五月太忙,还是写一篇吧!
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
该系列文章主要讲解Python OpenCV图像处理和图像识别知识,前期主要讲解图像处理基础知识、OpenCV基础用法、常用图像绘制方法、图像几何变换等,中期讲解图像处理的各种运算,包括图像点运算、形态学处理、图像锐化、图像增强、图像平滑等,后期研究图像识别、图像分割、图像分类、图像特效处理以及图像处理相关应用。
第一部分作者介绍了图像处理基础知识,第二部分介绍了图像运算和图像增强,接下来第三部分我们将详细讲解图像识别及图像处理经典案例,该部分属于高阶图像处理知识,能进一步加深我们的理解和实践能力。图像分类是根据图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。本文主要讲解常见的图像分类算法,并详细讲解了Python环境下的贝叶斯图像分类算法和基于KNN算法的图像分类等案例。希望文章对您有所帮助,如果有不足之处,还请海涵。
文章目录
- 一.图像分类
- 二.基于朴素贝叶斯的图像分类
- 三.基于KNN的图像分类
- 四.总结
下载地址:记得点赞喔 O(∩_∩)O
- https://github.com/eastmountyxz/Python-zero2one
- 开源600多页电子书:https://github.com/eastmountyxz/HWCloudImageRecognition
前文赏析:(尽管该部分占大量篇幅,但我舍不得删除,哈哈!)
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析和机器学习
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
- [Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
- [Python从零到壹] 十四.机器学习之分类算法三万字总结全网首发(决策树、KNN、SVM、分类算法对比)
- [Python从零到壹] 十五.文本挖掘之数据预处理、Jieba工具和文本聚类万字详解
- [Python从零到壹] 十六.文本挖掘之词云热点与LDA主题分布分析万字详解
- [Python从零到壹] 十七.可视化分析之Matplotlib、Pandas、Echarts入门万字详解
- [Python从零到壹] 十八.可视化分析之Basemap地图包入门详解
- [Python从零到壹] 十九.可视化分析之热力图和箱图绘制及应用详解
- [Python从零到壹] 二十.可视化分析之Seaborn绘图万字详解
- [Python从零到壹] 二十一.可视化分析之Pyechart绘图万字详解
- [Python从零到壹] 二十二.可视化分析之OpenGL绘图万字详解
- [Python从零到壹] 二十三.十大机器学习算法之决策树分类分析详解(1)
- [Python从零到壹] 二十四.十大机器学习算法之KMeans聚类分析详解(2)
- [Python从零到壹] 二十五.十大机器学习算法之KNN算法及图像分类详解(3)
- [Python从零到壹] 二十六.十大机器学习算法之朴素贝叶斯算法及文本分类详解(4)
- [Python从零到壹] 二十七.十大机器学习算法之线性回归算法分析详解(5)
- [Python从零到壹] 二十八.十大机器学习算法之SVM算法分析详解(6)
- [Python从零到壹] 二十九.十大机器学习算法之随机森林算法分析详解(7)
- [Python从零到壹] 三十.十大机器学习算法之逻辑回归算法及恶意请求检测应用详解(8)
- [Python从零到壹] 三十一.十大机器学习算法之Boosting和AdaBoost应用详解(9)
- [Python从零到壹] 三十二.十大机器学习算法之层次聚类和树状图聚类应用详解(10)
第四部分 Python图像处理基础
- [Python从零到壹] 三十三.图像处理基础篇之什么是图像处理和OpenCV配置
- [Python从零到壹] 三十四.OpenCV入门详解——显示读取修改及保存图像
- [Python从零到壹] 三十五.图像处理基础篇之OpenCV绘制各类几何图形
- [Python从零到壹] 三十六.图像处理基础篇之图像算术与逻辑运算详解
- [Python从零到壹] 三十七.图像处理基础篇之图像融合处理和ROI区域绘制
- [Python从零到壹] 三十八.图像处理基础篇之图像几何变换(平移缩放旋转)
- [Python从零到壹] 三十九.图像处理基础篇之图像几何变换(镜像仿射透视)
- [Python从零到壹] 四十.图像处理基础篇之图像量化处理
- [Python从零到壹] 四十一.图像处理基础篇之图像采样处理
- [Python从零到壹] 四十二.图像处理基础篇之图像金字塔向上取样和向下取样
第五部分 Python图像运算和图像增强
- [Python从零到壹] 四十三.图像增强及运算篇之图像点运算和图像灰度化处理
- [Python从零到壹] 四十四.图像增强及运算篇之图像灰度线性变换详解
- [Python从零到壹] 四十五.图像增强及运算篇之图像灰度非线性变换详解
- [Python从零到壹] 四十六.图像增强及运算篇之图像阈值化处理
- [Python从零到壹] 四十七.图像增强及运算篇之腐蚀和膨胀详解
- [Python从零到壹] 四十八.图像增强及运算篇之形态学开运算、闭运算和梯度运算
- [Python从零到壹] 四十九.图像增强及运算篇之顶帽运算和底帽运算
- [Python从零到壹] 五十.图像增强及运算篇之图像直方图理论知识和绘制实现
- [Python从零到壹] 五十一.图像增强及运算篇之图像灰度直方图对比分析万字详解
- [Python从零到壹] 五十二.图像增强及运算篇之图像掩膜直方图和HS直方图
- [Python从零到壹] 五十三.图像增强及运算篇之直方图均衡化处理
- [Python从零到壹] 五十四.图像增强及运算篇之局部直方图均衡化和自动色彩均衡化处理
- [Python从零到壹] 五十五.图像增强及运算篇之图像平滑(均值滤波、方框滤波、高斯滤波)
- [Python从零到壹] 五十六.图像增强及运算篇之图像平滑(中值滤波、双边滤波)
- [Python从零到壹] 五十七.图像增强及运算篇之图像锐化Roberts、Prewitt算子实现边缘检测
- [Python从零到壹] 五十八.图像增强及运算篇之图像锐化Sobel、Laplacian算子实现边缘检测
- [Python从零到壹] 五十九.图像增强及运算篇之图像锐化Scharr、Canny、LOG实现边缘检测
第六部分 Python图像识别和图像高阶案例
- [Python从零到壹] 六十.图像识别及经典案例篇之基于阈值及边缘检测的图像分割
- [Python从零到壹] 六十一.图像识别及经典案例篇之基于纹理背景和聚类算法的图像分割
- [Python从零到壹] 六十二.图像识别及经典案例篇之基于均值漂移算法和分水岭算法的图像分割
- [Python从零到壹] 六十三.图像识别及经典案例篇之图像漫水填充分割应用
- [Python从零到壹] 六十四.图像识别及经典案例篇之图像傅里叶变换和傅里叶逆变换详解
- [Python从零到壹] 六十五.图像识别及经典案例篇之图像霍夫变换详解
- [Python从零到壹] 六十六.图像识别及经典案例篇之基于机器学习的图像分类
第七部分 NLP与文本挖掘
第八部分 人工智能入门知识
第九部分 网络攻防与AI安全
第十部分 知识图谱构建实战
扩展部分 人工智能高级案例
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
一.图像分类
图像分类(Image Classification)是对图像内容进行分类的问题,它利用计算机对图像进行定量分析,把图像或图像中的区域划分为若干个类别,以代替人的视觉判断。图像分类的传统方法是特征描述及检测,这类传统方法可能对于一些简单的图像分类是有效的,但由于实际情况非常复杂,传统的分类方法不堪重负。现在,广泛使用机器学习和深度学习的方法来处理图像分类问题,其主要任务是给定一堆输入图片,将其指派到一个已知的混合类别中的某个标签[1]。
在图1中,图像分类模型将获取单个图像,并将为4个标签{cat,dog,hat,mug}分配对应的概率{0.6, 0.3, 0.05, 0.05},其中0.6表示图像标签为猫的概率,其余类比。如图所示,该图像被表示为一个三维数组。在这个例子中,猫的图像宽度为248像素,高度为400像素,并具有红绿蓝三个颜色通道(通常称为RGB)。因此,图像由248×400×3个数字组成或总共297600个数字,每个数字是一个从0(黑色)到255(白色)的整数。图像分类的任务是将这接近30万个数字变成一个单一的标签,如“猫(cat)”[2]。

那么,如何编写一个图像分类的算法呢?又怎么从众多图像中识别出猫呢?
这里所采取的方法和教育小孩看图识物类似,给出很多图像数据,让模型不断去学习每个类的特征。在训练之前,首先需要对训练集的图像进行分类标注,如图2所示,包括cat、dog、mug和hat四类。在实际工程中,可能有成千上万类别的物体,每个类别都会有上百万张图像。

图像分类是输入一堆图像的像素值数组,然后给它分配一个分类标签,通过训练学习来建立算法模型,接着使用该模型进行图像分类预测,具体流程如下:
- 输入:输入包含N个图像的集合,每个图像的标签是K种分类标签中的一种,这个集合称为训练集;
- 学习:第二步任务是使用训练集来学习每个类的特征,构建训练分类器或者分类模型;
- 评价:通过分类器来预测新输入图像的分类标签,并以此来评价分类器的质量。通过分类器预测的标签和图像真正的分类标签对比,从而评价分类算法的好坏。如果分类器预测的分类标签和图像真正的分类标签一致,表示预测正确,否则预测错误。
常见的分类算法包括朴素贝叶斯分类器、决策树、K最近邻分类算法、支持向量机、神经网络和基于规则的分类算法等,同时还有用于组合单一类方法的集成学习算法,如Bagging和Boosting等[2]。
二.基于朴素贝叶斯的图像分类
朴素贝叶斯分类(Naive Bayes Classifier)发源于古典数学理论,利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。在朴素贝叶斯分类模型中,它将为每一个类别的特征向量建立服从正态分布的函数,给定训练数据,算法将会估计每一个类别的向量均值和方差矩阵,然后根据这些进行预测。
朴素贝叶斯分类模型的正式定义如下:

该算法的特点为:如果没有很多数据,该模型会比很多复杂的模型获得更好的性能,因为复杂的模型用了太多假设,以致产生欠拟合。
本文主要使用Scikit-Learn包进行Python图像分类处理。Scikit-Learn扩展包是用于Python数据挖掘和数据分析的经典、实用扩展包,通常缩写为Sklearn。Scikit-Learn中的机器学习模型是非常丰富的,包括线性回归、决策树、SVM、KMeans、KNN、PCA等等,用户可以根据具体分析问题的类型选择该扩展包的合适模型,从而进行数据分析,其安装过程主要通过“pip install scikit-learn”实现。

实验所采用的数据集为Sort_1000pics数据集,该数据集包含了1000张图片,总共分为10大类,分别是人(第0类)、沙滩(第1类)、建筑(第2类)、大卡车(第3类)、恐龙(第4类)、大象(第5类)、花朵(第6类)、马(第7类)、山峰(第8类)和食品(第9类),每类100张。如图所示。

接着将所有各类图像按照对应的类标划分至“0”至“9”命名的文件夹中,如图所示,每个文件夹中均包含了100张图像,对应同一类别。

比如,文件夹名称为“6”中包含了100张花的图像,如图所示。

下面是调用朴素贝叶斯算法进行图像分类的完整代码,调用sklearn.naive_bayes中的BernoulliNB()函数进行实验。它将1000张图像按照训练集为70%,测试集为30%的比例随机划分,再获取每张图像的像素直方图,根据像素的特征分布情况进行图像分类分析。
# -*- coding: utf-8 -*-
# By: Eastmount
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
#------------------------------------------------------------------------
# 第一步 切分训练集和测试集
#------------------------------------------------------------------------
X = [] #定义图像名称
Y = [] #定义图像分类类标
Z = [] #定义图像像素
for i in range(0, 10):
#遍历文件夹,读取图片
for f in os.listdir("photo/%s" % i):
#获取图像名称
X.append("photo//" +str(i) + "//" + str(f))
#获取图像类标即为文件夹名称
Y.append(i)
X = np.array(X)
Y = np.array(Y)
#随机率为100% 选取其中的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=0.3, random_state=1)
print(len(X_train), len(X_test), len(y_train), len(y_test))
#------------------------------------------------------------------------
# 第二步 图像读取及转换为像素直方图
#------------------------------------------------------------------------
#训练集
XX_train = []
for i in X_train:
#读取图像
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_train.append(((hist/255).flatten()))
#测试集
XX_test = []
for i in X_test:
image = cv2.imread(i)
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_test.append(((hist/255).flatten()))
#------------------------------------------------------------------------
# 第三步 基于朴素贝叶斯的图像分类处理
#------------------------------------------------------------------------
from sklearn.naive_bayes import BernoulliNB
clf = BernoulliNB().fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
print('预测结果:')
print(predictions_labels)
print('算法评价:')
print((classification_report(y_test, predictions_labels)))
#输出前10张图片及预测结果
k = 0
while k<10:
#读取图像
print(X_test[k])
image = cv2.imread(X_test[k])
print(predictions_labels[k])
#显示图像
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
k = k + 1
代码中对预测集的前十张图像进行了显示,其中“368.jpg”图像如图7所示,其分类预测的类标结果为“3”,表示第3类大卡车,预测结果正确。

图8展示了“452.jpg”图像,其分类预测的类标结果为“4”,表示第4类恐龙,预测结果正确。

图9展示了“507.jpg”图像,其分类预测的类标结果为“7”,错误地预测为第7类恐龙,其真实结果应该是第5类大象。

使用朴素贝叶斯算法进行图像分类实验,最后预测的结果及算法评价准确率(Precision)、召回率(Recall)和F值(F1-score)如图10所示。

三.基于KNN的图像分类
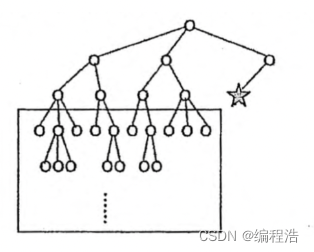
K最近邻分类(K-Nearest Neighbor Classifier)算法是一种基于实例的分类方法,是数据挖掘分类技术中最简单常用的方法之一[2]。该算法的核心思想如下:一个样本x与样本集中的k个最相邻的样本中的大多数属于某一个类别yLabel,那么该样本x也属于类别yLabel,并具有这个类别样本的特性。简而言之,一个样本与数据集中的k个最相邻样本中的大多数的类别相同。由其思想可以看出,KNN是通过测量不同特征值之间的距离进行分类,而且在决策样本类别时,只参考样本周围k个“邻居”样本的所属类别。因此比较适合处理样本集存在较多重叠的场景,主要用于预测分析、文本分类、降维等处理。
该算法在建立训练集时,就要确定训练数据及其对应的类别标签;然后把待分类的测试数据与训练集数据依次进行特征比较,从训练集中挑选出最相近的k个数据,这k个数据中投票最多的分类,即为新样本的类别。KNN分类算法的流程描述为如图11所示。

该算法的特点为:简单有效,但因为需要存储所有的训练集,占用很大内存,速度相对较慢,使用该方法前通常训练集需要进行降维处理。
下面是基于KNN算法的图像分类代码,调用sklearn.neighbors中的KNeighborsClassifier()函数进行实验。核心代码如下:
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
完整代码如下。
# -*- coding: utf-8 -*-
# By: Eastmount
import os
import cv2
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
#------------------------------------------------------------------------
# 第一步 切分训练集和测试集
#------------------------------------------------------------------------
X = [] #定义图像名称
Y = [] #定义图像分类类标
Z = [] #定义图像像素
for i in range(0, 10):
#遍历文件夹,读取图片
for f in os.listdir("photo/%s" % i):
#获取图像名称
X.append("photo//" +str(i) + "//" + str(f))
#获取图像类标即为文件夹名称
Y.append(i)
X = np.array(X)
Y = np.array(Y)
#随机率为100% 选取其中的30%作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=0.3, random_state=1)
print(len(X_train), len(X_test), len(y_train), len(y_test))
#------------------------------------------------------------------------
# 第二步 图像读取及转换为像素直方图
#------------------------------------------------------------------------
#训练集
XX_train = []
for i in X_train:
#读取图像
image = cv2.imread(i)
#图像像素大小一致
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
#计算图像直方图并存储至X数组
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_train.append(((hist/255).flatten()))
#测试集
XX_test = []
for i in X_test:
image = cv2.imread(i)
img = cv2.resize(image, (256,256),
interpolation=cv2.INTER_CUBIC)
hist = cv2.calcHist([img], [0,1], None,
[256,256], [0.0,255.0,0.0,255.0])
XX_test.append(((hist/255).flatten()))
#------------------------------------------------------------------------
# 第三步 基于KNN的图像分类处理
#------------------------------------------------------------------------
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=11).fit(XX_train, y_train)
predictions_labels = clf.predict(XX_test)
print('预测结果:')
print(predictions_labels)
print('算法评价:')
print((classification_report(y_test, predictions_labels)))
#输出前10张图片及预测结果
k = 0
while k<10:
#读取图像
print(X_test[k])
image = cv2.imread(X_test[k])
print(predictions_labels[k])
#显示图像
cv2.imshow("img", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
k = k + 1
代码中对预测集的前十张图像进行了显示,其中“818.jpg”图像如图12所示,其分类预测的类标结果为“8”,表示第8类山峰,预测结果正确。

图13展示了“929.jpg”图像,其分类预测的类标结果为“9”,正确地预测为第9类食品。

使用KNN算法进行图像分类实验,最后算法评价的准确率(Precision)、召回率(Recall)和F值(F1-score)如图14所示,其中平均准确率为0.64,平均召回率为0.55,平均F值为0.50,其结果略差于朴素贝叶斯的图像分类算法。

四.总结
本文主要讲解Python环境下的图像分类算法,首先普及了常见的分类算法,包括朴素贝叶斯、KNN、SVM、随机森林、神经网络等,接着通过朴素贝叶斯和KNN分别实现了1000张图像的图像分类实验,希望对读者有一定帮助。此外,本文的代码存在很多缺陷,比如图像分类使用整幅图像的像素进行计算效果会更好,再如深度学习应用于图像分类的结果由于机器学习等,接下来我们将分享基于卷积神经网络的图像分类案例。
感谢在求学路上的同行者,不负遇见,勿忘初心。图像处理系列主要包括三部分,分别是:



忙碌的五月,忙碌的2023。又进城弄了一整天材料,乡里人每次来都要拍几张照,周日继续出差,希望一切顺利。梦回2019,又吃上了这家鸡公煲,可惜锅变了,味也变了。转眼四年过去,我和她都不容易,两人每次看“致谢”都会泪目,青春变了,唯有情感不变,希望一家人健康快乐。刚到寝室,要战斗了!

参考文献:
- [1]冈萨雷斯著. 数字图像处理(第3版)[M]. 北京:电子工业出版社,2013.
- [2]杨秀璋, 颜娜. Python网络数据爬取及分析从入门到精通(分析篇)[M]. 北京:北京航天航空大学出版社, 2018.
- [3]gzq0723. 干货——图像分类(上)[EB/OL]. (2018-08-28). https://blog.csdn.net/gzq0723/
article/details/82185832. - [4]sinat_34430765. OpenCV分类器学习心得[EB/OL]. (2016-08-03). https://blog.csdn.net/sinat_34430765/article/details/52103189.
- [5]baidu_28342107. 机器学习之贝叶斯算法图像分类[EB/OL]. (2018-10-10). https://blog.csdn.net/baidu_28342107/article/details/82999249.
- [6]Eastmount. [Python图像处理] 二十六.图像分类原理及基于KNN、朴素贝叶斯算法的图像分类案例[EB/OL]. (2020-02-11). https://blog.csdn.net/Eastmount/article/details/104263641.