SVO: Fast Semi-Direct Monocular Visual Odometry
摘要
我们提出了一种半直接单目视觉测距算法,该算法精确、鲁棒且比当前算法更快最先进的方法。半直接方法为运动估计技术消除了需要高成本的特征提取和鲁棒匹配。我们的算法可直接在像素强度上处理,以较高速率获得亚像素精度。一种概率映射方法显式建模异常值测量用于估计3D点,这导致更少的异常值和更可靠的点。精确和高帧率的运动估计带来了在少量、重复和高频场景中的稳健性纹理该算法应用于GPS拒绝环境下的微型飞行器状态估计,并在55帧下运行在板载嵌入式计算机上每秒及更多在消费型笔记本电脑上每秒超过300帧。我们称之为SVO(半直接视觉里程计)并进行开源。
开源链接
介绍
分类:
- 特征点法
- 直接法
贡献
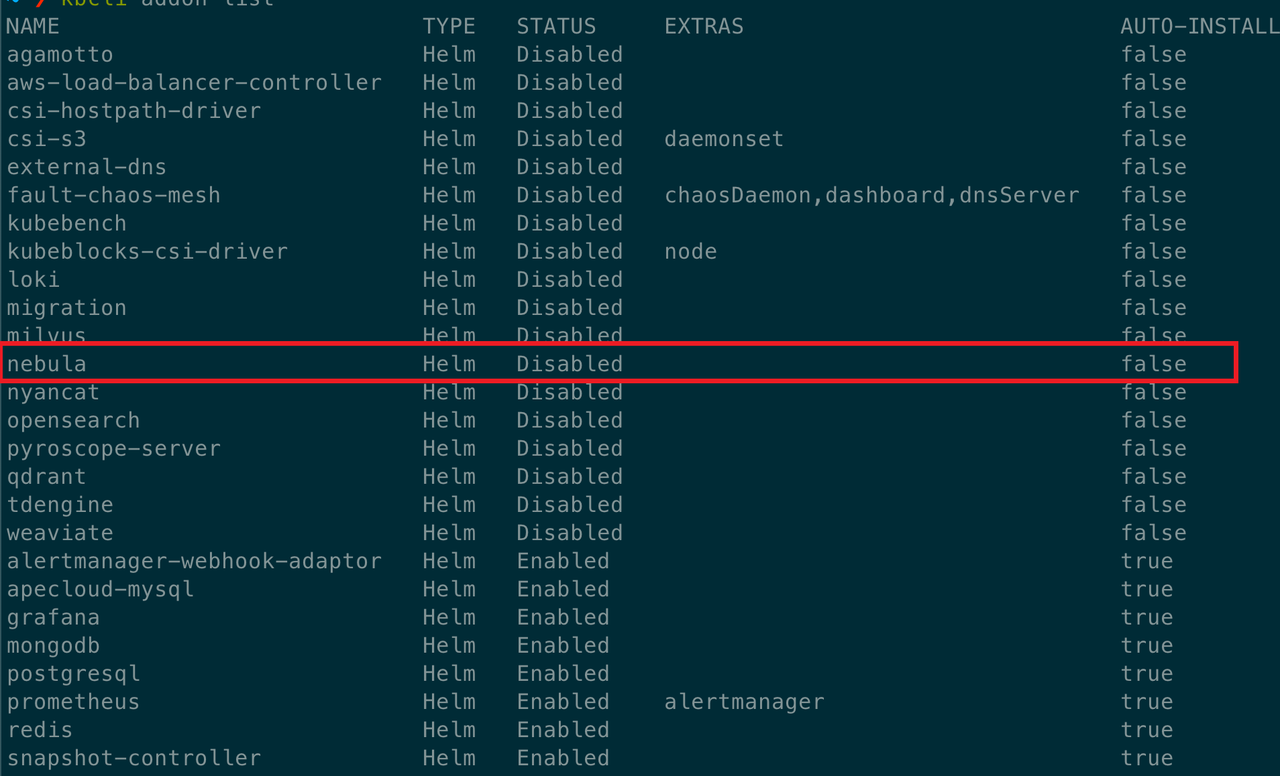
提出的半直接视觉里程计(SVO)算法使用特征相关;然而,特征相关是直接运动估计的隐含结果,而不是显式特征提取和匹配的结果。因此,只有当帧被选择为关键帧时才会初始化新的3D点(见图1)。优点是由于避免对每帧进行特征提取而提高了速度,并且通过亚像素特征相关增加精度。与之前的直接方法相比,我们使用许多(数百)个小patch而不是几个(几十个)大的平面patch[18]-[21]。使许多小的patch增加鲁棒性并允许忽略patch法线。所提出的基于稀疏模型的用于运动估计的图像对准算法与基于模型的密集图像对齐[8]-[10],[24]。然而我们证明了稀疏的深度信息是足够的获得运动的粗略估计并找到特征对应关系。一旦特征关联和建立了初始位姿估计,算法后续会仅使用点特征;因此名称“半直接”。这种切换使我们能够保持快速和进行BA过程(例如,[25])。使用显式地对异常值测量进行建模的贝叶斯滤波器来估计特征位置处的深度。一个3d点只有当对应的深度滤波器进行多次测量收敛后,才会被插入地图中。得到一张几乎没有异常值和点的地图从而可以可靠地跟踪。
本文贡献
- 用于无人机的达到先进水平的半直接vo算法
- 建图的方法对外点非常鲁棒
系统概述
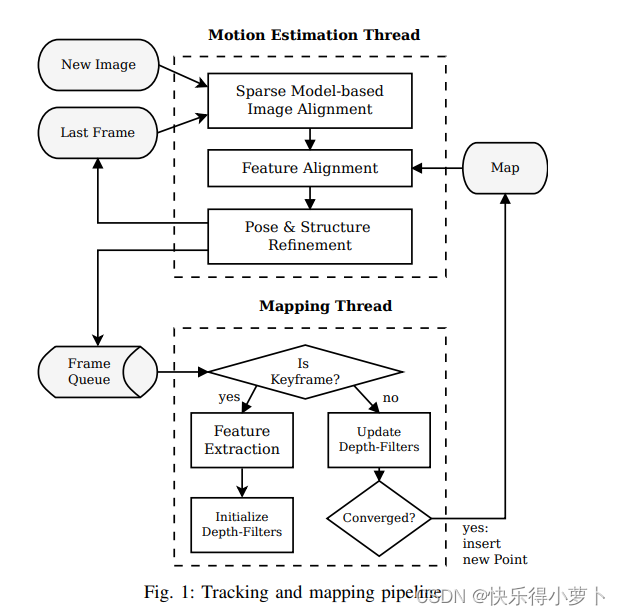
图1提供了SVO的概述。算法使用两个并行线程(如[16]所示),其中一个用于估计相机运动,以及第二个用于建图为环境正在被探索。这种分离允许快速和一个线程中的恒定时间跟踪,而第二个线程建图线程硬实时限制解耦。运动估计线程实现了所提出的相对姿态估计的半直接方法。第一个步骤是通过基于稀疏模型的图像进行姿态初始化对齐:摄影机相对于上一帧的姿势是通过最小化与相同的投影位置相对应的像素三维点(见图2)。对应的二维坐标到在下一步中通过对齐相应的特征补丁(见图3) 。运动估计通过使用特征对齐的像素块的细化姿态和最小化重投影误差的结构。
在mapping线程中,为每个2D特征初始化概率深度滤波器,其中对应的需要估计三维点。新的深度过滤器已初始化每当在图像区域中选择新的关键帧时其中很少发现3D-2D对应关系。深度滤器在深度上初始化一个很大的不确定度。每在随后的帧中,深度估计在贝叶斯中被更新时尚(见图5)。当深度滤波器的不确定性变得足够小时,会把点插入到地图中,并立即用于运动估计。
记号
在详细介绍算法之前,我们简要定义通篇论文中使用的符号。在时间步长
k
k
k处收集的强度图像表示为
I
k
I_k
Ik,
Ω
⊂
R
2
↦
R
\Omega \subset \mathbb{R}^{2} \mapsto \mathbb{R}
Ω⊂R2↦R 这里的
Ω
\Omega
Ω是图像坐标系。任意的3d点
Ω
⊂
R
2
↦
R
,
p
=
(
x
,
y
,
z
)
⊤
∈
S
\Omega \subset \mathbb{R}^{2} \mapsto \mathbb{R} ,\mathbf{p}=(x, y, z)^{\top} \in \mathcal{S}
Ω⊂R2↦R,p=(x,y,z)⊤∈S在可见场景表面上 通过相机投影模型
u
=
π
(
k
p
)
\mathbf{u}=\pi\left({ }_k \mathbf{p}\right)
u=π(kp)
其中下标k表示点坐标在参考k的相机帧中表示。投影π由标定已知的本征相机参数决定。给定逆投影函数π−1和深度Du∈R,可以恢复对应于图像坐标u的3D点:
k
p
=
π
−
1
(
u
,
d
u
)
{ }_k \mathbf{p}=\pi^{-1}\left(\mathbf{u}, d_{\mathbf{u}}\right)
kp=π−1(u,du)
其中 R ⊆ Ω 是深度已知的域。时间步 k 处的相机位置和方向用刚体变换
T
k
,
w
∈
S
E
(
3
)
T_{k,w} ∈ SE(3)
Tk,w∈SE(3)表示。它允许我们将世界坐标帧中的 3D 点映射到参考的相机帧:
k
p
=
T
k
,
w
w
p
kp = T_{k,w} w_p
kp=Tk,wwp。两个连续帧之间的相对变换可以用
T
k
,
k
−
1
=
T
k
,
w
T
k
−
1
,
w
−
1
T_{k,k−1} = T_{k,w}T^{-1}_{k−1,w}
Tk,k−1=Tk,wTk−1,w−1计算。在优化过程中,我们需要变换的最小表示,因此,使用对应于身份SE(3)切线空间的李代数se(3)。我们表示代数元素——也称为扭曲坐标——ξ = (ω, ν)T ∈ R6,其中 ω 称为角速度,ν 表示线性速度。扭转坐标ξ通过指数映射[26]映射到SE(3):
T
(
ξ
)
=
e
x
p
(
ξ
)
T(ξ) = exp(ξ)
T(ξ)=exp(ξ)。
运动估计
SVO 使用直接方法计算相对相机运动和特征对应的初步猜测,并以基于特征的非线性重投影误差细化结束。以下各节详细介绍了每个步骤,如图 2 至 4 所示。
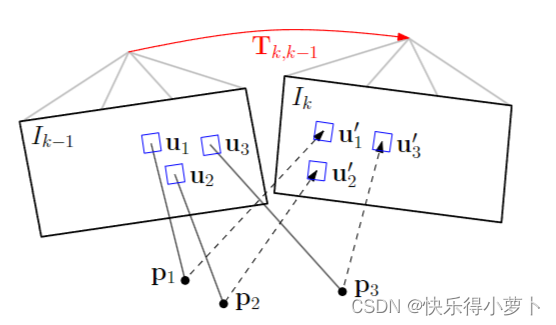
图2:改变当前帧和前一帧之间的相对姿态 T k , k − 1 T_{k,k−1} Tk,k−1隐式地移动重投影点在新图像u 'i中的位置。稀疏图像对齐试图找到 T k , k − 1 T_{k,k−1} Tk,k−1,以最小化对应于相同3D点(蓝色方块)的图像补丁之间的光度差异。请注意,在所有图中,要优化的参数以红色绘制,优化成本以蓝色突出显示。
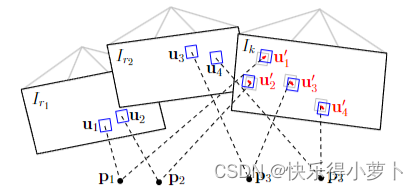
图 3:由于 3D 点和相机位姿估计的不准确性,可以通过单独优化每个补丁的 2D 位置来进一步最小化当前帧和先前关键帧
r
i
r_i
ri 中相应补丁(蓝色方块)之间的光度误差。
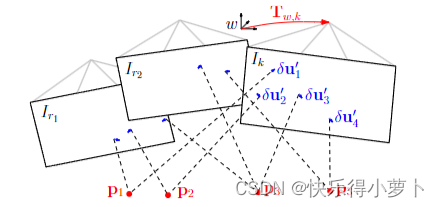
图4:在最后的运动估计步骤中,对相机姿态和结构(3D点)进行优化,以最小化在之前的特征对齐步骤中建立的重投影误差。
基于稀疏模型的图像对齐
两个连续相机姿态之间刚体变换
T
k
,
k
−
1
T_{k,k−1}
Tk,k−1的最大似然估计使强度残差的负对数似然最小化:
T
k
,
k
−
1
=
arg
min
T
∬
R
‾
ρ
[
δ
I
(
T
,
u
)
]
d
u
.
\mathbf{T}_{k, k-1}=\arg \min _{\mathbf{T}} \iint_{\overline{\mathcal{R}}} \rho[\delta I(\mathbf{T}, \mathbf{u})] d \mathbf{u} .
Tk,k−1=argTmin∬Rρ[δI(T,u)]du.
强度残差
δ
I
δI
δI 由观察相同3D点的像素之间的光度差定义。它可以通过从前一个图像
I
k
−
1
I_{k−1}
Ik−1反向投影2D点
u
u
u,然后将其投影到当前相机视图中来计算:
δ
I
(
T
,
u
)
=
I
k
(
π
(
T
⋅
π
−
1
(
u
,
d
u
)
)
)
−
I
k
−
1
(
u
)
∀
u
∈
R
‾
\delta I(\mathbf{T}, \mathbf{u})=I_k\left(\pi\left(\mathbf{T} \cdot \pi^{-1}\left(\mathbf{u}, d_{\mathbf{u}}\right)\right)\right)-I_{k-1}(\mathbf{u}) \quad \forall \mathbf{u} \in \overline{\mathcal{R}}
δI(T,u)=Ik(π(T⋅π−1(u,du)))−Ik−1(u)∀u∈R
其中 ̄R这个条件是深度
d
u
d_u
du在时间 k-1 已知的图像区域,并且反向投影点在当前图像域可见:
R
‾
=
{
u
∣
u
∈
R
k
−
1
∧
π
(
T
⋅
π
−
1
(
u
,
d
u
)
)
∈
Ω
k
}
\overline{\mathcal{R}}=\left\{\mathbf{u} \mid \mathbf{u} \in \mathcal{R}_{k-1} \wedge \pi\left(\mathbf{T} \cdot \pi^{-1}\left(\mathbf{u}, d_{\mathbf{u}}\right)\right) \in \Omega_k\right\}
R={u∣u∈Rk−1∧π(T⋅π−1(u,du))∈Ωk}
为简单起见,我们假设强度残差服从单位方差的正态分布。然后负对数似然最小化器对应于最小二乘问题:
ρ
[
.
]
=
^
1
2
∥
.
∥
2
\rho[.] \hat{=} \frac{1}{2}\|.\|^2
ρ[.]=^21∥.∥2。在实践中,由于遮挡,分布具有较重的尾部,因此必须应用稳健的成本函数[10]。与之前的工作相比,对于图像[8]-[10],[24]中的大区域,我们只知道稀疏特征位置
u
i
u_i
ui的深度
d
u
i
d_{ui}
dui。我们用向量
I
(
u
i
)
I(u_i)
I(ui)表示特征点周围 4 × 4 像素的小块。我们寻求找到最小化的相机姿势所有补丁的光度误差(见图2):
T
k
,
k
−
1
=
arg
min
T
k
,
k
−
1
1
2
∑
i
∈
R
∥
δ
I
(
T
k
,
k
−
1
,
u
i
)
∥
2
\mathbf{T}_{k, k-1}=\arg \min _{\mathbf{T}_{k, k-1}} \frac{1}{2} \sum_{i \in \mathcal{\mathcal { R }}}\left\|\delta \mathbf{I}\left(\mathbf{T}_{k, k-1}, \mathbf{u}_i\right)\right\|^2
Tk,k−1=argTk,k−1min21i∈R∑∥δI(Tk,k−1,ui)∥2
由于等式 (7) 在
T
k
,
k
−
1
T_{k,k−1}
Tk,k−1中是非线性的,我们在迭代高斯-牛顿过程中对其进行了求解。给定相对变换
T
k
,
k
−
1
T_{k,k−1}
Tk,k−1的估计,估计的增量更新T(ξ)可以用ξ∈se(3)参数化。我们使用强度残差的逆组合公式[27],它在k−1时刻计算参考图像的更新步骤T(ξ):
δ
I
(
ξ
,
u
i
)
=
I
k
(
π
(
T
^
k
,
k
−
1
⋅
p
i
)
)
−
I
k
−
1
(
π
(
T
(
ξ
)
⋅
p
i
)
)
\delta \mathbf{I}\left(\xi, \mathbf{u}_i\right)=\mathbf{I}_k\left(\pi\left(\hat{\mathbf{T}}_{k, k-1} \cdot \mathbf{p}_i\right)\right)-\mathbf{I}_{k-1}\left(\pi\left(\mathbf{T}(\xi) \cdot \mathbf{p}_i\right)\right)
δI(ξ,ui)=Ik(π(T^k,k−1⋅pi))−Ik−1(π(T(ξ)⋅pi))
其中
p
i
=
π
−
1
(
u
i
,
d
u
i
)
p_i = \pi^{-1}(u_i, d_{u_i})
pi=π−1(ui,dui).然后使用等式 (3) 将更新步骤的逆应用于当前估计:
T
^
k
,
k
−
1
⟵
T
^
k
,
k
−
1
⋅
T
(
ξ
)
−
1
\hat{\mathbf{T}}_{k, k-1} \longleftarrow \hat{\mathbf{T}}_{k, k-1} \cdot \mathbf{T}(\boldsymbol{\xi})^{-1}
T^k,k−1⟵T^k,k−1⋅T(ξ)−1
请注意,我们不会扭曲补丁以计算速度原因。对于小帧到帧的运动和小补丁大小,这个假设是有效的。为了找到最优更新步骤
T
(
ξ
)
T(ξ)
T(ξ),我们计算 (7) 的导数并将其设置为零:
∑
i
∈
R
‾
∇
δ
I
(
ξ
,
u
i
)
⊤
δ
I
(
ξ
,
u
i
)
=
0
\sum_{i \in \overline{\mathcal{R}}} \nabla \delta \mathbf{I}\left(\xi, \mathbf{u}_i\right)^{\top} \delta \mathbf{I}\left(\xi, \mathbf{u}_i\right)=0
i∈R∑∇δI(ξ,ui)⊤δI(ξ,ui)=0
为了解决这个问题,我们围绕当前状态线性化:
δ
I
(
ξ
,
u
i
)
≈
δ
I
(
0
,
u
i
)
+
∇
δ
I
(
0
,
u
i
)
⋅
ξ
\delta \mathbf{I}\left(\xi, \mathbf{u}_i\right) \approx \delta \mathbf{I}\left(0, \mathbf{u}_i\right)+\nabla \delta \mathbf{I}\left(0, \mathbf{u}_i\right) \cdot \xi
δI(ξ,ui)≈δI(0,ui)+∇δI(0,ui)⋅ξ
雅可比 Ji := ∇δ I(0, ui) 的维度为 16 × 6,因为 4 × 4 补丁大小,并使用链式法则计算:
∂
δ
I
(
ξ
,
u
i
)
∂
ξ
=
∂
I
k
−
1
(
a
)
∂
a
∣
a
=
u
i
⋅
∂
π
(
b
)
∂
b
∣
b
=
p
i
⋅
∂
T
(
ξ
)
∂
ξ
∣
ξ
=
0
⋅
p
i
\frac{\partial \delta \mathbf{I}\left(\xi, \mathbf{u}_i\right)}{\partial \xi}=\left.\left.\left.\frac{\partial \mathbf{I}_{k-1}(\mathbf{a})}{\partial \mathbf{a}}\right|_{\mathbf{a}=\mathbf{u}_i} \cdot \frac{\partial \pi(\mathbf{b})}{\partial \mathbf{b}}\right|_{\mathbf{b}=\mathbf{p}_i} \cdot \frac{\partial \mathbf{T}(\xi)}{\partial \xi}\right|_{\xi=0} \cdot \mathbf{p}_i
∂ξ∂δI(ξ,ui)=∂a∂Ik−1(a)
a=ui⋅∂b∂π(b)
b=pi⋅∂ξ∂T(ξ)
ξ=0⋅pi
通过将 (11) 插入 (10) 并通过在矩阵
J
J
J 中堆叠雅可比矩阵,我们得到以下等式:
它可以求解更新扭转ξ值。请注意,通过使用逆组合方法,雅可比可以预先计算,因为它在所有迭代(参考补丁 I k − 1 ( u i ) I_{k−1}(ui) Ik−1(ui) 和点 p i p_i pi 没有变化)上保持不变,这导致了显着的加速 [27]。
通过特征对齐松弛
在上一步将相机与之前的帧对齐。通过投影,找到的相对姿态 T k , k − 1 T_{k,k-1} Tk,k−1 隐含地定义了对新图像中所有可见 3D 点的特征位置的初步猜测。由于 3D 点位置不准确,以及相机位姿,这些初始猜测可以被提高。为了减少漂移,相机姿态应该与地图对齐,而不是与以前的帧对齐。
从估计的相机姿态可见的地图的所有 3D 点被投影到图像中,从而得到相应 2D 特征位置
u
′
i
u′_i
u′i 的估计(见图 3)。对于每个重投影点,关键帧 r 确定了观测角度最接近的点。然后,特征对齐步骤通过最小化当前图像中patch相对于关键帧 r 中的参考patch的光度误差来单独优化新图像中的所有 2D 特征位置
u
i
u_i
ui:
u
i
′
=
arg
min
u
i
′
1
2
∥
I
k
(
u
i
′
)
−
A
i
⋅
I
r
(
u
i
)
∥
2
,
∀
i
\mathbf{u}_i^{\prime}=\arg \min _{\mathbf{u}_i^{\prime}} \frac{1}{2}\left\|\mathbf{I}_k\left(\mathbf{u}_i^{\prime}\right)-\mathbf{A}_i \cdot \mathbf{I}_r\left(\mathbf{u}_i\right)\right\|^2, \quad \forall i
ui′=argui′min21∥Ik(ui′)−Ai⋅Ir(ui)∥2,∀i
这种对齐是使用逆组合Lucas-Kanade算法[27]来解决的。与之前的步骤相反,我们将仿射扭曲Ai应用于参考补丁,因为使用了更大的补丁大小(8 × 8像素),并且最近的关键帧通常比以前的图像更远。这一步可以理解为违反极线约束的松弛步骤,以实现特征补丁之间的更高相关性。
姿态和结构细化
在上一步中,我们以违反极线约束为代价,建立了亚像素精度的特征对应关系。特别是,我们生成了重投影残差
∣
∣
δ
u
i
∣
∣
=
∣
∣
u
i
−
π
(
T
k
,
w
w
p
i
)
∣
∣
≠
0
||δ u_i|| = ||u_i − π(T_{k,w} w_{p_i})|| \not= 0
∣∣δui∣∣=∣∣ui−π(Tk,wwpi)∣∣=0,平均约为 0.3 像素(见图 11)。在最后一步中,我们再次优化相机位姿 T_{k,w} 以最小化重投影残差(见图 4):
T
k
,
w
=
arg
min
T
k
,
w
1
2
∑
i
∥
u
i
−
π
(
T
k
,
w
w
p
i
)
∥
2
.
\mathbf{T}_{k, w}=\arg \min _{\mathbf{T}_{k, w}} \frac{1}{2} \sum_i\left\|\mathbf{u}_i-\pi\left(\mathbf{T}_{k, w}{ }_w \mathbf{p}_i\right)\right\|^2 .
Tk,w=argTk,wmin21i∑∥ui−π(Tk,wwpi)∥2.
众所周知这是仅运动 BA [17] 问题,并且可以使用高斯牛顿等迭代非线性最小二乘最小化算法有效地解决。随后,我们通过重投影误差最小化(仅结构 BA)优化观察到的 3D 点的位置。最后,可以应用局部BA,其中联合优化所有近关键帧的姿态以及观察到的3D点。BA 步骤在算法的快速参数设置中省略(第 VII 节)。
讨论
该算法的第一个(第 IV-A 节)和最后一个(第 IV-C 节)优化似乎是多余的,因为两者都优化了相机的 6 个自由度姿势。事实上,我们可以直接从第二步开始,并通过所有特征块的Lucas-Kanade跟踪[27]建立特征对应关系,然后进行非线性姿态细化(第IV-C节)。虽然这将起作用,但处理时间将更高。在大距离(例如 30 像素)上跟踪所有特征需要更大的patch和金字塔实现。此外,一些特征可能会不准确跟踪,这需要异常值检测。然而,在 SVO 中,特征对齐是通过在稀疏图像对齐步骤中仅优化六个参数(相机姿势)来有效地初始化的。稀疏图像对齐步骤隐含地满足极线约束,并确保不存在异常值。
事实上,这是最近为 RGB-D 相机开发的算法所做的 [10],但是,通过对齐完整的深度图而不是稀疏补丁。我们凭经验发现,与同时使用所有三个步骤相比,使用第一步仅会导致明显更多的漂移。提高准确性是由于新图像与关键帧和地图的对齐,而稀疏图像对齐仅相对于前一帧对齐新帧。
建图过程
给定一个图像及其姿势 I k , T k , w {I_k, T_{k,w}} Ik,Tk,w,映射线程估计尚未知道相应 3D 点的 2D 特征的深度。特征的深度估计用概率分布建模。每个后续观察 I k , T k , w {I_k, T_{k,w}} Ik,Tk,w 用于更新贝叶斯框架中的分布(见图 5),如 [28] 所示。当分布的方差足够小时,使用 (2) 将深度估计转换为 3D 点,将点插入地图中并立即用于运动估计(见图 1)。在下文中,我们报告了对 [28] 中的原始实现的基本结果和修改。
每个深度过滤器都与一个参考关键帧 r 相关联。该滤波器以深度的高度不确定性初始化,均值设置为参考帧中的平均场景深度。对于每个后续的观察 I k , T k , w {I_k, T_{k,w}} Ik,Tk,w,我们在新图像Ik中搜索与参考patch相关性最高的极线上的patch。极线可以从帧 T r , k T_{r,k} Tr,k与通过ui的光射线之间的相对姿态来计算。相关性最高的点 u i ′ u'_i ui′对应于三角剖分可以找到的深度 d i k d^k_i dik(见图5)。
测量 ̃dk i 使用高斯 + 均匀混合模型分布 [28] 建模:一个好的测量通常在真实深度 di 周围分布,而异常值测量来自区间
[
d
m
i
n
i
,
d
m
a
x
i
]
[d_{min_i} , d_{max_i}]
[dmini,dmaxi] 中的均匀分布:
p
(
d
~
i
k
∣
d
i
,
ρ
i
)
=
ρ
i
N
(
d
~
i
k
∣
d
i
,
τ
i
2
)
+
(
1
−
ρ
i
)
U
(
d
~
i
k
∣
d
i
min
,
d
i
max
)
,
p\left(\tilde{d}_i^k \mid d_i, \rho_i\right)=\rho_i \mathcal{N}\left(\tilde{d}_i^k \mid d_i, \tau_i^2\right)+\left(1-\rho_i\right) \mathcal{U}\left(\tilde{d}_i^k \mid d_i^{\min }, d_i^{\max }\right),
p(d~ik∣di,ρi)=ρiN(d~ik∣di,τi2)+(1−ρi)U(d~ik∣dimin,dimax),
其中
ρ
i
ρ_i
ρi 是内点概率,
τ
i
2
τ_i^2
τi2 是可以通过假设图像平面中一个像素的光度视差方差来几何计算的良好测量的方差 [29]。
该模型的递归贝叶斯更新步骤在[28]中有详细描述。与[28]相比,我们使用逆深度坐标来处理大场景深度。当搜索极线上当前深度估计周围的一个小范围时,所提出的深度估计是非常有效的;在我们的例子中,范围对应于当前深度估计的标准差的两倍。图 6 展示了需要多少运动来显着减少深度的不确定性。所提出的方法在两个视图三角剖分点的标准方法上的主要优点是我们观察到的异常值要少得多,因为每个过滤器经历许多测量直到收敛。此外,显式建模错误的测量,这允许深度即使在高度相似的环境中也能收敛。在[29]中,我们演示了如何将相同的方法用于密集映射。
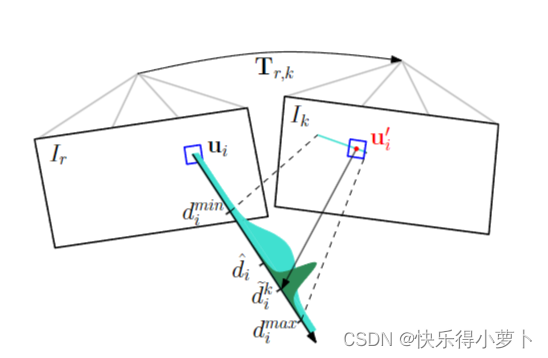
图5:参考帧r中特征i的概率深度估计ˆdi。真实深度的点投影到两幅图像中的相似图像区域(蓝色方块)。因此,深度估计使用三角深度 d k i d_{k_i} dki进行更新,该深度 d k i d_{k_i} dki 从与参考补丁相关性最高的点 u i u_i ui 计算。相关性最高的点总是位于新图像中的极线上。
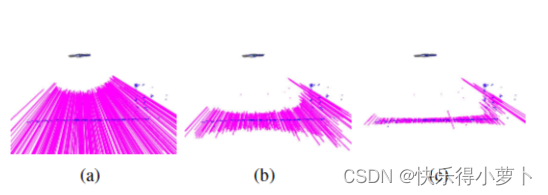
图6:对于深度滤波器(如紧急线所示)的不确定性收敛,MAV(从顶部的侧面看)需要更少的运动。
实施细节
该算法被引导得到前两个关键帧和初始地图的姿态。与[16]一样,我们假设局部平面场景并估计单应性。初始地图是从前两个视图三角化的。为了处理大的运动,我们在粗到细的方案中应用稀疏图像对齐算法。对图像进行半采样以创建五个级别的图像金字塔。然后,在最粗的水平上优化强度残差,直到收敛。随后,优化在下一个更精细的级别进行初始化。为了节省处理时间,我们在第三层收敛后停止,在这个阶段,估计足够准确来初始化特征对齐。该算法由于效率原因,地图中固定数量的关键帧,这些关键帧被用作特征对齐和结构细化的参考。如果新帧相对于所有关键帧的欧几里得距离超过平均场景深度的 12%,则选择关键帧。当在地图中插入一个新的关键帧时,去除距离相机当前位置最远的关键帧。
在映射线程中,我们将图像划分为固定大小的单元格(例如,30 × 30 像素)。一个新的深度过滤器在 FAST 角 [30] 进行初始化,该角 [30] 中具有最高的 Shi-Tomasi 分数,除非已经存在 2D 到 3D 对应关系。这导致图像中均匀分布的特征。相同的网格也用于在特征对齐之前重新投影地图。请注意,我们在图像金字塔的每一层提取 FAST 角,以找到与尺度无关的最佳角。
总结
在本文中,我们提出了半直接 VO 管道“SVO”,它比当前最先进的管道精确且更快。速度的增益是由于运动估计不需要特征提取和匹配。相反,使用了直接的方法,该方法直接基于图像强度。该算法对于机载MAVs的状态估计特别有用,因为它在当前嵌入式计算机上以每秒50帧的速度运行。高帧率运动估计,结合异常值抵抗概率映射方法,在很少、重复和高频纹理的场景中提供了更高的鲁棒性。