目录
- 1、为什么要设计TLB?
- TLB中不包含我们需要的映射关系怎么办?
- 2、TLB中都包含了啥?
- 3、那什么是ASID
- Address Space ID(ASID)
- 4、小结
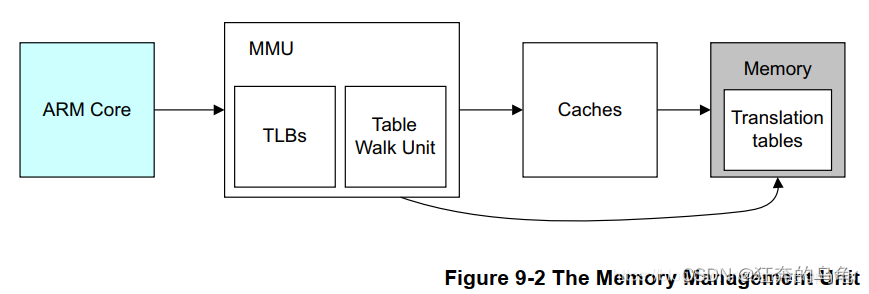 内存寻址简要过程如下:VA以页表大小取余,得到PA的低位,关键是PA的高位(PFN)如何得到。内存中存放着页表,页表记录的是VPN到PFN的对应关系(一般可能会分为多级页表),以VPN查询页表即可获得PFN。为了加速这个查询,引入了TLB,TLB记录的是一个内存页表的一个子集,相当于是内存页表的缓存。所以MMU在以VPN索引先在TLB中查找页表,如果查询TLB miss则会产生异常,由异常处理程序进行地址转换。系统中如果有多个进程,他们访问同样的虚拟地址VA的话,他们的页表缓存对应TLB中同一条目,如果进程切换需要刷新TLB,为了降低进程切换的成本引入ASID(Addrss Space ID)地址空间,OS为每个进程分配各自的ASID(存储在mm_struct.context.id中,这样TLB中可以同时缓存多个进程的页表,进程切换的时候不需要刷TLB了,属于使用一个空间换时间的设计。
内存寻址简要过程如下:VA以页表大小取余,得到PA的低位,关键是PA的高位(PFN)如何得到。内存中存放着页表,页表记录的是VPN到PFN的对应关系(一般可能会分为多级页表),以VPN查询页表即可获得PFN。为了加速这个查询,引入了TLB,TLB记录的是一个内存页表的一个子集,相当于是内存页表的缓存。所以MMU在以VPN索引先在TLB中查找页表,如果查询TLB miss则会产生异常,由异常处理程序进行地址转换。系统中如果有多个进程,他们访问同样的虚拟地址VA的话,他们的页表缓存对应TLB中同一条目,如果进程切换需要刷新TLB,为了降低进程切换的成本引入ASID(Addrss Space ID)地址空间,OS为每个进程分配各自的ASID(存储在mm_struct.context.id中,这样TLB中可以同时缓存多个进程的页表,进程切换的时候不需要刷TLB了,属于使用一个空间换时间的设计。
1、为什么要设计TLB?
TLB 的全称是:Translation Lookaside Buffer;从第一节的那个图可以看出来,MMU 做 Table Walk 的这个 Transliation Tables 是放到主存中,主存访问速度很慢(加 Cache 的根本原因),所以,这里每次都去再主存中做 Table Walk,显然效率非常低,所以,这里就为这个 Table Walk 定制了一个属于他的 “Cache”,称之为 TLB;TLB的设计初衷就是支持将映射表存入缓存区域,大大提高映射效率。在虚拟地址映射时,MMU会检查映射关系是否已经被缓存在了TLB中,如果已被缓存,那么就会引起缓存命中,此映射关系立即可用。
TLB中不包含我们需要的映射关系怎么办?
如果TLB不包含处理器发出的虚拟地址的有效映射,称为TLB缺失,则执行外部映射表查表。MMU内的专用硬件使其能够读取内存中的映射表。然后,新加载的映射可以被缓存在TLB中,以便在映射表查表没有导致页面故障的情况下进行重复使用。
2、TLB中都包含了啥?
每一个TLB条目不仅物理地址和虚拟地址,还包含诸如内存类型、缓存策略、访问权限、地址空间ID(ASID)和虚拟机ID(VMID)等属性。
TLB可以容纳固定数量的条目。我们可以通过最大限度地减少由映射表遍历引起的外部内存访问数量并获得高TLB命中率来实现最佳性能。ARMv8-A架构提供了一个称为连续块条目的功能,可以有效地使用TLB空间。映射表块条目每个都包含一个连续的位。当设置时,该位向TLB发出信号,它可以缓存一个涵盖多个块的映射的单一条目。一个查找可以索引到一个连续块所覆盖的地址范围的任何地方。因此,TLB可以为定义的地址范围缓存一个条目,使得在TLB中存储更大范围的虚拟地址成为可能。
要使用一个连续的位,连续的块必须是相邻的,也就是说它们必须对应于一个连续的虚拟地址范围。它们必须从一个对齐的边界开始,具有一致的属性,并指向同一级别转换的连续输出地址范围。
但是与 真实的Cache是不一样(CPU Cache知识介绍),这个 TLB 是专门缓存 Transliation Tables 的,典型的情况,他的组成如下:
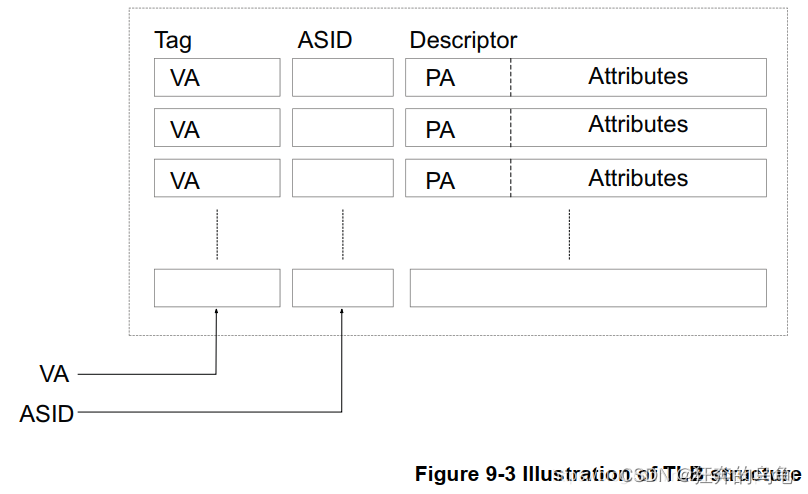
由 VA、ASID、PA、Attributes 组成,即:
- VA:虚拟地址;
- PA:物理地址;
- ASID:Address Space ID;
- Attributes:属性;
3、那什么是ASID
通常情况下,在使用 Cortex-A 系列处理器的时候,典型场景是跑多任务 OS;每一个任务(或者成为应用),都有它独立的虚拟地址空间,以及他的独立的 Translation Table;但是对于 OS 来说,Kernel 的 Translation Tables 其实是固定的,只是进程之间的 Translation Tables 不一样而已;
当一个进程启动的时候,OS 负责为他 code 和 data 段建立映射表(Translation Tables);当进程调用诸如 malloc 之类分配内存的行为,OS 负责修改 Translation Tables(Linux 中,实际访问分配的内存的时候,才去修改页表),进程生命周期消亡,OS 负责回收它的资源和页表,并可以为下一个新的进程提供资源;每一个进程都有自己的独立的页表,这便可以保证进程之间不会相互干扰;
Address Space ID(ASID)
在操作系统中,多进程是一种常态。那么多进程 的情况下,每次切换进程都需要进行 TLB 清理。这样会导致切换的效率变低。为了解决问题,TLB 引入了 ASID(Address Space ID) 。ASID 的范围是 0-255。ASID 由操作系统分配,当前进程的ASID值 被写在 ASID 寄存器 (使用CP15 c3访问)。TLB 在更新页表项时也会将 ASID 写入 TLB。
如果设置了如果 当前进程的ASID,那么 MMU 在查找 TLB 时, 只会查找 TLB 中具有 相同ASID值 的 TLB行。且在切换进程是,TLB 中被设置了 ASID 的 TLB行 不会被清理掉,当下次切换回来的时候还在。所以ASID 的出现使得切换进程时不需要清理 TLB 中的所有数据,可以大大减少切换开销。
有了这个 ASID + nG 的机制,那么 TLB 中就可以缓存不同进程的页表,不用每次都去 flush TLB,导致性能的损失:

4、小结
ASID (Adress Space ID)的主要目的是给 mmu 缓存到 tlb 时打标签用的,如果页表表项中设置了 G – Global 则是全局的不受 ASID 的约束。在 Linux 中每个用户进程拥有自己的地址空间,拥有一套独立的 mmu 映射关系。所以在进程切换时 mmu 映射也需要切换。
ASID 作用主要有两个:
- 减少 tlb 的全局刷新。
- 在不刷新的情况下做权限隔离。