一文看懂 ES 核心
Elasticsearch 作为一个搜索引擎,其可以提供高效的搜索匹配数据的能力,对于这类工具了解其运行原理其实是有一套功法的。
- 聊存储,ES 是如何存储数据的?
- 聊方法,ES 是如何进行搜索匹配的?
- 聊集群,ES 的最佳部署方案?集群如何协作?
- 聊使用,在代码中如何使用?
ES 的一些概念性名称
先解释一些概念性名词便于后续的快速理解
index 索引
index 相当于 ES 的数据表,我们主要建立的就是 index 索引文件,搜索也是基于索引来进行,建立的索引文件会存于磁盘
倒排索引
为什么叫 “倒排” 是因为一般的索引是通过下标找数据,而 ES 为了做分词搜索匹配是通过词来匹配找对应数据的下标,其实我觉得不如叫他 “分词索引” 更容易理解。
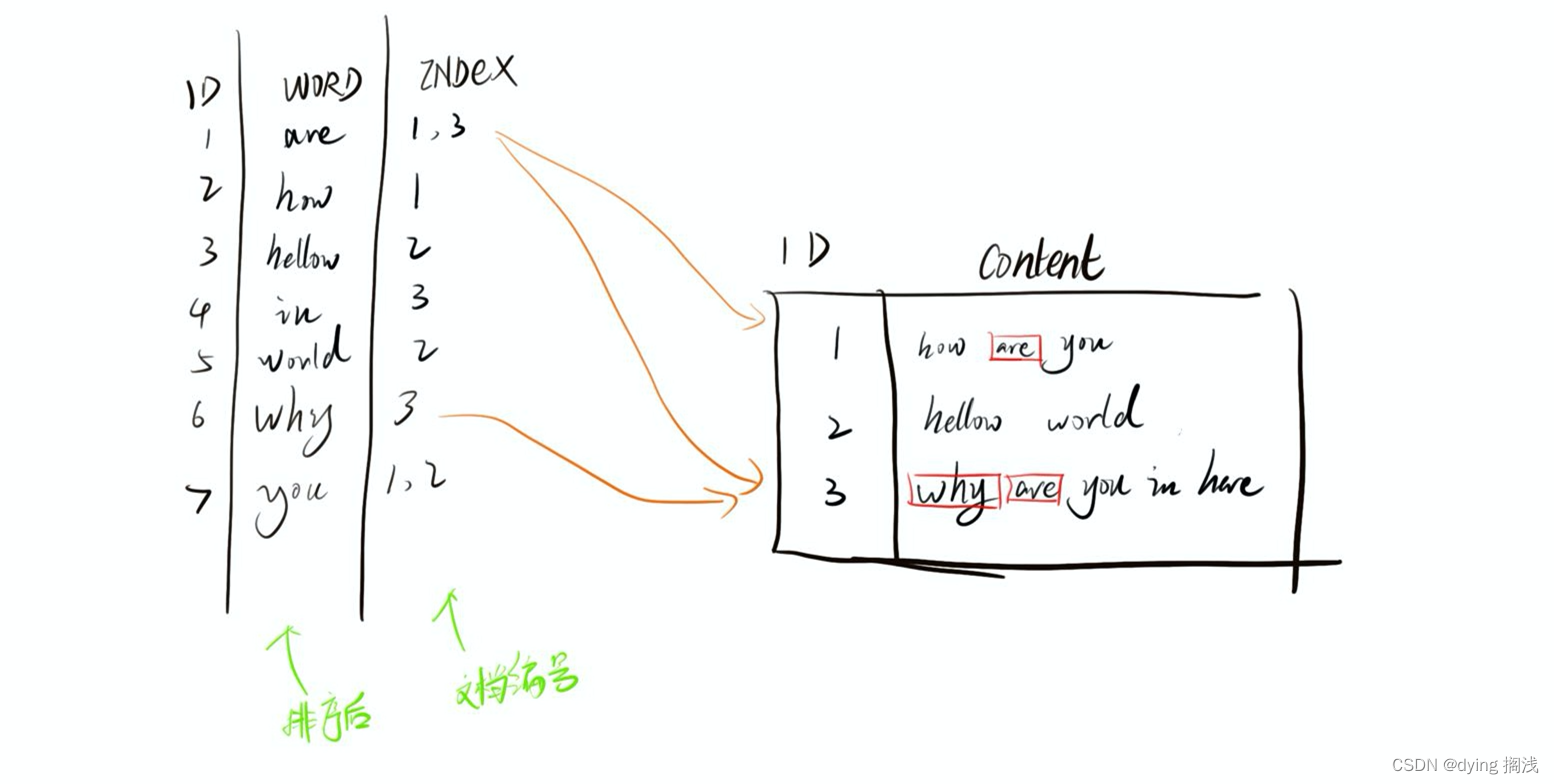
mapping 映射
定义你的 index 索引的数据结构映射,对应概念可以参考 Mysql 的表结构,这个是索引结构,定义了 index 存在那些字段,以及字段类型等相关配置参数。
field 字段
索引的数据字段,同比表字段
document 文档
是可以被索引的基元,人话就是:一条数据,一条记录。在 ES 中记录的格式是 JSON 格式。
cluster 集群
集群由多个节点组成,即多个 ES 服务,他们共同持有索引数据,并对外提供查询写入搜索服务
node 节点
每个 ES 服务称为一个节点,多个节点组成集群,对每个节点可以通过配置集群名称的方式来加入对应的集群。
shards 分片
为了平衡索引存储的大小问题,ES 提供对索引进行了分片的能力,简单理解就是将一个大容量的索引分为多份存储,有几个分片就有几份,而分片可以分布在不同的节点上。默认的确定一个 document 要存储在那个索引分片上是通过 id % 分片数 来确定的,类似 HashMap 的底层逻辑。分片的分布以及如何聚合搜索由 ES 负责管理。分片在 index 创建时指定,后续不可动态更改
replicas 副本
副本是分片的副本,设定几个副本 index 的分片就有几个副本分片,副本可以提供查询服务可以提高查询的并发能力,写入是在主分片然后同步到副本。副本可以在主分片节点宕机时重新选举成为主分片,从而实现高可用。
ES 的存储
ES 作为搜索引擎,其索引数据最终是会落到磁盘的,这样的数据是较为持久的。同时在落盘的过程中也使用了内存缓存进行优化。
其实很多的存储工具都在这么玩,持久话是一定要落盘的,但可以使用内存来优化落盘的时间,而内存不可靠可以通过顺序写磁盘记录日志来进行恢复。
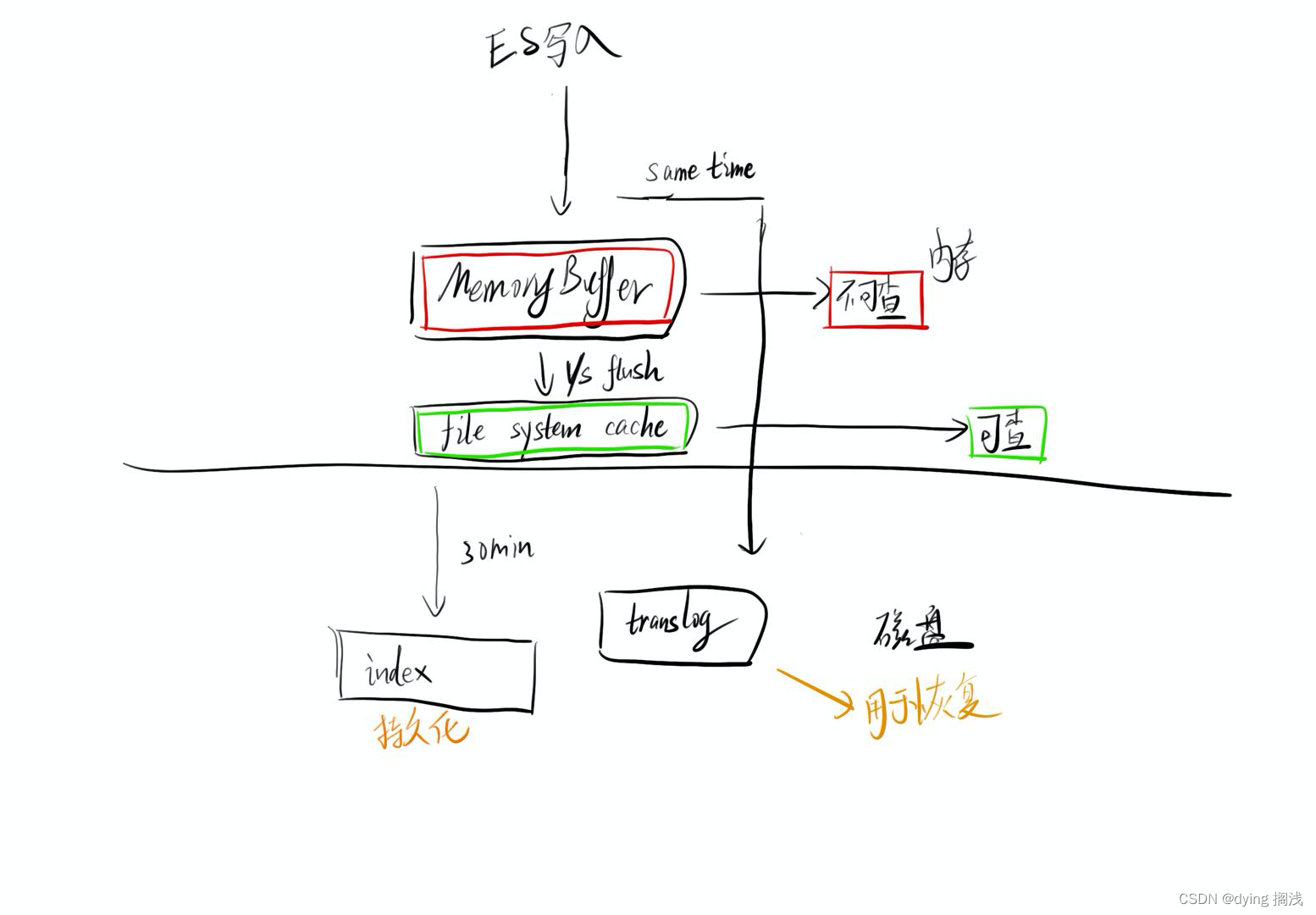
ES 在写入一条数据时首先会写入 memory buffer ,这部分是系统内存,同时会记录 translog 操作记录日志到磁盘(顺序读写命中系统 pageCache 性能较快),ES 每秒会将 memory buffer 数据刷新至 file system cache (或者 memory buffer 满时同步,ES 是基于 Luence 即 Java 实现,适用 JVM 垃圾收集,这里应该是进入了 JVM 内存中),读取到 JVM 内存后可搜索,即进入 file system cache 时可搜索。这个过程通常称之为 refresh 刷新 即 refresh 后数据可搜索
最终将 file system cache 写入 disk 的操作称为 flush 刷盘 flush 后数据持久化 这个过程有同样有两个触发点,一个是 translog 满时会进行 flush 如默认的 512M ,或者到达周期默认 30 min 进行 flush。flush 后会清空 translog
更详细的解释可以参考我之前的一篇博文 ES 的近实时搜索 filesystem cache 与 事务日志 Translog 数据恢复
ES 搜索匹配
通常来说企业级的 ES 一定是要组件集群的否则无法达到高可用,对于 ES 服务节点查询请求会发送到某一个 DataNode 数据节点上,此时这个节点会成为协调节点,该节点会广播这个查询请求到其他节点,其他节点在对应分片上进行数据查询最后将数据信息返回给协调节点,协调节点汇总数据进行返回。
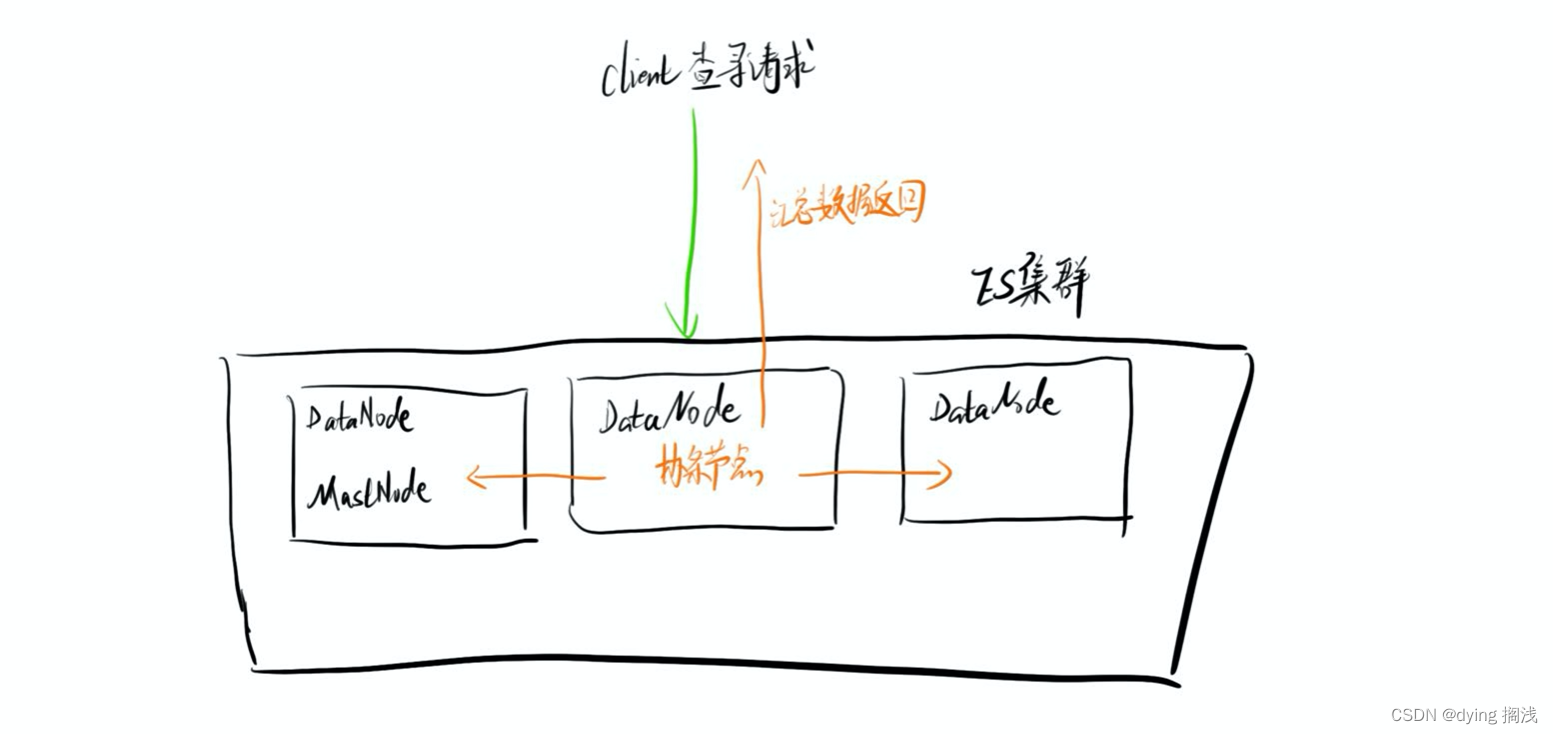
ES 集群
在企业应用中集群部署几乎是必不可少的,我们需要保证服务的高可用,ES 同样如此。一般的 ES 集群要保证至少 3 台或以上,用于保证某台服务宕机后的 Master 节点的选举。
比较常用的 ES 节点可以配置为 DataNode 数据节点,或者 MasterNode 主节点。
主节点负责管理索引(创建删除)以及维护元数据 mapping 以及节点状态,不负责查询和写入。
数据节点则会负责数据的查询写入等功能,估配置了数据节点的服务的内存需求更大。
这个配置可以同时配置,即一个节点即可以为 DataNode 也可以是 MasterNode ,但 MasterNode 在一个集群中只存在一个,配置了可以成为主节点的服务在选举过程中有机会成为主节点
ES 在 Java 中的使用
官方提供了 Java High Level REST Client
一般来说在项目中引入 ES 是为了搜索服务即分词文本匹配等检索场景
- 首先确定你要创建的索引 mapping
- 构建 Java 脚本创建 mapping
- 构建脚本同步 DB 数据到 ES (ES 虽然能持久但我们的数据一般要在 Mysql 存在的这是最可靠的)
- 相关更新同步 ES
- 提供 ES 查询方法查询到对应 id 后可通过 id 直接查 DB 数据
抛一个 Kibana( ES 可视化管理界面) 设置样例,对应 Java 代码转换可以参考官方案例
PUT /esIndex
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"sex": {
"type": "integer",
"index": true,
"store": true
},
"age": {
"type": "integer",
"index": true,
"store": true
}
}
}
}