文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
实操1:使用JVisualVM分析内存溢出OOM
OOM后系统已挂,使用JVisualVM分析内存溢出OOM
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从下面的链接获取:语雀 或者 码云
前置条件:
oom时导出了堆的dump文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=
分析路径:
- 查看占用 内存多的对象
- 找到GCRoot
- 查看线程栈、找到业务代码
准备模拟内存泄漏demo
1、定义静态变量HashMap
2、分段循环创建对象,并加入HashMap
代码如下:
package com.crazymaker.springcloud.demo.controller;
import com.alibaba.fastjson.JSONObject;
import com.crazymaker.springcloud.common.result.RestOut;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
import java.util.Map;
@Api(value = "JvmMemoryDemo", tags = {"JvmMemory"})
@RestController
@RequestMapping("/jvm/file")
public class JvmMemoryDemoController {
private int count=0;
static class TestMemory {
int foo;
}
//声明缓存对象
private static final Map map = new HashMap();
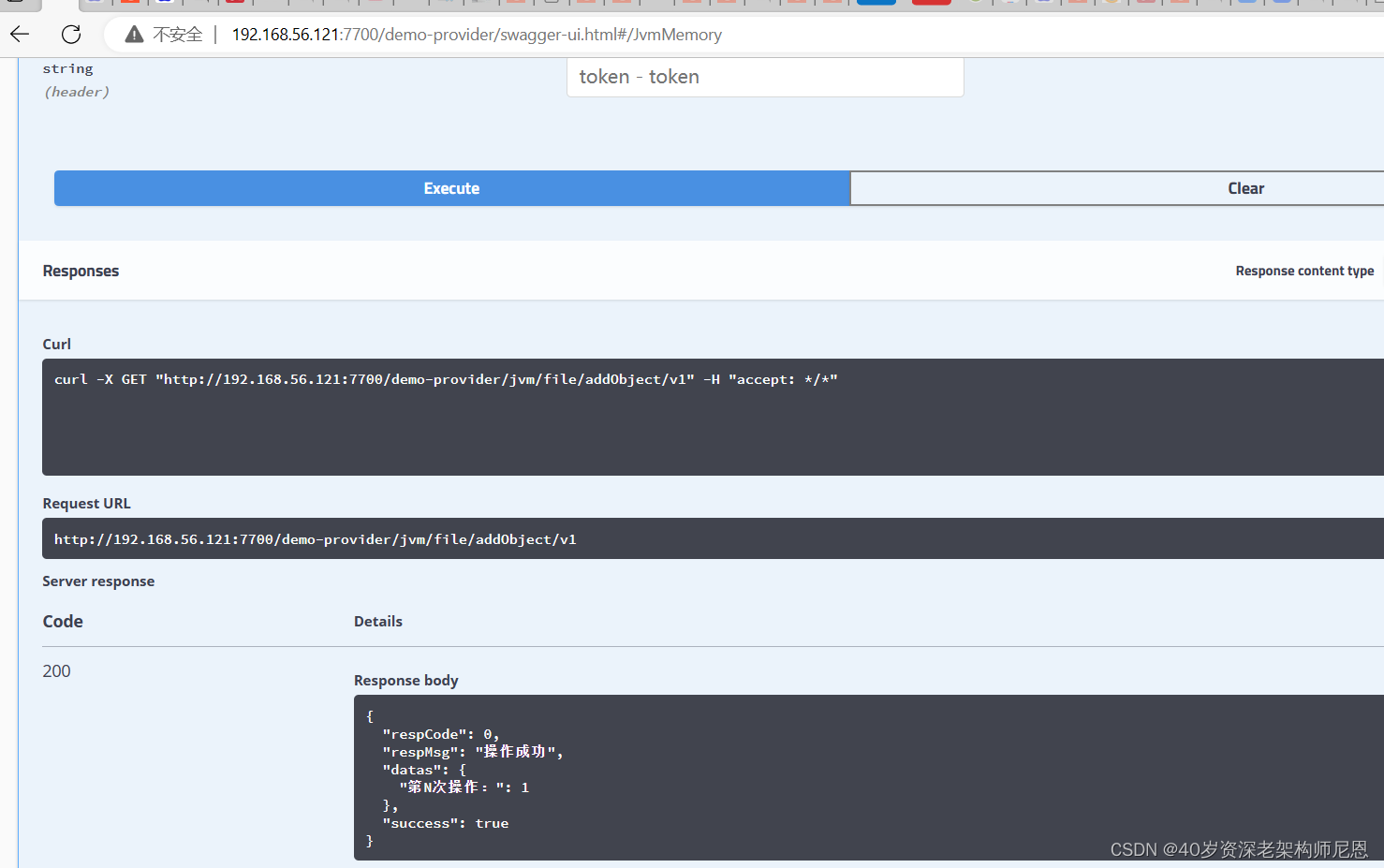
@GetMapping("/addObject/v1")
@ApiOperation(value = "添加对象到缓存")
public RestOut<JSONObject> addObject()
{
//循环添加对象到缓存
for(int i=0; i<1_000_000;i++){
TestMemory t = new TestMemory();
map.put("key"+i,t);
}
JSONObject data = new JSONObject();
data.put("第N次操作:", ++count);
return RestOut.success(data).setRespMsg("操作成功");
}
}
3、配置jvm参数如下:
-Xms150m
-Xmx150m
第1步: 点击 测试接口
http://192.168.56.121:7700/demo-provider/swagger-ui.html
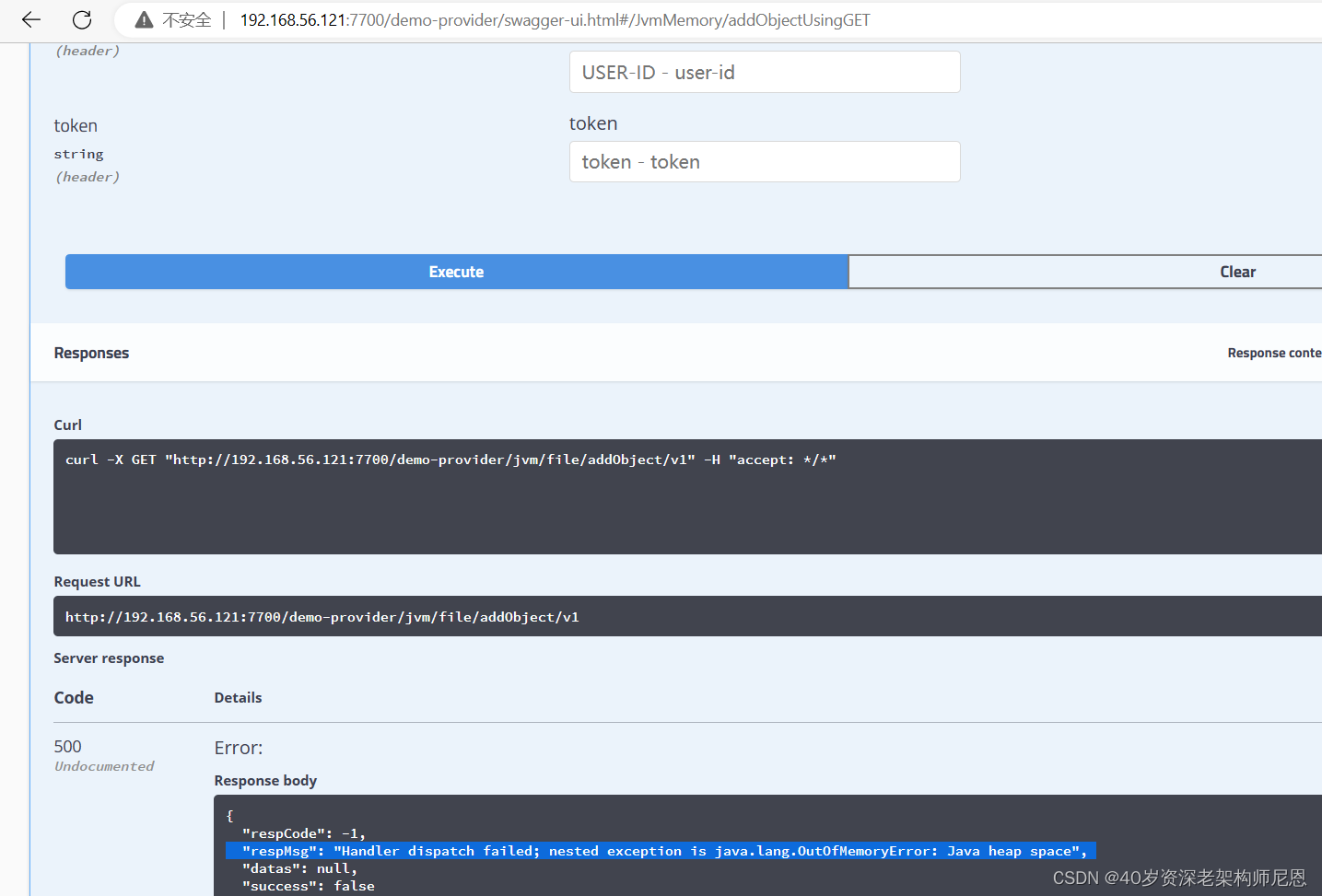
第2步: Jvm发生内存溢出,再说导出堆
java.lang.OutOfMemoryError: Java heap space
Dumping heap to /vagrant/chapter26/java_pid26149.hprof ...
Heap dump file created [208327083 bytes in 1.117 secs]
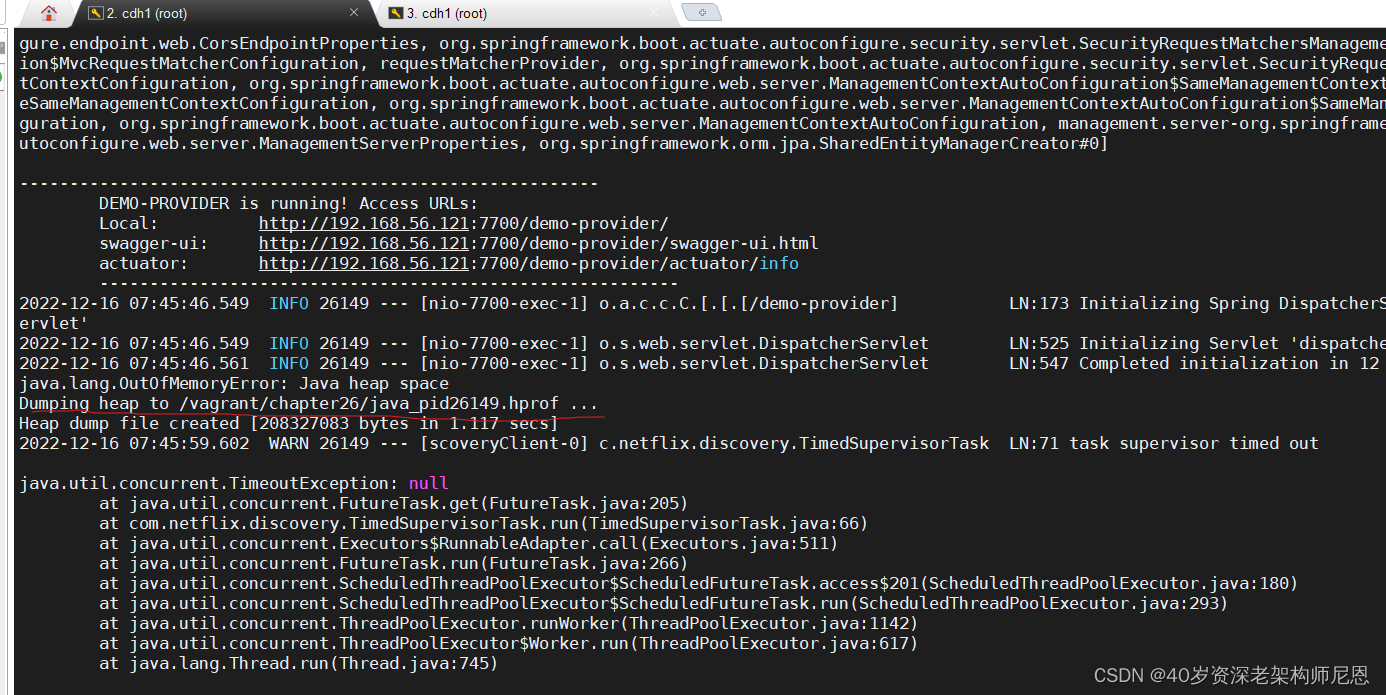
第3步: 找到dump文件
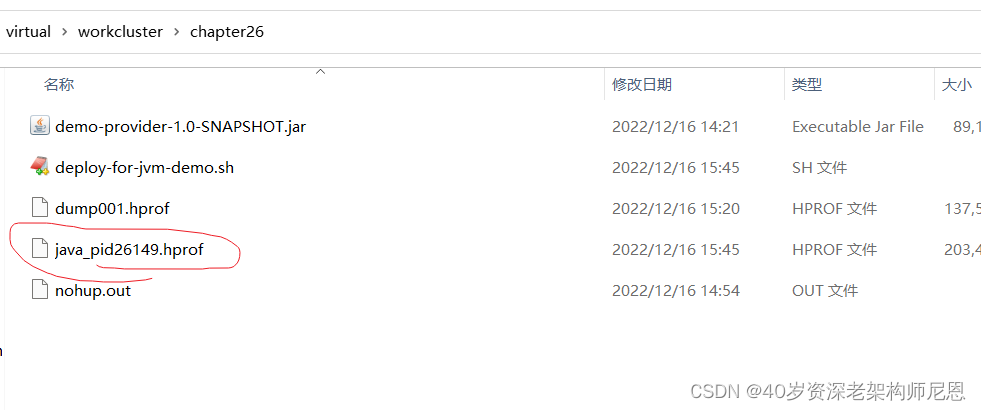
第4步: 装入dump文件到JvirtualVm
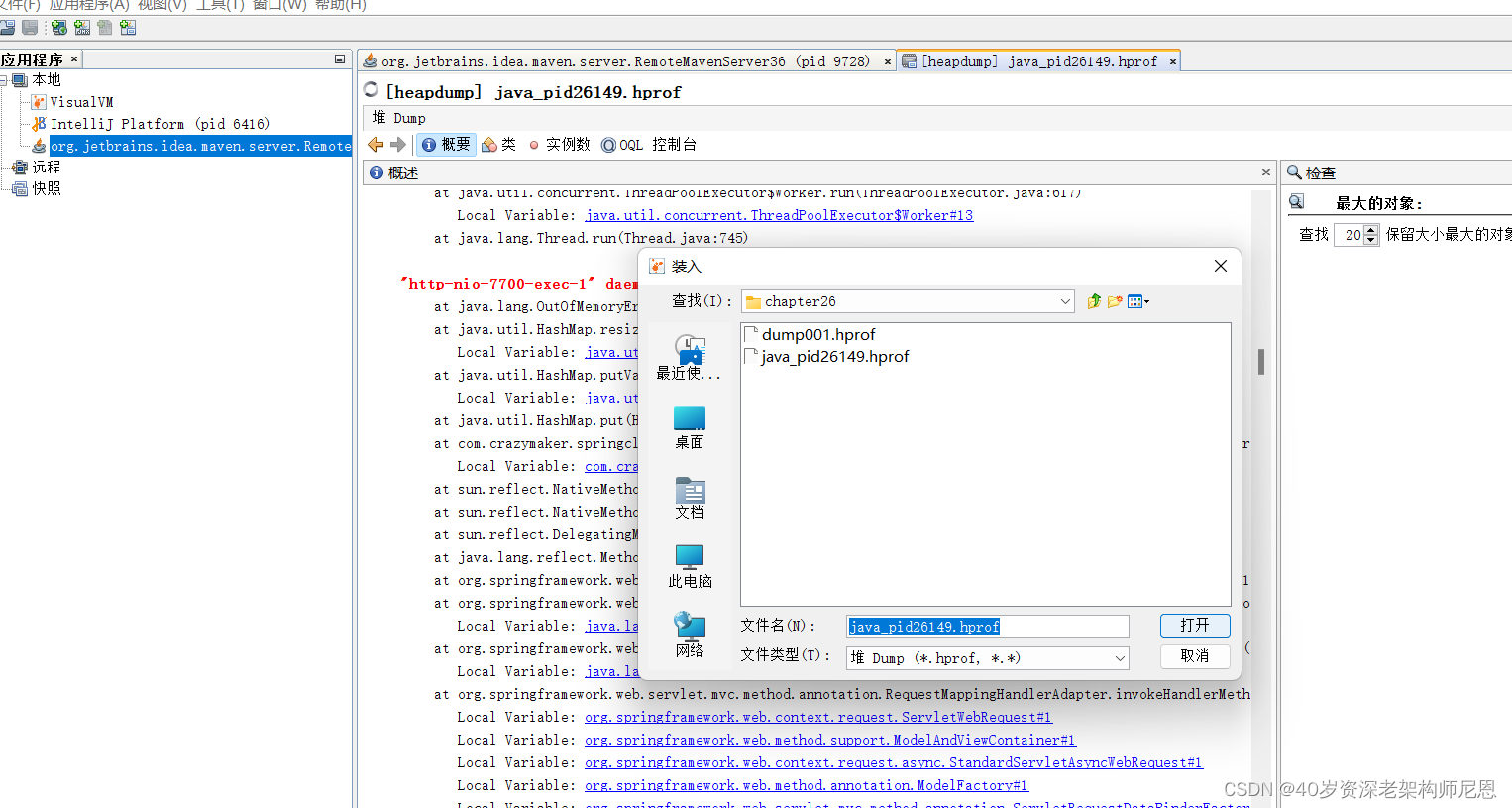
第5步: JVisualVM查看类的信息
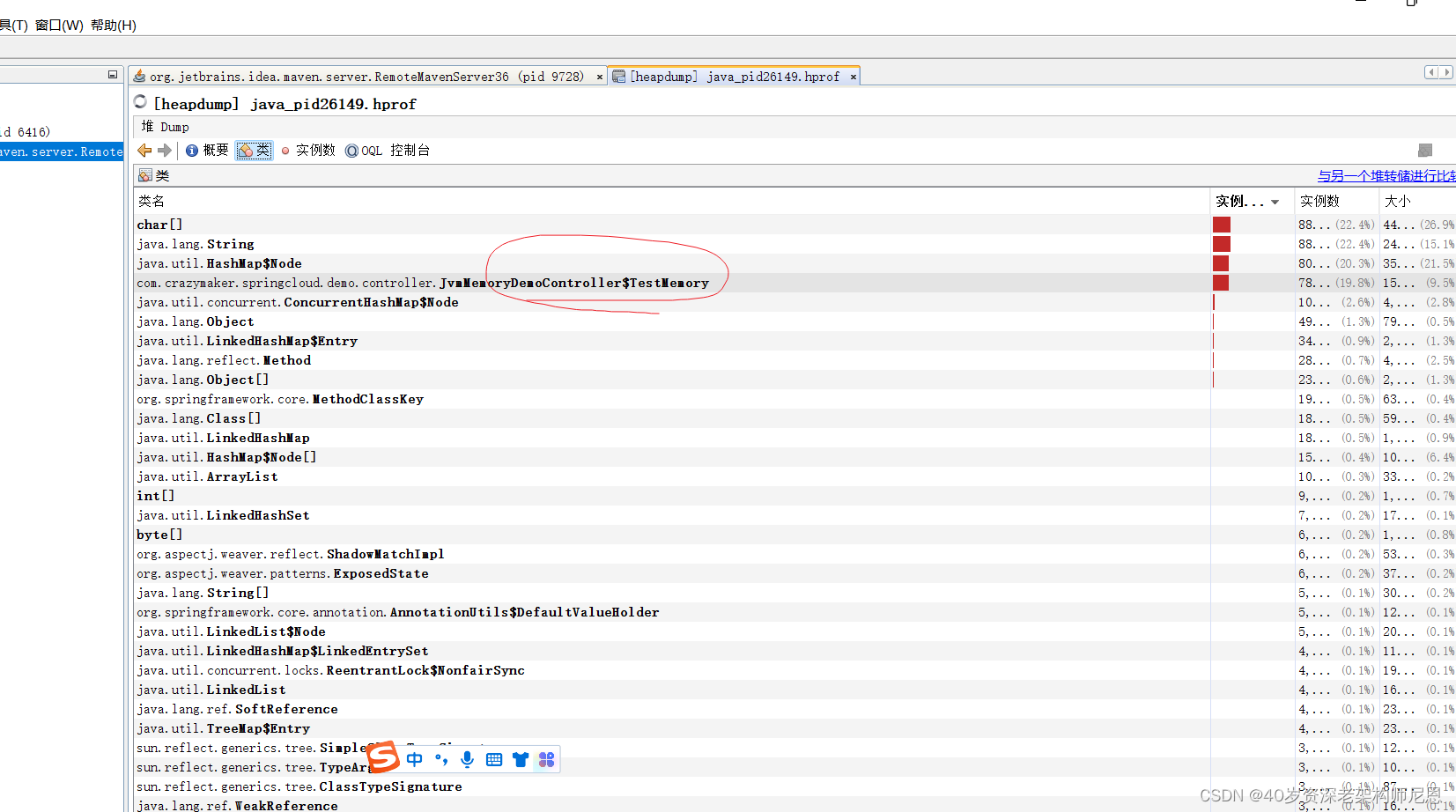
第6步: JVisualVM查看实例的信息
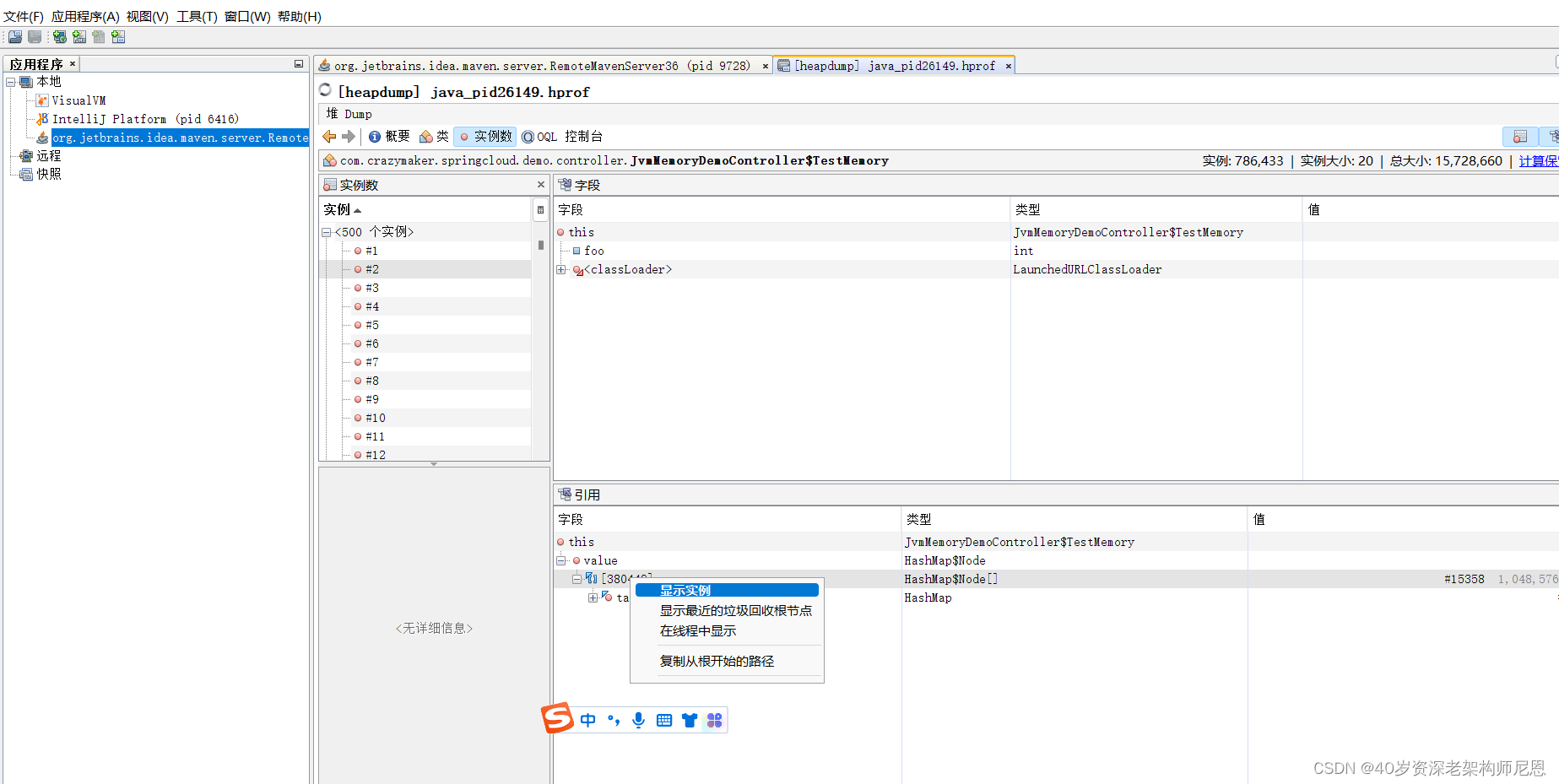
通过GC-Root 对象,查看线程信息
第7步: JVisualVM查看线程的信息
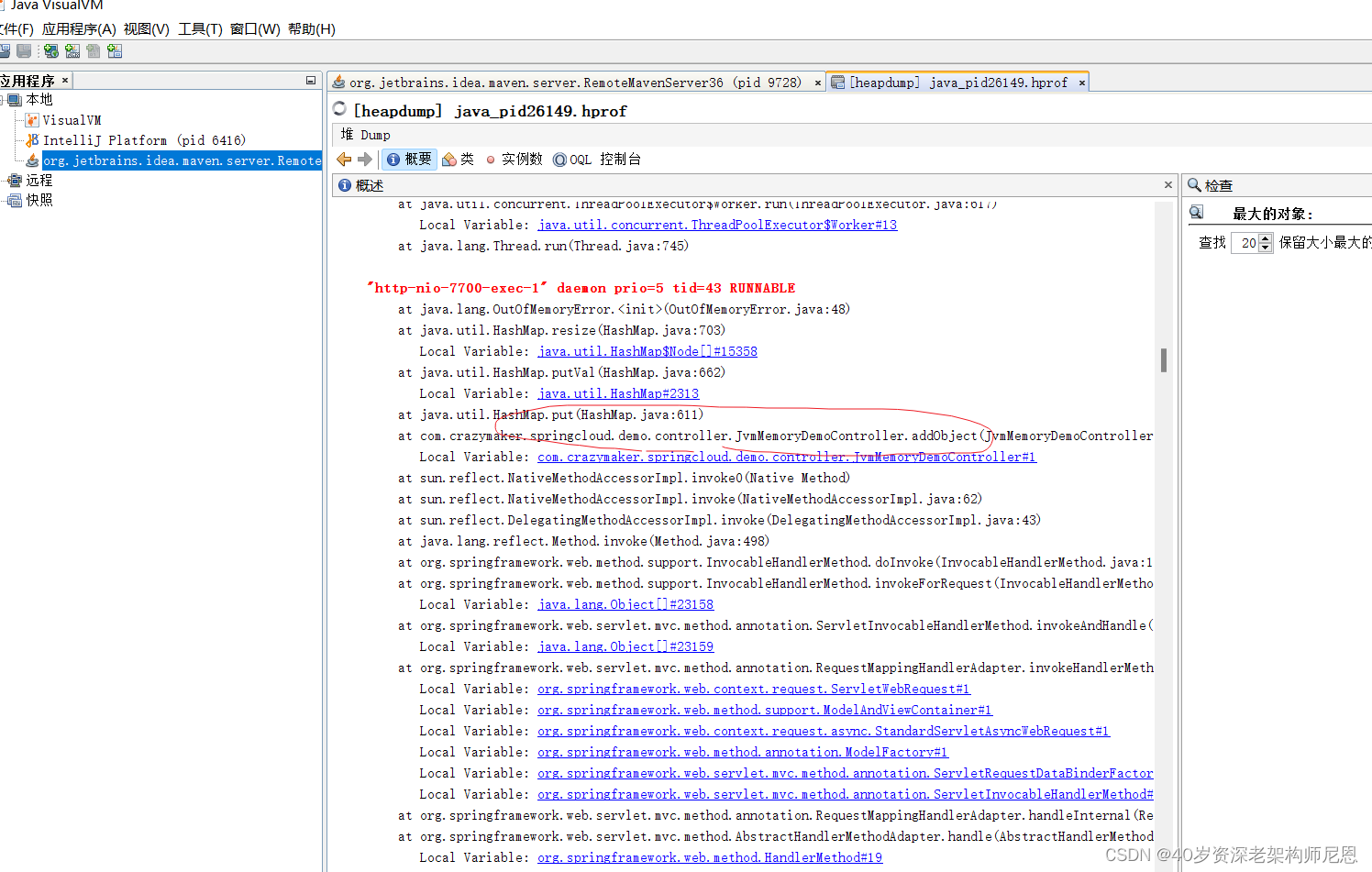
实操2:使用JVisualVM分析内存泄漏
相关命令:导出堆的dump文件
1.查看进程id
jps
2.查看内存状态
jmap -heap 进程ID
3.查看JVM堆中对象详情占用情况
jmap -histo 进程ID
4.导出整个JVM 中内存信息,可以利用其它工具打开dump文件分析,例如jdk自带的visualvm工具
jmap -dump:file=文件名.dump [pid]
jmap -dump:format=b,file=文件名 [pid]
format=b指定为二进制格式文件
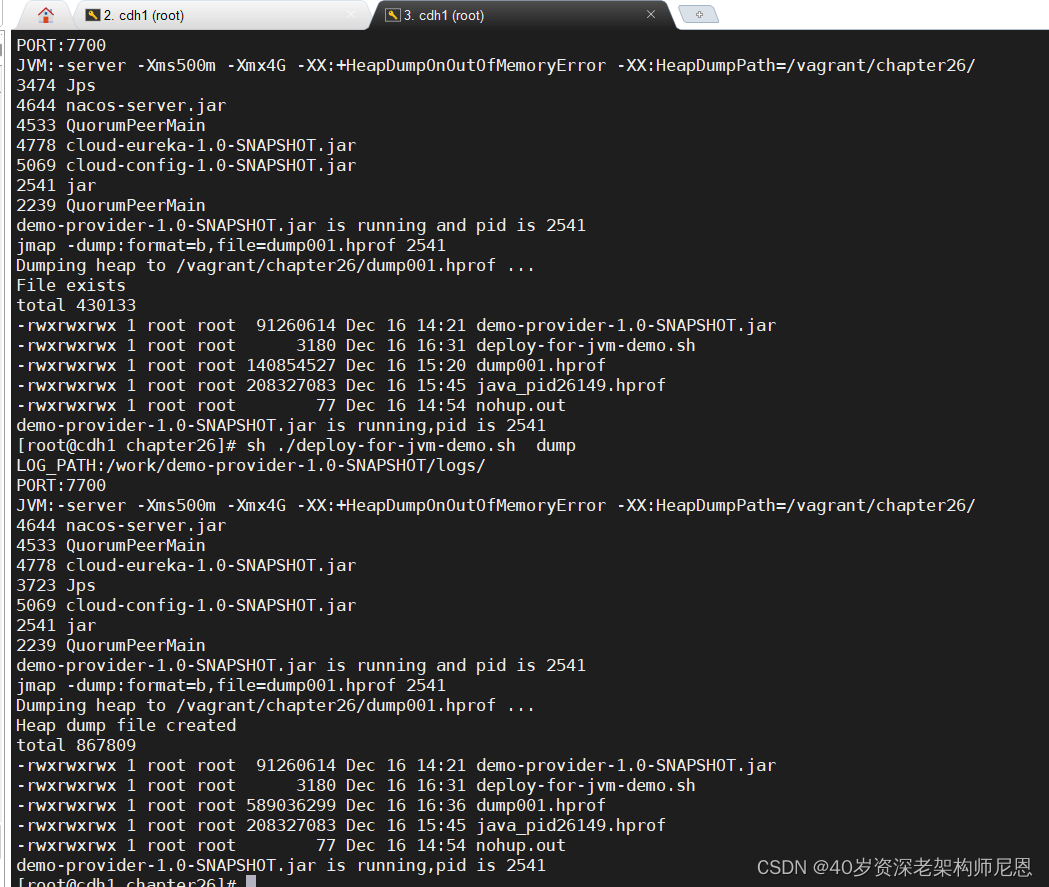
一般情况下,是 在shell脚本,配置这些选项:
使用脚本,速度更快:
function dump() {
pid=$(ps -ef | grep -v 'grep' | egrep $JAR_NAME| awk '{printf $2 " "}')
jps
echo "${JAR_NAME} is running and pid is $pid"
if [ "$pid" != "" ]; then
# jmap -dump:format=b,file=文件名
cmd="jmap -dump:format=b,file=dump001.hprof $pid"
echo $cmd
eval $cmd
ls -l
else
echo "${JAR_NAME} is stopped"
fi
status
}
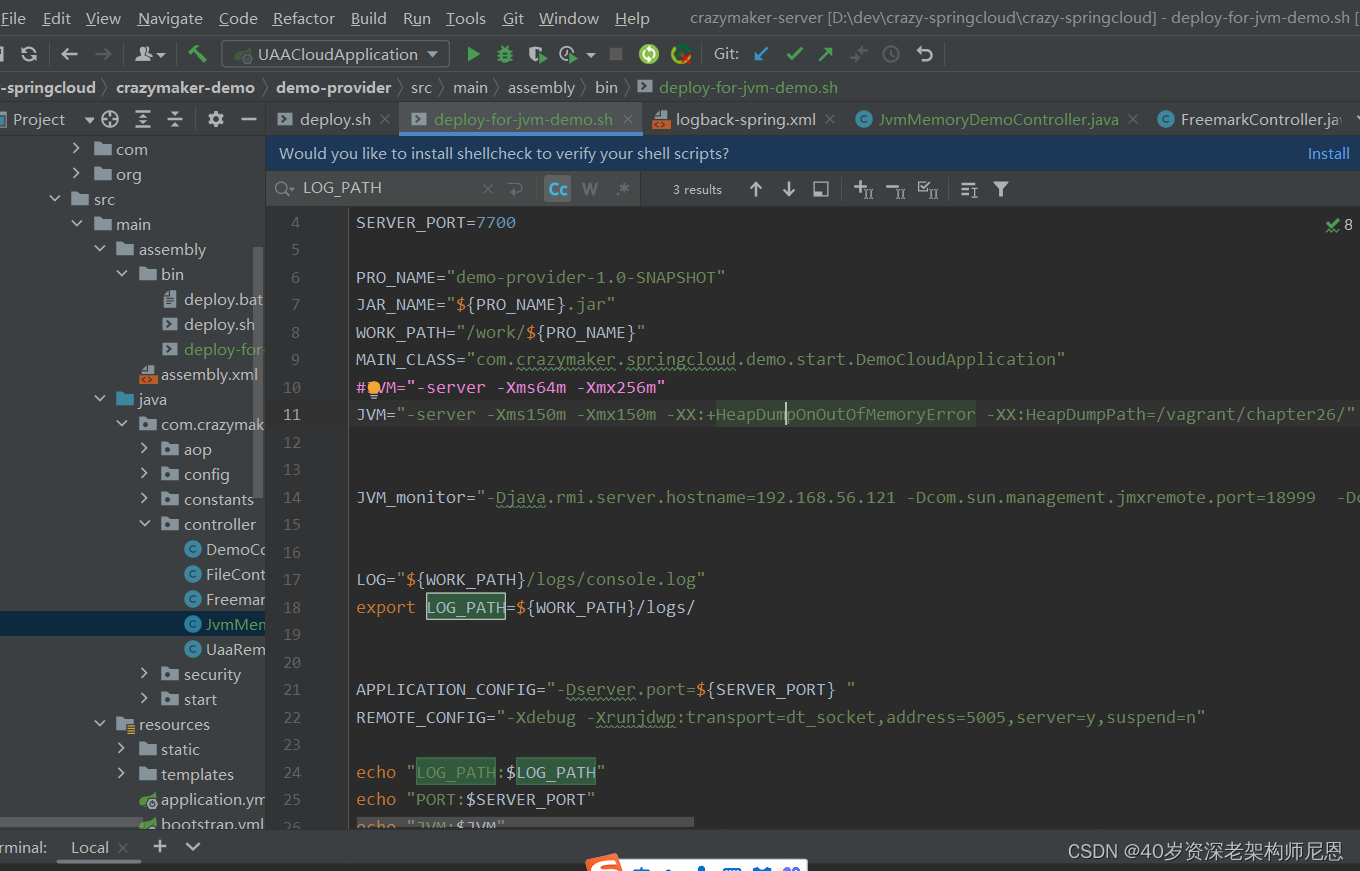
第1步:调整配置
免得一次就oom了,这一次,需要晚点oom
PRO_NAME="demo-provider-1.0-SNAPSHOT"
JAR_NAME="${PRO_NAME}.jar"
WORK_PATH="/work/${PRO_NAME}"
MAIN_CLASS="com.crazymaker.springcloud.demo.start.DemoCloudApplication"
#JVM="-server -Xms64m -Xmx256m"
#JVM="-server -Xms150m -Xmx150m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/vagrant/chapter26/"
JVM="-server -Xms500m -Xmx4G -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/vagrant/chapter26/"
第2步:开始启动应用
http://192.168.56.121:7700/demo-provider/swagger-ui.html
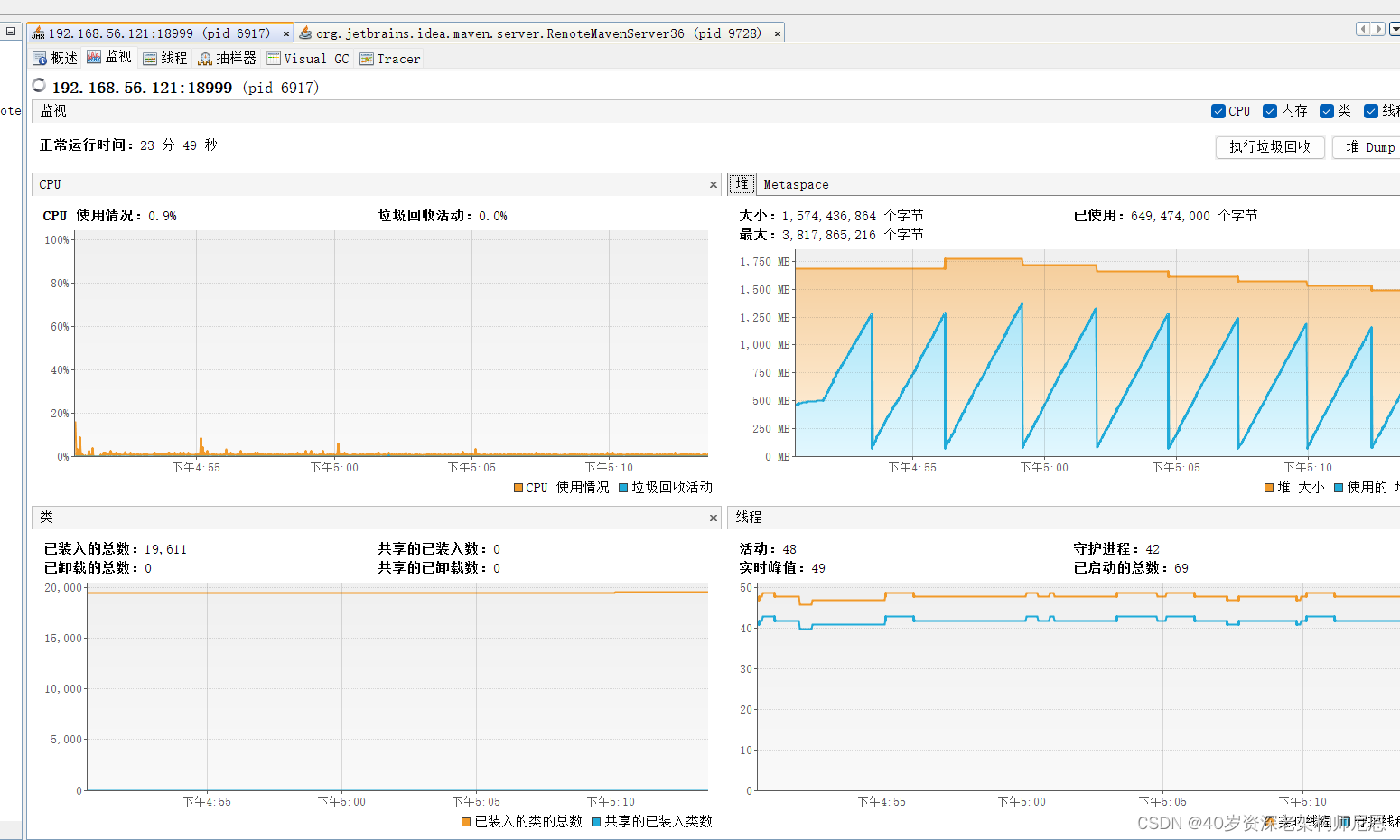
第3步:JVisualVM 远程监控 SpringBoot应用
1、修改远程jvm的启动命令,在其中增加:
JVM_monitor="-Djava.rmi.server.hostname=192.168.56.121 -Dcom.sun.management.jmxremote.port=18999 -Dcom.sun.management.jmxremote.rmi.port=18998 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false"
这次配置先不走权限校验。
只是打开jmx端口。
2、打开jvisualvm,右键远程,选择添加远程主机:
3、输入主机的名称,直接写ip,如下:

右键新建的主机,选择添加JMX连接,输入在tomcat中配置的端口即可。
4、双击打开。
导入JVisualVM,并且Visual GC标签,内容如下,
这是输出first的截图
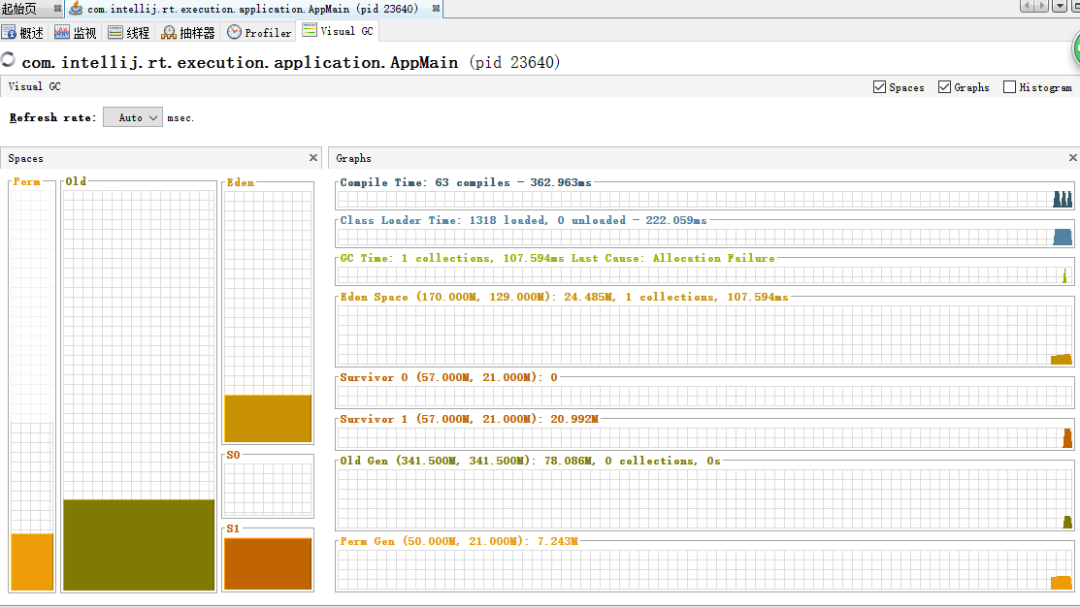
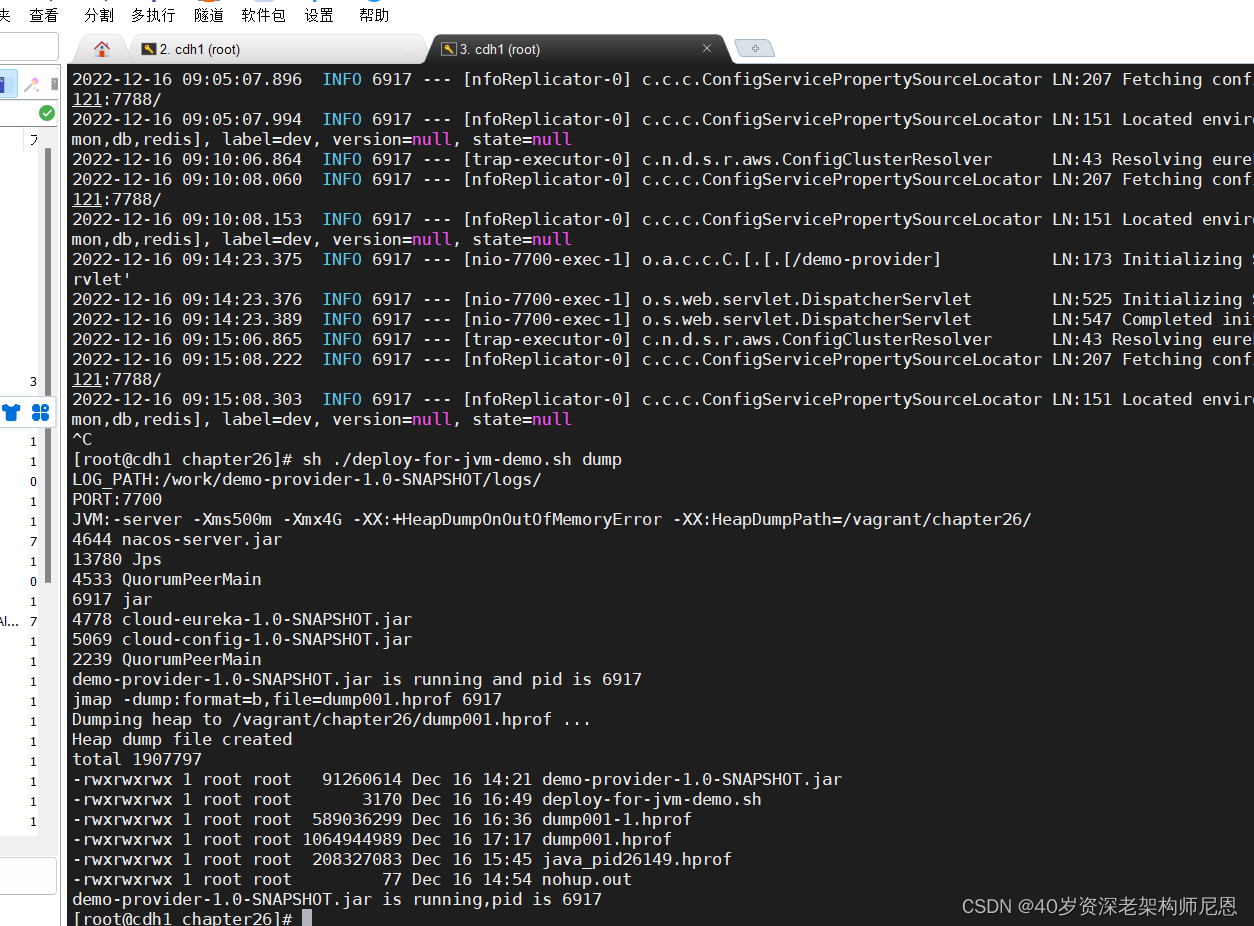
第4步:第一次请求和dump
dump 堆,这里使用 脚本,没有直接使用 jmap 命令
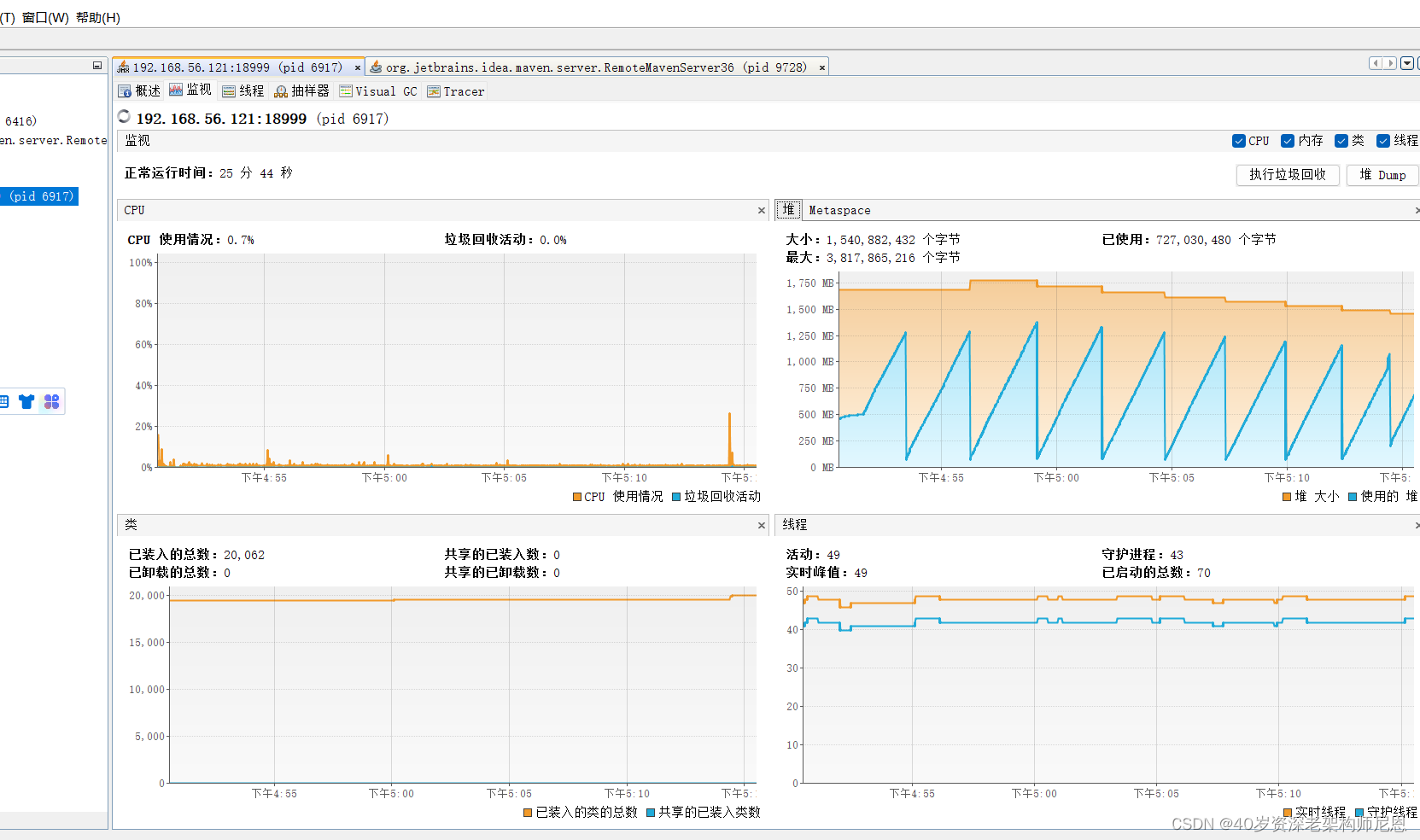
第1次请求之后,
第5步:第2次请求和dump
第2次请求之后
dump 堆,这里使用 脚本,没有直接使用 jmap 命令
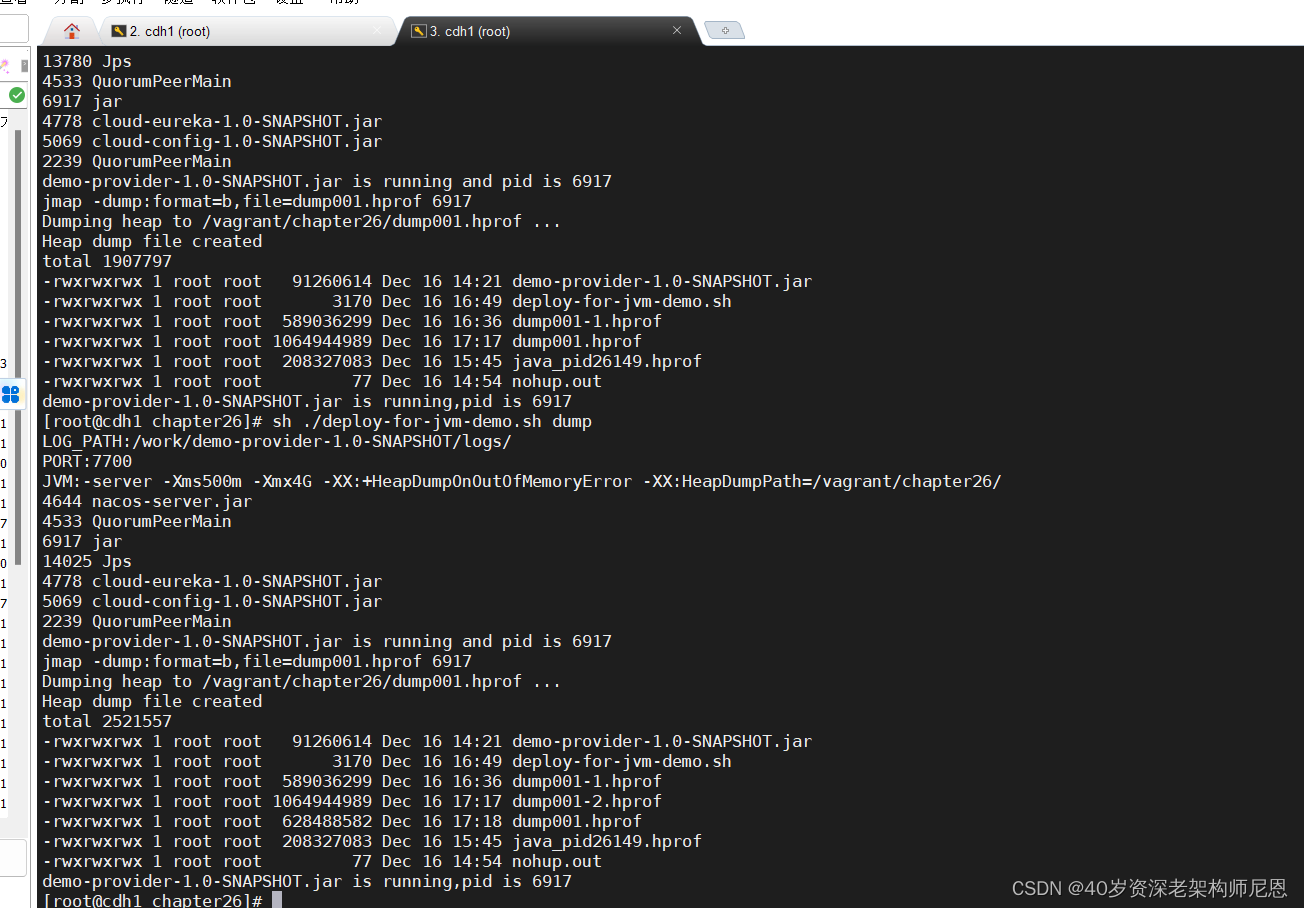
第6步:第6次请求和dump
第6次请求之后

dump 堆,这里使用 脚本,没有直接使用 jmap 命令
第3步:对照三个dump文件
进入最后dump出来的堆标签,点击类:

点击右上角:“与另一个堆存储对比”。如图选择第一次导出的dump内容比较:

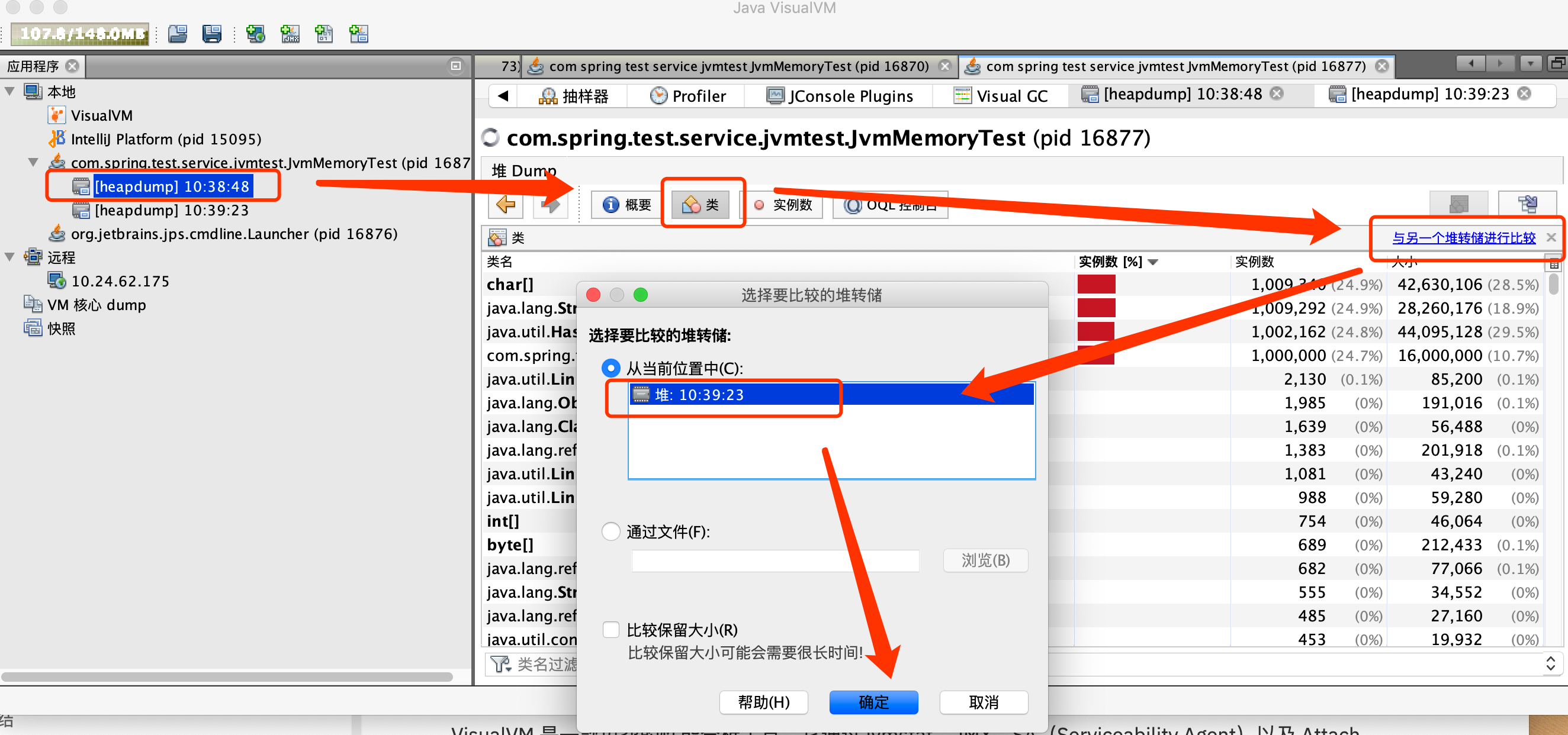
比较结果如下:

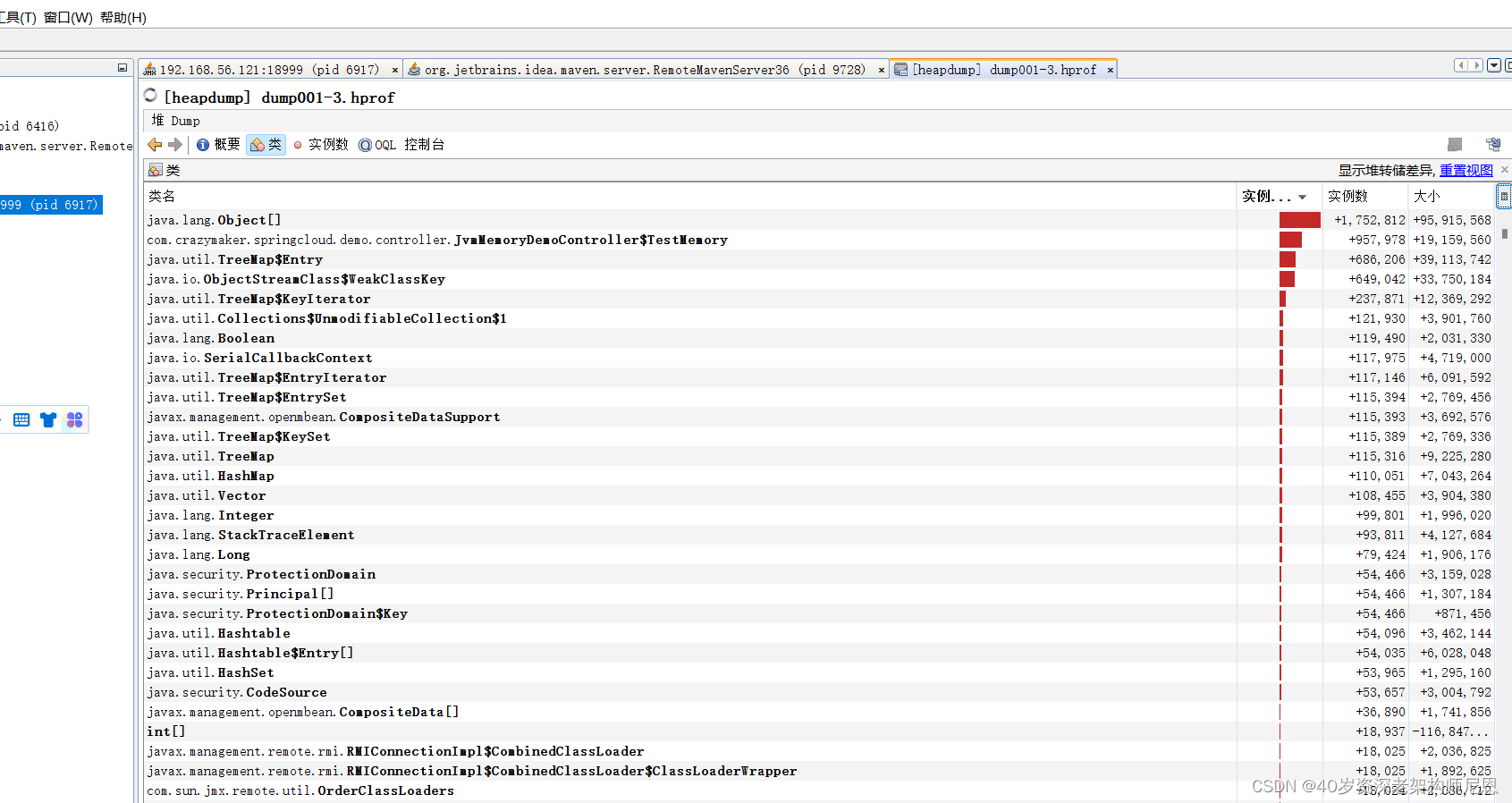
可以看出在两次间隔时间内TestMemory对象实例一直在增加并且多了,说明该对象引用的方法可能存在内存泄漏。
如何查看对象引用关系呢?
右键选择类TestMemory,选择“在实例视图中显示”,如下所示:
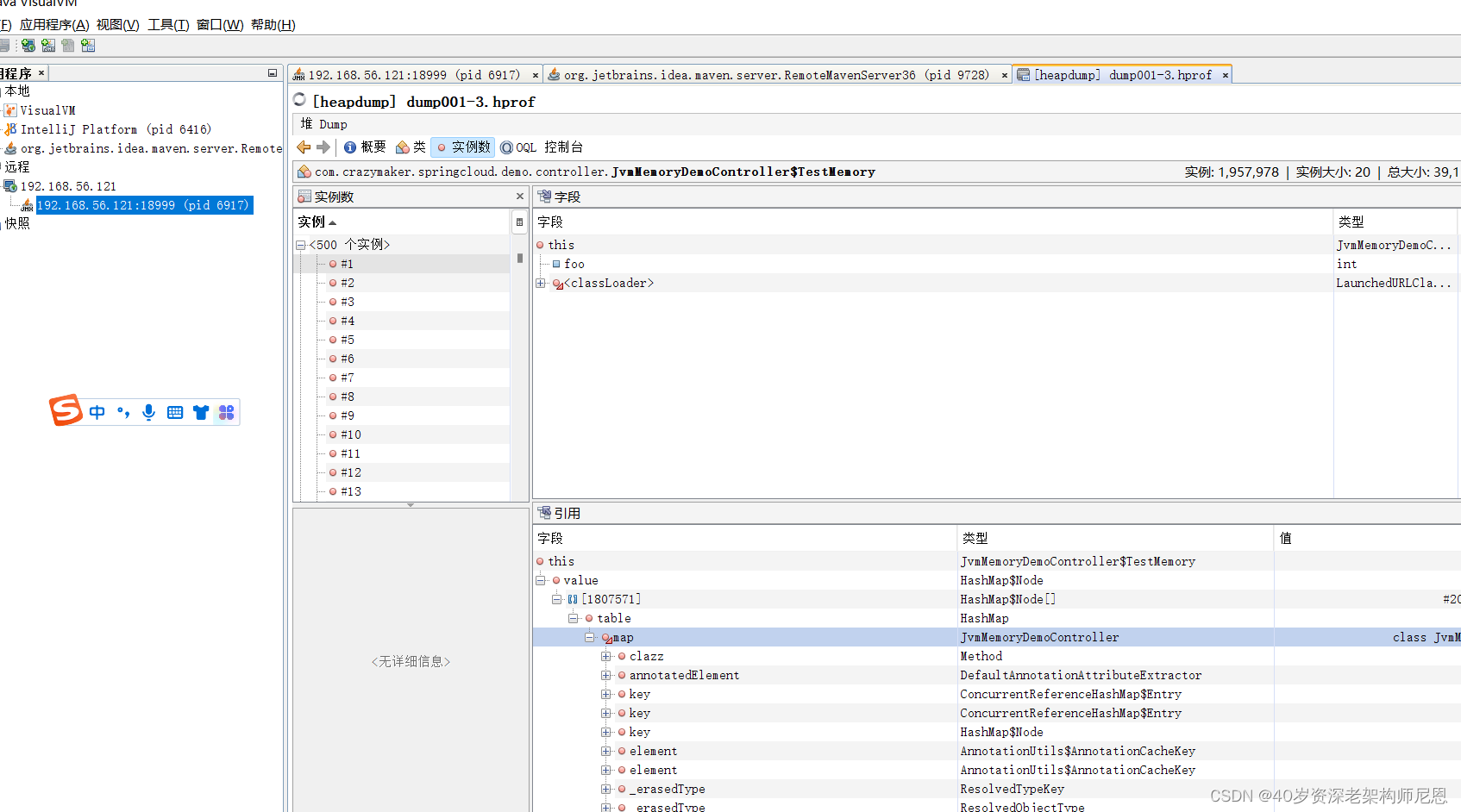
- 左侧是创建的实例总数,
- 右侧上部为该实例的结构,
- 下面为引用说明,
从图中可以看出在类JvmMemoryDemoController里面被引用了,并且被HashMap引用。
如此可以确定泄漏的位置,进而根据实际情况进行分析解决。
如何进行JVM调优
观察内存释放情况、集合类检查、对象树
上面这些调优工具都提供了强大的功能,但是总的来说一般分为以下几类功能
堆信息查看
可查看堆空间大小分配(年轻代、年老代、持久代分配)
提供即时的垃圾回收功能
垃圾监控(长时间监控回收情况)

查看堆内类、对象信息查看:数量、类型等

对象引用情况查看
有了堆信息查看方面的功能,我们一般可以顺利解决以下问题:
– 年老代年轻代大小划分是否合理
– 内存泄漏
– 垃圾回收算法设置是否合理
线程监控
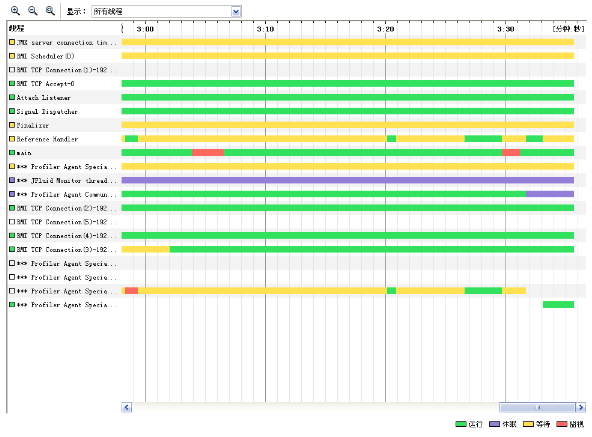
线程信息监控:系统线程数量。
线程状态监控:各个线程都处在什么样的状态下

Dump线程详细信息:查看线程内部运行情况
死锁检查
热点分析
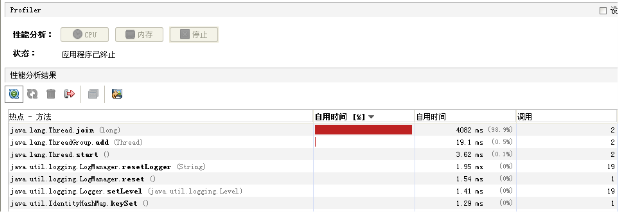
CPU热点:检查系统哪些方法占用的大量CPU时间
内存热点:检查哪些对象在系统中数量最大(一定时间内存活对象和销毁对象一起统计)
这两个东西对于系统优化很有帮助。
我们可以根据找到的热点,有针对性的进行系统的瓶颈查找和进行系统优化,而不是漫无目的的进行所有代码的优化。
快照分析
快照是系统运行到某一时刻的一个定格。
在我们进行调优的时候,不可能用眼睛去跟踪所有系统变化,
依赖快照功能,我们就可以进行系统两个不同运行时刻,对象(或类、线程等)的不同,以便快速找到问题
举例说,我要检查系统进行垃圾回收以后,是否还有该收回的对象被遗漏下来的了。
那么,我可以在进行垃圾回收前后,分别进行一次堆情况的快照,然后对比两次快照的对象情况。
内存泄漏检查
内存泄漏是比较常见的问题,而且解决方法也比较通用,这里可以重点说一下,而线程、热点方面的问题则是具体问题具体分析了。
内存泄漏一般可以理解为系统资源(各方面的资源,堆、栈、线程等)在错误使用的情况下,导致使用完毕的资源无法回收(或没有回收),从而导致新的资源分配请求无法完成,引起系统错误。
内存泄漏对系统危害比较大,因为他可以直接导致系统的崩溃。
需要区别一下,内存泄漏和系统超负荷两者是有区别的,虽然可能导致的最终结果是一样的。
内存泄漏是用完的资源没有回收引起错误,而系统超负荷则是系统确实没有那么多资源可以分配了(其他的资源都在使用)。
年老代堆空间被占满
异常: java.lang.OutOfMemoryError: Java heap space
说明:
这是最典型的内存泄漏方式,简单说就是所有堆空间都被无法回收的垃圾对象占满,虚拟机无法再在分配新空间。
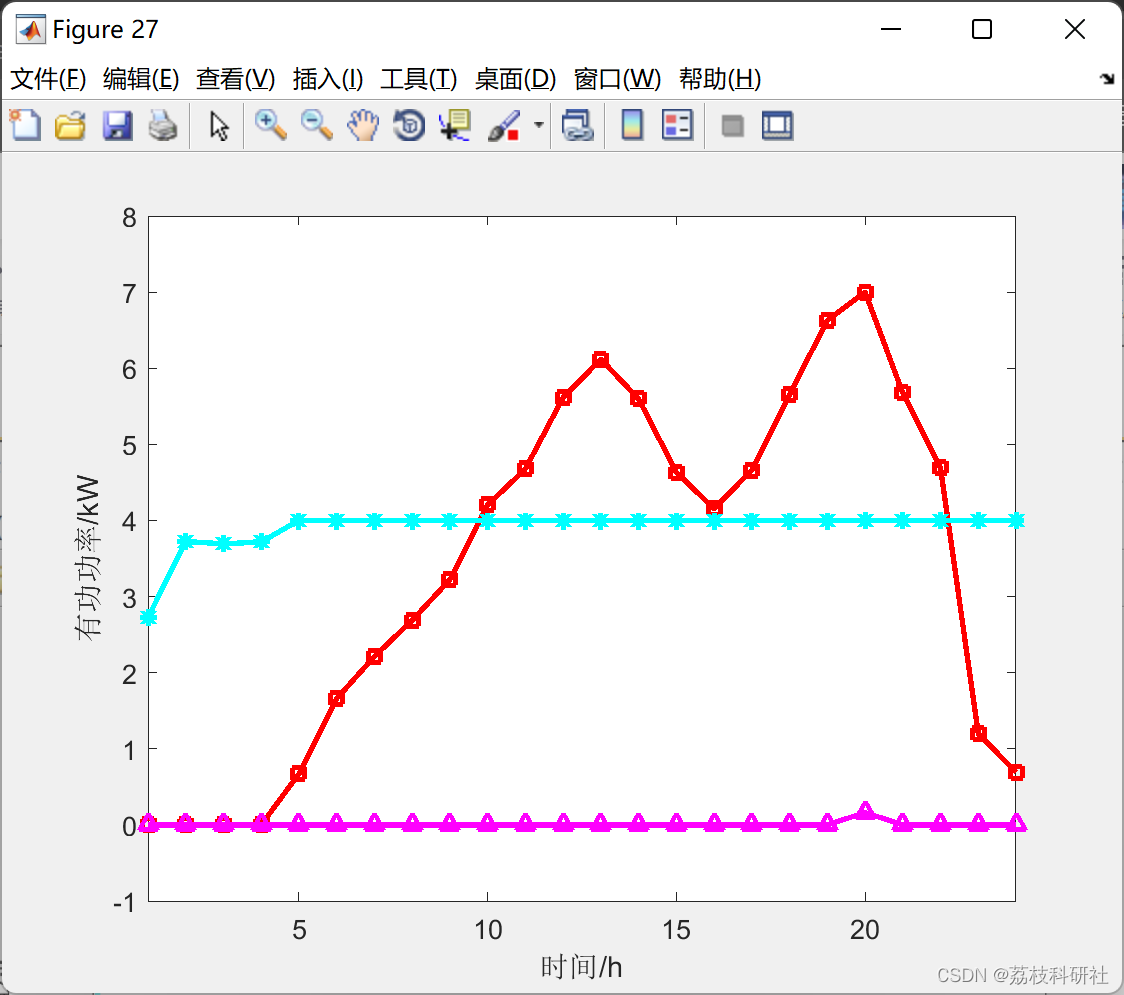
如上图所示,这是非常典型的内存泄漏的垃圾回收情况图。
所有峰值部分都是一次垃圾回收点,所有谷底部分表示是一次垃圾回收后剩余的内存。
连接所有谷底的点,可以发现一条由底到高的线,这说明,随时间的推移,系统的堆空间被不断占满,最终会占满整个堆空间。因此可以初步认为系统内部可能有内存泄漏。
(上面的图仅供示例,在实际情况下收集数据的时间需要更长,比如几个小时或者几天)
解决:
这种方式解决起来也比较容易,一般就是根据垃圾回收前后情况对比,同时根据对象引用情况(常见的集合对象引用)分析,基本都可以找到泄漏点。
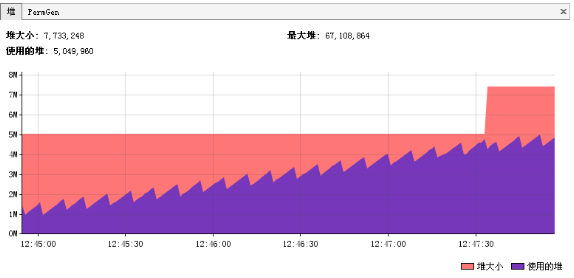
持久代被占满
异常:java.lang.OutOfMemoryError: PermGen space
说明:
Perm空间被占满。
无法为新的class分配存储空间而引发的异常。这个异常以前是没有的,但是在Java反射大量使用的今天这个异常比较常见了。主要原因就是大量动态反射生成的类不断被加载,最终导致Perm区被占满。
更可怕的是,不同的classLoader即便使用了相同的类,但是都会对其进行加载,相当于同一个东西,如果有N个classLoader那么他将会被加载N次。因此,某些情况下,这个问题基本视为无解。当然,存在大量classLoader和大量反射类的情况其实也不多。
解决:
- -XX:MaxPermSize=16m
- 换用JDK。比如JRocket。
堆栈溢出
异常:java.lang.StackOverflowError
说明:这个就不多说了,一般就是递归没返回,或者循环调用造成
线程堆栈满
异常:Fatal: Stack size too small
说明:java中一个线程的空间大小是有限制的。JDK5.0以后这个值是1M。与这个线程相关的数据将会保存在其中。但是当线程空间满了以后,将会出现上面异常。
解决:增加线程栈大小。-Xss2m。但这个配置无法解决根本问题,还要看代码部分是否有造成泄漏的部分。
系统内存被占满
异常:java.lang.OutOfMemoryError: unable to create new native thread
说明:
这个异常是由于操作系统没有足够的资源来产生这个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
分配给Java虚拟机的内存愈多,系统剩余的资源就越少,因此,当系统内存固定时,分配给Java虚拟机的内存越多,那么,系统总共能够产生的线程也就越少,两者成反比的关系。同时,可以通过修改-Xss来减少分配给单个线程的空间,也可以增加系统总共内生产的线程数。
解决:
- 重新设计系统减少线程数量。
- 线程数量不能减少的情况下,通过-Xss减小单个线程大小。以便能生产更多的线程。
jvm参数优化建议
本质上是减少GC的次数。
如果是频繁创建对象的应用,可以适当增加新生代大小。常量较多可以增加持久代大小。对于单例较多的对象可以增加老生代大小。比如spring应用中。
GC选择,在JDK5.0以后,JVM会根据当前系统配置进行判断。一般执行-Server命令便可以。
gc包括三种策略:串行,并行,并发。
吞吐量大大应用,一般采用并行收集,开启多个线程,加快gc的是否。
响应速度高的应用,一般采用并发收集,比如应用服务器。
年老代建议配置为并发收集器,由于并发收集器不会压缩和整理磁盘碎片,因此建议配置:
-XX:+UseConcMarkSweepGC #并发收集年老代
-XX:CMSInitiatingOccupancyFraction=80 # 表示年老代空间到80%时就开始执行CMS
-XX:+UseCMSCompactAtFullCollection # 打开对年老代的压缩。可能会影响性能,但是可以消除内存碎片。
-XX:CMSFullGCsBeforeCompaction=10 # 由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此参数设置运行次FullGC以后对内存空间进行压缩、整理。
如何防止被Linux系统OOM ( Out Of Memory Killer)暗杀
Linux内核根据服务器上当前运行应用的需要来分配内存。
因为这通常是预先发生的,所以应用并不会使用所有分配的内存。这将会导致资源浪费,Linux内核允许超分内存以提高内存使用效率。
Linux内核允许超分内存,比如总共8G内存,可以分给10个进程各1G,这通常没问题。
但问题发生在太多应用一起占用内存,有8个进程各占了1G,剩下两个进程要喝西北风了。
由于内存不足,服务器有崩溃的风险。
The server runs the risk of crashing because it ran out of memory。
为了防止服务器到达这个临近状态,内核中有一个OOM Killer杀手进程。
To prevent the server from reaching that critical state, the kernel also contains a process known as the OOM Killer。
内核利用这个杀手进程开始屠杀那些非必要进程,以便服务器正常运行。
The kernel uses this process to start killing non-essential processes so the server can remain operational.
当你认为这一切都不是问题时,因为OOM Killer只杀掉那些非必要的,不是用户需要的进程。
举例,两个应用(Apache和MySQL)通常先被杀掉,因为占用大量的内存。但这将导致一个web网站立马瘫痪了。
为啥某个进程被杀?
当尝试找到为什么一个应用程序或进程被OOM killer杀掉时,有很多地方可以找到一个进程如何被杀掉以及被杀掉的原因。
1) 系统日志
$ grep -i kill /var/log/messages
host kernel: Out of Memory: Killed process 5123 (exampleprocess)
The capital K in Killed tells you that the process was killed with a -9 signal, and this typically is a good indicator that the OOM Killer is to blame.
2) 检查服务器的高低内存统计
$ free -lh
The -l switch shows high and low memory statistics, and the -h switch puts the output into gigabytes for easier human readability. You can change this to the -m switch if you prefer the output in megabytes.
同时该命令会给出Swap内存使用信息。
注意:free命令给出某个时刻得数据,需要多执行几次才能知道内存动态的占用情况。
3) vmstat可以给出某个时间段内的内存使用情况
$ vmstat -SM 10 20
20次,每次间隔10秒给出内存使用情况。
4) top命令查看内存
top 默认输出CPU的使用情况,不过你可以在top后再按下shift + M,你将得到内存的使用情况。
如何配置(Configure the OOM Killer)
1) 内存不足则重启
配置文件 /etc/sysctl.conf:
sysctl vm.panic_on_oom=1
sysctl kernel.panic=X
使用命令
echo “vm.panic_on_oom=1” >> /etc/sysctl.conf
echo “kernel.panic=X” >> /etc/sysctl.conf
大多数情况下,内存不足时每次都重启是不合适的。
2) 修改进程的优先级
既可以保护一些重要进程不被OMM killer杀掉,又可以让不重要的进程更容易杀掉:
echo -15 > /proc/(PID)/oom_adj (不被杀)
echo 10 > /proc/(PID)/oom_adj (更易杀)
pstree -p | grep "process" | head -1
3) 豁免一个进程Exempt a process
在某些情况下,豁免进程可能导致意外的行为变化,取决于系统和资源配置。
假如内核无法杀死一个占用大量内存的进程,将杀死其他进程,包括那些重要的操作系统进程。
由于OOM killer可调节的有效范围在-16到+15之间,设置为-17将豁免一个进程,因为在OOM killer调节范围之外。
通常的规则是这个参数越大越容易被杀死豁免一个进程的命令是
echo -17 > /proc/(PID)/oom_adj
4) 有风险的参数
警告:不建议用于生产环境。
假如重启,修改进程优先级,豁免一个进程不足够好,有个风险的选项:
将oom killer 功能关闭。
sysctl vm.overcommit_memory=2
使用命令
echo “vm.overcommit_memory=2” >> /etc/sysctl.conf
这一选项参数将有如下影响:
- 严重的内核恐慌kernel panic
- 系统挂住system hang-up
- 一个完整的系统崩溃system crash
为什么关闭有风险呢呢?
如果你关闭此功能,将不能避免内存耗尽。考虑此项时请极度慎重。不推荐用在生产环境
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从下面的链接获取:语雀 或者 码云
参考文献:
http://www.manongjc.com/detail/63-vghxrdhsiblevlf.html
https://www.cnblogs.com/krock/p/14421332.html
https://www.cnblogs.com/krock/p/14421332.html
https://www.cnblogs.com/pxblog/p/16102490.html
https://blog.csdn.net/lusa1314/article/details/84134458
https://www.bilibili.com/video/BV12S4y1u7bY/?spm_id_from=333.788
推荐阅读:
《尼恩Java面试宝典》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《TCP协议详解 (史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)
《单例模式(史上最全)
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》