目录儿
- 一、计算机组成
- 二、进程与线程
- 2.1 线程的切换
- 2.2 CPU的并发控制
- 2.2.1 关中断
- 2.2.2 缓存一致性协议
- 2.2.2.1 缓存Cache
- 2.2.2.2 缓存行Cache Line
- 2.2.2.3 缓存一致性
- 拓展:超线程
- 2.2.3 内存屏障
- 2.2.3.1 CPU的乱序执行
- 拓展1:java 的 this 溢出问题
- 拓展2:双重检查锁DCL的bug
- 2.2.3.2 Java 中防止指令重排
- 禁止编译器乱序
- 使用内存屏障阻止指令乱序执行
- JVM中的内存屏障
- volatile的实现细节
- 2.2.4 总线锁、缓存锁
一、计算机组成
计算机组成简示:
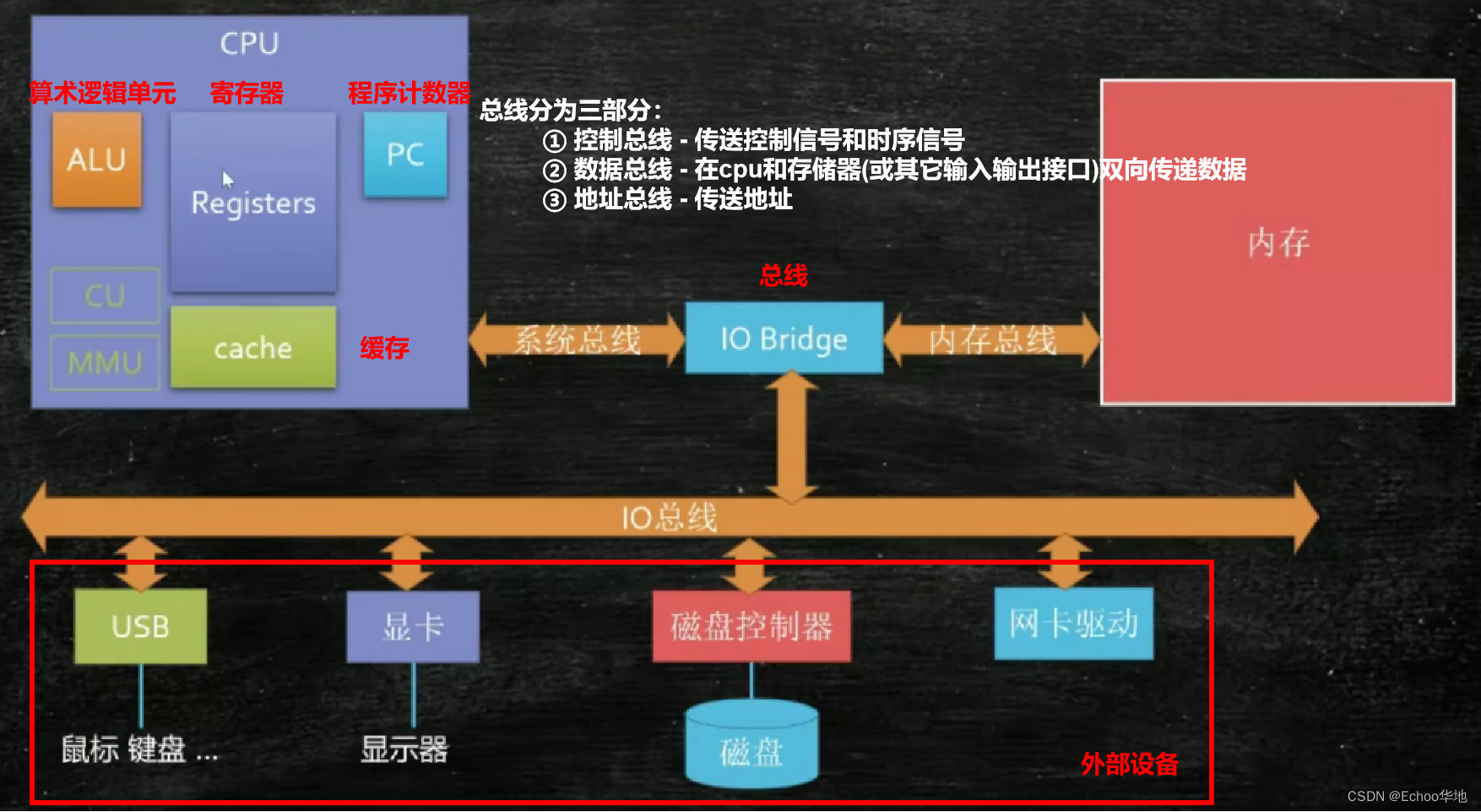
- CPU主要组成部分:
- 算术逻辑单元:负责算术和逻辑运算。
- 程序计数器:保存将要执行的下一条指令的主存地址(属于寄存器的组成部分)
- 寄存器:至少分为六部分,负责暂存各种数据
- 指令寄存器(IR)
- 程序计数器(PC)
- 地址寄存器(AR)
- 数据寄存器(DR)
- 累加寄存器(AC)
- 程序状态字寄存器(PSW)
- 总线:连接两个或多个计算机组件
- 控制总线:管理组件之间的信息流,指示操作是读取还是写入,并确保操作在正确的时间发生。
- 地址总线:处理器通过地址总线,从内存中读取数据的内存地址。
- 数据总线:在不同组件之间传输数据。
二、进程与线程
一个程序,读入内存,都是 0 和 1
从内存读入到 cpu 计算这个过程,需要通过总线
指令和数据是无差别存放在存储器中的,怎么知道一段 0 和 1 组成的数据到底是数据还是指令?
总线分三类,从不同总线读取到的数据类型不同,总线是如何解析区分的暂不深究
程序执行过程:
一个程序执行后,首先把可执行文件加载到内存中,找到起始(main方法的)位置,逐步读出指令和数据,进行计算,并写回内存。
什么是进程:
一个程序进入内存,称为进程。
同一个进程可以执行多份,比如游戏、微信的多开,每个进程都独立分配内存空间。
单个进程内通常存在需要多个任务通知进行的需要,比如收发数据,usb读取,输入输出设备的数据交互,这个时候就出现了并发的刚性需求
最早提出将一个进程拆分成多个进程的做法,但是存在严重的数据共享窜读的问题
于是线程的概念横空出世,也被称为轻量级进程
什么是线程:
线程没有自己的内存空间,都是用的进程的内存空间
同一个进程的多个线程之间共享内存,但是不共享计算,这也是多线程访问同一个资源产生并发问题的主要原因。
进程是静态的概念:程序进入内存,计算机会给它分配对应资源(主要是内存空间),同时产生一个主线程。
线程是动态的概念:是可执行的计算单元。
一个ALU同一时间只能执行一个线程
2.1 线程的切换
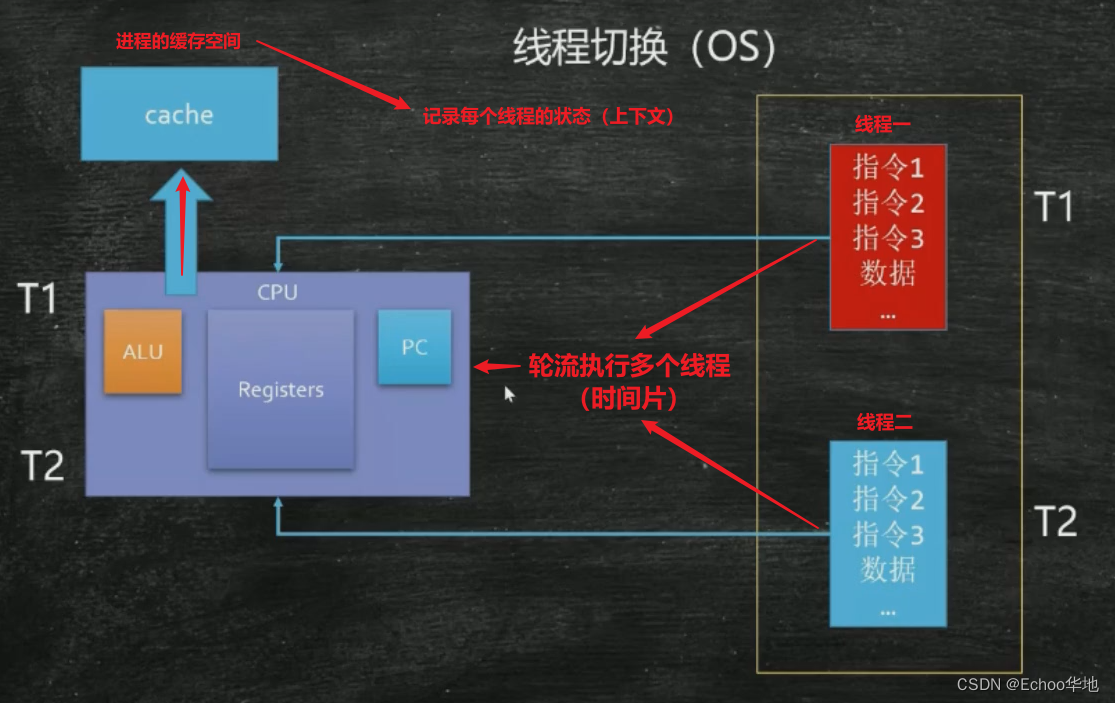
计算机以时间片为单元轮流执行多个线程,在切换的过程序会把每个线程的执行状态(上下文)保存在该线程所属进程的缓存空间中,以便下次执行该线程时能够读取线程执行到哪里。
问题一:是不是进程的线程的数量越多,执行效率越高?
回答:非也,线程切换是需要时间的,多线程主要目的是为了不浪费计算机的单位时间算力,线程数达到一定程度,切换线程花费的时间比例占比过大,反而影响了计算机的执行效率。
问题二:对于一个程序,设置多少个线程合适(线程池设定多少个核心线程)?
回答:理想情况是根据公式可以算出大概,但实际情况是很难计算线程的等待/计算时间比例,所以要进行压测。

比如某线程任务在CPU中的执行情况是50%的时间在计算,50%的时间在等待资源,现有一个双核CPU,希望CPU利用率跑到80%左右,则代入公式2×0.8×(1+0.5/0.5)=3.2,则线程应该为3个或者4个为合适。
2.2 CPU的并发控制
CPU的并发控制有四种方式。
2.2.1 关中断
2.2.2 缓存一致性协议
2.2.2.1 缓存Cache
CPU内ALU访问自身寄存器的速度比访问内存的速度快很多很多。为了充分利用CPU的计算能力,在内存和寄存器之间引入了缓存的概念。现在的CPU多采用三级缓存的架构。
多核CPU架构:
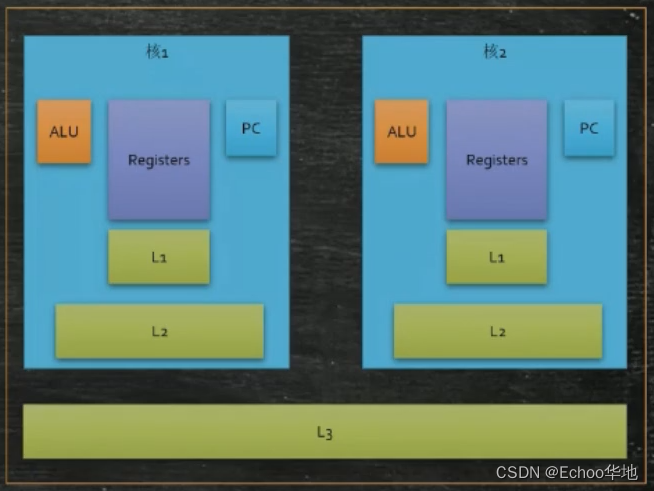
L1、L2、L3为缓存,其中一二级缓存跟核心绑定,三级缓存为多核共享。
2.2.2.2 缓存行Cache Line
缓存行指一次性读取的数据块。
处理器从缓存读取数据不是读取单独的一个数据,而是把包括这个数据在内的数据块读过来,这样做的理论基础是程序的局部性原理。
程序的局部性原理:
- 空间局部性:实践证明当处理器访问一个数据的时候,很大几率在短时间内会访问其相邻的数据。
- 时间局部性:实践证明当处理器执行一条指令的时候,很大几率在短时间内会执行其相邻的指令
如果缓存行大,则命中率高,读取效率低,反之相反
根据工业实践妥协的结果,目前(2021)的计算机多采用64byte(64 * 8 bit)为一行(一个缓存行)。
2.2.2.3 缓存一致性
由于缓存的存在,当多个核心对同一块缓存行进行修改的时候,如何保证每一级缓存中的数据一致?这时候就需要引入缓存一致性这个概念。
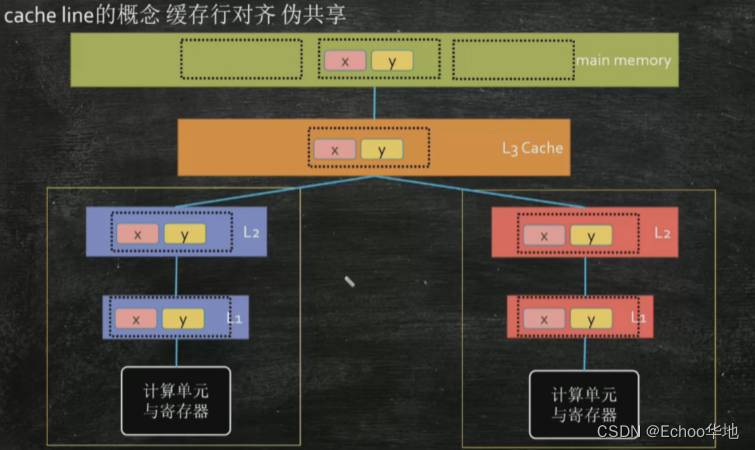
每个处理器厂商都有自己的缓存一致性协议,比如英特尔的MESI,还有其他MOSI、MSI等等。
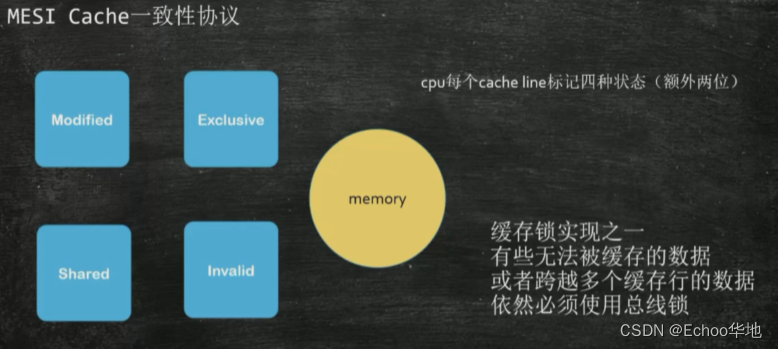
有些数据很大,超过了
64byte(缓存行)的大小无法被缓存或者跨越多个缓存行,这种数据需要使用总线锁来保证数据的一致性。
package 缓存一致性;
import java.util.concurrent.CountDownLatch;
public class CacheTest {
static class T {
public long a1, a2, a3, a4, a5, a6, a7;
public long x;
public long a8, a9, a10, a11, a12, a13, a14;
}
public static long COUNT = 1_000_000_000L; // 1亿
public static T[] arr = new T[2];
static {
// 初始化数组
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
for (int i = 0; i < COUNT; i++) {
arr[0].x = i;
}
countDownLatch.countDown();
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < COUNT; i++) {
arr[1].x = i;
}
countDownLatch.countDown();
});
final long start = System.nanoTime();
t1.start();
t2.start();
countDownLatch.await();
System.out.println("运行时间(ms) = " + (System.nanoTime() - start) / 1_000_000);
}
}
拓展:超线程
除此了引入缓存外,还引入了超线程的概念:
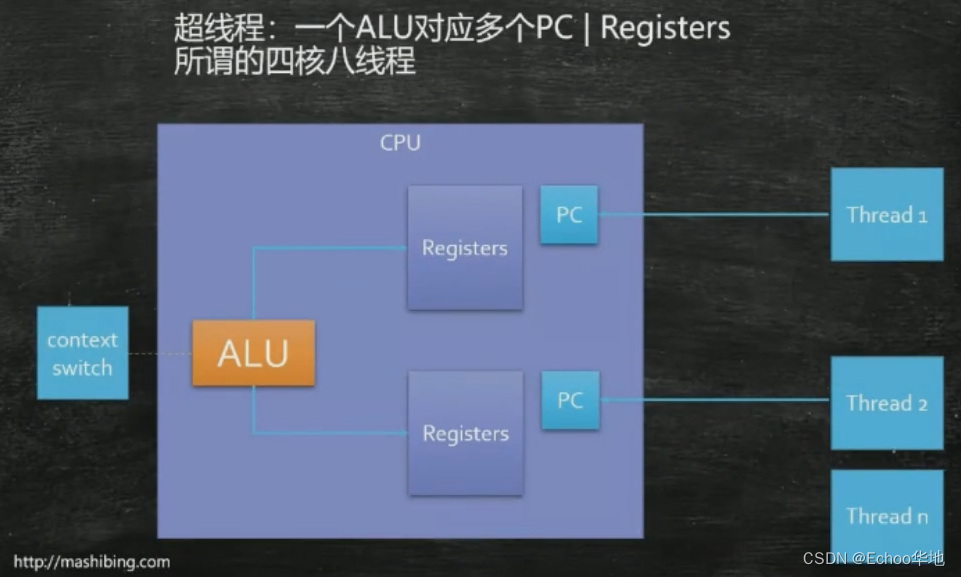
我们说的核就是指ALU,算力核!当一个核配两套寄存器,就成了一核双线程,大大节省了线程切换的时间。
2.2.3 内存屏障
内存屏障分为两级:
- 编译级别的屏障
- 指令级别的屏障
在了解内存屏障前先了解CPU的乱序执行。
2.2.3.1 CPU的乱序执行
启动一个程序,进程加载到内存,产生一个主线程,CPU开始执行主线程,处理器处理线程的过程中往往伴随着加载资源(从内存加载数据、等待网络等等)和计算。因为CPU的计算速度是非常快的,可能从内存读取数据的时间周期中就能完成多次运算。因此为了充分利用CPU的算力,CPU会对指令进行优化,比如第一条指令是从内存加载数据,第二条指令是变量自增,在第一条指令内存加载数据还没完成的时候,第二条变量自增指令很可能早已完成,这就形成了后面的指令比前面的指令先完成的乱序执行情况(这是CPU的流水线设计)。
总结:
CPU在等待费时指令执行的时候,优先执行后面的指令。目的就是为了提高执行效率。
单个线程,两条语句,未必是按顺序执行
单线程的重排序,必须保证线程的最终一致性。
但在多线程中可能出现不希望看到的乱序情况。
例 证明乱序执行的存在:
import java.util.concurrent.CountDownLatch;
public class Ordering{
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < Long.MAX_VALUE; i++) { // 超大次数循环
// 重置数据
x = 0;
y = 0;
a = 0;
b = 0;
CountDownLatch latch = new CountDownLatch(2);
// 线程一
Thread t1 = new Thread(() -> {
a = 1;
x = b;
latch.countDown();
});
// 线程二
Thread t2 = new Thread(() -> {
b = 1;
y = a;
latch.countDown();
});
t1.start();
t2.start();
latch.await();
if (x == 0 && y == 0) {
System.err.println("第" + i + "次循环出现(" + x + "," + y + ");");
break;
}
}
}
}
执行结果:
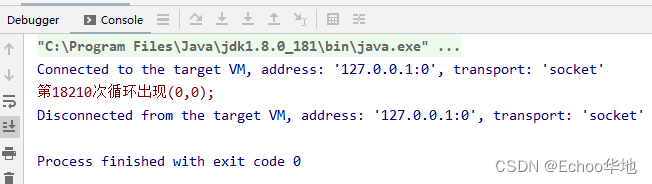
解释:
因为时间片的存在,处理器轮流执行线程任务,那么可能出现8种情况
① 执行 线程一 → 线程二:结果为 x = 0,y = 1;

① 执行 线程二 → 线程一:结果为 x = 1,y = 0;

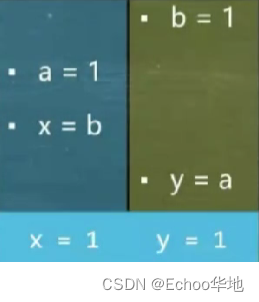
③ 执行 线程一 → 线程二 → 线程一 → 线程二:结果为 x = 1,y = 1;
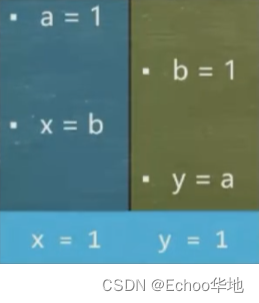
④ 执行 线程二 → 线程一 → 线程二→ 线程一:结果为 x = 1,y = 1;
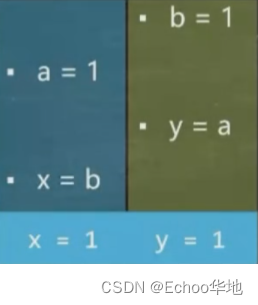
⑤ 执行 线程一 → 线程二→ 线程一:结果为 x = 1,y = 1;
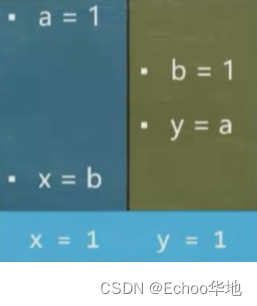
⑥ 执行 线程二 → 线程一→ 线程二:结果为 x = 1,y = 1;
⑦⑧
虽然在程序中
线程一中指令顺序为 a=1; x=b;
线程一中指令顺序为 b=1; y=a;
但是对于单线程来说,以线程一为例,无论是先执行 a = 1 ,还是先执行 x = b ,最终放入内存的结果都是一样的,因为 x = b 这个 b 对于线程一(x)来说它只是一个地址(引用),地址的实际值并不在线程一赋值,所以先执行 x = b 也是完全没问题的,它能够保证本线程的最终一致性。但是在多线程中,若碰巧出现线程一和线程二同时发生指令乱序执行,导致出现 x=0,y=0,虽然理论上指令的执行没问题,但是产生了我们不希望看到的结果:
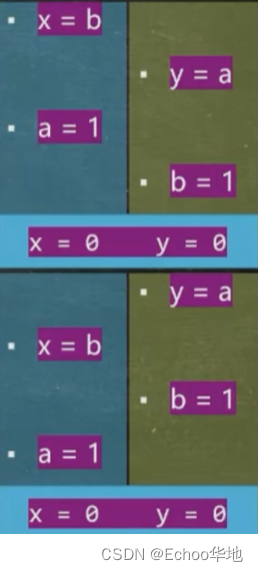
拓展1:java 的 this 溢出问题
例:
import java.io.IOException;
public class ThisEscape {
private int num = 8;
public ThisEscape() {
new Thread(()->{System.out.println(this.num);});
}
public static void main(String[] args) throws IOException {
ThisEscape thisEscape = new ThisEscape();
}
}
先看对象的创建过程:
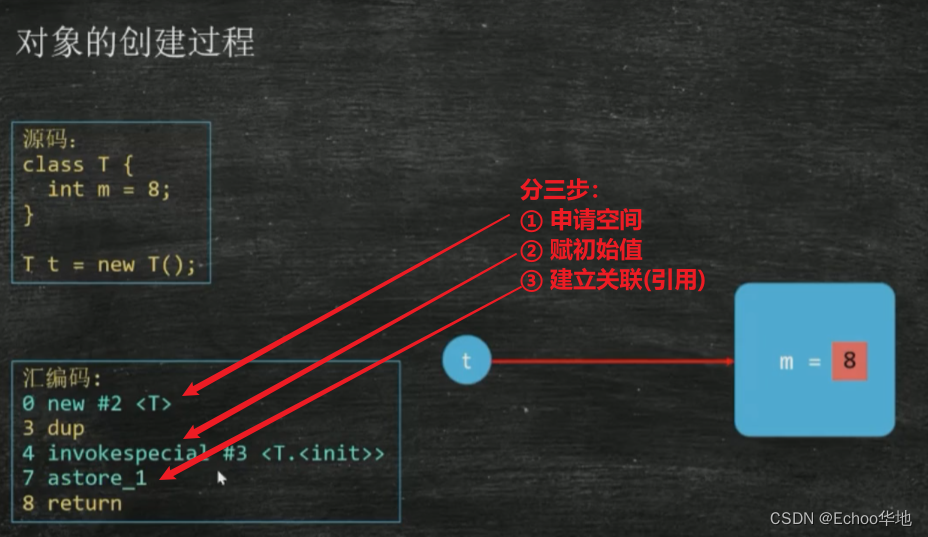
在C++中,申请完空间后变量的值是一个遗留值(上一个程序运行后留下来的值),而Java的做法是在申请空间后,会给变量赋初始值(从汇编码可以看出),目的是为了保证安全。
问题就在这里,上面例子在构造器中就创建线程通过this引用调用num变量
new Thread(()->{System.out.println(this.num);});
虽然在汇编码中this的引用建立是在构造方法的结尾才执行,但是因为编译器和处理器会对指令重排序,很有可能先建立了this引用再进行变量的初始化,在对象初始化不完全的时候就通过this建立引用关系去调用对象的变量,会出现对象不稳定的情况,这就是著名的 this溢出问题。就像 你女朋朋穿衣服穿到一半你把她拉出去见人,她是上半身走光还是下半身走光都有可能,
因此,有一个原则:不要在构造方法中启动线程或者注册监听器。
拓展2:双重检查锁DCL的bug
在单例模式的懒汉式中,面对多线程问题,通常用synchronized关键字上锁,其中最优解为双重检查锁Double Check Lock,能保证单例安全。
private static Test INSTANCE;
public static Test getInstance(){
if(Test.INSTANCE == null){
synchronized(Test.class){
if(Test.INSTANCE == null){
Test.INSTANCE = new Test();
}
}
}
return Test.INSTANCE;
}
但是在这个DCL解决方案中也存在bug。
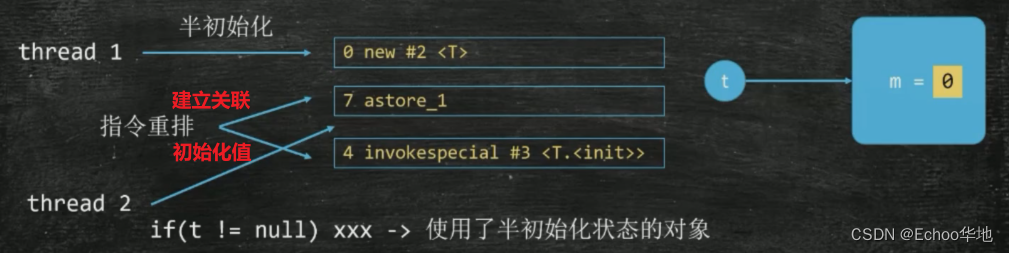
同样是创建对象的过程指令重排序的问题,如果线程1在创建对象的过程中发生了指令重排,先建立的引用关系,此时线程2进入判断就会发现实例不为null,那它就会 直接拿到实例然后调用,这时它拿到的是初始化不完全的不稳定对象。
解决办法:防止指令重排
在JAVA中可以通过volatile关键字(修饰变量)防止指令重排
private static volatile Test INSTANCE;
public static Test getInstance(){
if(Test.INSTANCE == null){
synchronized(Test.class){
if(Test.INSTANCE == null){
Test.INSTANCE = new Test();
}
}
}
return Test.INSTANCE;
}
synchronized可以保证原子性、可见性但是不能保证有序性。
2.2.3.2 Java 中防止指令重排
禁止编译器乱序
编译器对代码进行优化的时候可能会对两个没有依赖关系的指令重排序。
使用内存屏障阻止指令乱序执行
内存屏障是特殊指令:看到这种指令,前面的指令必须执行完,后面的才能执行。
对于不同的CPU,有不同的屏障指令。如
Intel的屏障指令是lfence、sfence、mfence
JVM中的内存屏障
所有实现JVM规范的虚拟机,必须实现四个屏障:
- LoadLoad屏障:
对于这样的语句Load1;LoadLoad;Load2;
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。 - StoreStore屏障:
对于这样的语句Store1;StoreStore;Store2;
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。 - LoadStore屏障:
对于这样的语句Load1;LoadStore;Store2;
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。 - StroeLoad屏障:
对于这样的语句Store1;StoreLoad;Load2;,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
简单地说就是任一屏障前后的操作不能换顺序。
JVM的内存屏障最终还是要映射到CPU提供的内存屏障上。
最流行的JAM内存屏障实现:hotspot
hotspot是用C++写的,因为Java是解释性语言,是解释运行的,当hotspot中的二进制码解释器bytecodeinterpretor.cpp遇到volatile关键字时,它通过汇编指令lock把volatile映射成CPU级别的屏障:
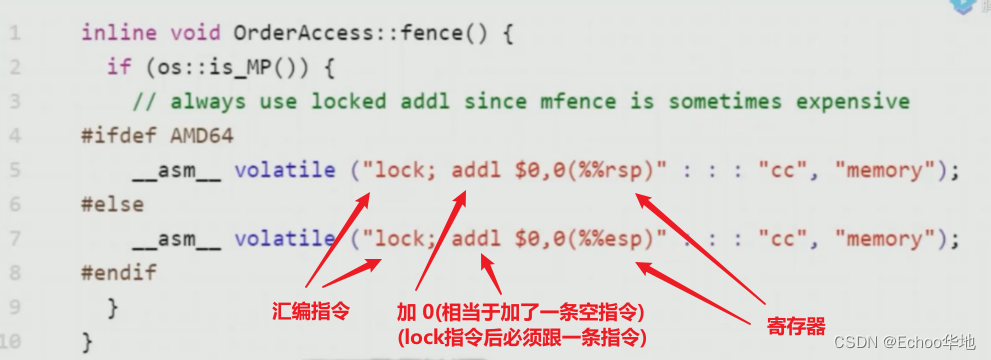
汇编指令
LOCK用于在多处理器中执行指令时对共享内容的独占使用;
它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效,另外还提供了使后面有序的指令无法越过这个内存屏障的作用。
volatile的实现细节
volatile有两大作用:
- 保证可见性:一颗核心改了另外的核心立刻可见,一个线程改了另外的线程立刻可见
- 禁止指令重排
JVM会对volatile修饰的那块内存的读写操作指令前后添加内存屏障:

2.2.4 总线锁、缓存锁
上面内存屏障中提到的汇编指令lock就是其中之一,至于什么时候锁总线什么时候锁内存赞不深究。
资料来源:哔哩哔哩 马士兵-小森 清华大牛耗时1000分钟把计算机底层知识 | 计算机组成原理 | 操作系统
https://www.bilibili.com/video/BV1qe4y1T7t3?p=5&spm_id_from=pageDriver&vd_source=c2e346bb74807b3fde142d31e57292ce