目录
一:遍历参数 超参调优测试
二:网格模型 超参调优测试
三:模型保存
四:模型使用
一:遍历参数 超参调优测试
1.1 超参调试,找到模型最优解[仅做测试,得出最优:n_neighbors, weights, p,即可删除此测试代码]
# 超参调试 -- 找出对这个模型最优秀的解:k weight p
best_k = -1 # 区间 数据集长度开平方
best_w = 0 # list['uniform','distance']
best_p = -1 # 表示求和的次方数 8
Weight = ['uniform', 'distance']
best_score = 0 # 模型最高评分
for k in range(1, 13): # 1-12
for p in range(1, 7): # 1-6
for w in Weight: # 2
knn_model = KNeighborsClassifier(n_neighbors=k, p=p, weights=w)
knn_model.fit(X_train, y_train)
score = knn_model.score(X_test, y_test)
if score > best_score:
best_score = score
best_k = k
best_w = w
best_p = p
print("best_score", best_score, "best_k", best_k, "best_w", best_w, "best_p", best_p)输出结果如下
best_score 1.0 best_k 5 best_w uniform best_p 41.2 KNeighborsClassifier,参数最优:n_neighbors=5, weights='uniform', p=4
如下代入
# 创建算法
knn_model = KNeighborsClassifier(n_neighbors=5, weights='uniform', p=4)由最优参数,输出的模型预测结果,也是最优结果,如下
1.0
[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True]1.3 完整源码分享,鸢尾花模型预测
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 加载数据 鸢尾花load_iris
iris_datasets = load_iris()
# 特征数据
iris_data = iris_datasets['data']
# 标签数据
iris_target = iris_datasets['target']
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.3, random_state=6)
# 选择算法 -- 有监督的分类问题
# KNN K近邻算法(近朱者赤近墨者黑)
# 创建算法
knn_model = KNeighborsClassifier(n_neighbors=5, weights='uniform', p=4)
# 构建基于训练集的模型
knn_model.fit(X_train, y_train)
# 模型评分
score = knn_model.score(X_test, y_test)
print(score)
# 模型预测
predict_y = knn_model.predict(X_test)
print(predict_y == y_test)
1.0
[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True]
二:网格模型 超参调优测试
模型调优-交叉验证
将数据训练数据分为多个数据模块,然后循环地从这些数据块中取出训练集和测试集,来进行模型测试/验证
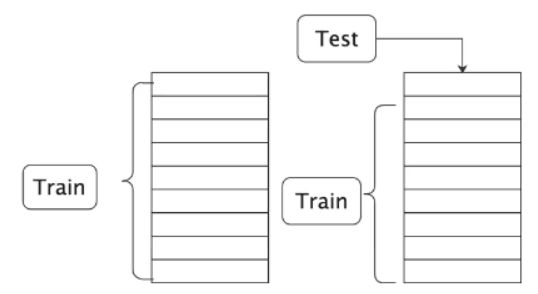
网格模型,超参调优测试
from sklearn.model_selection import train_test_split, GridSearchCV# 网格模型 参数测试--求最优解 k weight p
knn_model = KNeighborsClassifier()
param_list = [
{
"n_neighbors": list(range(1, 13)),
"p": [i for i in range(1, 9)],
"weights": ['uniform', 'distance']
}
]
# 网格化 超参调试
grid = GridSearchCV(knn_model, param_list, cv=4)
grid.fit(X_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
print(grid.best_estimator_)输出结果如下,
参数最优:n_neighbors=12, weights='uniform', p=2
注:KNeighborsClassifier输出结果中 参数少了p,为默认p值2,因此没有输出
0.9807692307692308
{'n_neighbors': 12, 'p': 2, 'weights': 'distance'}
KNeighborsClassifier(n_neighbors=12, weights='distance')三:模型保存
import joblib# 模型保存
joblib.dump(value=best_model, filename="knnModelIris.model")
四:模型使用
再新建一个.py编写程序,使用模型
import numpy as np
from sklearn.datasets import load_iris
# 使用已经保存好的模型来进行预测
import joblib
# 1 加载模型
model = joblib.load("knnModelIris.model")
# 2 测试集准备
feature = np.array([
[4.6, 3.1, 1.5, 0.2], # 0
[5.1, 3.6, 1.4, 0.3], # 0
[6., 2.9, 5.5, 1.5], # 2
[6.6, 3.1, 4.4, 1.4], # 1
[6.7, 2.8, 4.5, 1.4] # 1
])
y_predict = model.predict(feature)
print(y_predict)
0、1、2分别表示鸢尾花的3个不同类别,通过测试集准备、模型使用能正确预测出鸢尾花类型 输出结果如下
[0 0 2 1 1]