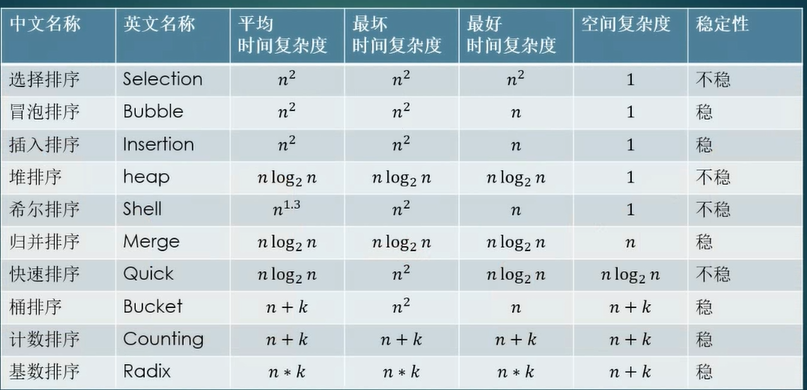
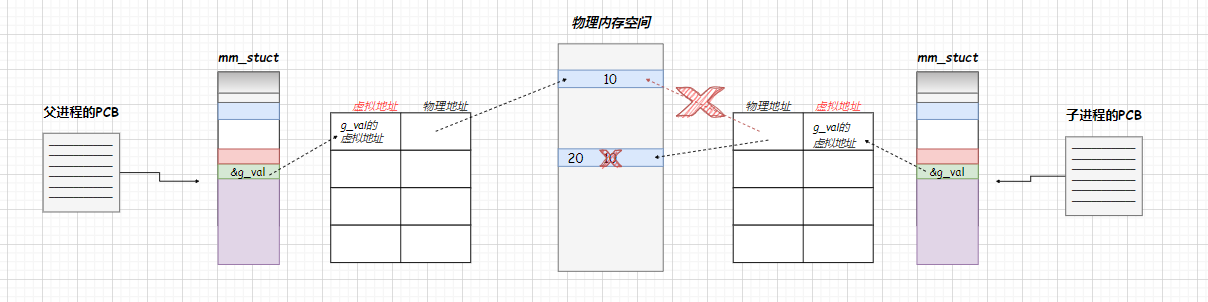
索引类型可以分为哈希表、有序数组和 N 叉树
不管是哈希还是有序数组,或者 N 叉树,它们都是基于其自身数据结构的特性来提高读写速度。在 NoSQL 里面还运用到了 LSM 树,来提高写的速度,还有跳表等数据结构来进行优化。
不过需要关注的是,数据库底层存储的核心就是基于数据模型的。通过这些数据模型,才能分析这个数据库到底适用于什么场景。
这里只浅谈了三种类型的索引类型,索引的目的是来提高数据查询的效率,不同的数据类型终究是时间与空间的 trade off。
下面的例子都基于学生的数据存储,假设学生表的索引是学号,格式为 idx_stu_no。索引后面文章,相关的例子也是用这个学生的数据存储。
| id | stu_no | stu_name |
|---|---|---|
| 1 | 1001 | 张三 |
| 2 | 1002 | 李四 |
| 3 | 1010 | 王五 |
| 4 | 1003 | 赵六 |
哈希表
哈希表是一种以 key-value 存储数据的结构,即输入 key 得到 value。
哈希表的思路就是把 value 放到数组里面,然后 value 存在哪位置,是通过哈希函数把 key 转换成一个位置。
哈希表的问题就是在 一定概率下,会造成哈希冲突。处理这种方式就是需要一个链表,如果哈希函数计算出来的值有重复,则往链表后面追加。可以通过下图理解:
假设分别插入1001,1002,1003,1010 。分别通过 HashFunc 计算出来的数组下标是,1,4,2,2。1003和1010在下标2里面,因此,下标2内以链表存储(其他只有一个的也是链表,只不过下图这么展示)

哈希表的缺点就是,因为 key 计算出来的位置不是有序的,所以哈希索引做区间查询的速度是很慢的。
因此,哈希表的适用场景就是等值查询的场景,比如一些缓存场景。
hash table 的实现,自己实现的一个简单的 hash table : hashTable zxmfke/train (github.com)
有序数组
有序数组的存储方式,就是 key 递增的形式存储在数组里面。
有序数字相较于哈希表的好处就是既能等值查询,也能范围查询(这种情况一般假定,key 都是唯一的)。
最简单的有序数组,就是通过遍历来找到要的 key,这个时间复杂度是O(N)。如果是范围查询,就需要找到 start key,然后遍历到 end key。
还有一种方式是通过二分法查找,时间复杂度是 O(log(N))。范围查找就可以先通过二分法查找到 start key,然后再向右遍历,直到小于等于 end key。
可以通过下图理解:
insert 1001,找到下标0
insert 1002,找到下标1
insert 1010,找到下标2
insert 1003,找到下标2

有序数组的缺点就是需要更新数据的时候就比较麻烦,中间插入一个数据,后面的数据都要向后挪一格,成本巨大。
因此,有序数组只适合静态存储引擎,比如一些历史数据,不会再改动的数据。
有序数组的源码实现,自己实现的一个简单的 ordered slice: orderedSlice · zxmfke/train (github.com)
N叉树
N叉树最初始的样子是二叉搜索树,二叉搜索树的实现就不在这边详细说了。
二叉搜索树的特点就是,每个节点的左二子小于父节点,父节点又小于右儿子,查询的时间复杂度为 O(log(N))。为了保证每次查询都是 O(log(N)),就要变成平衡二叉树,这样更新时间也会是 O(log(N))。
二叉树是搜索效率最高,但是实际不使用二叉树,因为索引不只存在在内存中,也有在磁盘上。
树可以有二叉,也可以有多叉,多叉树节点里面的儿子的大小也得保证是从左往右递增的。因此,为了保证少从磁盘读取数据,就不能使用二叉树,而是要使用 N叉树,这里的 N 取决于数据块的大小。N叉数由于在读写上的性能特点,以及适配磁盘的访问模式,更广泛地在数据库引擎中应用。
下图可以理解为N=2,一个二叉搜索树来插入上面的学生数据:

数据库底层存储的核心就是基于这些数据模型的。每碰到一个新的数据库,我们需要先关注它的数据模型,这样才能从理论上分析这个数据的适用场景。
资料来源
极客时间:mysql45讲
基于这些数据模型的。每碰到一个新的数据库,我们需要先关注它的数据模型,这样才能从理论上分析这个数据的适用场景。
资料来源
极客时间:mysql45讲