目录
Elasticsearch集群_概念
Elasticsearch集群_搭建集群
Elasticsearch集群_概念
在单台ES服务器上,随着一个索引内数据的增多,会产生存储、效率、安全等问题。
1、假设项目中有一个500G大小的索引,但我们只有几台200G硬盘 的服务器,此时是不可能将索引放入其中某一台服务器中的。
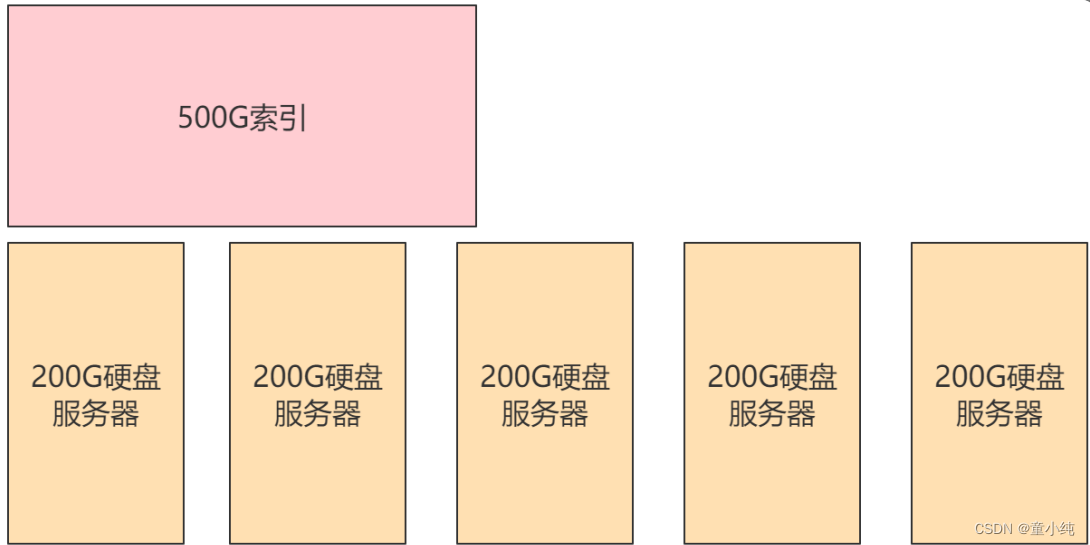
2、此时我们需要将索引拆分成多份,分别放入不同的服务器中,此时这几台服务器维护了同一个索引,我们称这几台服务器为一个集群,其中的每一台服务器为一个节点,每一台服务器中的数据 称为一个分片。
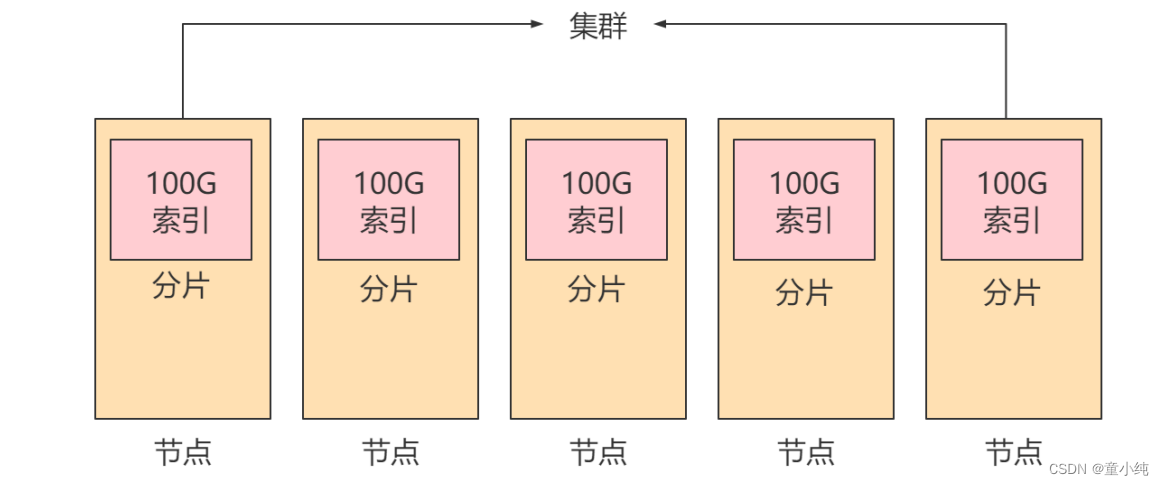
3、此时如果某个节点故障,则会造成集群崩溃,所以每个节点的分 片往往还会创建副本,存放在其他节点中,此时一个节点的崩溃 就不会影响整个集群的正常运行。
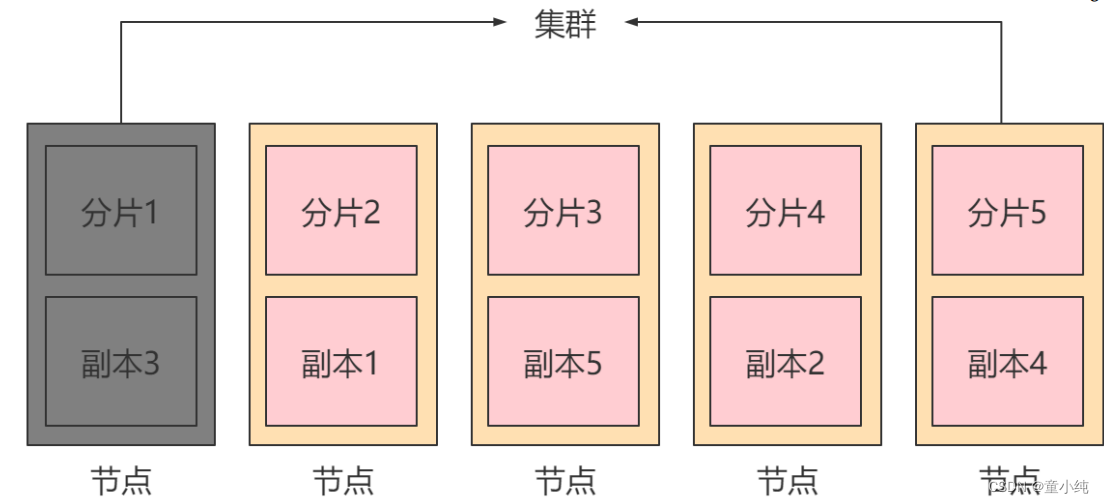
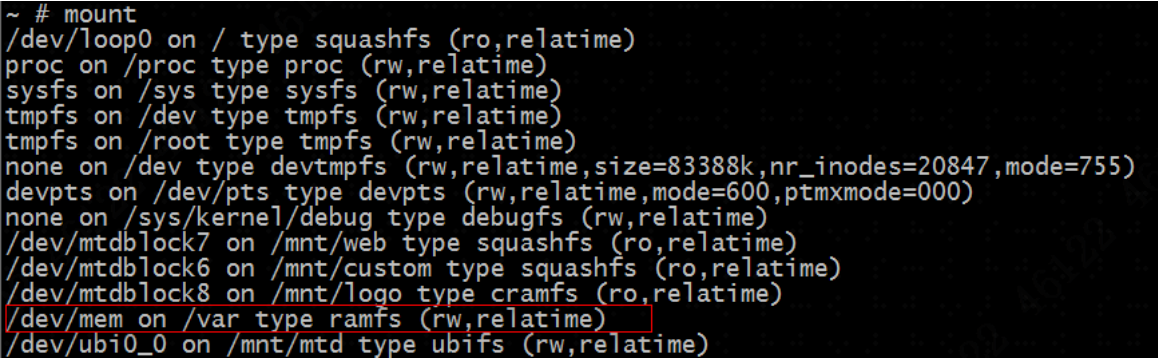
节点(node):一个节点是集群中的一台服务器,是集群的一部分。它存储数据,参与集群的索引和搜索功能。集群中有一个为主 节点,主节点通过ES内部选举产生。
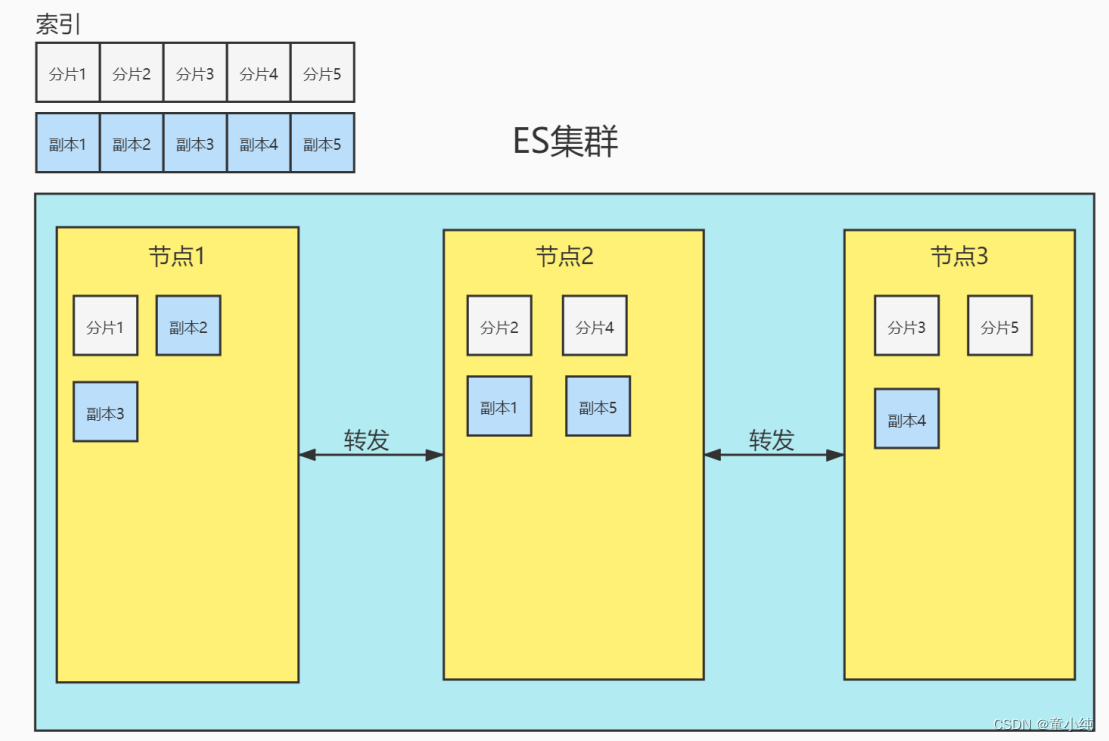
集群(cluster):一组节点组织在一起称为一个集群,它们共同持 有整个的数据,并一起提供索引和搜索功能。
分片(shards):ES可以把完整的索引分成多个分片,分别存储在 不同的节点上。
副本(replicas):ES可以为每个分片创建副本,提高查询效率, 保证在分片数据丢失后的恢复。
注: 分片的数量只能在索引创建时指定,索引创建后不能再更改 分片数量,但可以改变副本的数量。
为保证节点发生故障后集群的正常运行,ES不会将某个分片 和它的副本存在同一台节点上。
实时学习反馈
1. 在Elasticsearch中,可以保证数据丢失后的恢复
A 节点
B 集群
C 分片
D 副本
2. 一组节点组织在一起称为一个
A 索引
B 集群
C 分片
D 副本
Elasticsearch集群_搭建集群

安装第一个ES节点
1、安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-7.17.0 myes1
#移动文件夹:
mv myes1 /usr/local/
#安装ik分词器
unzip /elasticsearch-analysis-ik-7.17.0.zip -d
/usr/local/myes1/plugins/analysis-ik
#安装拼音分词器
unzip /elasticsearch-analysis-pinyin-7.17.0.zip -d
/usr/local/myes1/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes12、修改配置文件
#打开节点一配置文件:
vim /usr/local/myes1/config/elasticsearch.yml
配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node1
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9200
#集群间通信端口号
transport.tcp.port: 9300
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
3 、启动
#切换为es用户:
su es
#后台启动第一个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes1/bin/elasticsearch -d安装第二个ES节点
1、安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-7.17.0 myes2
#移动文件夹:
mv myes2 /usr/local/
#安装ik分词器
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/myes2/plugins/analysis-ik
#安装拼音分词器
unzip /elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/myes2/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes22、修改配置文件
#打开节点二配置文件:
vim /usr/local/myes2/config/elasticsearch.yml配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node2
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9201
#集群间通信端口号
transport.tcp.port: 9301
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
3、启动
#切换为es用户:
su es
#后台启动第二个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes2/bin/elasticsearch -d安装第三个ES节点
1、安装
#解压:
tar -zxvf elasticsearch-7.17.0-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-7.17.0 myes3
#移动文件夹:
mv myes3 /usr/local/
#安装ik分词器
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/myes3/plugins/analysis-ik
#安装拼音分词器
unzip /elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/myes3/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes3
2、修改配置文件
#打开节点一配置文件:
vim /usr/local/myes3/config/elasticsearch.yml配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node3
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9202
#集群间通信端口号
transport.tcp.port: 9302
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes:["node1","node2","node3"]
3、启动
#切换为es用户:
su es
#后台启动第三个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes3/bin/elasticsearch -d测试集群
访问 http://虚拟机IP:9200/_cat/nodes 查看是否集群搭建成功。
kibana连接es集群
1、在kibana中访问集群
# 打开kibana配置文件
vim /usr/local/kibana-7.17.0-linux-x86_64/config/kibana.yml
添加如下配置
# 该集群的所有节点
elasticsearch.hosts: ["http://虚拟机IP:9200","http://虚拟机IP:9201","http://虚拟机IP:9202"]
2、启动kibana
#切换为es用户:
su es
#启动kibana:
/usr/local/kibana-7.17.0-linux-x86_64/bin/kibana3、访问kibana: http://虚拟机IP:5601
实时学习反馈
1. 在Elasticsearch中,查看是否集群搭建成功的请求路径为
A /_cat/nodes
B /nodes
C /_cat/node
D node
复习:
Elasticsearch介绍_全文检索

Elasticsearch是一个全文检索服务器
全文检索是一种非结构化数据的搜索方式
- 结构化数据:指具有固定格式固定长度的数据,如数据库中的字段。
- 非结构化数据:指格式和长度不固定的数据,如电商网站的商品详情。


结构化数据一般存入数据库,使用sql语句即可快速查询。但由于非结构化数据的数据量大且格式不固定,我们需要采用全文检索的方式进行搜索。全文检索通过建立倒排索引加快搜索效率。
实时学习反馈
1. 什么是非结构化数据?
A 格式和长度固定的数据
B 格式和长度不固定的数据
C 格式固定的数据
D 长度固定的数据
2. 全文检索是
A 一种非结构化数据的搜索方式
B 一种结构化数据的搜索方式
C 一种非结构化数据的保存方式
D 一种结构化数据的保存方式
Elasticsearch介绍_倒排索引

索引
将数据中的一部分信息提取出来,重新组织成一定的数据结构,我 们可以根据该结构进行快速搜索,这样的结构称之为索引。 索引即目录,例如字典会将字的拼音提取出来做成目录,通过目录 即可快速找到字的位置。 索引分为正排索引和倒排索引。
正排索引(正向索引)
将文档id建立为索引,通过id快速可以快速查找数据。如数据库中 的主键就会创建正排索引。

倒排索引(反向索引)
非结构化数据中我们往往会根据关键词查询数据。此时我们将数据中的关键词建立为索引,指向文档数据,这样的索引称为倒排索引。

创建倒排索引流程:

实时学习反馈
1. 索引分为
A 正排索引和无序索引
B 正排索引和倒排索引
C 无序索引和有序索引
D 有序索引和倒排索引
2. 将数据中的关键词建立为索引,指向文档数据,这样的索引称为
A 无序索引
B 有序索引
C 正排索引
D 倒排索引
Elasticsearch介绍_Elasticsearch的出现

多年前,一个刚结婚的名叫Shay的失业开发者,跟着妻子去了伦敦,他的妻子在那里学习厨师。Shay使用全文检索工具—— lucene,给他的妻子做一个食谱搜索引擎。
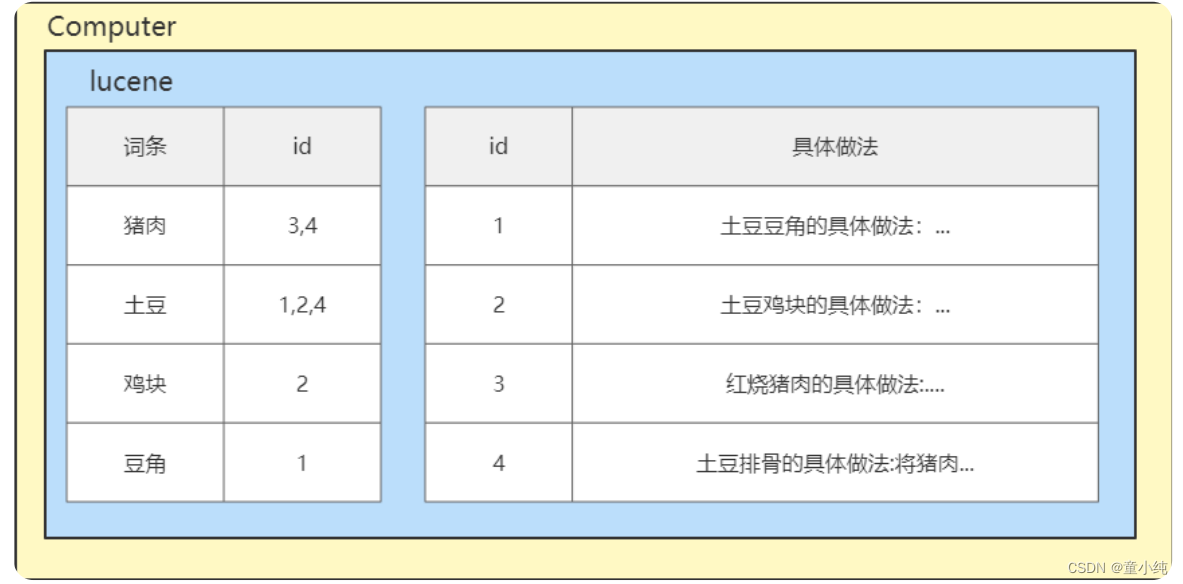
但Lucene的操作非常复杂,且Lucene是一个单机软件,不支持联网访问。因此 Shay基于Lucene开发了开源项目 Elasticsearch。 Elasticsearch本质是一个java语言开发的web项目,我们可以通过 RESTful风格的接口访问该项目内部的Lucene,从而让全文搜索变得简单。
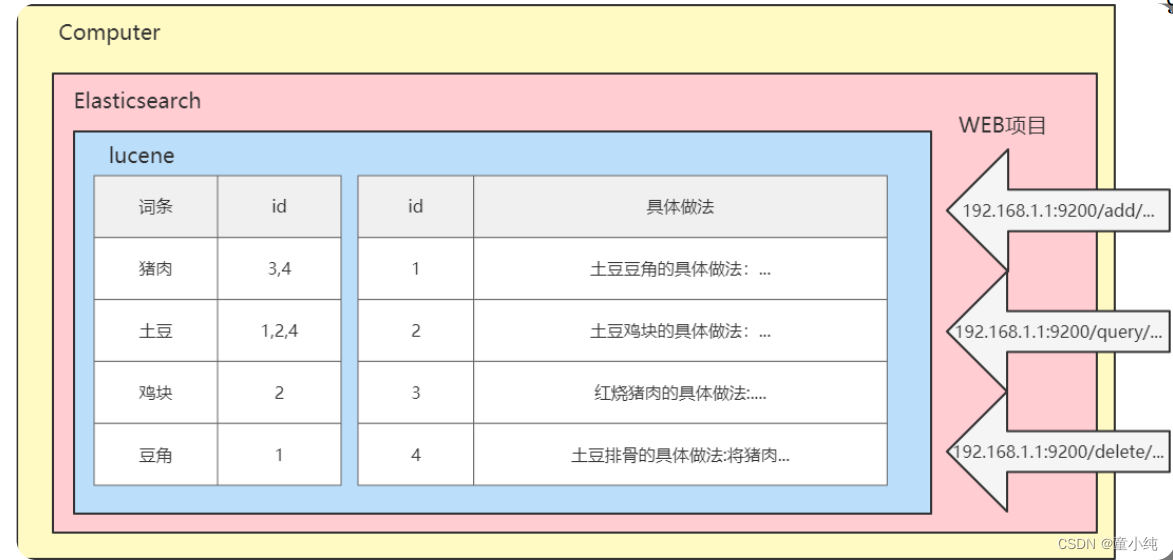
从此以后,Elasticsearch成为了Github上最活跃的项目之一, Elastic公司围绕Elasticsearch提供商业服务,并开发新的特性。 Elasticsearch将永远开源并对所有人可用。
实时学习反馈
1. Elasticsearch本质是一个
A python语言开发的web项目
B javascript语言开发的web项目
C java语言开发的web项目
D java语言开发的普通项目