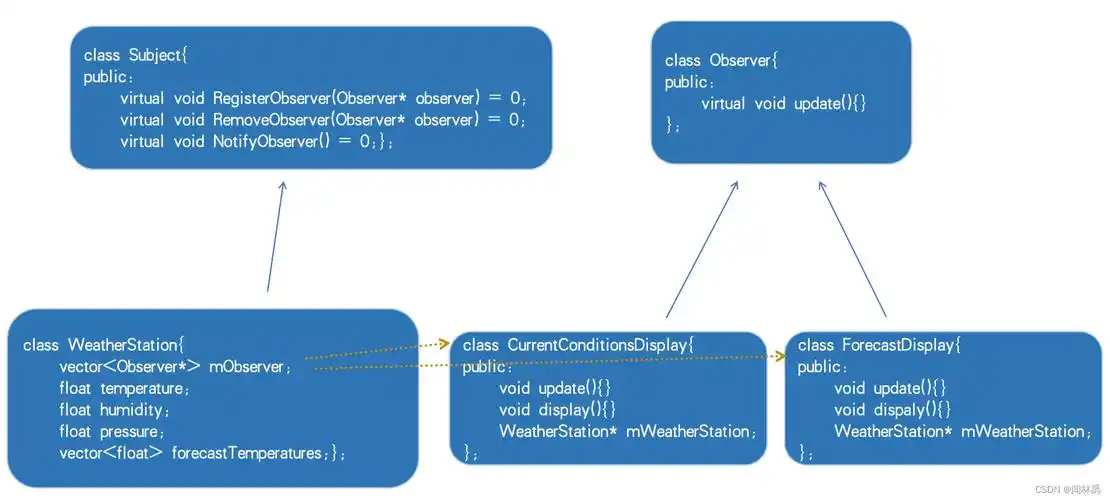
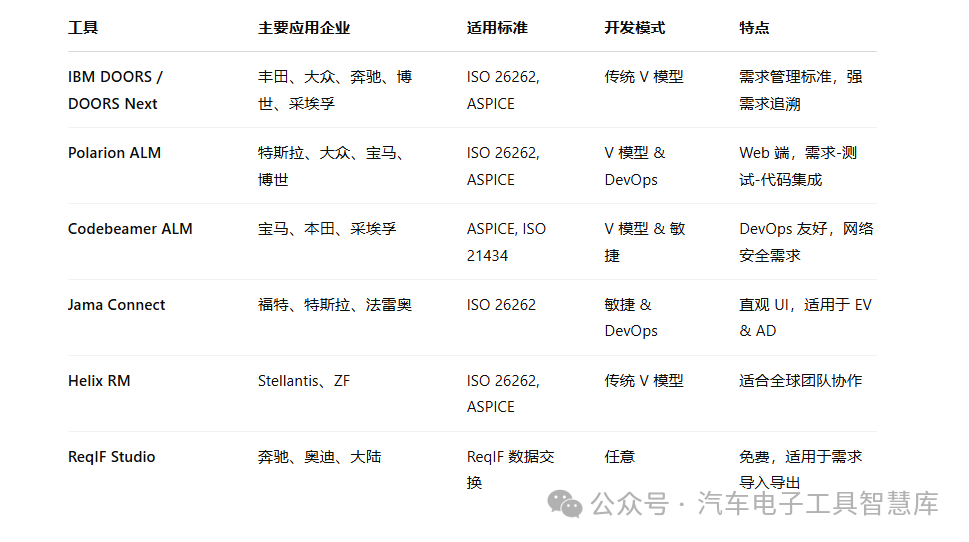
案例
Spring Boot 提供了 spring-data-elasticsearch 模块,可以方便地集成 Elasticsearch。 下面我们将详细讲解如何在 Spring Boot 中使用 Elasticsearch 8,并提供示例代码。
1. 添加依赖:
首先,需要在 pom.xml 文件中添加 spring-data-elasticsearch 的依赖。 注意,你需要选择与你的 Spring Boot 版本和 Elasticsearch 版本兼容的 spring-data-elasticsearch 版本
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency><!-- 其他依赖 -->
</dependencies>
2. 配置 Elasticsearch:
在 application.properties 或 application.yml 文件中配置 Elasticsearch 的连接信息。
spring.elasticsearch.uris=http://localhost:9200
# 如果 Elasticsearch 开启了安全认证,需要配置用户名和密码
#spring.elasticsearch.username=elastic
#spring.elasticsearch.password=your_password
3. 创建实体类:
创建一个实体类,用于映射 Elasticsearch 中的文档结构。 使用 @Document 注解指定索引名称,使用 @Id 注解指定文档 ID 字段。
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "products") // 指定索引名称
public class Product {
@Id // 指定文档 ID 字段
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Double, name = "price")
private Double price;
// 必须要有默认构造函数
public Product() {}
public Product(String id, String name, Double price) {
this.id = id;
this.name = name;
this.price = price;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
}
4. 创建 Repository 接口:
创建一个 Repository 接口,用于操作 Elasticsearch 中的文档。 继承 ElasticsearchRepository 接口,并指定实体类和 ID 的类型。
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, String> {
// 可以自定义查询方法,例如根据名称查询商品
// Spring Data Elasticsearch 会根据方法名自动生成查询语句
Iterable<Product> findByName(String name);
}
5. 创建 Service 类:
创建一个 Service 类,用于调用 Repository 接口,实现业务逻辑。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
// 创建索引(可选,通常 Elasticsearch 会自动创建)
public void createIndex() {
// 注意: Spring Data Elasticsearch 提供了自动索引管理的机制,通常不需要手动创建索引
// 如果需要自定义索引设置,可以使用 ElasticsearchClient 手动创建
// 例如设置 Settings 和 Mappings。
}
// 添加商品
public Product addProduct(Product product) {
return productRepository.save(product);
}
// 根据ID查找商品
public Product findProductById(String id) {
return productRepository.findById(id).orElse(null);
}
// 根据名称查找商品
public Iterable<Product> findProductsByName(String name) {
return productRepository.findByName(name);
}
// 更新商品
public Product updateProduct(Product product) {
return productRepository.save(product); // save 方法在 ID 存在时更新文档
}
// 删除商品
public void deleteProductById(String id) {
productRepository.deleteById(id);
}
// 列出所有商品
public Iterable<Product> getAllProducts() {
return productRepository.findAll();
}
}
6. 创建 Controller 类:
创建一个 Controller 类,提供 RESTful API 接口。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/products")
public class ProductController {
@Autowired
private ProductService productService;
@PostMapping
public Product addProduct(@RequestBody Product product) {
return productService.addProduct(product);
}
@GetMapping("/{id}")
public Product findProductById(@PathVariable String id) {
return productService.findProductById(id);
}
@GetMapping("/name/{name}")
public Iterable<Product> findProductsByName(@PathVariable String name) {
return productService.findProductsByName(name);
}
@PutMapping
public Product updateProduct(@RequestBody Product product) {
return productService.updateProduct(product);
}
@DeleteMapping("/{id}")
public void deleteProductById(@PathVariable String id) {
productService.deleteProductById(id);
}
@GetMapping
public Iterable<Product> getAllProducts() {
return productService.getAllProducts();
}
}
7. 完整示例与注意事项:
-
自动索引管理:
spring-data-elasticsearch提供了自动索引管理的机制。 当你的应用程序启动时,它会自动检查 Elasticsearch 中是否存在与你的实体类对应的索引。 如果不存在,它会自动创建索引,并根据实体类的注解设置 mappings。 如果需要更细粒度的控制,你可以禁用自动索引管理,并使用ElasticsearchClient手动创建索引。 -
ElasticsearchClient 的使用 (高级):
spring-data-elasticsearch默认提供了ElasticsearchRestTemplate,可以方便地执行 Elasticsearch 操作。 如果你需要更高级的功能,例如手动创建索引、执行复杂的查询等,可以使用ElasticsearchClient。
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.indices.CreateIndexRequest;
import co.elastic.clients.elasticsearch.indices.CreateIndexResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.Map;
@Service
public class ElasticsearchIndexService {
@Autowired
private ElasticsearchOperations elasticsearchOperations;
public void createIndex(String indexName, Map<String, Object> mappings) throws IOException {
ElasticsearchClient client = elasticsearchOperations.getClient();
CreateIndexRequest request = new CreateIndexRequest.Builder()
.index(indexName)
.mappings(m -> m.properties(mappings)) // 这里 mappings 是一个 Map<String,Object>
.build();
CreateIndexResponse response = client.indices().create(request);
if (response.acknowledged()) {
System.out.println("Index '" + indexName + "' created successfully.");
} else {
System.out.println("Failed to create index '" + indexName + "'.");
}
}
}
企业中使用
ElasticsearchClient是 Elasticsearch Java 客户端库中的核心组件,用于与 Elasticsearch 集群进行交互。它提供了一系列方法来执行各种操作,如索引文档、搜索数据、更新文档、删除文档等。
删
//根据查询条件删除
@Override
public DeleteByQueryResponse delete(@NonNull Class<?> model, @NonNull Query query) {
ModelContext context = ModelContext.of(model);
DeleteByQueryRequest request = new DeleteByQueryRequest.Builder().index(context.getIndex()).query(query)
.conflicts(Conflicts.Proceed).build();
try {
return this.client.deleteByQuery(request);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
Query query = QueryBuilders.term(t -> t.field("resumeId").value(resume.getId()));
DeleteByQueryResponse response = this.elasticsearchHandler.delete(Vitae.class, query);
//使用
DeleteRequest request = new DeleteRequest.Builder().index(context.getIndex()).id(id).build();改
前期学习
修改文档:
全量修改:PUT/索引库名/_doc/文档id{json文档}增量修改:POST/索引库名/_update/文档id{"doc":{字段}}
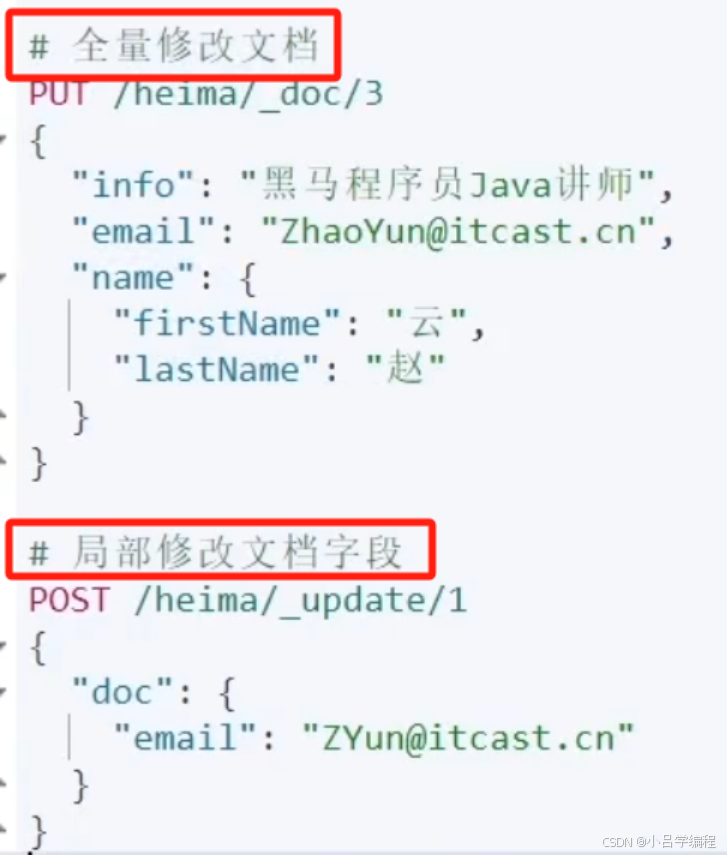
@Override
public UpdateByQueryResponse update(@NonNull Class<?> model, @NonNull Query query,
@NonNull Map<String, ?> parameters) {
ModelContext context = ModelContext.of(model);
StringBuilder source = new StringBuilder();
Map<String, JsonData> params = Maps.newHashMapWithExpectedSize(parameters.size());
parameters.forEach((key, value) -> {
if (source.length() > 0) {
source.append(";");
}
if (value == null) {
source.append("ctx._source.").append(key).append("=null");
} else {
source.append("ctx._source.").append(key).append("=params.").append(key);
params.put(key, JsonData.of(value));
}
});
Script script = new Script.Builder().lang(ScriptLanguage.Painless).source(source.toString())
.params(params).build();
UpdateByQueryRequest request = new UpdateByQueryRequest.Builder().index(context.getIndex()).script(script)
.query(query).conflicts(Conflicts.Proceed).build();
try {
return this.client.updateByQuery(request);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//使用
UpdateByQueryResponse response = this.elasticsearchHandler.update(Vitae.class, query, parameters);
@Override
public UpdateByQueryResponse update(@NonNull Class<?> model, @NonNull Query query, @NonNull String field,
Object value) {
ModelContext context = ModelContext.of(model);
String source = "ctx._source." + field + (value == null ? "=null" : ("=params." + field));
Map<String, JsonData> params = value == null ? Collections.emptyMap() :
ImmutableMap.of(field, JsonData.of(value));
Script script = new Script.Builder().lang(ScriptLanguage.Painless).source(source).params(params).build();
UpdateByQueryRequest request = new UpdateByQueryRequest.Builder().index(context.getIndex()).script(script)
.query(query).conflicts(Conflicts.Proceed).build();
try {
return this.client.updateByQuery(request);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//使用
this.elasticsearchHandler.update(Vitae.class, query, "topping", document);
@Override
public <T> UpdateResponse<T> update(@NonNull Class<T> model, @NonNull String id, @NonNull Object document,
Long primary, Long sequence) {
ModelContext context = ModelContext.of(model);
UpdateRequest<T, ?> request = new UpdateRequest.Builder<T, Object>().index(context.getIndex()).id(id)
.doc(document).ifPrimaryTerm(primary).ifSeqNo(sequence).retryOnConflict(3).build();
try {
return this.client.update(request, model);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//使用
this.elasticsearchHandler.update(Job.class, id, ImmutableMap.of("recruiting", recruiting));
查
前期学习
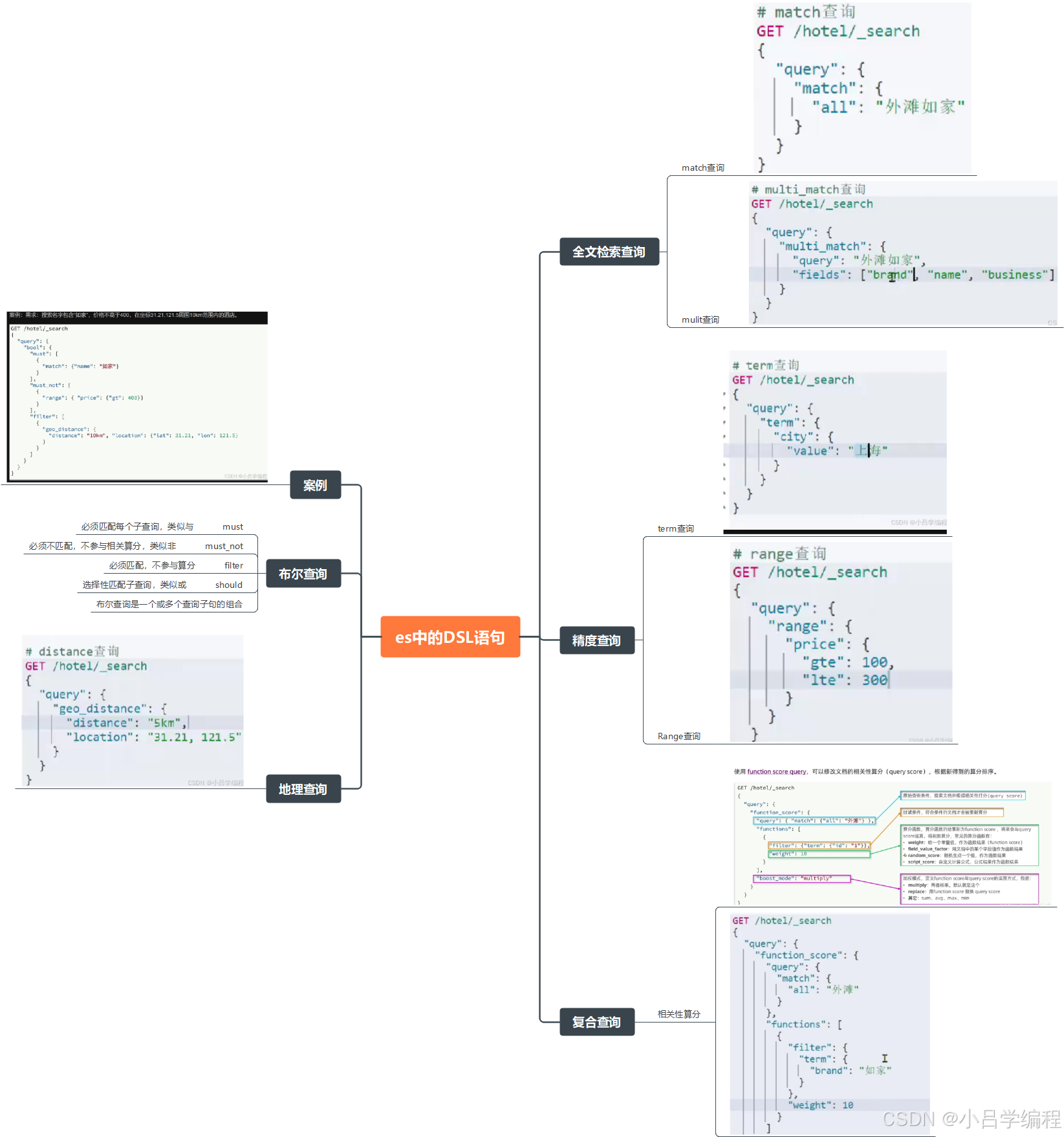
springboot操作es的DSL
QueryBuilders 常用方法
全文查询
-
matchQuery(String field, Object value): 全文匹配 -
multiMatchQuery(Object value, String... fields): 多字段匹配 -
matchPhraseQuery(String field, Object value): 短语匹配 -
matchPhrasePrefixQuery(String field, Object value): 短语前缀匹配
词项查询
-
termQuery(String field, Object value): 精确词项匹配 -
termsQuery(String field, String... values): 多词项精确匹配 -
rangeQuery(String field): 范围查询(如数值、日期) -
existsQuery(String field): 检查字段是否存在 -
prefixQuery(String field, String value): 前缀匹配 -
wildcardQuery(String field, String value): 通配符匹配(如*或?) -
regexpQuery(String field, String value): 正则表达式匹配 -
fuzzyQuery(String field, String value): 模糊匹配(容错匹配)
复合查询
-
boolQuery(): 布尔查询(组合多个子查询) -
disMaxQuery(): 取多个查询中的最佳匹配 -
constantScoreQuery(QueryBuilder query): 固定评分查询 -
nestedQuery(String path, QueryBuilder query, ScoreMode scoreMode): 嵌套对象查询 -
functionScoreQuery(QueryBuilder query, FunctionScoreBuilder... functions): 自定义评分函数
地理位置查询
-
geoDistanceQuery(String field): 地理距离范围查询 -
geoBoundingBoxQuery(String field): 地理边界框查询
其他查询
-
scriptQuery(Script script): 脚本查询 -
idsQuery().addIds(String... ids): 根据ID查询
综合示例一
假设有一个products索引,包含以下字段:
-
name(文本) -
price(整数) -
status(关键字) -
tags(关键字数组) -
location(地理坐标) -
metadata(嵌套类型,包含key和value)
import org.elasticsearch.index.query.*;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.script.Script;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.action.search.SearchRequest;
public class QueryExample {
public static void main(String[] args) {
// 1. 布尔查询(组合多个子查询)
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2. 全文匹配:搜索name中包含"phone"
boolQuery.must(QueryBuilders.matchQuery("name", "phone"));
// 3. 多字段匹配:在name和description中搜索"smart"
boolQuery.must(QueryBuilders.multiMatchQuery("smart", "name", "description"));
// 4. 短语匹配:description中精确匹配"high quality"
boolQuery.must(QueryBuilders.matchPhraseQuery("description", "high quality"));
// 5. 精确词项匹配:status为"active"
boolQuery.must(QueryBuilders.termQuery("status", "active"));
// 6. 多词项匹配:tags包含"electronics"或"gadgets"
boolQuery.must(QueryBuilders.termsQuery("tags", "electronics", "gadgets"));
// 7. 范围查询:price在100到500之间
boolQuery.must(QueryBuilders.rangeQuery("price").gte(100).lte(500));
// 8. 存在性检查:stock字段必须存在
boolQuery.filter(QueryBuilders.existsQuery("stock"));
// 9. 前缀匹配:description以"latest"开头
boolQuery.should(QueryBuilders.prefixQuery("description", "latest"));
// 10. 通配符匹配:tags字段匹配"tec*"(如"tech")
boolQuery.should(QueryBuilders.wildcardQuery("tags", "tec*"));
// 11. 正则表达式匹配:name匹配正则"pho.*e"
boolQuery.should(QueryBuilders.regexpQuery("name", "pho.*e"));
// 12. 模糊查询:name容错匹配"fone"
boolQuery.should(QueryBuilders.fuzzyQuery("name", "fone"));
// 13. 地理距离查询:location距离(37.7749, -122.4194)10公里内
boolQuery.filter(QueryBuilders.geoDistanceQuery("location")
.point(37.7749, -122.4194)
.distance("10km"));
// 14. 嵌套查询:metadata.key为"color"且metadata.value为"black"
boolQuery.must(QueryBuilders.nestedQuery("metadata",
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("metadata.key", "color"))
.must(QueryBuilders.matchQuery("metadata.value", "black")),
ScoreMode.Total));
// 15. 脚本查询:price大于200
Script script = new Script("doc['price'].value > 200");
boolQuery.filter(QueryBuilders.scriptQuery(script));
// 构建搜索请求
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(boolQuery);
SearchRequest searchRequest = new SearchRequest("products");
searchRequest.source(sourceBuilder);
// 执行搜索(需Elasticsearch客户端)
// SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
}
}综合案例二
@Override
public List<Job> listSearchJobs(@NonNull TextSearch search) {
List<Query> pairs = Lists.newLinkedList();
if (search.getRegion() != null) {
pairs.add(this.jobRegionQuery("regionId", search.getRegion()));
}
if (StringUtils.notEmpty(search.getKeyword())) {
pairs.add(QueryBuilders.match(b -> b.field("description").query(search.getKeyword())));
}
if (search.getType() != null) {
// 指定职位类型
pairs.add(QueryBuilders.term(t -> t.field("type").value(search.getType().name())));
}
if (ObjectUtils.notEmpty(search.getDriveLicenses())) {
List<FieldValue> values = search.getDriveLicenses().stream()
.map(driveLicense -> FieldValue.of(driveLicense.name())).collect(Collectors.toList());
pairs.add(QueryBuilders.terms(t -> t.field("driveLicense").terms(v -> v.value(values))));
}
if (ObjectUtils.isEmpty(pairs)) {
return Collections.emptyList();
}
pairs.add(QueryBuilders.term(t -> t.field("status").value(ContentStatus.ONLINE.name())));
Query query = QueryBuilders.bool(b -> b.must(pairs));
SearchResponse<Job> response = this.elasticsearchHandler.search(Job.class, query,
b -> b.sort(s -> s.field(f -> f.field("refreshTime").order(SortOrder.Desc)))
.sort(s -> s.field(f -> f.field("_score").order(SortOrder.Desc)))
.from(search.getPaging().getIndex()).size(search.getPaging().getSize()));
return ElasticsearchUtils.sources(response);
}根据id查询:
@Override
public <T> MgetResponse<T> get(@NonNull Class<T> model, @NonNull List<String> ids) {
ModelContext context = ModelContext.of(model);
MgetRequest request = new MgetRequest.Builder().index(context.getIndex()).ids(ids).build();
try {
return this.client.mget(request, model);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//使用
MgetResponse<Vitae> response = this.elasticsearchHandler.get(Vitae.class, vitaeIds);
Set<Long> exists = response.docs().stream().map(doc -> doc.result().source()).filter(Objects::nonNull)
.map(Vitae::getId).collect(Collectors.toSet());滚动:
@Override
public <T> ScrollResponse<T> scroll(@NonNull Class<T> model, @NonNull String id, @NonNull String time) {
ScrollRequest request = new ScrollRequest.Builder().scrollId(id).scroll(s -> s.time(time)).build();
try {
return this.client.scroll(request, model);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//使用
scrollResponse = elasticsearchHandler.scroll(Job.class, scrollId, keyLive + "m");
ElasticsearchUtils.sources(scrollResponse)



![【吾爱出品】[Windows] 鼠标或键盘可自定义可同时多按键连点工具](https://i-blog.csdnimg.cn/direct/c0a3ae6ae0204cc68050be251b9c6120.png)