欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131403263
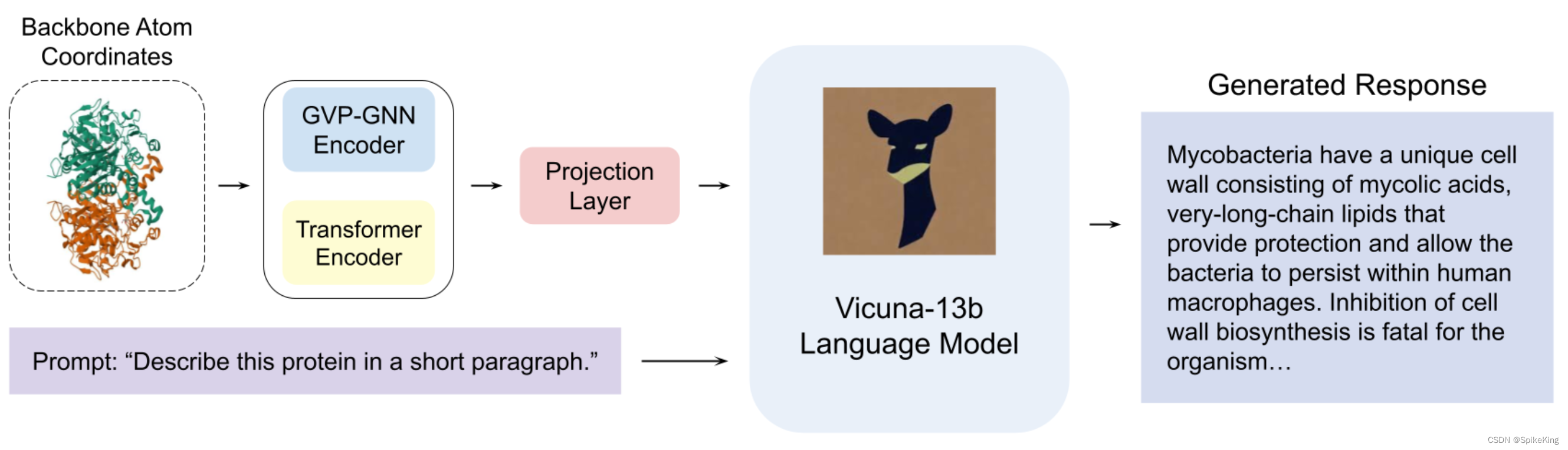
论文:ProteinChat: Towards Enabling ChatGPT-Like Capabilities on Protein 3D Structures
工程:https://github.com/UCSD-AI4H/proteinchat
ProteinChat 是基于大型语言模型(LLM)的原型系统,能够根据蛋白质的三维结构进行问答和文本解释。ProteinChat 利用一个复合编码器块和一个 LLM 解码器块,协同工作,提供蛋白质相关的洞察。复合编码器块结合了一个图神经网络(GNN)编码器块和一个 Transformer 编码器块,有效地从蛋白质结构中提取重要特征。LLM 解码器利用编码器块生成的蛋白质嵌入和用户的问题,生成信息丰富的答案。为了训练 ProteinChat,构建了RCSB-PDB蛋白质描述数据集,包含了143,508个来自公开可用资源的蛋白质-描述对。ProteinChat 是第一个利用LLM来研究蛋白质的工作,为进一步探索和利用ChatGPT-like系统在蛋白质研究中的应用奠定了基础。
参考:LLM - 搭建 DrugGPT 结合药物化学分子知识的 ChatGPT 系统
1. 配置环境
下载工程和配置 Conda 环境,参考 DrugGPT 的配置方案。
# 文件较多,下载需要一段时间
git clone https://github.com/UCSD-AI4H/proteinchat
conda env create -f environment.yml
conda activate proteinchat
pip install einops
更新适配 PyTorch:
nvidia-smi
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
验证 PyTorch 通过:
python -c "import torchvision; print(torchvision.__version__)"
0.13.1
python -c "import torch; print(torch.__version__)"
1.12.1
准备数据集:
# 链接
https://drive.google.com/u/0/uc?id=1xdiBP-FPMfwpMGBUPAKd0FyRrqQtxAEK&export=download # qa_all.json (499M)
https://drive.google.com/u/0/uc?id=1iMgPyiIzpvXdKiNsXnRKn2YpmP92Xyub&export=download # abstract.json (182M)
https://drive.google.com/u/0/uc?id=1AeJW5BY5C-d8mKJjAULTax6WA4hzWS0N&export=download # 暂时无法访问
pip install gdown
gdown https://drive.google.com/uc?id=1xdiBP-FPMfwpMGBUPAKd0FyRrqQtxAEK # 已下载完成
gdown https://drive.google.com/uc?id=1iMgPyiIzpvXdKiNsXnRKn2YpmP92Xyub # 已下载完成
下载 Google云盘使用 gdown 软件,参考:GitHub gdown,注意本地可以使用,服务器需要连接外网。
ESM-IF1 数据问题,等待解决,暂时使用临时数据。
2. 训练模型
修改训练脚本train_esm.py,使用 mini 训练集:
datasets_raw = ESMDataset(pdb_root="data/esm_subset/pt",
ann_paths="data/esm_subset/ann.json",
chain="A")
修改配置文件 minigpt4/configs/models/minigpt4.yaml:
llama_model: "workspace/vicuna-13b-weight"
暂时无法训练,待解决 bert-base-uncased 的问题,下载 5 个模型:
flax_model.msgpack # 417M
model.safetensors # 420M
pytorch_model.bin # 420M
rust_model.ot # 509M
tf_model.h5 # 511M
参考 CSDN - Hugging Face 工程 BERT base model (uncased) 配置
修改 bert-base-uncased 的路径,即minigpt4/models/blip2.py:
class Blip2Base(BaseModel):
@classmethod
def init_tokenizer(cls):
# tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("workspace_v2/bert-base-uncased")
tokenizer.add_special_tokens({"bos_token": "[DEC]"})
return tokenizer
运行训练脚本:
nvidia-smi
CUDA_VISIBLE_DEVICES=2 bash finetune.sh
训练日志如下:
2023-06-26 17:37:16,309 [INFO] Start training
2023-06-26 17:37:16,317 [INFO] Start training epoch 15, 762 iters per inner epoch.
Train: data epoch: [15] [ 0/762] eta: 0:33:20 lr: 0.000010 loss: 1.3494 time: 2.6249 data: 0.0000 max mem: 35719
Train: data epoch: [15] [ 50/762] eta: 0:03:14 lr: 0.000010 loss: 1.3266 time: 0.2184 data: 0.0000 max mem: 35719
Train: data epoch: [15] [100/762] eta: 0:02:45 lr: 0.000010 loss: 2.3126 time: 0.2295 data: 0.0000 max mem: 35719
Train: data epoch: [15] [150/762] eta: 0:02:29 lr: 0.000009 loss: 1.8479 time: 0.2468 data: 0.0000 max mem: 35719
Train: data epoch: [15] [200/762] eta: 0:02:16 lr: 0.000009 loss: 1.7400 time: 0.2444 data: 0.0000 max mem: 35719
...
参考
- CSDN - 在服务器上下载google云端硬盘文件