1.一条 update 语句的执行流程
一条更新语句,其实是增,删,查的综合体,查询语句需要经过的流程,更新语句全部需要执行一次,因为更新之前必须要先拿到(查询)需要更新的数据。
Buffer Pool
InnnoDB 的数据都是放在磁盘上的,而磁盘的速度和 CPU 的速度之间有难以逾越的鸿沟,为了提升效率,就引入了缓冲池技术,在 InnoDB 中称之为 Buffer Pool。
从磁盘中读取数据的时候,会先将从磁盘中读取到的页放在缓冲池 Buffer Pool 中,这样下次读相同的页的时候,就可以直接从 Buffer Pool 中获取。
更新数据的时候首先会看数据在不在缓冲池中,在的话就直接修改缓冲池中的数据。注意,前提是我们不需要对这条数据进行唯一性检查(因为如果要进行唯一性检查就必须加载磁盘中的数据来判断是否唯一了)。
如果只修改了 Buffer Pool 中的数据而不修改磁盘中数据,这时候就会造成内存和磁盘中数据不一致,这种也叫做脏页。InnoDB 里面有专门的后台线程把 Buffer Pool 的数据写入到磁盘, 每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
那么现在有一个问题,假如我们更新都需要把数据写入数据磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高。为了解决这个问题,InnoDB 就有了 redo log,并且采用了 Write-Ahead Logging(WAL) 方案来实现。
2.redo log
redo log,即重做日志,是 InnoDB 引擎所特有,主要用于崩溃修复(crash-safe)。
举个例子,读书的时候我们听课会做笔记,而做笔记的目的就是为了忘了之后可以复习, redo log 的作用也是一样,一旦 MySQL 因为异常宕机,就可以利用 redo log 进行恢复。
Write-Ahead Logging(WAL)
Write-Ahead Logging,即日志先行,也就是说我们执行一个操作的时候会先将操作写入日志,然后再写入数据磁盘,那么有人就会问了,写入数据表是磁盘操作,写入 redo log 也是磁盘操作,同样都是写入磁盘,为什么不直接写入数据,而要先写入日志呢?这不是多此一举吗?
设想一下,假如我们所需要的数据是随机分散在不同页的不同扇区中,那么我们去找数据的时候就是随机 IO 操作,而redo log 是循环写入的,也就是顺序 IO。
一句话:刷盘是随机 I/O,而记录日志是顺序 I/O,顺序 I/O 效率更高。因此先把修改写入日 志,可以延迟刷盘时机,进而提升系统吞吐量。
redo log 如何刷盘
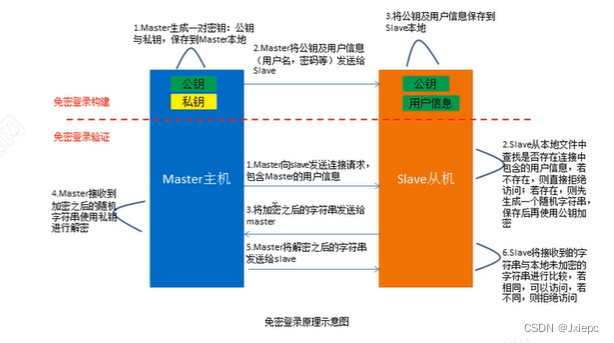
nnoDB 中的 redo log 是固定大小的,也就是说 redo log 并不是随着文件写入慢慢变大,而是一开始就分配好了空间,空间一旦写满了,前面的空间就会被覆盖掉,刷盘的操作是通过 Checkpoint 实现的。如下图:
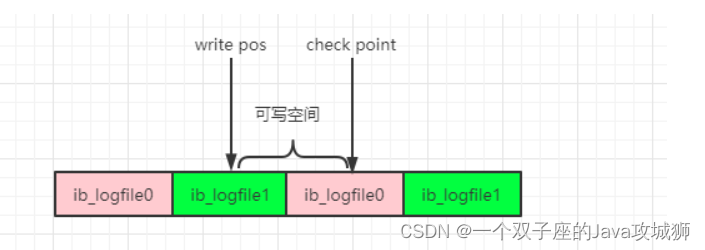
check point 是当前要覆盖的位置。write pos 是当前写入日志的位置。写日志的时候是循环写的,覆盖旧记录前要把记录更新到数据文件。如果 write pos 和 check point 重叠,说明 redo log 已经写满,这时候需要强制将 redo log 中的数据刷到磁盘中。
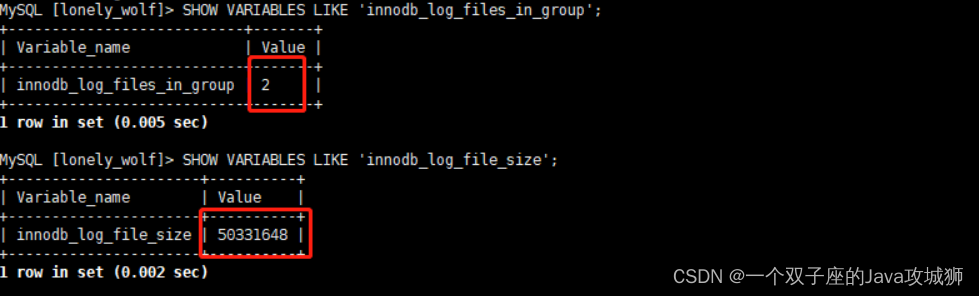
上图中粉红色的其实是一个文件,绿色的也是一个文件,这里其实画成一个圆形会更形象,因为数据是循环写的,默认配置下 redo log 有两个文件,每个文件大小是 48MB,可以通过以下两个变量控制:
SHOW VARIABLES LIKE 'innodb_log_files_in_group'; -- 设置redo log文件个数
SHOW VARIABLES LIKE 'innodb_log_file_size';-- 设置每个文件的大小
3.bin log
上面讲的 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志),也叫做二进制日志。
可能有人会问,为什么会有两份日志呢? 因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 是不支持事务的,也没有崩溃恢复(crash-safe)的能力,binlog 日志只能用于归档。那么既然 InnoDB 需要支持事务,那么就必须要有崩溃恢复(crash-safe)能力,所以就使用另外一套自己的日志系统,也就是 redo log。
bin log 和 redo log 的区别
-
redo log 是 InnoDB 引擎特有的,而 binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
-
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”,而 binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 id=2 这一行的 c 字段加 1 ”。
-
redo log 是循环写的,空间固定会用完,而 binlog 是可以追加写入的。“追加写”是指 binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
4.update 语句的执行流程
前面铺垫了这么多,主要是想让大家先理解 redo log 和 bin log 这两个概念,因为更新操作离不开这两个日志文件,接下来我们正式回到正题,一条 update 语句到底是如何执行的,可以通过下图表示:
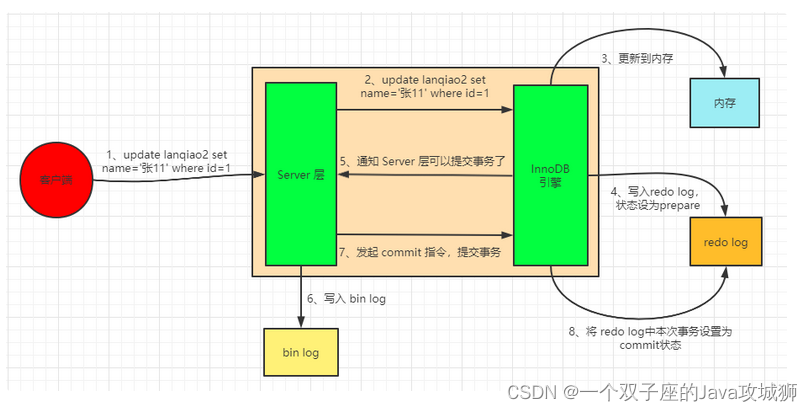
上图可以大概概括为以下几步:
-
先根据更新语句的条件,查询出对应的记录,如果有缓存,也会用到缓存。
-
Server 层调用 InnoDB 引擎的 API 接口,InnoDB 引擎将这条数据写到内存,同时写入 redo log,并将redo log 状态设置为 prepare。
-
通知 Server 层,可以正式提交数据了。
-
Server 层收到通知后立刻写入 bin log,然后调用 InnoDB 对应接口发出 commit 请求。
-
InnoDB 收到 commit 请求后将数据设置为 commit 状态,完成此时事务。
上面的步骤中,我们注意到,redo log 会经过两次提交,这就是两阶段提交法。
5.两阶段提交
两阶段提交是分布式事务的设计思想,就是首先会有请求方发出请求到各个服务器,然后等其他各个服务器都准备好之后再通知请求方可以提交了,请求方收到请求后再发出指令,通知所有服务器一起提交。
而我们这里 redo log 是属于存储引擎层的日志,bin log 是属于 Server 层日志,属于两个独立的日志文件,采用两阶段提交就是为了使两个日志文件逻辑上保持一致。
假如不采用两阶段提交法
假如有一条数据 id=1,name=张1,我们现在要把这条数据的 name 更新为 张11:
- 先写 redo log 后写 bin log:
假设在 redo log 写完,binlog 还没有写完的时候,MySQL 发生了宕机。重启后因为 redo log 写完了,所以会自动进行数据恢复,也就是 张11。但是由于 binlog 没写完就宕机(了,这时候 bin log 里面就没有记录这个语句。然后某一天假如我们把数据丢失了,需要用 bin log 进行数据恢复就会发现少了这一次更新。
- 先写 bin log 后写 redo log:
假如在 binlog 写完,redo log 还没有写完的时候,MySQL 发生了宕机。重启后因为 redo log 没写完,所以无法进行自动恢复,那么数据就还是 name=张1 了,然后某一天假如我们把数据丢失了,需要用 bin log 进行恢复又会发现恢复出来的数据 name=张11 了。
通过以上的两个假设我们就会发现,假如不采用两阶段提交法就会出现数据不一致的情况,尤其是在有主从库的时候,因为主从复制是基于 binlog 实现的,如果 redo log 和 bin log 不一致,就会导致主从库数据不一致。
宕机后的数据恢复规则
采用两阶段提交后,假如数据库发生宕机,那么会遵循以下两条规则进行数据恢复:
-
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交。
-
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 bin log是否存在并完整:如果是,则提交事务;否则,回滚事务。