,则必须手动 rebuild,重新执行 MapReduce 作业,生成索引表数据。
同时按照官方文档 的说明,Hive 会从 3.0 开始移除索引功能,主要基于以下两个原因:
- 具有自动重写的物化视图 (Materialized View) 可以产生与索引相似的效果(Hive 2.3.0 增加了对物化视图的支持,在 3.0 之后正式引入)。
- 使用列式存储文件格式(Parquet,ORC)进行存储时,这些格式支持选择性扫描,可以跳过不需要的文件或块。