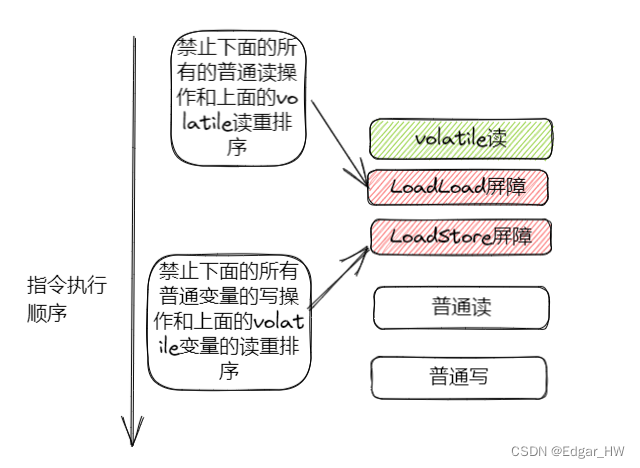
一、注解的定义和作用
1、定义
注解(Annotation),也叫元数据。一种代码级别的说明。它是JDK1.5及以后版本引入的一个特性,与类、接口、枚举是在同一个层次。它可以声明在包、类、字段、方法、局部变量、方法参数等的前面,用来对这些元素进行说明,注释。
2、作用
(1)编写文档:
通过代码里标识的元数据生成文档【生成文档doc文档】
(2)代码分析:
通过代码里标识的元数据对代码进行分析【使用反射】
(3)编译检查:
通过代码里标识的元数据让编译器能够实现基本的编译检查【Override】
二、元注解
| 注解 | 说明 |
|---|---|
| @Target(JDK1.5) | 定义注解的作用目标 |
| @Retention(JDK1.5) | 定义注解的保留策略 |
| @Document(JDK1.5) | 注解是否应当被包含在 JavaDoc 文档中(生成说明文档,添加类的解释 ) |
| @Inherited(JDK1.5) | 说明子类可以继承父类中的该注解 |
| @Repeatable(JDK1.8) | 允许在相同的程序元素中重复注解,在需要对同一注解多次使用时,往往需要借助@Repeatable注解。 |
| @Native(JDK1.8) | 修饰成员变量,则表示这个变量可以被本地代码引用,常常被代码生成工具使用。 |
1、Target类型说明
| Target类型 | 说明 |
|---|---|
| ElementType.TYPE | 类、接口(包括注释类型)或枚举声明 |
| ElementType.FIELD | 字段声明(包括枚举常量) |
| ElementType.METHOD | 方法声明 |
| ElementType.PARAMETER | 正式的参数声明 |
| ElementType.CONSTRUCTOR | 构造函数声明 |
| ElementType.LOCAL_VARIABLE | 局部变量声明 |
| ElementType.ANNOTATION_TYPE | 注解类型声明 |
| ElementType.PACKAGE | 程式包说明 |
2、Retention类型说明
| Target类型 | 说明 |
|---|---|
| RetentionPolicy.SOURCE | 注解仅存在于源码中,在class字节码文件中不包含 |
| RetentionPolicy.CLASS | 默认的保留策略,注解会在class字节码文件中存在,但运行时无法获得 |
| RetentionPolicy.RUNTIME | 注解会在class字节码文件中存在,在运行时可以通过反射获取到 |
3、@Documented和@Inherited的比较
(1)@Documented注解修饰的注解,当我们执行 JavaDoc 文档打包时会被保存进 doc 文档,反之将在打包时丢弃。
(2)@Inherited注解修饰的注解是具有可继承性的,也就说我们的注解修饰了一个类,而该类的子类将自动继承父类的该注解。
4、注意
(1)@Repeatable 所声明的注解,其元注解@Target的使用范围要比@Repeatable的值声明的注解中的@Target的范围要大或相同,否则编译器错误,显示@Repeatable值所声明的注解的元注解@Target不是@Repeatable声明的注解的@Target的子集。
(2)@Repeatable注解声明的注解的元注解@Retention的周期要比@Repeatable的值指向的注解的@Retention得周期要小或相同。
周期长度为:SOURCE(源码) < CLASS (字节码) < RUNTIME(运行)
5、实例
//Java 8 之前的做法
public @interface Roles {
Role[] roles();
}
public @interface Role {
String roleName();
}
public class RoleTest {
@Roles(roles = {@Role(roleName = "role1"), @Role(roleName = "role2")})
public String doString(){
return "这是C语言中国网Java教程";
}
}
//java 8 之后增加了重复注解
public @interface Roles {
Role[] value();
}
@Repeatable(Roles.class)
public @interface Role {
String roleName();
}
public class RoleTest {
@Role(roleName = "role1")
@Role(roleName = "role2")
public String doString(){
return "这是C语言中文网Java教程";
}
}
三、自定义注解实现
1、运行时处理的注解(反射机制)
(1)定义注解
package com.newtouch.springboot.examples.annotation.runningAnnotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 定义注解
* 运行时处理的注解(反射机制)
*/
@Target(ElementType.METHOD)//作用目标是方法
@Retention(RetentionPolicy.RUNTIME)//保留策略使用RUNTIME:注解会在class字节码文件中存在,在运行时可以通过反射获取到
public @interface Reflect {
String name() default "liuyifei";
}
(2)注解处理器
package com.newtouch.springboot.examples.annotation.runningAnnotation;
import java.lang.reflect.Method;
/**
* 注解处理器
*/
public class ReflectProcessor {
public void parseMethod(final Class<?> clazz) throws Exception {
final Object obj = clazz.getConstructor(new Class[] {}).newInstance(new Object[] {});
final Method[] methods = clazz.getDeclaredMethods();
for (final Method method : methods) {
final Reflect my = method.getAnnotation(Reflect.class);
if (null != my) {
System.out.println("方法名:");
System.out.println(method.getName());
method.invoke(obj, my.name());
}
}
}
}
(3)测试注解
package com.newtouch.springboot.examples.annotation.runningAnnotation;
/**
* 测试注解
*/
public class ReflectTest {
@Reflect
public static void sayHello1(final String name) {
System.out.println("==>> Hi, " + name + " , nest to meet you!");
}
@Reflect(name = "yangmi")
public static void sayHello2(final String name) {
System.out.println("==>> Hi, " + name + " , nest to meet you!");
}
public static void main(final String[] args) throws Exception {
final ReflectProcessor reflectProcessor = new ReflectProcessor();
reflectProcessor.parseMethod(ReflectTest.class);
}
}
(4)测试结果
方法名:
sayHello1
==>> Hi, liuyifei , nest to meet you!
方法名:
sayHello2
==>> Hi, yangmi , nest to meet you!
2、编译时处理的注解(虚处理器方式AbstractProcessor)
(1)定义注解
package com.newtouch.springboot.examples.annotation.compileAnnotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 定义注解
* 编译时处理的注解(虚处理器方式AbstractProcessor)
*/
@Target({ElementType.TYPE, ElementType.METHOD,ElementType.FIELD})//类、接口(包括注释类型)或枚举声明;方法声明;字段声明(包括枚举常量)
@Retention(RetentionPolicy.SOURCE)//保留策略使用SOURCE:注解仅存在于源码中,在class字节码文件中不包含
public @interface NameScanner {
}
(2)注解处理器
package com.newtouch.springboot.examples.annotation.compileAnnotation;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.ProcessingEnvironment;
import javax.annotation.processing.RoundEnvironment;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import javax.tools.Diagnostic;
import java.util.Set;
/**
* 注解处理器
* 将每一个被注解的元素名称打印出来
*/
public class NameScannerProcessor extends AbstractProcessor {
/**
* 该方法主要用于一些初始化的操作,通过该方法的参数ProcessingEnvironment可以获取一系列有用的工具类。
* @param processingEnv
*/
@Override
public void init(ProcessingEnvironment processingEnv){
super.init(processingEnv);
}
/**
* 注解处理器的核心方法,处理具体的注解。主要功能基本可以理解为两个:
* 1、获取同一个类中的所有指定注解修饰的Element;
* a、set参数,存放的是支持的注解类型,一般无用。
* b、RoundEnvironment参数,可以通过遍历获取代码中所有通过指定注解(例如在ButterKnife中主要就是@BindeView等)修饰的Element对象。通过Element对象可以获取字段名称,字段类型以及注解元素的值。
* 2、创建Java文件;
* 将同一个类中通过指定注解修饰的所有Element在同一个Java文件中实现初始化,这样做的目的是让在最终依赖注入时便于操作。
* @param annotations
* @param roundEnv
* @return
*/
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv){
if(!roundEnv.processingOver()){
for(Element element : roundEnv.getElementsAnnotatedWith(NameScanner.class)){
String name = element.getSimpleName().toString();
processingEnv.getMessager().printMessage(Diagnostic.Kind.NOTE, "element name: " + name);
}
}
return false;
}
}
(3)测试注解
package com.newtouch.springboot.examples.annotation.compileAnnotation;
@NameScanner
public class NameScannerTest {
@NameScanner
private String name;
@NameScanner
private int age;
@NameScanner
public String getName(){
return this.name;
}
@NameScanner
public void setName(String name){
this.name = name;
}
public static void main(String[] args){
System.out.println("--finished--");
}
}
(4)手动编译
javac NameScanner.java
javac NameScannerProcessor.java
javac -processor NameScannerProcessor NameScannerTest.java
编译输出:
element name: NameScannerTest
element name: name
element name: age
element name: getName
element name: setName
3、AbstractProcessor方法作用解析
(1)void init(ProcessingEnvironment processingEnv)
该方法主要用于一些初始化的操作,通过该方法的参数ProcessingEnvironment可以获取一系列有用的工具类。
(2)SourceVersion getSupportedSourceVersion()
返回此注释 Processor 支持的最新的源版本,该方法可以通过注解@SupportedSourceVersion指定。
(3)Set getSupportedAnnotationTypes()
返回此 Processor 支持的注释类型的名称。结果元素可能是某一受支持注释类型的规范(完全限定)名称。它也可能是 ” name.” 形式的名称,表示所有以 ” name.” 开头的规范名称的注释类型集合。最后,自身表示所有注释类型的集合,包括空集。
注意:
Processor不应声明 “*”,除非它实际处理了所有文件;声明不必要的注释可能导致在某些环境中的性能下降。
(4)boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment)
注解处理器的核心方法,处理具体的注解。主要功能基本可以理解为两个:
1)获取同一个类中的所有指定注解修饰的Element;
set参数,存放的是支持的注解类型,一般无用。
RoundEnvironment参数,可以通过遍历获取代码中所有通过指定注解(例如在ButterKnife中主要就是@BindeView等)修饰的Element对象。通过Element对象可以获取字段名称,字段类型以及注解元素的值。
2)创建Java文件;
将同一个类中通过指定注解修饰的所有Element在同一个Java文件中实现初始化,这样做的目的是让在最终依赖注入时便于操作。
4、Java代码编译过程与注解处理器的注解处理过程
(1)Java代码编译过程
1)解析与填充符号表过程;
2)插入式注解处理器的注解处理过程;
3)语义分析与字节码生成过程。

(2)注解处理器的注解处理过程
插入式注解处理器可以在编译器时读取、修改、添加抽象语法树中的任意元素。如果这些插件在处理注解期间对语法树进行了修改,那么编译器将回到解析及填充符号表的过程重新处理,直到所有的插入式注解处理器都没有再对语法树进行修改为止。
参考文献:
https://blog.csdn.net/qq_16268979/article/details/108251227
https://blog.csdn.net/doc_sgl/article/details/50367083
https://www.jianshu.com/p/1acb3cd1fc8f


](https://img-blog.csdnimg.cn/img_convert/32e4e5eb993fe0514c9785a254e84e88.jpeg)