Python数据处理-Pandas笔记
📝 基本概念
Pandas是一个强大的Python数据处理库,它提供了高效的数据结构和数据分析工具,使数据处理变得简单而快速。本篇笔记将介绍Pandas中最常用的数据结构——Series和DataFrame,以及数据处理的各种操作和技巧。
📝 Series
(一)创建Series
Series是Pandas中的一维数组,类似于带有标签的NumPy数组。创建Series可以通过多种方式进行,以下是几种常用的方法:
✨ 使用列表创建Series
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
print(s)
输出:
0 10
1 20
2 30
3 40
4 50
dtype: int64
✨ 使用NumPy数组创建Series
import pandas as pd
import numpy as np
data = np.array([10, 20, 30, 40, 50])
s = pd.Series(data)
print(s)
输出:
0 10
1 20
2 30
3 40
4 50
dtype: int32
✨ 使用字典创建Series
import pandas as pd
data = {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}
s = pd.Series(data)
print(s)
输出:
a 10
b 20
c 30
d 40
e 50
dtype: int64
(二)Series的简单操作
Series对象提供了许多方便的方法和属性来操作数据。以下是一些常用的操作:
🕛️访问数据
通过索引访问数据
import pandas as pd
data = [10, 20, 30, 40, 50]
s1 = pd.Series(data)
print(s1)
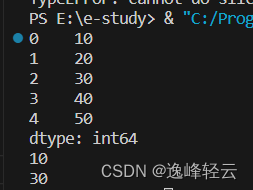
# 通过索引访问数据
print(s1[0]) # 输出 10
print(s1[2]) # 输出 30
运行结果:
通过标签访问数据
import pandas as pd
data = [10, 20, 30, 40, 50]
s2 = pd.Series(data,index = ['a','b','c','d','e'])
print(s2)
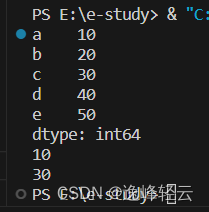
# 通过索引访问数据
print(s2['a']) # 输出 10
print(s2['c']) # 输出 30
运行结果:
🕛️ 切片操作
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
# 切片操作
print(s[1:4]) # 输出 [20, 30, 40]
运行结果

import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data,index = ['a','b','c','d','e'])# 修改
# 切片操作
print(s['b':'d']) # 输出 [20, 30, 40]
运行结果

🕛️ 矢量化操作
import pandas as pd
data = [10, 20, 30, 40, 50]
s = pd.Series(data)
# 矢量化操作
print(s * 2)
输出:
0 20
1 40
2 60
3 80
4 100
dtype: int64
📝DataFrame
🏘️ 创建方式
DataFrame是Pandas中的二维数据结构,可以看作是由多个Series组成的表格。创建DataFrame的方法有很多种,下面介绍几种常见的方式:
✨ 使用列表创建DataFrame
import pandas as pd
data = [['Alice', 25], ['Bob', 30], ['Charlie', 35]]
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)
输出:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
✨使用字典创建DataFrame
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
print(df)
输出:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
✨使用NumPy数组创建DataFrame
import pandas as pd
import numpy as np
data = np.array([['Alice', 25], ['Bob', 30], ['Charlie', 35]])
df = pd.DataFrame(data, columns=['Name', 'Age'])
print(df)
输出:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
☑️ 数据选取
数据选取是对DataFrame中的数据进行访问和操作的关键步骤。下面介绍一些常用的数据选取方法。
🛠️ [[]]
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 选取多列数据
print(df[['Name', 'Age']])
输出:
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
🛠️ copy()
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 复制DataFrame
df_copy = df.copy()
🛠️ 列操作
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 添加新列
df['Gender'] = ['Female', 'Male', 'Male']
# 删除列
df = df.drop('Gender', axis=1)
🛠️ 行操作
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 选取行数据
print(df.loc[0]) # 输出第一行数据
print(df.loc[1:2]) # 输出第二行到第三行的数据
🛠️ 行-列
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 选取指定行列的数据
print(df.loc[0, 'Name']) # 输出第一行的Name列数据
print(df.loc[1:2, 'Name']) # 输出第二行到第三行的Name列数据
🛠️ 数据筛选
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 根据条件筛选数据
filtered_df = df[df['Age'] > 30]
print(filtered_df)
🔍 加载数据
在实际的数据处理中,我们常常需要从外部文件中加载数据到DataFrame中进行分析和处理。Pandas提供了多种方法来加载不同格式的数据,下面介绍常用的几种方式。
📉 Txt
import pandas as pd
# 从txt文件加载数据
df = pd.read_csv('data.txt', sep='\t')
print(df)
📉 Csv
import pandas as pd
# 从csv文件加载数据
df = pd.read_csv('data.csv')
print(df)
📉 Excel
import pandas as pd
# 从Excel文件加载数据
df = pd.read_excel('data.xlsx')
print(df)
👨💻 排序与合并
数据排序和合并是数据处理中常用的操作之一。下面介绍几种常见的排序和合并方法。
✨ Series排序
import pandas as pd
data = [10, 5, 8, 3, 12]
s = pd.Series(data)
# Series排序
sorted_s = s.sort_values()
print(sorted_s)
✨ DataFrame排序
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# DataFrame按某一列排序
sorted_df = df.sort_values('Age')
print(sorted_df)
✨ Rank
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 30]}
df = pd.DataFrame(data)
# 计算DataFrame的排名
ranked_df = df.rank()
print(ranked_df)
✨ merge(按列匹配合并)
import pandas as pd
data1 = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
data2 = {'Name': ['Alice', 'David', 'Charlie'], 'Salary': [5000, 6000, 7000]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 按列匹配合并两个DataFrame
merged_df = pd.merge(df1, df2, on='Name')
print(merged_df)
✨ concat(数据的拼接)
import pandas as pd
data1 = {'Name': ['Alice', 'Bob'], 'Age': [25, 30]}
data2 = {'Name': ['Charlie', 'David'], 'Age': [35, 40]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 拼接两个DataFrame
concatenated_df = pd.concat([df1, df2])
print(concatenated_df)
📊 数据汇总
在数据处理过程中,我们经常需要对数据进行汇总和统计。下面介绍几种常用的数据汇总方法。
🚀 特殊值(info, describe)
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# 查看DataFrame的基本信息
print(df.info())
# 查看DataFrame的统计信息
print(df.describe())
🚀 分组统计
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35, 40, 45, 50],
'Salary': [5000, 6000, 7000, 8000, 9000, 10000]}
df = pd.DataFrame(data)
# 按Name列进行分组统计
grouped_df = df.groupby('Name').mean()
print(grouped_df)
⏰ 时间序列
Pandas提供了强大的时间序列处理功能,方便对时间相关的数据进行分析和处理。下面介绍一些时间序列的常用操作。
🕛️ 初始化时间序列
import pandas as pd
# 初始化时间序列
dates = pd.date_range(start='2021-01-01', periods=10, freq='D')
print(dates)
🕛️ 时间索引
import pandas as pd
# 创建带有时间索引的DataFrame
dates = pd.date_range(start='2021-01-01', periods=10, freq='D')
data = {'Value': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]}
df = pd.DataFrame(data, index=dates)
print(df)
🕛️ 重采样
import pandas as pd
# 创建带有时间索引的DataFrame
dates = pd.date_range(start='2021-01-01', periods=10, freq='D')
data = {'Value': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]}
df = pd.DataFrame(data, index=dates)
# 对时间序列进行重采样
resampled_df = df.resample('W').sum()
print(resampled_df)
📚 参考资料
- Pandas官方文档
- Pandas User Guide
⭐️希望本篇文章对你有所帮助。
⭐️如果你有任何问题或疑惑,请随时向提问。
⭐️感谢阅读!





![【线段树】P6492 [COCI2010-2011#6] STEP](https://img-blog.csdnimg.cn/91489698409c4a719676d670f53a8d05.png)