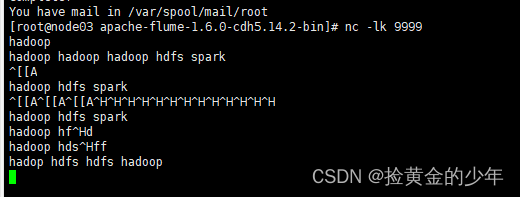
Flink将数据写入到 hudi
准备阶段
启动hadoop集群(单机模式)
./sbin/start-all.sh
hdfs离开安全模式
hdfs dfsadmin -safemode leave
启动hive
后台启动元数据
./hive --service metastore &
启动hiveserver2
./hiveserver2 &
执行sql语句之前先设置本地模式,要不然很慢
set hive.exec.mode.local.auto=true;
启动Flink集群(单机模式)
指向hadoop的路径
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
启动集群
./bin/start-cluster.sh
指向hadoop的路径
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
启动flink sql client
./bin/sql-client.sh embedded
三种模式
表格模式(table mode)在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
SET sql-client.execution.result-mode=table;
变更日志模式(changelog mode)不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET sql-client.execution.result-mode=changelog;
Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET sql-client.execution.result-mode=tableau;
设置flink sql属性
set sql-client.execution.result-mode=tableau;
set execution.checkpointing.interval=3sec;
Flink中创建hudi表
创建表
CREATE TABLE t1(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://ip:port/tmp/t1',
'table.type' = 'MERGE_ON_READ' -- this creates a MERGE_ON_READ table, by default is COPY_ON_WRITE
);
插入数据
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
这里遇到了问题,提交任务到web ui后一直处在create状态,后来通过查看日志,原来是slot数不够,重新设置并行度为2,taskmanager数位4,taskmanager.numberOfTaskSlots为4,相当于总共16个slot

执行成功

Flink CDC(本地模式)
创建Mysql表
create table flink_cdc.users(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default CURRENT_TIMESTAMP NOT NULL,
ts timestamp default CURRENT_TIMESTAMP NOT NULL
);
插入数据
INSERT INTO flink_cdc.users(name) VALUES(“测试”);
INSERT INTO flink_cdc.users(name) VALUES(“张三”);
INSERT INTO flink_cdc.users(name) VALUES(“李四”);
INSERT INTO flink_cdc.users(name) VALUES(“王五”);
INSERT INTO flink_cdc.users(name) VALUES(“赵六");
Flink创建输入表,关联mysql表
CREATE TABLE users_source_mysql(
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
age INT,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
)WITH(
'connector' = 'mysql-cdc-zaj',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone'= 'Asia/Shanghai',
'debezium.snapshot.mode' = 'initial',
'database-name' = 'flink_cdc',
'table-name' = 'users'
);
查询数据
select * from users_source_mysql;
创建视图,查询输入表,字段与输出表相同
创建视图,增加分区列part,方便后续同步hive分区表
创建视图view_users_cdc和user_soure_mysql进行关联
CREATE VIEW view_users_cdc AS
SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') AS part FROM users_source_mysql;
利用视图来进行查询
select * From view_users_cdc;

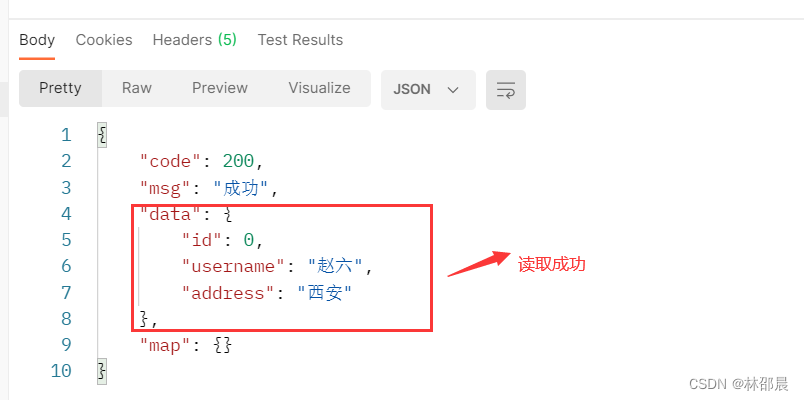
有意思的是,我随机修改了两条数据,cdc会自动把修改的数据放在最后,直接会显示出来

创建CDC Hudi Sink 表,并自动同步hive分区
CREATE TABLE test_sink_hudi_hive(
id bigint ,
name string,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
part VARCHAR(20),
primary key(id) not enforced
)
PARTITIONED BY (part)
with(
'connector'='hudi',
'path'= 'hdfs://ip:port/hudi-warehouse/test_sink_hudi_hive'
, 'hoodie.datasource.write.recordkey.field'= 'id'-- 主键
, 'write.precombine.field'= 'ts'-- 自动precombine的字段
, 'write.tasks'= '1'
, 'compaction.tasks'= '1'
, 'write.rate.limit'= '2000'-- 限速
, 'table.type'= 'MERGE_ON_READ'-- 默认COPY_ON_WRITE,可选MERGE_ON_READ
, 'compaction.async.enabled'= 'true'-- 是否开启异步压缩
, 'compaction.trigger.strategy'= 'num_commits'-- 按次数压缩
, 'compaction.delta_commits'= '1'-- 默认为5
, 'changelog.enabled'= 'true'-- 开启changelog变更
, 'read.streaming.enabled'= 'true'-- 开启流读
, 'read.streaming.check-interval'= '3'-- 检查间隔,默认60s
, 'hive_sync.enable'= 'true'-- 开启自动同步hive
, 'hive_sync.mode'= 'hms'-- 自动同步hive模式,默认jdbc模式, hms:hive metastore
, 'hive_sync.metastore.uris'= 'thrift://ip:9083'-- hive metastore地址
-- , 'hive_sync.jdbc_url'= 'jdbc:hive2://ip:10000'-- hiveServer地址
, 'hive_sync.table'= 'test_sink_hudi_hive_sync'-- hive 新建表名
, 'hive_sync.db'= 'default'-- hive 同步表存在默认数据库中,也可以自动新建数据库
, 'hive_sync.username'= 'root'-- HMS 用户名
, 'hive_sync.password'= '123'-- HMS 密码
, 'hive_sync.support_timestamp'= 'true'-- 兼容hive timestamp类型
);
利用users_sink_hudi_hive来查询
这时候遇到个问题,直接通过users_sink_hudi_hive表来查询,web ui也会一直运行一个任务,来监视数据变化,可是通过测试插入
200条数据,明显感觉速度不如直接查询视图表,而且插入数据是乱序

视图数据写入hudi表
INSERT INTO users_sink_hudi_hive
SELECT id,name,birthday,ts,part FROM view_users_cdc;
可以看到web ui有一个新任务,一直在运行状态,对视图表进行监视

会自动生成hudi MOR模式的两张表(这里我没有生成,有点问题)原理是没有开启hiveserver2,这里还是有问题,我启动了hiveserver2还是无法自动创建ro表和rt表
后续:上述问题已解决,其实ro表rt表已经生成了,在hive的db_hudi数据库中,因为我建hudi表时自动创建了一个新的数据库,如果不指定则新的表在default数据库中。

查询ro表

users_sink_hudi_hive_ro:ro表全称read optimized table,对于MOR表同步的xxx_ro表,只暴露压缩后的parquet。其查询方式和COW表类似。设置完hiveInputformat之后和普通的hive表一样查询即可。
users_sink_hudi_rt:rt表示增量视图,主要针对增量查询的rt表;ro表只能查parquet文件数据,rt表parquet文件数据和log文件数据都可查。
查看hive表数据
set hive.exec.mode.local.auto = true;
set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
set hive.mapred.mode = nonstrict;
promethues监控cdc状态下的Hudi表
create table stu6_binlog_sink_hudi(
id bigint not null,
name string,
`school` string,
nickname string,
age int not null,
class_num int not null,
phone bigint not null,
email string,
ip string,
primary key (id) not enforced
)
partitioned by (`school`)
with (
'connector' = 'hudi',
'path' = 'hdfs://ip:9000/tmp/stu6_binlog_sink_hudi',
'table.type' = 'MERGE_ON_READ',
'write.option' = 'insert',
'write.precombine.field' = 'school',
'hoodie.metrics.on' = 'true',
'hoodie.metrics.executor.enable' = 'true',
'hoodie.metrics.reporter.type' = 'PROMETHEUS_PUSHGATEWAY',
'hoodie.metrics.pushgateway.job.name' = 'hudi-metrics',
'hoodie.metrics.pushgateway.host' = 'ip',
'hoodie.metrics.pushgateway.report.period.seconds' = '10',
'hoodie.metrics.pushgateway.delete.on.shutdown' = 'false',
'hoodie.metrics.pushgateway.random.job.name.suffix' = 'false'
);
OSS实现文件的上传、下载、删除、查询
前期准备
其阿里云申请开通OSS
在Sping Boot项目里引入依赖
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<!--<version>3.10.2</version>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.1</version>
</dependency>
package com.zaj.order.controller;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSS;
import com.aliyun.oss.OSSClientBuilder;
import com.aliyun.oss.OSSException;
import com.aliyun.oss.model.OSSObject;
import com.aliyun.oss.model.OSSObjectSummary;
import com.aliyun.oss.model.ObjectListing;
import java.io.*;
public class Demo {
/**
* 上传
* @param args
* @throws Exception
*/
OSSConfigure ossConfigure = new OSSConfigure();
// Endpoint以华东1(杭州)为例,其它Region请按实际情况填写。
String endpoint = ossConfigure.endpoint();
// 阿里云账号AccessKey拥有所有API的访问权限,风险很高。强烈建议您创建并使用RAM用户进行API访问或日常运维,请登录RAM控制台创建RAM用户。
String accessKeyId = ossConfigure.accessKeyId();
String accessKeySecret = ossConfigure.accessKeySecret();
// 填写Bucket名称,例如examplebucket。
String bucketName = ossConfigure.bucketName();
// 填写Object完整路径,例如exampledir/exampleobject.txt。Object完整路径中不能包含Bucket名称。
String objectName = "my-first-key";
OSS ossClient = new OSSClientBuilder().build(endpoint, accessKeyId, accessKeySecret);
public static void main(String[] args) throws Exception {
// 创建OSSClient实例。
Demo demo = new Demo();
//demo.download();
//demo.Enum();
demo.delete();
}
/**
* 上传
* @return
*/
public String upload(){
try {
String content = "Hello OSS";
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content.getBytes()));
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
return "ok";
}
/**
* 下载
*/
public String download(){
try {
// 调用ossClient.getObject返回一个OSSObject实例,该实例包含文件内容及文件元信息。
OSSObject ossObject = ossClient.getObject(bucketName, objectName);
// 调用ossObject.getObjectContent获取文件输入流,可读取此输入流获取其内容。
InputStream content = ossObject.getObjectContent();
if (content != null) {
BufferedReader reader = new BufferedReader(new InputStreamReader(content));
while (true) {
String line = reader.readLine();
if (line == null) break;
System.out.println("\n" + line);
}
// 数据读取完成后,获取的流必须关闭,否则会造成连接泄漏,导致请求无连接可用,程序无法正常工作。
content.close();
}
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
return "ok";
}
/**
* 列举
* @return
*/
public String Enum(){
try {
// ossClient.listObjects返回ObjectListing实例,包含此次listObject请求的返回结果。
ObjectListing objectListing = ossClient.listObjects(bucketName);
// objectListing.getObjectSummaries获取所有文件的描述信息。
for (OSSObjectSummary objectSummary : objectListing.getObjectSummaries()) {
System.out.println(" - " + objectSummary.getKey() + " " +
"(size = " + objectSummary.getSize() + ")");
}
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
return "ok";
}
public String delete(){
try {
// 删除文件。
ossClient.deleteObject(bucketName, objectName);
} catch (OSSException oe) {
System.out.println("Caught an OSSException, which means your request made it to OSS, "
+ "but was rejected with an error response for some reason.");
System.out.println("Error Message:" + oe.getErrorMessage());
System.out.println("Error Code:" + oe.getErrorCode());
System.out.println("Request ID:" + oe.getRequestId());
System.out.println("Host ID:" + oe.getHostId());
} catch (ClientException ce) {
System.out.println("Caught an ClientException, which means the client encountered "
+ "a serious internal problem while trying to communicate with OSS, "
+ "such as not being able to access the network.");
System.out.println("Error Message:" + ce.getMessage());
} finally {
if (ossClient != null) {
ossClient.shutdown();
}
}
return "ok";
}
}
OSS-HDFS
OSS-HDFS服务(JindoFS服务)是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。
功能优势
通过OSS-HDFS服务,无需对现有的Hadoop、Spark大数据分析应用做任何修改。通过简单的配置即可像在原生HDFS中那样管理和访问数据,同时获得OSS无限容量、弹性扩展、更高的安全性、可靠性和可用性支撑。
作为云原生数据湖基础,OSS-HDFS在满足EB级数据分析、亿级文件管理服务、TB级吞吐量的同时,全面融合大数据存储生态,除提供对象存储扁平命名空间之外,还提供了分层命名空间服务。分层命名空间支持将对象组织到一个目录层次结构中进行管理,并能通过统一元数据管理能力进行内部自动转换。对Hadoop用户而言,无需做数据复制或转换就可以实现像访问本地HDFS一样高效的数据访问,极大提升整体作业性能,降低了维护成本。
-
HDFS兼容访问
OSS-HDFS服务完全兼容HDFS接口,同时支持目录层级的操作,您只需集成JindoSDK,即可为Apache Hadoop的计算分析应用(例如MapReduce、Hive、Spark、Flink等)提供了访问HDFS服务的能力,像使用Hadoop分布式文件系统(HDFS)一样管理和访问数据。具体操作,请参见OSS-HDFS服务快速入门。
-
POSIX能力支持
OSS-HDFS服务可以通过JindoFuse提供POSIX支持,允许您将OSS-HDFS服务上的文件挂载到本地文件系统中,能够像操作本地文件系统一样操作JindoFS服务中的文件。具体操作,请参见使用JindoFuse访问OSS-HDFS服务。
-
高性能、高弹性、低成本
使用自建Hadoop集群,严重依赖硬件资源,难以实现资源的弹性伸缩。例如Hadoop集群规模超过数百台,文件数达到4亿左右时,NameNode基本达到瓶颈。随着元数据规模的上涨,其QPS存在下降的趋势。
OSS-HDFS服务是专为多租户、海量数据存储服务设计。元数据管理能力可弹性扩容,可支持更高的并发度、吞吐量和低时延。即使超过10亿文件数依然可以保持服务稳定,提供高性能、高可用的服务。同时采用统一元数据管理能力,可轻松应对超大文件规模,并支持多种分层分级策略,系统的资源利用率更高,更节约成本,能充分满足业务体量快速变化的需求。
-
数据持久性和服务可用性
OSS-HDFS服务中的数据存储在OSS上,而OSS作为阿里巴巴全集团数据存储的核心基础设施,多年支撑双11业务高峰,历经高可用与高可靠的严苛考验。OSS特性如下:
- 服务可用性(或业务连续性)不低于99.995%。
- 数据设计持久性不低于99.9999999999%(12个9)。
- 规模自动扩展,不影响对外服务。
- 数据自动多重冗余备份。
数据湖中的应用