本文属于专栏《构建工业级QPS百万级服务》
继续上篇《QPS百万级的有状态服务实践》04 - 服务一致性。目前我们的系统如图1。现在我们虽然已经尽量把相同用户的请求转发到相同的机器,并且在客户端做了适配。但是因为成本,更极端的情况下,服务依然是最终一致性。截止目前,用户查询不同日期间的功能我们已经我完成了。
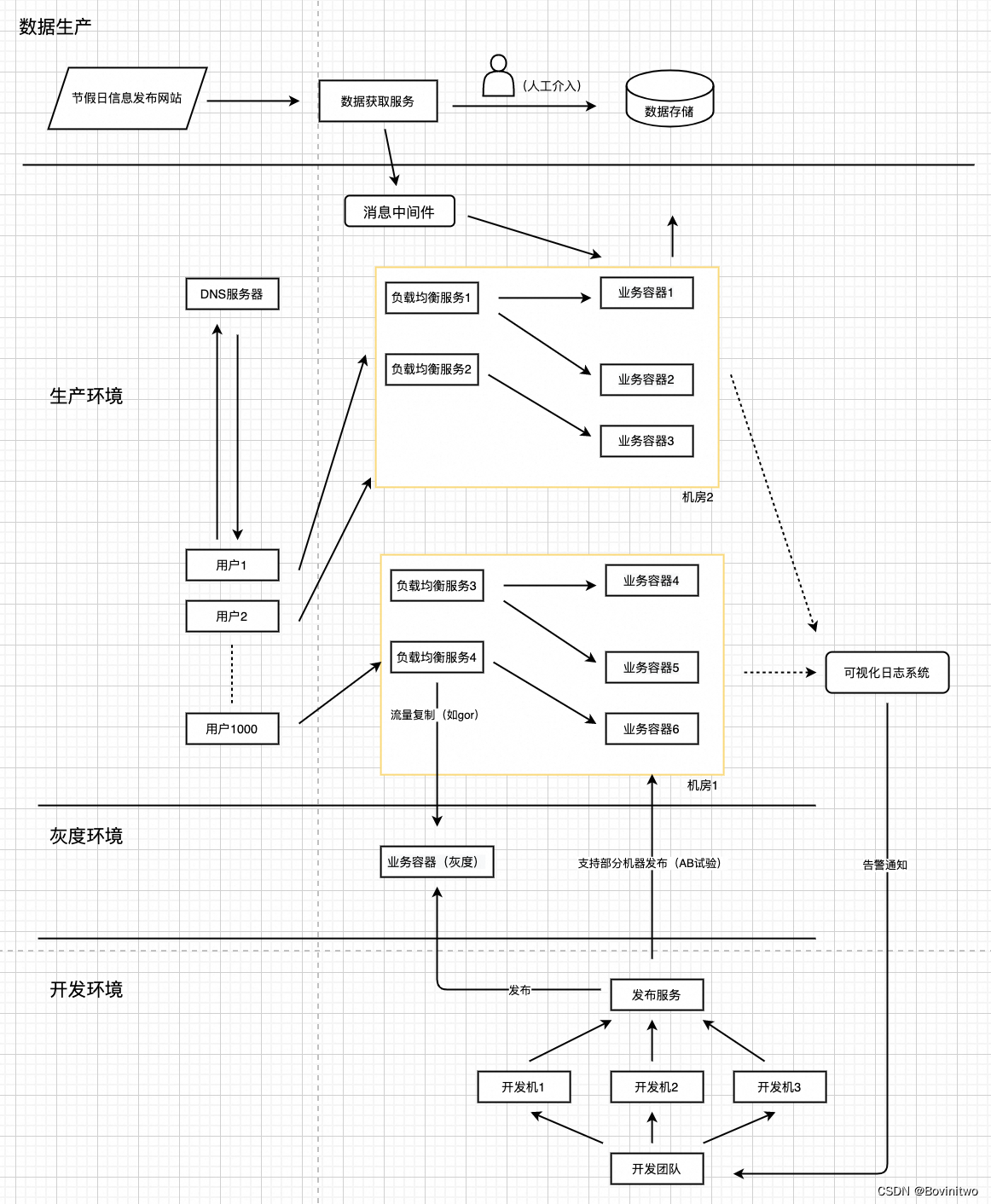
图1
现在我们还有一个需求,用户想看到历史的查询请求和结果。要看历史,就需要一个持久化存储的方式。比如古人就是用石头刻龟壳,把信息持久化存储。这个方式有用,但是效率太低,现代,最通用的方式是机械硬盘,它在成本和高效方面,目前平衡做得最好。那看起来我们的方案很简单,就是每个服务把用户请求和返回都存在本地磁盘,然后当用户来查询的时候,返回给他。一开始我们就是这么做的。著名的Oracle也是从做本地数据库开始的。
但是随着互联网用户数量变多,用户对数据存储稳定性的要求变高。本地数据库一个关键问题暴露了,就是磁盘是会坏的,一般情况下硬盘寿命在3-5年,如果数据只存了一份,磁盘坏了,数据就丢了,就像如果古人刻有信息的龟壳坏了,那信息将永久丢失。所以对于重要的数据,古人会把信息刻在多个龟壳上,减少信息丢失的概率。我们也一样,要做的就是把数据存几份冗余。这样的需求是大部分业务都需要的,所以分布式数据库应运而生。我们的业务选择相对成熟的MySQL。
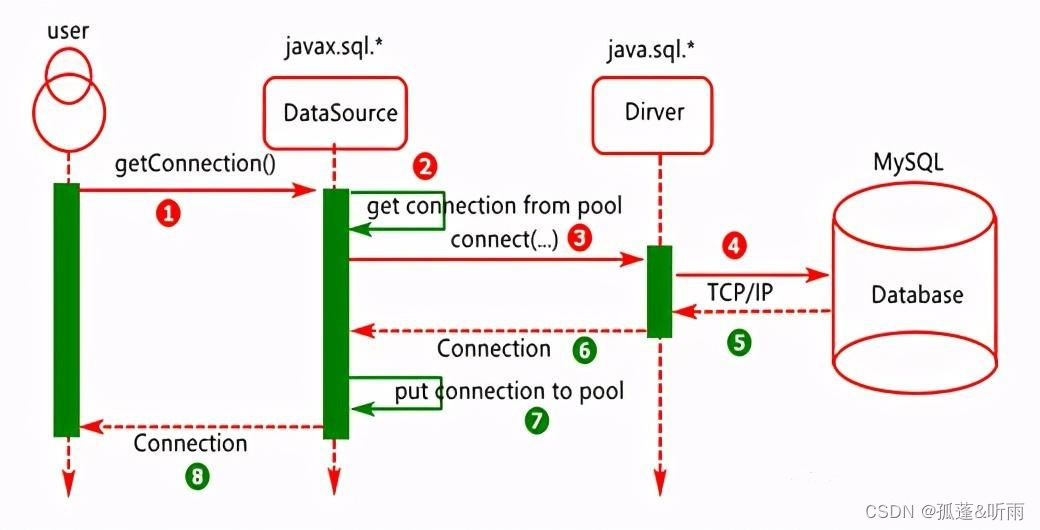
所以我们的架构升级了,如图2。图中,我们选择每个机房有自己的MySQL集群的原因是因为,跨机房的延迟是远大于同机房,而我们的业务容器是同步查询MySQL,如果查询延迟大,将极大影响吞吐量。为了整体成本,我们选择每个机房有自己的MySQL集群,虽然集群有两个,但是两个集群总共使用的机器数,比只使用一个集群多不了太多。

图2
但现在的方案还不够完美。因为目前我们每个机房处理一部分用户,如果机房1出现故障,所有的请求会飘移到机房2,但是机房2只有一部分用户的持久化数据,那用户就会查不到历史请求数据。并且在机房1故障恢复之后,刚刚被转移到机房2的用户的持久化数据还在机房2呢,这个时候,转移回机房1的用户也会丢失查询历史。
容易想到,也是业界普遍的做法,就是让MySQL集群1和MySQL集群2做自动同步,于是我们架构升级为图3。
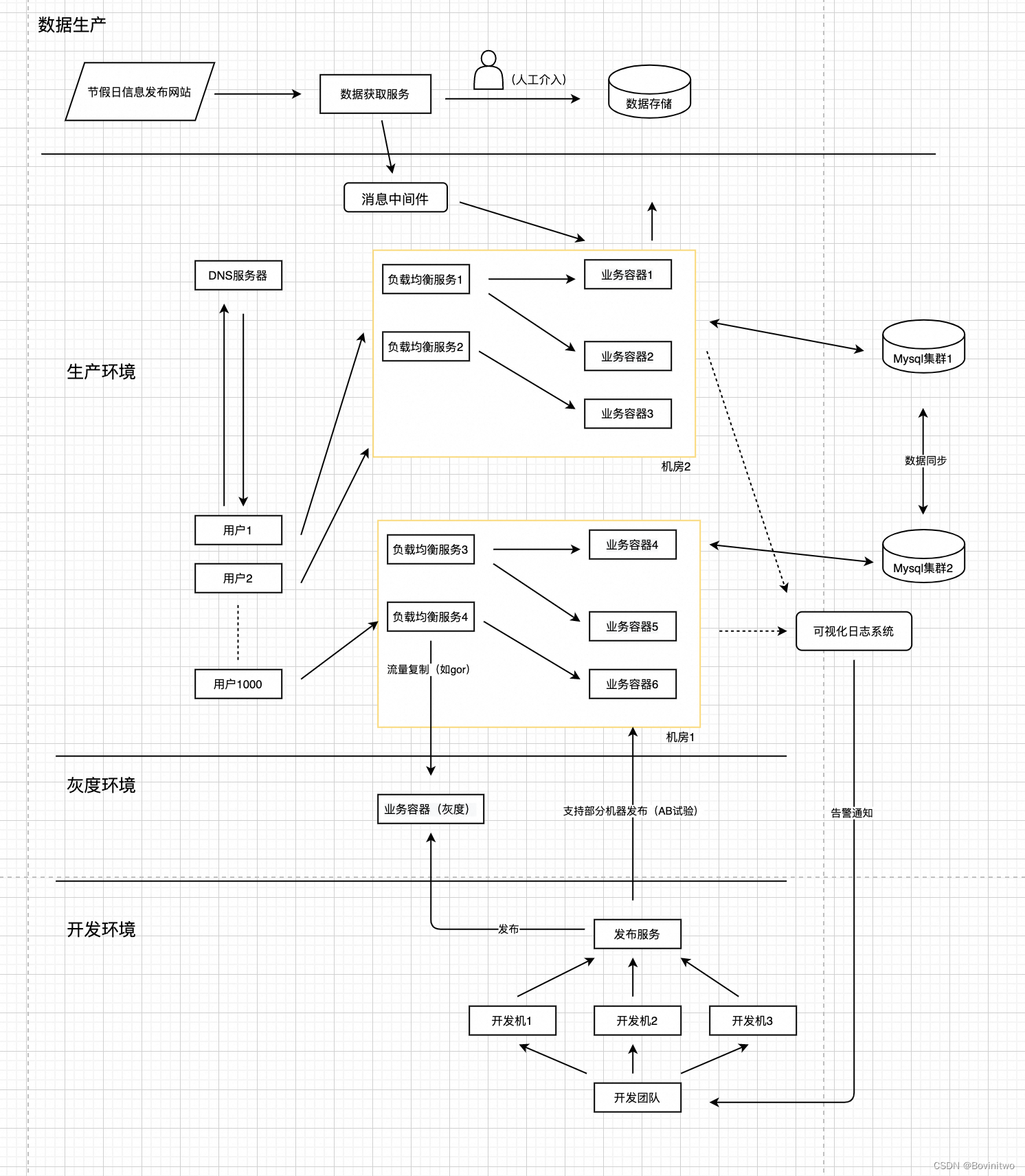
图3
虽然架构升级了,但是问题还没有完全解决。因为数据同步是有延迟的,一般来说是秒级的,所以在一个机房出现故障时,请求转移的瞬间,可能机房间还没完成该用户的同步。这个问题是不能100%解决的,不仅是数据传播需要时间,还因为MySQL集群中的部分机器也可能在请求转移的时候重启或者坏掉,这样数据同步的延迟会更高。但是好消息时,只有极少情况下,用户会丢失最近的请求记录,并且在几秒后就恢复了。日常我们在使用网页或者APP时,发现数据不对,刷新几次就好了,也是常见的操作了,这就是背后的原因之一。
注意,每个机房有独立的MySQL集群不是所有场景的最佳方案。我们的服务使用独立的MySQL集群有一个很重要的原因的,我们不希望机房延迟导致业务容器处理能力下降很多。因为对于请求量达到QPS百万级的业务,业务容器一般很多,成本一般很高,一旦降低容器处理能力,那成本会增加很多。但是对于处理用户量不大,对几十毫秒的延迟不敏感的场景,通过双机房容灾,但是使用一个集群的MySQL才是最佳的方案,维护简单,成本也几乎不会增长。还是那句话,架构只有最适合,没有最优。
截止目前为止《工业级QPS百万级服务从0到1概述》的需求我们都已经完成。
但是,前面只说了持久化存储方案选择MySQL,但是为什么选择它,还有其他哪些持久化方案可以选择。以及这个方案背后有什么共性,它们的原理、成本到底是怎样的。对于海量请求,在使用它们时需要注意什么,我会在后面的章节分享。

![Sqli-labs靶场第8关详解[Sqli-labs-less-8]](https://img-blog.csdnimg.cn/direct/a75945bb611847b3b87435df0900f064.png)





![[LWC] Components Communication](https://img-blog.csdnimg.cn/direct/3975290d87c448639f50f870db02817a.png)