string类模拟实现
- 1.为什么要模拟实现string
- 2.string的模拟实现需要注意哪些问题
- 3.经典的string类问题
- 4.写时拷贝
- 5.传统版写法的String类(参考)
- 6.现代版写法的String类(参考)
- 7.string类的模拟实现(讲解)
- 7.1 命名空间string类的成员变量定义
- 7.2 string类构造函数
- 7.3 string类拷贝构造函数
- 7.4 string类赋值运算符重载
- 7.5 string类析构函数和易实现的成员函数
- 7.6 string类reserve函数
- 7.7 string类resize函数
- 7.8 string类insert函数、append函数、push_back函数、+=重载
- 7.9 string类erase函数
- 7.10 string类erase函数
- 7.11 string类substr 函数
- 7.12 string类比较运算符重载
- 7.13 string类流插入<<和流提取>>重载
- 8.string类的模拟实现(完整代码)
- 结语
1.为什么要模拟实现string

模拟实现 std::string 是一个有挑战性的练习,它可以带来多方面的收益,尤其对于学习 C++ 和深入了解字符串操作以及动态内存管理的机制。以下是模拟实现 std::string 的一些好处和重要意义:
- 学习 C++ 内存管理:std::string 是一个动态分配内存的容器,模拟实现需要手动处理内存的分配和释放。这可以让你更深入地理解动态内存管理的原理和机制,如何正确地使用 new 和 delete 运算符,以及如何避免内存泄漏和悬空指针。
- 字符串操作的练习:在模拟实现过程中,您需要实现字符串的拼接、插入、删除、查找等操作,以及其他与字符串处理相关的函数。这可以帮助您熟悉 C++ 中字符串的操作和处理方式。
- 深入理解类和对象:std::string 是一个类模板,模拟实现它需要深入理解类和对象的概念,包括构造函数、析构函数、成员函数、成员变量等。通过实现一个类似 std::string 的类,你可以更好地理解类的设计和使用。
- 提高编程技能:模拟实现 std::string 是一项挑战性的任务,它可以锻炼你的编程技能,让你更加熟练地使用 C++ 的语法和特性。
- 深入学习模板编程:std::string 是一个类模板,模拟实现它可以帮助你深入了解模板编程的机制和技巧。
- 实现自定义容器:std::string 是 C++ 标准库中的一个容器类,模拟实现它是实现自定义容器的练习。自定义容器可以帮助您更好地理解容器的设计和实现。
2.string的模拟实现需要注意哪些问题
模拟实现 std::string 类是一个有挑战性的任务,因为 std::string 是 C++ 标准库中的一个复杂数据类型,它有很多功能和特性,而其实现涉及到动态内存管理、字符串操作、复制语义等方面。在进行模拟实现时,需要注意以下一些关键问题:
- 内存管理:std::string 类是一个动态分配内存的容器,模拟实现需要正确地处理内存的分配和释放。你可以使用动态数组、指针或其他数据结构来模拟动态内存的管理。
- 字符串操作:模拟实现需要支持字符串的拼接、插入、删除、查找等操作,以及其他字符串处理的函数(如 size()、substr()、find() 等)。
- 异常处理:std::string 在一些情况下可能会引发异常,例如内存分配失败或访问越界等。模拟实现需要考虑如何正确处理异常情况,以确保程序的稳定性和安全性。
- 内存拷贝:std::string 采用了深拷贝(deep copy)语义,即在复制时会复制整个字符串的内容。模拟实现需要正确地处理内存的拷贝,以避免悬空指针和资源泄漏等问题。
- 迭代器支持:std::string 支持迭代器用于访问字符串的内容,模拟实现需要提供相应的迭代器支持。
- 性能优化:std::string 的标准实现通常会对性能进行优化,例如采用了扩容策略来减少频繁的内存分配。模拟实现可以考虑一些优化策略,提高性能和效率。
- 边界条件:在进行模拟实现时,需要特别注意边界条件和特殊情况,确保实现的正确性和鲁棒性。
- 完整性:std::string 类是一个非常复杂的数据类型,模拟实现时需要尽可能完整地实现其功能和接口。
虽然模拟实现 std::string 是一个复杂的任务,但它也是一个很好的学习练习,可以加深对 C++ 内存管理、字符串处理等方面的理解。
3.经典的string类问题
上一篇文章已经对string类进行了简单的介绍,大家只要能够正常使用即可。在面试中,面试官总喜欢让学生自己来模拟实现string类,最主要是实现string类的构造、拷贝构造、赋值运算符重载以及析构函数。大家看下以下string类的实现是否有问题?
// 为了和标准库区分,此处使用String
class String
{
public:
/*String()
:_str(new char[1])
{*_str = '\0';}
*/
//String(const char* str = "\0") 错误示范
//String(const char* str = nullptr) 错误示范
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非法
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
// 测试
void TestString()
{
String s1("hello bit!!!");
String s2(s1);
}

上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
什么是浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。其实我们可以采用深拷贝解决浅拷贝问题,即:每个对象都有一份独立的资源,不要和其他对象共享。
什么是深拷贝
深拷贝是指在进行对象拷贝时,不仅复制对象本身的成员变量,还复制对象所指向的动态分配的资源(例如堆内存)到新的对象中。这意味着拷贝后的对象和原对象拥有独立的资源副本,彼此之间不会相互影响。
当对象中含有动态分配的资源,如指针指向的内存块,或者其他动态分配的资源(文件句柄、网络连接等),进行深拷贝是非常重要的,以避免多个对象共享同一块资源导致释放重复、悬挂指针等问题。
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供。

4.写时拷贝
“写时拷贝”(Copy on Write,简称为 COW)是一种优化技术,通常应用于操作系统的内存管理或数据结构中,目的是节省内存和提高性能。在 COW 中,当多个对象共享同一份资源时,只有在某个对象试图修改资源内容时,才会进行实际的拷贝操作,否则所有对象共享相同的原始资源。这样可以避免在修改前对整个资源进行拷贝,节省了内存和执行时间。
COW 最常见的应用是在操作系统中的进程管理和内存分配。当一个进程 fork(复制)自身时,通常会采用 COW 机制。在 fork 时,子进程会与父进程共享相同的内存空间,即物理页框。只有当子进程或父进程中的一个试图修改其中的内容时,操作系统才会执行实际的拷贝,将要修改的页框内容复制到新的页框中,使得两个进程的内存空间独立开来。这样,父子进程可以共享大部分资源,而无需进行大规模的内存拷贝,从而提高了 fork 操作的效率。
在编程语言或数据结构中,写实拷贝也可以用于优化数据结构的复制操作。例如,在某些容器类(如字符串、数组、向量等)中,当多个对象共享相同的数据时,只有在其中一个对象试图修改数据时,才会进行实际的拷贝操作,确保各个对象之间的数据相互独立。
需要注意的是,COW 并不是适用于所有情况的通用优化技术,它的有效性取决于具体的应用场景。在某些情况下,COW 可以带来显著的性能优势,但在其他情况下,可能会增加复杂性和开销。因此,在实现时需要仔细权衡利弊,根据实际需求选择合适的优化策略。
其实写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源。
一个常见的例子是字符串的写实拷贝。
在许多编程语言中,字符串通常是不可变的(immutable),即一旦创建后,就无法修改其内容。在这种情况下,当多个变量或对象引用同一个字符串时,如果其中一个变量试图修改字符串的内容,就需要创建一个新的字符串对象,而不是直接在原始字符串上进行修改。
假设有两个变量 str1 和 str2 都指向相同的字符串 “Hello”:
std::string str1 = "Hello";
std::string str2 = str1;
在这里,str2 是通过拷贝构造函数从 str1 创建的。在传统的拷贝情况下,这将导致整个字符串 “Hello” 的拷贝,即两个变量 str1 和 str2 都指向不同的内存地址,但其内容是相同的。
但是,写时拷贝可以优化这种情况。在写时拷贝中,当 str2 拷贝 str1 时,并不会立即创建一个新的字符串副本。而是让 str2 和 str1 共享同一个底层的字符串数据。只有当其中一个字符串试图修改其内容时,才会触发实际的拷贝操作。
例如,如果现在对 str2 进行修改操作:
str2[0] = 'h'; // 修改第一个字符为小写 'h'
在写时拷贝机制下,会创建一个新的字符串 “hello”,然后 str2 的内容指向新的字符串,而 str1 的内容保持不变。这样,两个变量 str1 和 str2 仍然共享相同的底层数据,但它们的内容已经不再相同。
写时拷贝可以有效地节省内存,尤其在字符串长期共享的情况下,避免了不必要的内存复制。但在其他情况下,可能会增加复杂性和开销。因此,在实现时需要仔细权衡利弊,根据实际需求选择合适的优化策略。
5.传统版写法的String类(参考)
class String
{
public:
String(const char* str = "")
{
// 构造String类对象时,如果传递nullptr指针,可以认为程序非法
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(new char[strlen(s._str) + 1])
{
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* pStr = new char[strlen(s._str) + 1];
strcpy(pStr, s._str);
delete[] _str;
_str = pStr;
}
return *this;
}
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
6.现代版写法的String类(参考)
class String
{
public:
String(const char* str = "")
{
if (nullptr == str)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
: _str(nullptr)
{
String strTmp(s._str);
swap(_str, strTmp._str);
}
String& operator=(String s)
{
swap(_str, s._str);
return *this;
}
/*
String& operator=(const String& s)
{
if(this != &s)
{
String strTmp(s);
swap(_str, strTmp._str);
}
return *this;
}
*/
~String()
{
if (_str)
{
delete[] _str;
_str = nullptr;
}
}
private:
char* _str;
};
7.string类的模拟实现(讲解)
根据上面提到的内容和知识,我们可以来实现string类框架和大部分的接口函数,但在实际面试中,我们可能需要实现的功能并不多,所以我们这里只把最常见和常用的那些部分模拟实现。
7.1 命名空间string类的成员变量定义
namespace mystring
{
class string
{
public:
//...
private:
size_t _capacity;
size_t _size;
char* _str;
public:
// const static 语法特殊处理
// 直接可以当成定义初始化
const static size_t npos = -1;
}
首先我们重新定义一个命名空间,防止和库中的string类重定义,或者重新写一个别的名字的string类也可以,类成员包括capacity,size和字符串str,npos定义成公有并初始化。
7.2 string类构造函数
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
const char* str = “” 是构造函数的默认参数。默认参数是在函数声明中为函数参数提供默认值的一种特性,它允许在调用函数时,如果没有提供相应的参数值,就会使用默认值作为参数的值,实际包含一个’\0’,分配足够存储字符串的内存空间(_size + 1,其中 _size 是输入字符串的长度),然后通过 strcpy 函数将输入的 C 风格字符串复制到 _str 成员变量中。
7.3 string类拷贝构造函数
传统写法:
string(const string& s)
:_str(new char[s._capacity+1])
, _size(s._size)
, _capacity(s._capacity)
{
strcpy(_str, s._str);
}
现代写法:
void swap(string& tmp)
{
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp); //this->swap(tmp);
}
第一段代码中,拷贝构造函数采用传统的深拷贝方式。它首先分配了与源对象(s)相同大小的内存空间(包括结尾的空字符),然后将源对象的内容复制到新分配的内存空间中。
这种实现方式确保了新创建的对象和源对象具有独立的内存空间,即它们不共享资源。这样,当一个对象修改其内容时,不会影响到另一个对象,从而保证了对象之间的数据隔离。
而在第二段代码中,拷贝构造函数使用了 C++11 引入的移动语义。它先创建了一个名为 tmp 的临时对象,并使用 s._str 初始化了这个临时对象。接着,通过调用成员函数 swap(tmp) 将当前对象的成员和临时对象的成员进行交换。
swap 函数的实现会使当前对象的成员指向临时对象的内存空间,而临时对象的成员指向了当前对象之前的内存空间。这样一来,原来的资源被交换了,临时对象会在析构时释放当前对象原来的资源,而当前对象则拥有了 s 对象的资源。
这种实现方式通过避免了不必要的内存拷贝,从而提高了拷贝构造函数的性能。在 tmp 作为临时对象被析构时,它会自动释放原来 s 对象的资源,因此没有内存泄漏。
两种实现方式都是有效的拷贝构造函数,但第二种实现利用了移动语义,可以在拷贝对象时避免不必要的内存复制,提高性能。在 C++11 及以上版本中,推荐使用第二种实现方式。
7.4 string类赋值运算符重载
传统写法:
string& operator=(const string& s)
{
if (this != &s)
{
string tmp(s);
swap(tmp);
}
return *this;
}
现代写法:
string& operator=(string s)
{
swap(s);
return *this;
}
在第一个函数中,赋值运算符采用了传统的深拷贝方式。它首先检查目标对象与源对象是否是同一个对象(地址比较),如果是同一个对象则不执行赋值操作,避免了自赋值的情况。
然后,它创建一个临时的 string 对象 tmp,并将源对象 s 的内容复制到 tmp 中。接着,通过调用 swap(tmp),将当前对象的成员和临时对象的成员进行交换。
这样,原来的资源被交换了,当前对象拥有了 s 对象的资源,而临时对象在析构时会自动释放当前对象原来的资源。这样实现了赋值操作,并在赋值时避免了不必要的内存拷贝。
在第二个函数中,赋值运算符使用了 C++11 引入的移动语义。它的参数是一个 string 对象 s,这里采用了按值传递,即通过值拷贝的方式传递参数。
在函数内部,它直接通过 swap(s) 将当前对象的成员和参数 s 对象的成员进行交换。由于参数 s 是按值传递的,意味着在调用函数时会执行一次拷贝构造函数来创建 s 对象的副本,因此在 swap(s) 中,将 s 对象的资源交换给了当前对象,同时临时对象 s 会在函数结束时自动析构并释放当前对象原来的资源。
这样,通过移动语义实现了赋值操作,并在赋值时避免了不必要的内存复制。
区别总结:
参数传递方式:第一个函数采用了常量引用传递,而第二个函数采用了按值传递。
拷贝控制技术:第一个函数使用了深拷贝和交换资源的方式,而第二个函数利用了移动语义和 swap 操作来避免拷贝。
两者都能正确实现赋值操作,并避免了不必要的内存拷贝。然而,第二个函数在 C++11 及以上版本中更推荐,因为它利用了移动语义,性能更高效。如果你的代码环境支持 C++11 或更高版本,建议优先考虑使用第二种实现方式。
7.5 string类析构函数和易实现的成员函数
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
这里的析构函数通过 delete[] 操作释放 _str 指向的动态分配的字符数组(字符串内存),然后将 _str 置为 nullptr,同时将 _size 和 _capacity 设置为 0。这样确保对象被销毁时内存得到正确的释放,防止内存泄漏。
const char* c_str() const
{
return _str;
}
c_str()函数用于返回指向存储字符串的字符数组的指针。
size_t size() const
{
return _size;
}
size()函数用于返回字符串的大小,即字符串中实际存储的字符个数,返回类型为 size_t。这里的 _size 成员变量表示实际存储的字符个数,因此直接返回 _size 即可。
size_t capacity() const
{
return _capacity;
}
capacity()函数用于返回字符串的容量,即字符串中当前分配的内存空间大小,返回类型为 size_t。这里的 _capacity 成员变量表示当前的容量,因此直接返回 _capacity 即可。
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
operator[](size_t pos) const是 const 版本的下标操作符重载函数,用于访问字符串中指定位置 pos 处的字符。函数返回类型为 const char&,表示返回的是常量字符的引用,即不允许通过该引用修改字符内容。这是为了确保字符串的不可变性。
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
operator[](size_t pos)是非 const 版本的下标操作符重载函数,功能与上面的 const 版本类似,但这个函数返回类型是 char&,表示返回的是可修改字符的引用,允许通过该引用修改字符内容。
void clear()
{
_str[0] = '\0';
_size = 0;
}
clear 函数用于清空字符串,即将字符串内容全部置为空,并将实际大小 _size 设为 0,将字符数组的第一个字符(即字符串的起始位置)设置为空字符 ‘\0’,以将字符串内容清空。
7.6 string类reserve函数
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
`void reserve(size_t n):这是 std::string 类中的 reserve 函数的声明,表示该函数将预留 n 个字符的内存空间。n 是传入的参数,表示需要预留的字符个数。
if (n > _capacity):这里通过比较传入的 n 和当前字符串的容量 _capacity,来判断是否需要增加字符串的容量。只有当需要预留的字符个数 n 大于当前容量 _capacity 时,才需要进行内存扩展操作。
char* tmp = new char[n + 1];:如果需要增加容量,首先创建一个新的字符数组 tmp,长度为 n + 1,即预留的字符个数加上结尾的空字符。这里将字符串的容量设置为 n,是为了预留额外的一个位置来存储结尾的空字符。
strcpy(tmp, _str);:将原来的字符串内容复制到新创建的字符数组 tmp 中。
delete[] _str;:释放原来字符串 _str 指向的动态分配的字符数组,即释放原来的内存空间。
_str = tmp;:将原来的指针 _str 指向新的字符数组 tmp,这样字符串的内存空间得到了扩展。
_capacity = n;:将 _capacity 更新为新的容量 n。
这样,当需要预留更多的内存空间时,reserve 函数会创建一个新的字符数组,并将原来的字符串内容复制到新数组中,然后释放原来的内存空间,并将 _str 指向新的字符数组,更新容量 _capacity 为新的预留值 n。
7.7 string类resize函数
void resize(size_t n, char ch = '\0')
{
if (n > _size)
{
// 插入数据
reserve(n);
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_str[n] = '\0';
_size = n;
}
else
{
// 删除数据
_str[n] = '\0';
_size = n;
}
}
resize 函数用于改变字符串的大小,即增加或减少字符串中的字符个数。这里简单解释一下这个函数的实现:
void resize(size_t n, char ch = '\0'):这是 std::string 类中的 resize 函数的声明,表示该函数将改变字符串的大小为 n。n 是传入的参数,表示新的字符串大小。参数 ch 是可选的,默认值为 ‘\0’,用于在扩展字符串大小时填充新增的字符。
if (n > _size):在这个条件分支中,判断需要增加字符串大小的情况。如果传入的新大小 n 大于当前字符串大小 _size,表示需要在字符串末尾添加新的字符。
reserve(n);:首先调用 reserve 函数来预留足够的内存空间,确保字符串有足够的容量来容纳新增的字符。
for (size_t i = _size; i < n; ++i):然后在字符串中新增的位置,从当前字符串的大小 _size 开始循环添加字符。这里将新增的字符都设置为 ch,即传入的第二个参数。
_str[n] = '\0';:在循环结束后,将字符串的新末尾字符设置为空字符 ‘\0’,保证新的字符串正确终止。
_size = n;:最后将字符串的大小 _size 更新为新的大小 n。
else:在这个条件分支中,处理需要减小字符串大小的情况。如果传入的新大小 n 小于当前字符串大小 _size,表示需要删除字符串中多余的字符。
_str[n] = '\0';:将字符串的新末尾字符设置为空字符 ‘\0’,保证新的字符串正确终止。
_size = n;:最后将字符串的大小 _size 更新为新的大小 n。
这样,resize 函数可以根据传入的大小 n,扩展或缩小字符串的大小,并在必要时添加或删除字符。
7.8 string类insert函数、append函数、push_back函数、+=重载
insert函数
insert的模拟实现主要实现字符和字符串插入两种
字符插入
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
// 满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
insert 函数在字符串中指定位置插入一个字符。这里简单解释一下这个函数的实现:
string& insert(size_t pos, char ch):这是 std::string 类中的 insert 函数的声明,表示该函数将在指定位置 pos 插入字符 ch。pos 是传入的参数,表示插入位置的索引;ch 是要插入的字符。
assert(pos <= _size);:使用 assert 断言来确保插入位置 pos 不超过字符串的实际大小 _size。如果断言失败(pos 大于 _size),则会触发断言失败错误,帮助调试找到错误的位置。
if (_size == _capacity):检查当前字符串是否已满(即 _size 等于 _capacity)。如果字符串已满,则需要扩容,以确保有足够的容量来插入新字符。这里使用 reserve 函数扩容,使字符串有足够的容量来容纳新字符。
size_t end = _size + 1;:在插入字符前,先将字符串的末尾位置(实际字符个数 _size 后面)向后移动一个位置,为新字符留出空间。这样做是为了将插入位置 pos 之后的字符后移。
while (end > pos):通过一个循环,将插入位置 pos 之后的字符依次向后移动一个位置。
_str[pos] = ch;:将字符 ch 插入到指定的插入位置 pos。
++_size;:插入字符后,将字符串的实际大小 _size 增加 1。
return *this;:返回当前 std::string 对象的引用,以支持链式调用。
字符串插入
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
// 挪动数据
size_t end = _size + len;
while (end >= pos + len)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
与上一个 insert 函数相比,这里的参数 str 是一个 C-style 字符串(const char*),而不是一个单个字符。函数的功能是在字符串中指定位置插入一个 C-style 字符串。现在来解释这个函数的实现:
string& insert(size_t pos, const char* str):这是 std::string 类中的 insert 函数的声明,表示该函数将在指定位置 pos 插入一个 C-style 字符串 str。pos 是传入的参数,表示插入位置的索引;str 是要插入的 C-style 字符串。
assert(pos <= _size);:使用 assert 断言来确保插入位置 pos 不超过字符串的实际大小 _size。如果断言失败(pos 大于 _size),则会触发断言失败错误,帮助调试找到错误的位置。
size_t len = strlen(str);:计算要插入的 C-style 字符串 str 的长度,即字符个数。
if (_size + len > _capacity):检查插入后的字符串大小是否超过当前的容量 _capacity,如果超过,则需要扩容,以确保有足够的容量来容纳插入的字符串。
reserve(_size + len);:调用 reserve 函数来扩容,保证有足够的容量来容纳插入的字符串。
size_t end = _size + len;:在插入字符串前,先将字符串的末尾位置(实际字符个数 _size 后面)向后移动 len 个位置,为新字符串留出空间。
while (end >= pos + len):通过一个循环,将插入位置 pos 之后的字符依次向后移动 len 个位置,为新字符串的插入留出空间。
strncpy(_str + pos, str, len);:使用 strncpy 函数将 C-style 字符串 str 复制到指定的插入位置 pos,并且只复制 len 个字符。
_size += len;:插入字符串后,将字符串的实际大小 _size 增加 len,以反映插入后的新大小。
return *this;:返回当前 std::string 对象的引用,以支持链式调用。
append函数
void append(const char* str)
{
size_t len = strlen(str);
// 满了就扩容
if (_size + len > _capacity)
{
reserve(_size+len);
}
strcpy(_str + _size, str);
//strcat(_str, str); 需要找\0,效率低
_size += len;
}
append 函数用于在字符串末尾添加一个 C-style 字符串。现在来解释这个函数的实现:
void append(const char* str):这是 std::string 类中的 append 函数的声明,表示该函数将在字符串末尾添加一个 C-style 字符串 str。str 是传入的参数,表示要添加的 C-style 字符串。
size_t len = strlen(str);:计算要添加的 C-style 字符串 str 的长度,即字符个数。
if (_size + len > _capacity):检查添加后的字符串大小是否超过当前的容量 _capacity,如果超过,则需要扩容,以确保有足够的容量来容纳添加的字符串。
reserve(_size + len);:调用 reserve 函数来扩容,保证有足够的容量来容纳添加的字符串。
strcpy(_str + _size, str);:使用 strcpy 函数将 C-style 字符串 str 复制到字符串末尾,即从 _str 的实际字符个数 _size 处开始复制。
_size += len;:添加字符串后,将字符串的实际大小 _size 增加 len,以反映添加后的新大小。
这样,append 函数将 C-style 字符串 str 添加到字符串末尾,并且在必要时进行了内存扩容。
当然你可以对insert函数复用
void append(const char* str)
{
insert(_size, str);
}
push_back函数
void push_back(char ch)
{
// 满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
push_back 函数用于在字符串末尾添加一个字符。现在来解释这个函数的实现:
void push_back(char ch):这是 std::string 类中的 push_back 函数的声明,表示该函数将在字符串末尾添加一个字符 ch。ch 是传入的参数,表示要添加的字符。
if (_size == _capacity):检查当前字符串是否已满(即 _size 等于 _capacity)。如果字符串已满,则需要扩容,以确保有足够的容量来容纳新增的字符。这里使用 reserve 函数扩容,使字符串有足够的容量来容纳新字符。
_str[_size] = ch;:将字符 ch 添加到字符串末尾,即在 _str 的实际字符个数 _size 处添加字符。
++_size;:字符串的实际大小 _size 增加 1,以反映添加后的新大小。
_str[_size] = '\0';:在字符串末尾添加一个空字符 ‘\0’,以保证新的字符串正确终止。
这样,push_back 函数将字符 ch 添加到字符串末尾,并在必要时进行了内存扩容。
同样的,push_back 函数你也可以对insert函数复用
void push_back(char ch)
{
insert(_size, ch);
}
+=重载
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
operator+= 运算符重载用于在现有字符串后追加字符或 C-style 字符串。现在来解释这个函数的实现:
string& operator+=(char ch):这是 operator+= 运算符重载的第一个版本,表示该运算符将在字符串末尾追加一个字符 ch。在这个版本中,直接调用了 push_back 函数,将字符 ch 添加到字符串末尾。
string& operator+=(const char* str):这是 operator+= 运算符重载的第二个版本,表示该运算符将在字符串末尾追加一个 C-style 字符串 str。在这个版本中,直接调用了 append 函数,将 C-style 字符串 str 添加到字符串末尾。
在两个版本的实现中,都返回当前 std::string 对象的引用,以支持链式调用。
7.9 string类erase函数
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
erase 函数用于从字符串中删除指定位置开始的一定长度的字符。现在来解释这个函数的实现:
void erase(size_t pos, size_t len = npos):这是 std::string 类中的 erase 函数的声明,表示该函数将从指定位置 pos 开始删除一定长度 len 的字符。pos 是传入的参数,表示删除的起始位置的索引;len 是要删除的字符个数,默认值为 npos,表示删除从起始位置开始的所有字符。
assert(pos < _size);:使用 assert 断言来确保删除的起始位置 pos 不超过字符串的实际大小 _size。如果断言失败(pos 大于等于 _size),则会触发断言失败错误,帮助调试找到错误的位置。
if (len == npos || pos + len >= _size):检查是否要删除从起始位置 pos 开始的所有字符(即 len 等于 npos),或者是否要删除的字符个数超过字符串末尾(即 pos + len 大于等于 _size)。如果是其中一种情况,表示要删除从 pos 开始的所有字符或从 pos 开始直到末尾的所有字符。
_str[pos] = '\0'; 和 _size = pos;:在上述情况下,将字符串从位置 pos 处截断,即将字符数组的第 pos 个字符设置为空字符 ‘\0’,并更新字符串的实际大小 _size 为 pos,以反映删除后的新大小。
else:如果要删除的字符个数小于字符串末尾的字符个数,则需要将后面的字符向前移动。
strcpy(_str + pos, _str + pos + len);:将从位置 pos + len 开始的字符复制到位置 pos,覆盖掉要删除的字符。
_size -= len;:删除字符后,将字符串的实际大小 _size 减去 len,以反映删除后的新大小。
7.10 string类erase函数
size_t find(char ch, size_t pos = 0) const
{
assert(pos < _size);
for (size_t i = pos; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
find 函数用于在字符串中查找指定字符或子串,并返回其位置。现在来解释这个函数的实现:
size_t find(char ch, size_t pos = 0) const:这是 std::string 类中的 find 函数的第一个版本,表示该函数将在字符串中从位置 pos 开始查找字符 ch。pos 是传入的参数,表示查找的起始位置的索引,默认值为 0,表示从字符串的开头开始查找。
assert(pos < _size);:使用 assert 断言来确保查找的起始位置 pos 不超过字符串的实际大小 _size。如果断言失败(pos 大于等于 _size),则会触发断言失败错误,帮助调试找到错误的位置。
在这个版本中,使用了简单的循环遍历,从位置 pos 开始遍历字符串,查找是否存在字符 ch。如果找到了,就返回该字符的位置索引;如果未找到,则返回 npos。
size_t find(const char* sub, size_t pos = 0) const
{
assert(sub);
assert(pos < _size);
const char* ptr = strstr(_str + pos, sub);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
size_t find(const char* sub, size_t pos = 0) const:这是 std::string 类中的 find 函数的第二个版本,表示该函数将在字符串中从位置 pos 开始查找子串 sub。sub 是传入的参数,表示要查找的子串;pos 是传入的参数,表示查找的起始位置的索引,默认值为 0,表示从字符串的开头开始查找。
assert(sub);:使用 assert 断言来确保传入的子串 sub 不为空指针。如果断言失败(sub 为空指针),则会触发断言失败错误,帮助调试找到错误的位置。
assert(pos < _size);:同样,使用 assert 断言来确保查找的起始位置 pos 不超过字符串的实际大小 _size。
在这个版本中,使用 strstr 函数在字符串中查找子串 sub,如果找到了,就返回子串的位置索引;如果未找到,则返回 npos。
7.11 string类substr 函数
string substr(size_t pos, size_t len = npos) const
{
assert(pos < _size);
size_t realLen = len;
if (len == npos || pos + len > _size)
{
realLen = _size - pos;
}
string sub;
for (size_t i = 0; i < realLen; ++i)
{
sub += _str[pos + i];
}
return sub;
}
substr 函数用于从字符串中提取子串,从指定位置 pos 开始,并且可选地指定子串的长度 len。现在来解释这个函数的实现:
string substr(size_t pos, size_t len = npos) const:这是 std::string 类中的 substr 函数的声明,表示该函数将从指定位置 pos 开始提取子串,并且可选地指定子串的长度 len。pos 是传入的参数,表示提取子串的起始位置的索引;len 是传入的参数,表示要提取的子串的长度,默认值为 npos,表示提取从起始位置 pos 开始的所有字符。
assert(pos < _size);:使用 assert 断言来确保提取子串的起始位置 pos 不超过字符串的实际大小 _size。如果断言失败(pos 大于等于 _size),则会触发断言失败错误,帮助调试找到错误的位置。
size_t realLen = len;:定义一个变量 realLen,用于存储实际要提取的子串的长度。初始值为传入的参数 len。
if (len == npos || pos + len > _size):检查是否要提取从起始位置 pos 开始的所有字符(即 len 等于 npos),或者是否要提取的字符个数超过字符串末尾(即 pos + len 大于等于 _size)。如果是其中一种情况,表示要提取从 pos 开始的所有字符或从 pos 开始直到末尾的所有字符。此时,将 realLen 更新为从 pos 开始到末尾的字符个数。创建一个名为 sub 的新的 std::string 对象,用于存储提取的子串。使用循环从位置 pos 开始,逐个字符地将子串添加到 sub 中。返回提取的子串 sub。
7.12 string类比较运算符重载
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
这是大于运算符 > 的重载版本,表示该运算符用于比较当前字符串与另一个字符串 s 的大小关系。在这个版本中,使用 strcmp 函数比较两个字符串 _str 和 s._str 的字典序。如果 _str 大于 s._str,则返回 true,否则返回 false。
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
这是等于运算符 == 的重载版本,表示该运算符用于比较当前字符串与另一个字符串 s 是否相等。同样,使用 strcmp 函数比较两个字符串 _str 和 s._str 的内容是否相同。如果相同,返回 true,否则返回 false。
bool operator>=(const string& s) const
{
return *this > s || *this == s;
}
这是大于等于运算符 >= 的重载版本,表示该运算符用于比较当前字符串是否大于或等于另一个字符串 s。在这个版本中,直接使用已经定义好的大于运算符 > 和等于运算符 == 进行组合,如果当前字符串大于 s 或者与 s 相等,则返回 true,否则返回 false。
bool operator<=(const string& s) const
{
return !(*this > s);
}
这是小于等于运算符 <= 的重载版本,表示该运算符用于比较当前字符串是否小于或等于另一个字符串 s。同样,直接使用已经定义好的大于等于运算符 >= 进行取反,如果当前字符串小于 s,则返回 true,否则返回 false。
bool operator<(const string& s) const
{
return !(*this >= s);
}
这是小于运算符 < 的重载版本,表示该运算符用于比较当前字符串是否小于另一个字符串 s。同样,直接使用已经定义好的大于等于运算符 >= 进行取反,如果当前字符串不大于等于 s,则说明当前字符串小于 s,返回 true,否则返回 false。
bool operator!=(const string& s) const
{
return !(*this == s);
}
这是不等于运算符 != 的重载版本,表示该运算符用于比较当前字符串是否不等于另一个字符串 s。同样,直接使用已经定义好的等于运算符 == 进行取反,如果当前字符串与 s 不相等,则返回 true,否则返回 false。
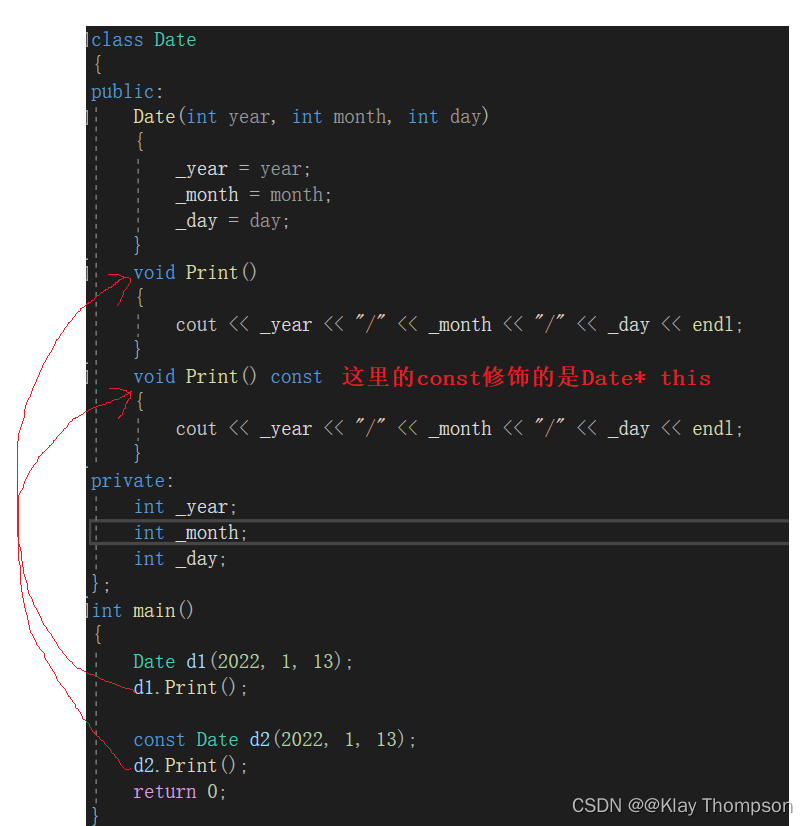
其实和之前类和对象的文章中讲到的日期类比较运算符重载一样,先实现> == 或< ==后面的都可以进行复用。
7.13 string类流插入<<和流提取>>重载
首先这里要注意的是,流插入和流提取在这里定义为全局函数,因此我们不要再类中定义,而是在类外,即全局定义。这样定义的运算符重载函数不属于类的成员,因此在其实现中不能直接访问类的私有成员,而需要通过类的公有接口进行访问。
运算符重载函数可以作为成员函数或全局非成员函数进行定义,具体取决于使用场景和设计需求。通常情况下,如果运算符的操作数为类对象本身或需要直接访问类的私有成员,可以考虑将其定义为成员函数。而如果运算符的操作数为类对象外的其他类型,或者运算符涉及的操作不仅限于类对象本身,可以考虑将其定义为全局非成员函数。
流插入<<
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
out << s[i];
}
return out;
}
这是输出运算符 << 的重载版本,表示将 std::string 类对象 s 输出到输出流 out 中。
使用一个循环遍历 s 中的每个字符,并将每个字符依次输出到输出流 out 中。最后,将输出流 out 返回,以支持链式输出。
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
const size_t N = 32;
char buff[N];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
buff[i] = '\0';
s += buff;
return in;
}
这是输入运算符 >> 的重载版本,表示将输入流 in 中的数据读取并存储到 std::string 类对象 s 中。
首先调用 s.clear() 函数,将 s 的内容清空,以便接收新的输入。然后,使用一个循环从输入流 in 中逐个读取字符 ch。如果字符 ch 不是空格或换行符,就将字符添加到一个临时字符数组 buff 中,并增加索引 i。一旦 buff 已满(i == N - 1),就将 buff 最后一个元素设为空字符 ‘\0’,然后将 buff 添加到 s 中,然后将索引 i 重置为 0,以继续接收后续字符。如果字符 ch 是空格或换行符,说明一个单词的输入结束,将 buff 最后一个元素设为空字符 ‘\0’,然后将 buff 添加到 s 中。最后,将输入流 in 返回,以支持链式输入。
8.string类的模拟实现(完整代码)
#include<iostream>
#include<string.h>
#include<assert.h>
using namespace std;
namespace mystring
{
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator begin() const
{
return _str;
}
const_iterator end() const
{
return _str + _size;
}
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// 传统写法
//string(const string& s)
// :_str(new char[s._capacity+1])
// , _size(s._size)
// , _capacity(s._capacity)
//{
// strcpy(_str, s._str);
//}
// 现代写法
void swap(string& tmp)
{
::swap(_str, tmp._str);
::swap(_size, tmp._size);
::swap(_capacity, tmp._capacity);
}
string(const string& s)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string tmp(s._str);
swap(tmp);
}
//string& operator=(const string& s)
//{
// if (this != &s)
// {
// //string tmp(s._str);
// string tmp(s);
// swap(tmp); // this->swap(tmp);
// }
// return *this;
//}
string& operator=(string s)
{
swap(s);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
const char* c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
const char& operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void resize(size_t n, char ch = '\0')
{
if (n > _size)
{
// 插入数据
reserve(n);
for (size_t i = _size; i < n; ++i)
{
_str[i] = ch;
}
_str[n] = '\0';
_size = n;
}
else
{
// 删除数据
_str[n] = '\0';
_size = n;
}
}
void push_back(char ch)
{
// 满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
//insert(_size, ch);
}
void append(const char* str)
{
size_t len = strlen(str);
// 满了就扩容
if (_size + len > _capacity)
{
reserve(_size+len);
}
strcpy(_str + _size, str);
//strcat(_str, str); 需要找\0,效率低
_size += len;
//insert(_size, str);
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& insert(size_t pos, char ch)
{
assert(pos <= _size);
// 满了就扩容
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
size_t end = _size + 1;
while (end > pos)
{
_str[end] = _str[end - 1];
--end;
}
_str[pos] = ch;
++_size;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
// 挪动数据
size_t end = _size + len;
while (end >= pos + len)
{
_str[end] = _str[end - len];
--end;
}
strncpy(_str + pos, str, len);
_size += len;
return *this;
}
void erase(size_t pos, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
size_t find(char ch, size_t pos = 0) const
{
assert(pos < _size);
for (size_t i = pos; i < _size; ++i)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
size_t find(const char* sub, size_t pos = 0) const
{
assert(sub);
assert(pos < _size);
// kmp/bm
const char* ptr = strstr(_str + pos, sub);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;
}
}
string substr(size_t pos, size_t len = npos) const
{
assert(pos < _size);
size_t realLen = len;
if (len == npos || pos + len > _size)
{
realLen = _size - pos;
}
string sub;
for (size_t i = 0; i < realLen; ++i)
{
sub += _str[pos + i];
}
return sub;
}
bool operator>(const string& s) const
{
return strcmp(_str, s._str) > 0;
}
bool operator==(const string& s) const
{
return strcmp(_str, s._str) == 0;
}
bool operator>=(const string& s) const
{
return *this > s || *this == s;
}
bool operator<=(const string& s) const
{
return !(*this > s);
}
bool operator<(const string& s) const
{
return !(*this >= s);
}
bool operator!=(const string& s) const
{
return !(*this == s);
}
private:
size_t _capacity;
size_t _size;
char* _str;
public:
const static size_t npos = -1;
};
ostream& operator<<(ostream& out, const string& s)
{
for (size_t i = 0; i < s.size(); ++i)
{
out << s[i];
}
return out;
}
istream& operator>>(istream& in, string& s)
{
s.clear();
char ch;
ch = in.get();
const size_t N = 32;
char buff[N];
size_t i = 0;
while (ch != ' ' && ch != '\n')
{
buff[i++] = ch;
if (i == N - 1)
{
buff[i] = '\0';
s += buff;
i = 0;
}
ch = in.get();
}
buff[i] = '\0';
s += buff;
return in;
}
}
结语
有兴趣的小伙伴可以关注作者,如果觉得内容不错,请给个一键三连吧,蟹蟹你哟!!!
制作不易,如有不正之处敬请指出
感谢大家的来访,UU们的观看是我坚持下去的动力
在时间的催化剂下,让我们彼此都成为更优秀的人吧!!!