一、PageRank算法的前置知识
PageRank算法:计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。
从用户角度来看,一个网站就是若干页面组成的集合。然而,对于网站的设计者来说,这些页面是经过精心组织的,是通过页面的链接串联起来的一个整体。因此,Web的结构挖掘主要是对网站中页面链接结构的发现。例如:在设计搜索引擎等服务时,对Web页面的链接结构进行挖掘可以得出有用的知识来提高检索效率和质量。
一般来说,Web页面的链接类似学术上的引用,因此,一个重要的页面可能会有很多页面的链接指向它。也就是说,如果有很多链接指向一个页面,那么它一定是重要的页面。同样地,假如一个页面能链接到很多页面,它也有其重要的价值。
设u为一个Web页,Bu为所有指向u的页面的集合,Fu为所有u指向的页面的集合,c(<1)为一个归一化的因子,那么u页面的等级R(u)被定义为:R(u)=c∑_(v∈Bu)▒(R(v))/(|Fv|),很显然,基本的页面分级方法主要考虑一个页面的入度,即通过进入该页面的页面等级得到。同时,在将一个页面的等级值传递时,采用平均分配方法传递到所有它所指向的页面,即每个从它链接处的页面等分它的等级值。
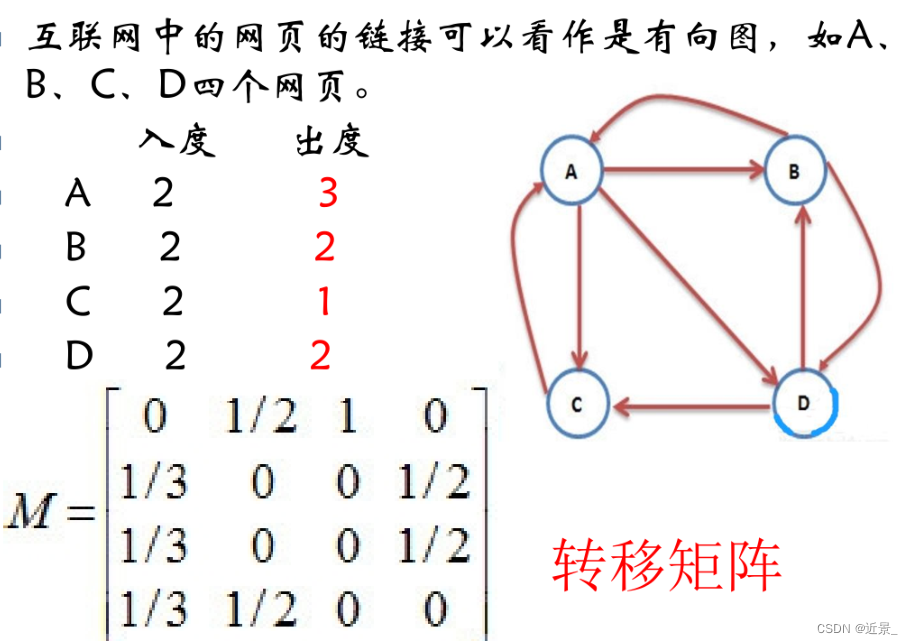
PageRank算法的核心部分可以从一个有向图开始。最典型的方法是根据有向图构造一个邻接矩阵来进行处理。邻接矩阵A=(ai,j)中的元素ai,j(∈[0,1])表示从页面j指向页面i的概率。
二、PageRank算法的基本思想
基本的PageRank算法在计算等级值时,每个页面都将自己的等级值平均地分配给其引用的页面节点。假设一个页面的等级值为1,该页面上共有n个超链接,其分配给每个超链接页面的等级值就是1/n,那么就可以理解为该页面以1/n的概率跳转到任意一个其所引用的页面上。
一般地,把邻接矩阵A转换成所谓的转移概率矩阵M来实现PageRank算法:M=(1-d)Q+dA,其中,Q是一个常量矩阵,最常用的是Q=(qi,j),qi,j=1/n,转移概率矩阵M可以作为一个向量变换矩阵来帮助完成页面等级值向量R的迭代计算:Ri+1=M*R
三、PageRank算法的例子
PageRank算法例子



四、PageRank算法的实现过程
实验内容
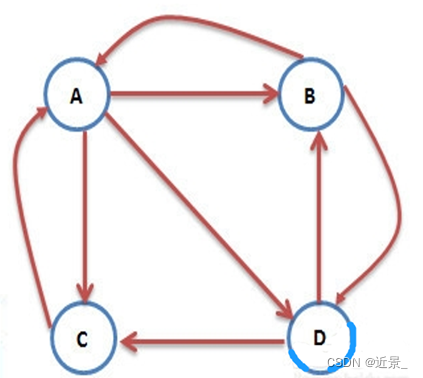
互联网中的网页的链接可以看作是有向图,如A、B、C、D四个网页,请采用PageRank算法对网页进行分级排序
实验思路
(1)定义Score分数类,在Score分数类中包含分子son和分母mom属性,还包含静态方法simplify()用于对分子分母进行约分,静态方法getAdd()用于分数相加并化简结果,静态方法getMultiply()用于分数相乘并调用simplify()对结果进行化简。
(2)定义初始数据集dataList,定义转移矩阵的每一项Score分数类对象,调用InitData()方法对数据集进行初始化。
(3)定义Score类对象v0Score并对其实例化,v0Score对象表示分数值1/4,表示最初人们对点击A,B,C,D四个网页的概率都是相同的1/4。定义一维数组V0存放4个v0Score,初始的PageRank也赋值成V0。
(4)进入while循环,调用getPageRank()方法获取PageRank矩阵。在getPageRank()方法体内部定义pageRankList集合存放最终的PageRank值,遍历dataList数据集中每一项数据dataItem,使用for循环遍历dataItem,使得dataItem和Vk完成矩阵乘法,并将矩阵乘法后每一项的结果保存在itemSum当中,当遍历dataItm结束后,将itemSum添加到pageRankList集合当中,在遍历数据集dataList集合结束后,将pageRankList转换成数组后返回。
(5)调用isRankEqual()方法判断新得到的PageRank矩阵值是否和上次得到的PageRank矩阵值相同,若不相同则继续迭代,若相同则不再迭代。isRankEqual()方法主要是判断形参V1和形参V2的PageRank矩阵内的值是否相等,返回boolean类型的值,方法体内部对数组V1进行遍历,比较V1中每一项的分子和V2中每一项的分子是否相同,若有不相同的则返回false,若遍历结束后没有不同的则返回true。
(6)若新得到的PageRank矩阵值不与上次得到的PageRank矩阵值相同,则将新得到的PageRank矩阵值赋值给最终要输出的pageRank变量,输出每一次得到的PageRank值。
实现源码
Score类
package com.data.mining.entity;
import lombok.Data;
@Data
public class Score {
private int son;
private int mom;
public Score(){}
public Score(int s, int m){
son = s;
mom = m;
}
/**
* 分数相加并调用simplify方法进行约分
* @param s1
* @param s2
* @return
*/
public static Score getAdd(Score s1, Score s2){
if (s1.getMom() == 0 || s2.getMom() == 0) return s1.getMom() == 0 ? s2 : s1;
int commonMom = s1.getMom() * s2.getMom();
int commonSon = s1.getSon() * s2.getMom() + s2.getSon() * s1.getMom();
Score addResult = simplify(commonSon, commonMom);
return addResult;
}
/**
* 分数相乘并调用simplify方法进行约分
* @param s1
* @param s2
* @return
*/
public static Score getMultiply(Score s1, Score s2){
int tempMom = s1.getMom() * s2.getMom();
int tempSon = s1.getSon() * s2.getSon();
Score simplifyResult = simplify(tempSon, tempMom);
return simplifyResult;
}
/**
* 对分子分母进行约分
* @param s
* @param m
* @return
*/
private static Score simplify(int s, int m){
int common = getCommon(s, m);
s = s / common;
m = m / common;
Score result = new Score(s, m);
return result;
}
/**
* 找分子分母的最大公约数
* @param s
* @param m
* @return
*/
private static int getCommon(int s, int m){
for (int i = s; i >= 1; i--) {
if (m%i==0 && s%i==0){
return i;
}
}
return 1;
}
}
PageRank算法实现代码
package com.data.mining.main;
import com.data.mining.entity.Score;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class PageRank {
//定义转移矩阵
public static List<Score[]> dataList = new ArrayList<>();
//定义转移矩阵中的每一项
public static Score s00,s01,s02,s03,s10,s11,s12,s13,s20,s21,s22,s23,s30,s31,s32,s33;
public static void main(String[] args) {
initData();
Score voScore = new Score(1, 4);
Score[] V0 = {voScore, voScore, voScore, voScore};
Score[] pageRank = V0;
while (true){
Score[] tmpVk = getPageRank(pageRank);
if (isRankEqual(pageRank, tmpVk)) break; //新得到的PageRank矩阵和上次得到的PageRank矩阵不相同,则继续迭代,相同则不再迭代
pageRank = tmpVk;
System.out.println(Arrays.toString(pageRank));
}
System.out.println(Arrays.toString(pageRank));
}
/**
* 判断V1和V2的PageRank矩阵内的值是否相等
* @param V1
* @param V2
* @return
*/
public static boolean isRankEqual(Score[] V1, Score[] V2){
for (int i = 0; i < V1.length; i++) {
int subSon = V1[i].getSon() - V2[i].getSon();
int subMom = V1[i].getMom() - V2[i].getMom();
if (subSon != 0 || subMom != 0) return false;
}
return true;
}
/**
* 获取PageRank矩阵
* @param Vk
* @return
*/
public static Score[] getPageRank(Score[] Vk){
List<Score> pageRankList = new ArrayList<>();
for (Score[] dataItem : dataList) {
Score itemSum = new Score(0,0); //itemSum中存放PageRank矩阵的每一项
//通过遍历数据集的每一行和Vk的每一列实现矩阵乘法
for (int i = 0; i < dataItem.length; i++) {
Score multiply = Score.getMultiply(dataItem[i], Vk[i]);
itemSum = Score.getAdd(multiply, itemSum); //将对应项相乘的结果累加到itemSum中
}
pageRankList.add(itemSum);
}
return pageRankList.toArray(new Score[pageRankList.size()]);
}
/**
* 初始化数据集
*/
public static void initData(){
s00 = new Score(0, 0);
s01 = new Score(1, 2);
s02 = new Score(1, 1);
s03 = new Score(0, 0);
s10 = new Score(1, 3);
s11 = new Score(0, 0);
s12 = new Score(0, 0);
s13 = new Score(1, 2);
s20 = new Score(1, 3);
s21 = new Score(0, 0);
s22 = new Score(0, 0);
s23 = new Score(1, 2);
s30 = new Score(1, 3);
s31 = new Score(1, 2);
s32 = new Score(0, 0);
s33 = new Score(0, 0);
Score[] s0 = {s00, s01, s02, s03};
Score[] s1 = {s10, s11, s12, s13};
Score[] s2 = {s20, s21, s22, s23};
Score[] s3 = {s30, s31, s32, s33};
dataList.add(s0);
dataList.add(s1);
dataList.add(s2);
dataList.add(s3);
}
}
实验结果
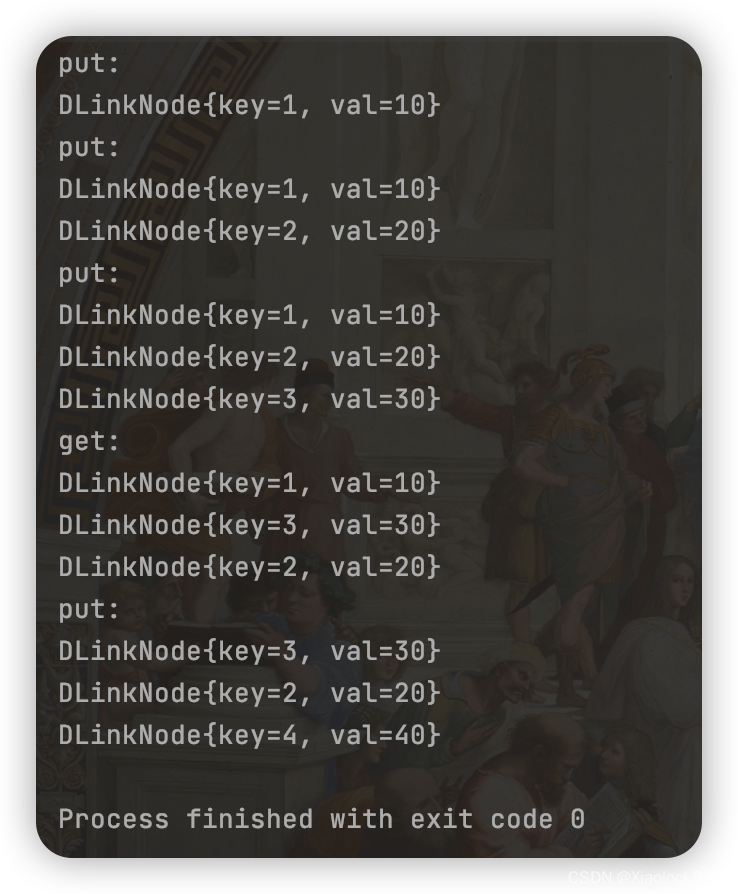
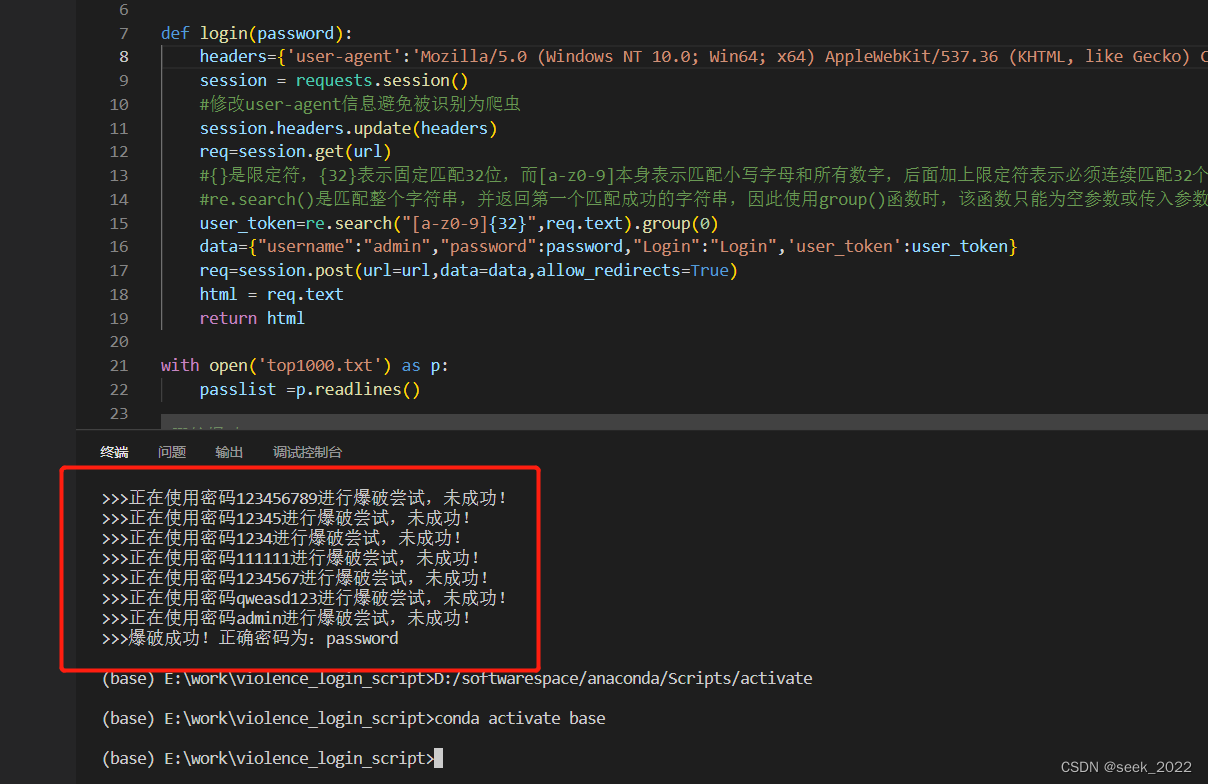
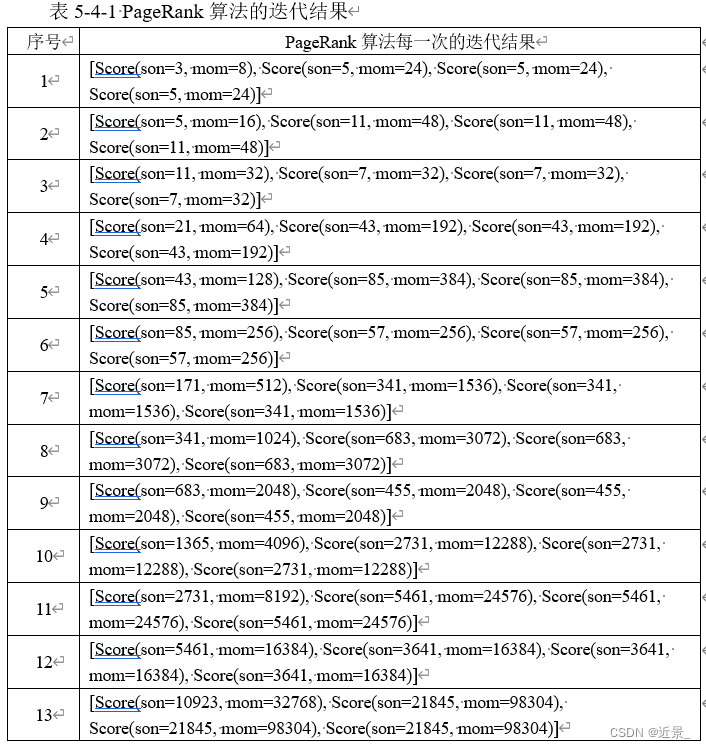
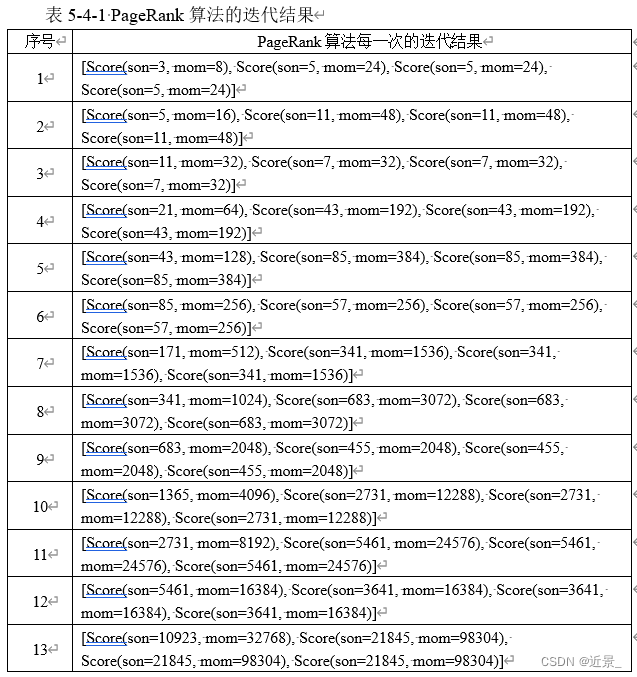
面对这个迭代结果,笔者还是有些许疑问的,书上最后的迭代结果说是趋于稳定了最后结果是[3/9,2/9,2/9,2/9],可是本次实验最终并没有得到满意的结果,而是因为数据溢出直接终止了程序,但可以看到最后一次输出的结果已经很趋近于正确答案了,包括每次的迭代结果笔者也进行了笔算,也没发现什么问题。这图片不知道为啥字这么小,反正我是看不清,所以用表格盛一下:
五、实验总结
本实验结果笔者并不保证一定是正确的,笔者仅仅是提供一种使用Java语言实现PageRank算法的思路。因为实验并没有给答案,笔者已将书上有答案的实验数据输入程序后,程序输出的结果和答案一致,所以问题应该不大。若有写的不到位的地方,还请各位多多指点!
笔者主页还有其他数据挖掘算法的总结,欢迎各位光顾!