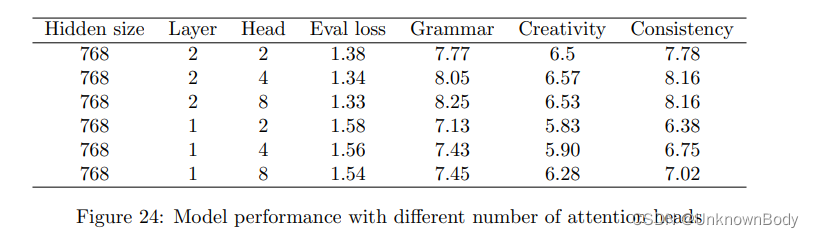
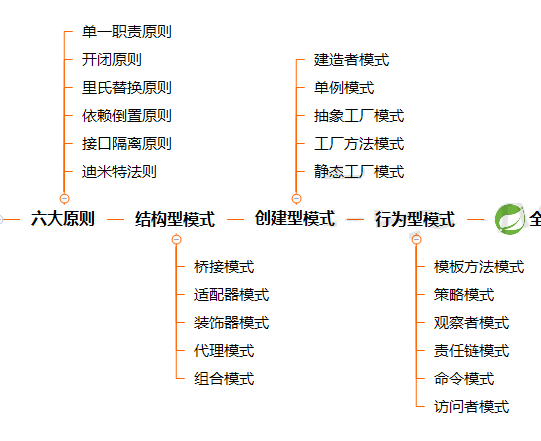
AQE处理SkewedJoin的原理
Spark Adaptive Query Execution , 简称 Spark AQE,总体思想是动态优化和修改 stage 的物理执行计划。利用执行结束的上游 stage 的统计信息(主要是数据量和记录数),来优化下游 stage 的物理执行计划。
Spark AQE 处理数据倾斜的原理如下:
mapTask 完成后,driver 先统计 map satus,维护一个 array,里面是这个 MapTask 发给下游 reducer 的数据大小。
比如 mapTask-1:[100m,100m,1G]。即 reduceTask-1 获取 mapTask-1 的 100m 数据, reduceTask-2 获取 mapTask-1 的 100m 数据,reduceTask-3 获取 mapTask-1 的 1G 数据。在这个 stage 中,还有 mapTask-2:[100m,100m,100m] 、mapTask-3:[100m,100m,100m]
那么最终 reduceTask-1 处理的总数据量为 0.3G,reduceTask-2: 0.3G reduceTask-3: 1.2G 。中位数为 0.3G,reduceTask-3 处理了 1.2G,是中位数的 4 倍,可以判断为 reduceTask-3 倾斜。
对于大任务而言,统计 map satus 会占据大量的 Driver 内存,假设有 M 个 mapTask 和 R 个 reduceTask, 则 map status 的空间复杂度是 O(M * R)。 所以社区版会进行压缩。压缩分为两种一种是 CompressedMapStatus、另一种是 HighlyCompressedMapStatus。
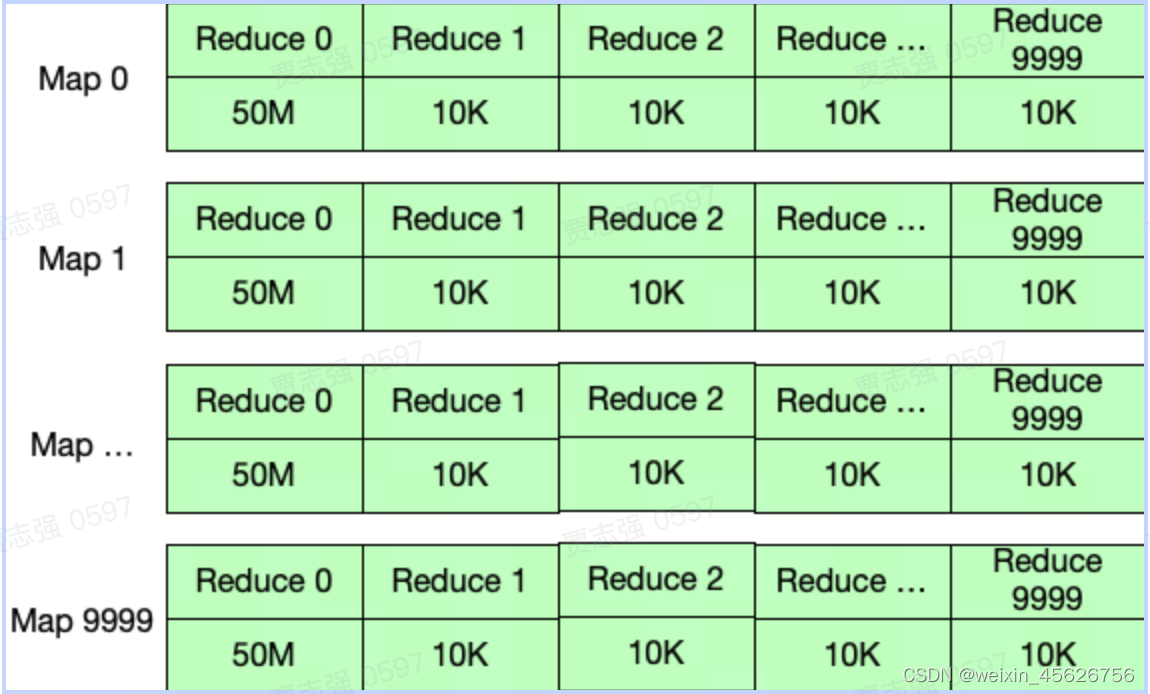
当下游 reduceTask 超过 2000(默认值) 时,使用 HighlyCompressedMapStatus。这种方式很粗暴,压缩时只保留了 MapStatus 中大块的数据大小(比如超过 100m 的为大块。)
比如 mapTask-1:[1m, 20m, 5m…(1999 个,假设都小于 100m), 100m],这时候 HighlyCompressedMapStatus 生效,只保留 100M 块大小,其他 1999 个块用(假设)平均值 10m 代替。
某些情况,会造成下游 reduceTask 统计数据不准,即下图应该都用平均值代替,因为所有数据量都没超过accurateBlockThreshold的值(默认 100M),这样所有 reduceTask 有相同的数据量,但真实情况是 reduceTask-0 处理 500G 数据,reduceTask-1 处理 100M 数据。这样识别不了倾斜。
建议参数:
- spark.shuffle.highlyCompressedMapStatusThreshold(默认 5000)需要大于等于spark.sql.adaptive.maxNumPostShufflePartitions(设置相等即可,默认 2000),否则 AQE SkewedJoin 可能无法生效。
- spark.sql.adaptive.maxNumPostShufflePartitions设置过高(例如超过 2w),会增加 driver cpu 的压力,可能出现 executor 心跳注册超时的可能 ,建议同时提高 driver 的内存和 cpu 个数。
- 倾斜非常严重,被拆分后倾斜仍然很严重,可能是 shuffle 分布统计精度太低,需要降低spark.shuffle.accurateBlockThreshold,默认为 100M,可按需降低(例如改成 4M 或 1M)。
a. 需要注意的是,降低该参数会增加 Driver 内存的压力(统计数据更加精确),为防止出现 Driver OOM 等问题,建议同时提高 driver 的内存和 cpu 个数。
AQE SkewedJoin生效条件
Join物理算子类型
AQE的SkewedJoin只针对SortMergeJoin和ShuffleHashJoin,对于BroadcastHashJoin无法生效。
JoinType
由于AQE的原理是拆分Partition,并分别与对应的Partition进行Join操作,然后将结果Union,所以对于Outer Join,非Outer Side是无法拆分的。
假设JoinType为LeftOuter,则如果Join的右侧输入存在倾斜,AQE是无法处理的。如果JoinType为Inner,则Join两边的倾斜都是可以处理的。
Join Pattern
AQE的优化是Stage级别的,即AQE在Stage执行之前,会根据当前Stage的已完成的上游的统计信息,对当前Stage进行优化调整。目前AQE支持如下几种包含SortMergeJoin的Stage Pattern。
- Normal Join
最常见的Join Pattern,Stage10中,只有一个SortMergeJoin,且两边都是Sort + Exchange的组合.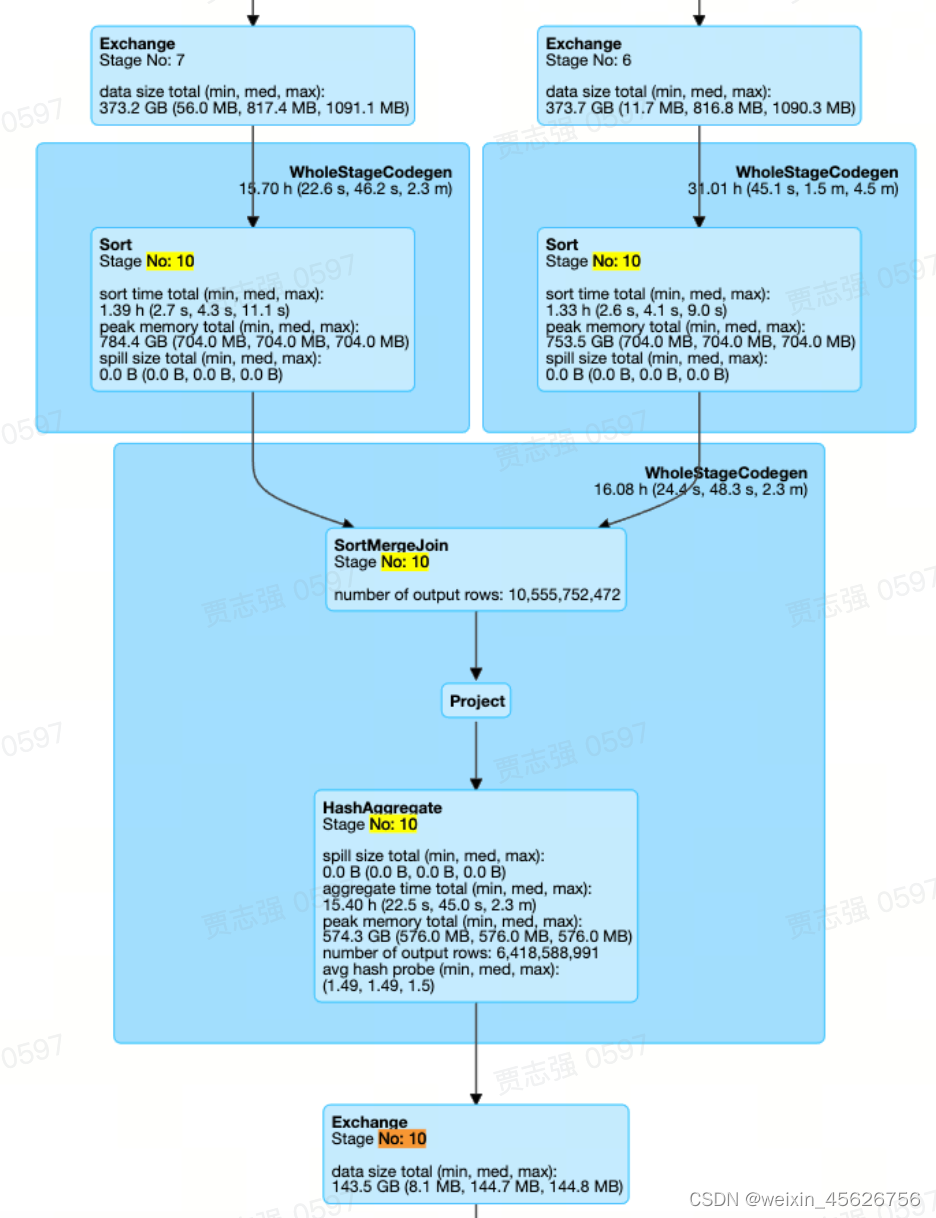
- JoinWIthAgg
Stage10中,同样只有一个SortMergeJoin,但是Join的一边并不是Sort+Exchange的组合,而是存在Aggregate算子
注:Join两边的倾斜是否可以处理,除了与JoinType有关,还与是否存在Agg算子有关。存在Agg算子的一侧也是无法处理倾斜的。例如,JoinType为Right Outer,且Join的右侧存在Agg算子,则Join两边的倾斜都无法处理。因为拆分后不符合agg算子对分布的需求,正确性会有问题
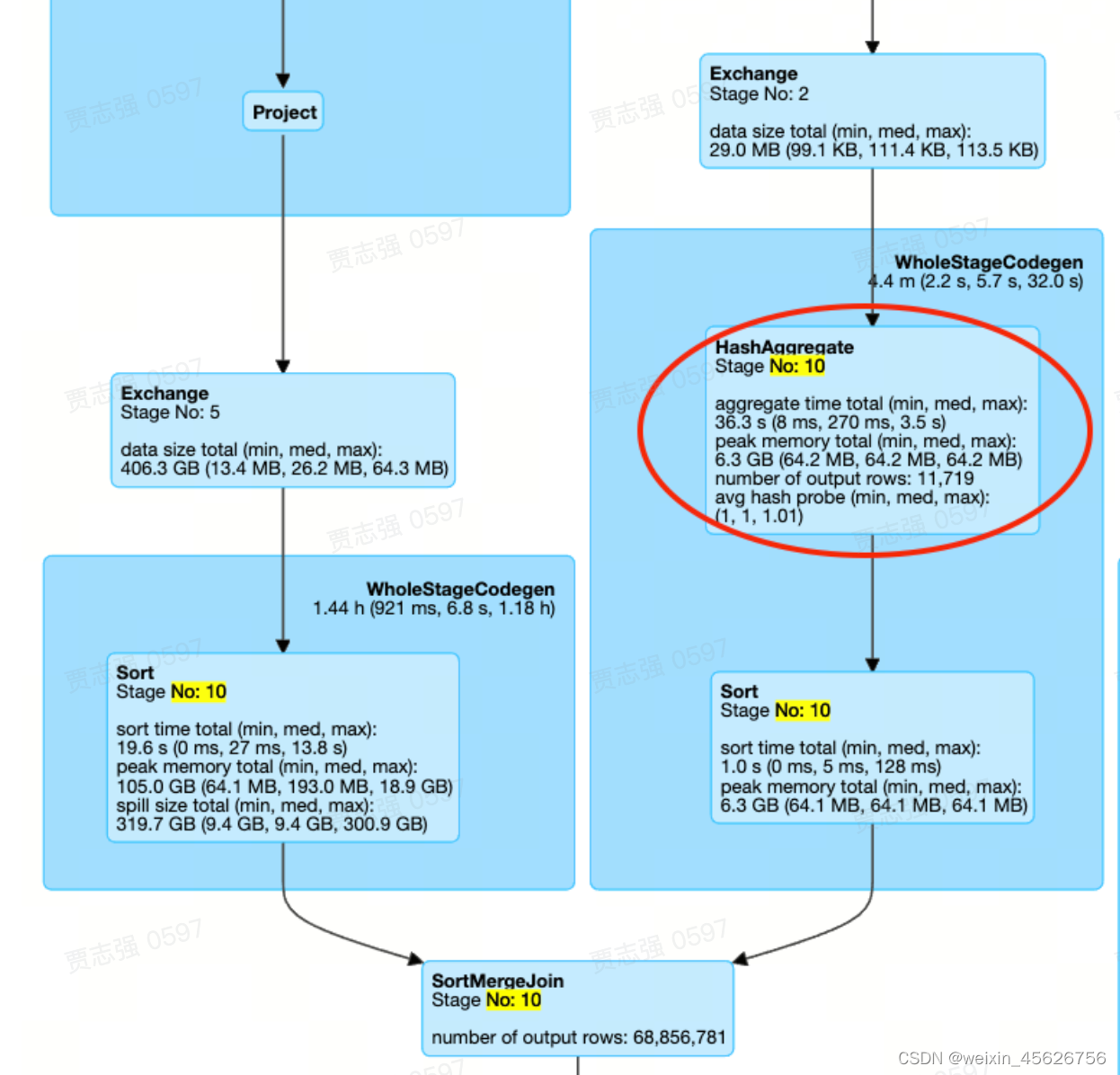
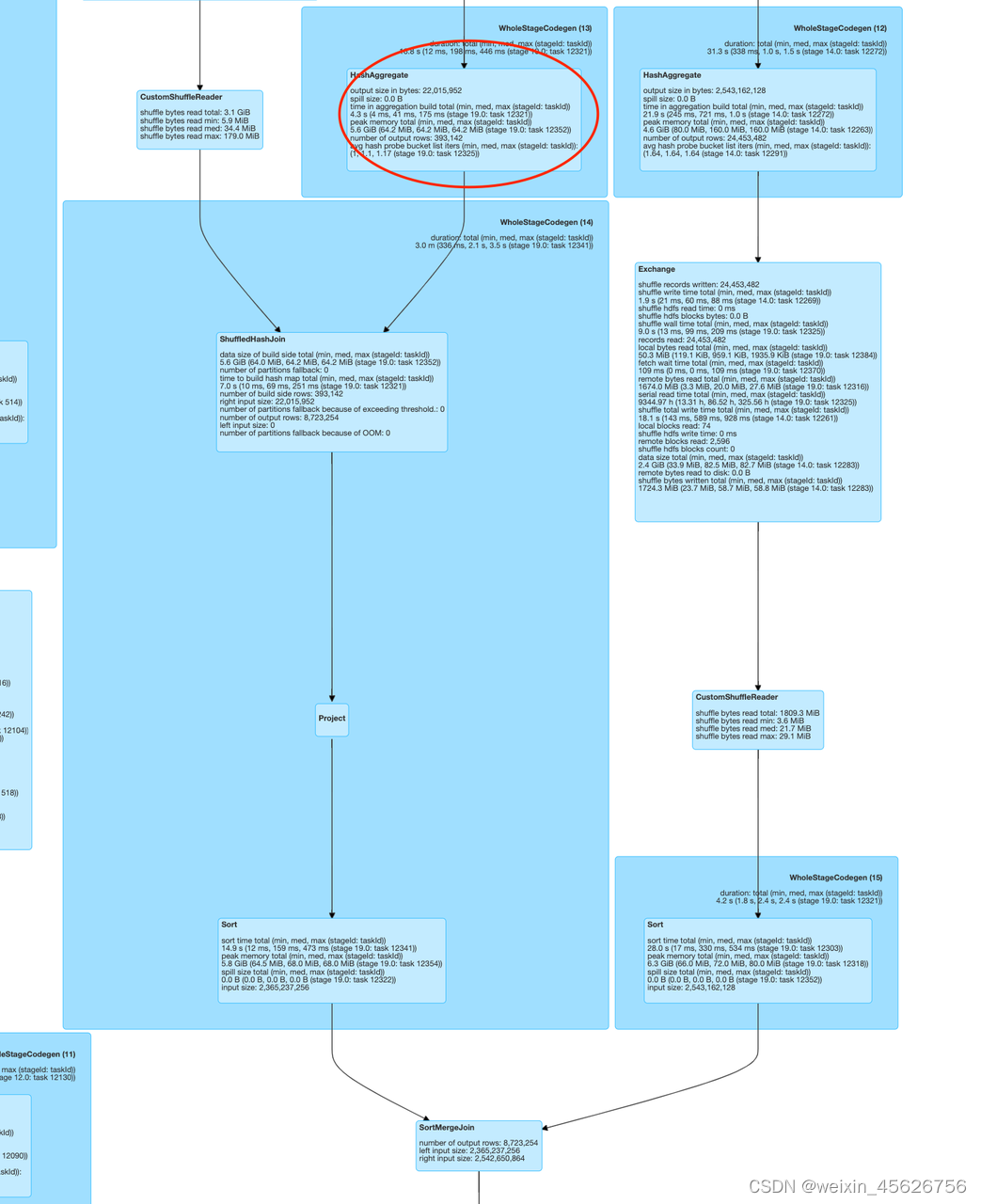
- MultipleJoinWithAggOrWin
从下图我们可以看到,Stage 19 中存在连续的 Join,且还存在 HashAgg 算子,目前开源版本不支持。