Coggle 30 Days of ML(23年7月)任务四:线性模型训练与预测
任务四:使用TFIDF特征和线性模型完成训练和预测
- 说明:在这个任务中,你需要使用TFIDF特征和线性模型(如逻辑回归)完成训练和预测,通过机器学习算法来区分人类编写的文本和机器生成的文本。
- 实践步骤:
- 准备TFIDF特征矩阵和相应的标签。
- 划分训练集和测试集。
- 使用Sklearn中的线性模型(如逻辑回归)进行训练,并使用训练好的模型对测试集进行预测。
- 评估模型的性能,如准确率、精确率、召回率等指标。
TFIDF提取特征
首先使用任务三中的方法先提取特征
tfidf = TfidfVectorizer(token_pattern=r'(?u)\b\w\w+\b', max_features=4000, ngram_range=(1, 2))
train_tfidf = tfidf.fit_transform(train_data['content'])
test_tfidf = tfidf.fit_transform(test_data['content'])
这样我们就一句得到了TFIDF的特征矩阵,接下来我们就可以进行下一步的训练和测试了
训练Logistic Regression
由于本身一句划分了训练集和测试集,所以暂时我这里就重新划分一个验证集了,就在训练集上训练和评估,最后在测试集上预测
这里选择了Sklearn中的线性模型进行训练,模型很简单,很快就能得到不错的结果
m = LogisticRegression()
m.fit(
train_tfidf,
train_data['label']
)
训练完以后,我们就得到了一个不错的线性模型,接下来我们可以进行评估模型的性能
评估模型
首先我们可以计算一下准确率,从结果上来看,得到的结果非常不错,大概有99%+的准确率
from sklearn.metrics import accuracy_score
predictions = m.predict(train_tfidf)
accuracy = accuracy_score(train_data['label'], predictions)
print("Accuracy:", accuracy)
Accuracy: 0.9922142857142857
我们还计算了精确率和召回率的指标,各方面指标都比较高,都在95%以上
from sklearn.metrics import precision_score, recall_score
precision = precision_score(train_data['label'], predictions)
recall = recall_score(train_data['label'], predictions)
print("Precision:", precision)
print("Recall:", recall)
Precision: 0.9995138551288284
Recall: 0.9500924214417745
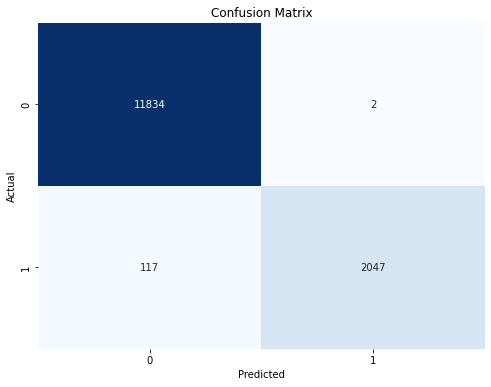
我还对混淆矩阵进行可视化,可以看到有一部分数据被误判了
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 计算混淆矩阵
cm = confusion_matrix(train_data['label'], predictions)
# 可视化混淆矩阵
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
模型预测及提交
最后利用模型对测试集进行预测,得到结果文件
import pandas as pd
submit = pd.read_csv('ChatGPT/sample_submit.csv')
submit = submit.sort_values(by='name')
submit['label'] = m.predict(test_tfidf).astype(int)
submit.to_csv('ChatGPT/lr.csv', index=None)
经过提交以后,最后的分数为0.8837,从结果上来看,还是存在一些过拟合的,所以后续可以选择更强大的模型或者一些防止过拟合的方法来提高分数。