文章目录
- HTTP协议是什么
- HTTP报文格式
- 抓包工具fiddler
- HTTP请求
- 请求行
- HTTP方法
- URL
- 版本号
- 请求头
- HOST
- Content-Type&Content-Length
- User-Agent(简称UA)
- Referer
- Cookie
- HTTP响应
- 状态行
- 版本号
- 状态码
HTTP协议是什么
HTTP协议全称为超文本传输协议,是一个被广泛使用的应用层协议,由于HTTP协议的可制定性非常强,所以HTTP被使用的非常广泛。
我们平时打开一个网页就是通过HTTP协议来传输数据的,当我们输入网址(URL)的时候就是向对应浏览器的服务器发送了一个HTTP请求,服务器接收到请求会返回一个HTTP响应,这个响应经过浏览器的解析后最终呈现的内容就是网页的内容。
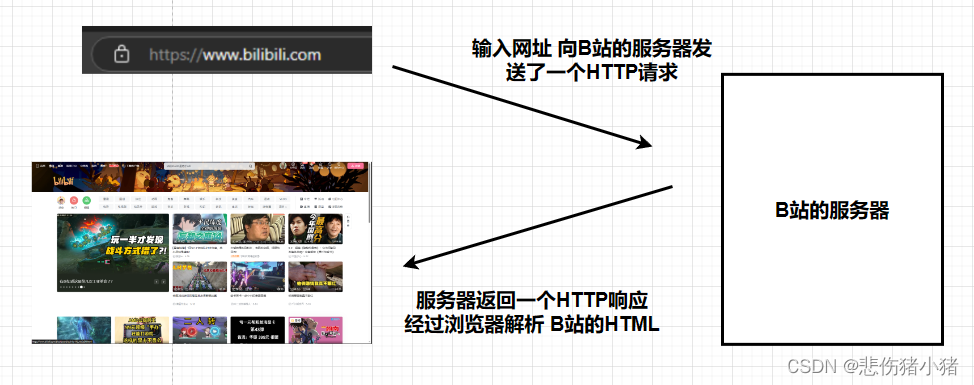
HTTP往往是基于传输层的TCP协议实现的,应用层协议关注的是数据干什么用,并不关注数据如何传输,我们将网络通信比作在淘宝买东西,传输层关注的是端到端,也就是我们的发货地址和收货地址是什么,网络层做的是路由选择,也就是从发货地址到收货地址究竟走哪一条路,数据链路层关注的是中间相邻节点如何走,当我们的快递从发货地址到达收货地址后就完了嘛?并没有,我们还需要确定这个快递买来是做什么用的,这是应用层协议所关注的。
HTTP报文格式
想要了解HTTP的报文协议格式我们需要借助一些工具,来把HTTP协议给显示出来——抓包工具。
抓包工具是什么?我们可以理解为代理,例如我有一个追随我的小弟,现在我想吃冰激凌但是我又不想自己去,这个时候我可以让我的小弟去帮我买冰激凌,此时小弟可以清楚的知道我在干什么,抓包工具跟上述过程类似,浏览器向服务器发送的HTTP请求通过抓包工具发送,服务器返回的HTTP响应也通过抓包工具返回,此时抓包工具可以清楚的看见HTTP的报文格式和内容。
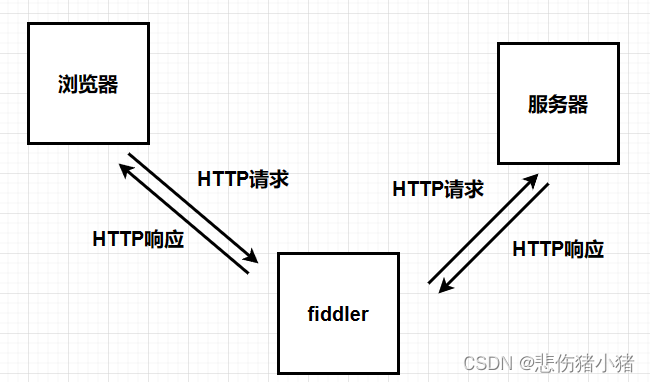
抓包工具fiddler
抓包工具有很多
1、chrome内置了一个
2、wireshark 功能全面,使用复杂,IP、TCP、UDP、HTTP都可以抓。
3、fiddler 专注于HTTP,使用简单。
工作中常用的是fiddler: fiddler下载地址
下载完成后打开fiddler,首次使用需要一些设置,找到tools下的Options

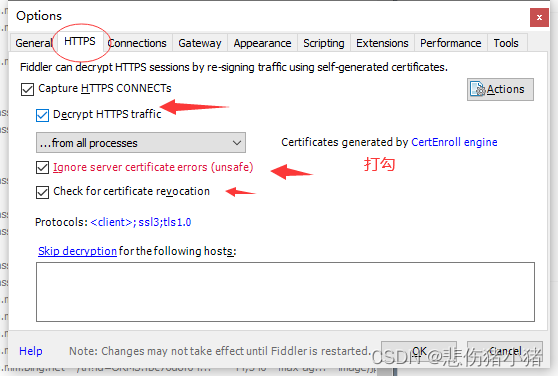
这个设置的大概意思就是让你是否要安装根证书,一定要选择YES,否则卸载重装,因为当前网络上的主要协议都是HTTPS。
如果fiddler使用不了可以检查一下下面两点:
1、没有勾选https,没有安装根证书,此时无法解析https数据,抓包的数据就会少很多
2、与其他的代理冲突了。
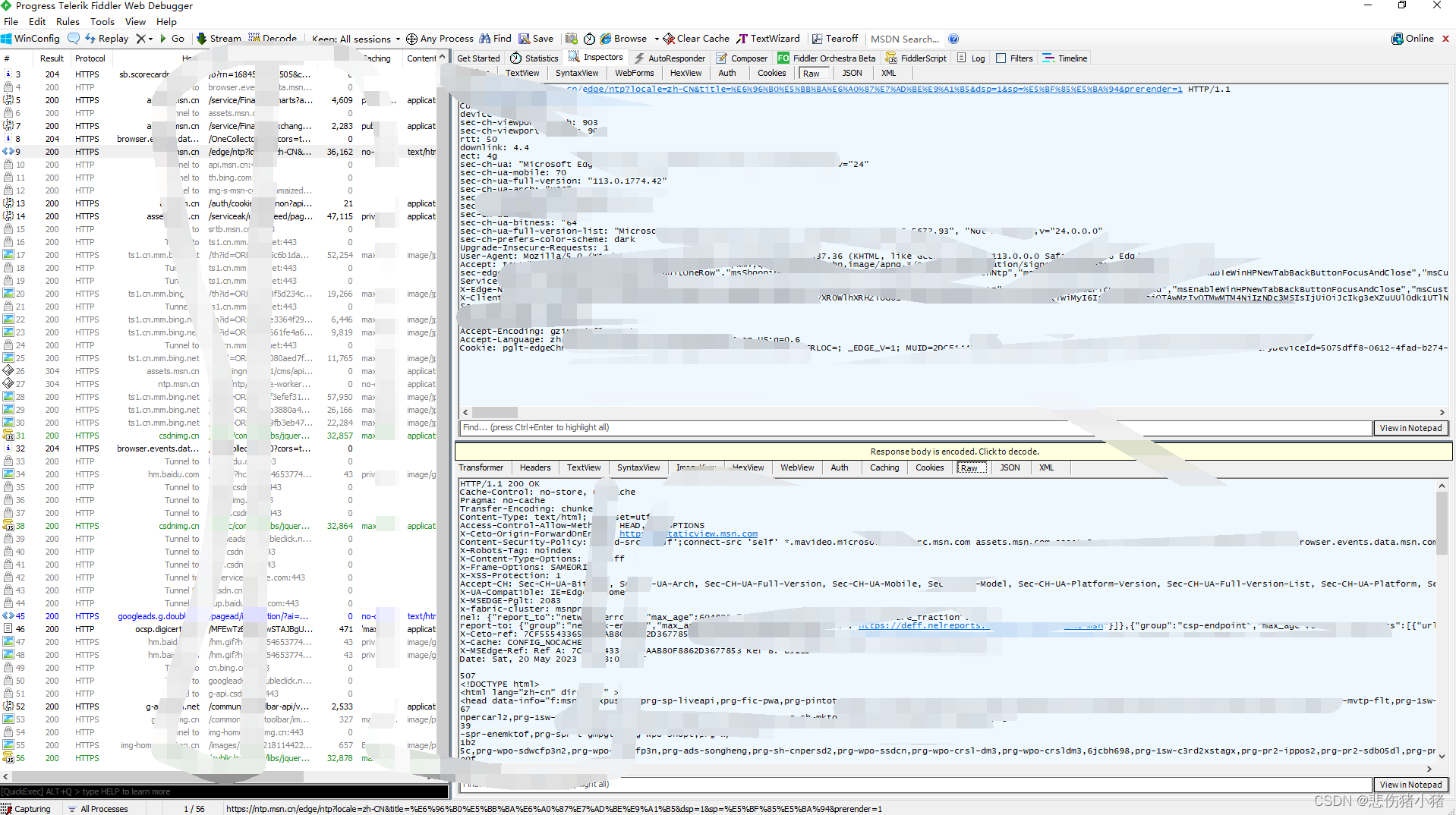
此时左边我们就可以看见所有HTTP请求和响应,双击选中某一个可以查看具体报文内容,右上方是HTTP请求报文内容右下方是HTTP响应报文内容,选择Raw可以查看详细信息。
通过观察我们可以总结出HTTP协议的报文格式
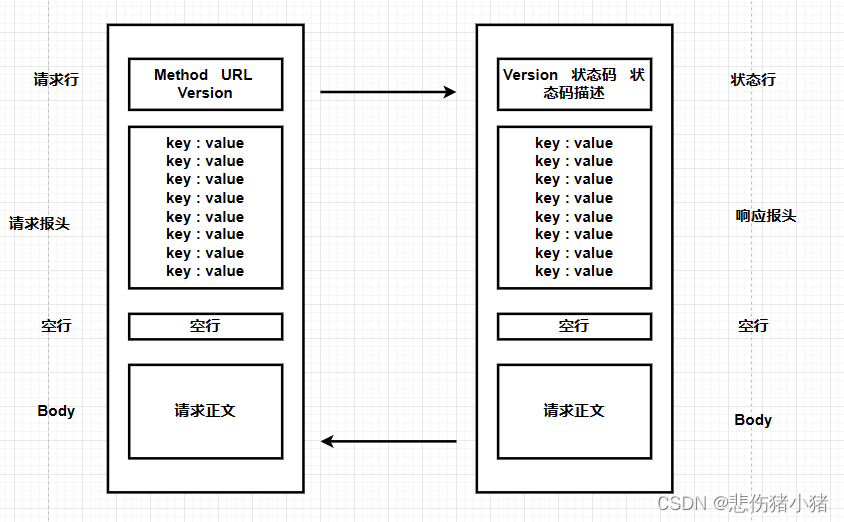
HTTP请求
请求行

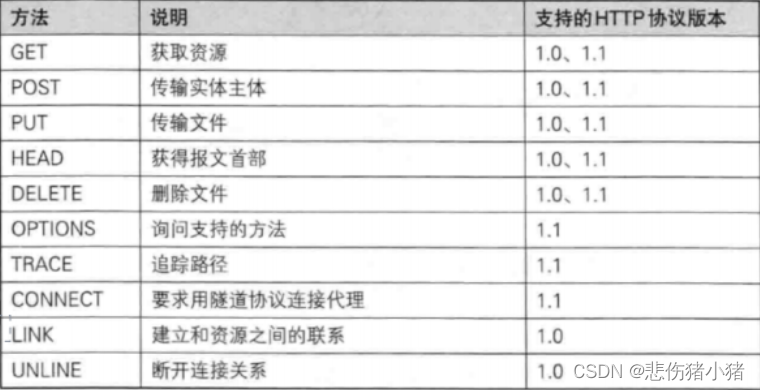
HTTP方法
这样一串拼接的字符串就是请求行的信息,首先GET是HTTP方法,描述了这个HTTP请求想干什么,不同的方法表示不同的语义,例如GET的语义是从服务器这里,拿一个东西,POST的语义是向服务器里提交一个东西。
后面跟着的一长串是URL,最后是版本号。
一般我们看到的请求大部分都是GET,在登陆或者上传文件的时候可以看见POST,GET语义下一般Body为空,POST语义下一般Body不为空,这两个HTTP方法也是最常用的,虽然语义不同,但在使用时并非需要严格的遵守规则。
这样我们就有了一个非常经典的面试题:GET和POST这两个方法究竟有啥区别。
1、首先下定义,并没有本质上的区别,两个方法可以互相替换
2、在使用习惯上存在区别,一般POST表示提交一个数据,GET表示获取一个数据
3、GET通常会设置成幂等的,POST没有要求
4、GET可缓存,POST不可以
5、GET请求可以被浏览器收藏,POST不可以。
幂等的意思就是每次相同的请求都会返回相同的响应,例如我搜索一个10*10的计算结果,此时服务器计算后可以把结果保存下来,下次就不需要在进行计算,返回给浏览器的数据,浏览器也可以存起来,下一次再有这样的请求就不需要发送给服务器了,这样的操作需要建立的幂等的前提下。
URL
URL是唯一资源定位符,描述了网络上的唯一的一个资源。
针对URL来说一般结构大概有这几个部分:
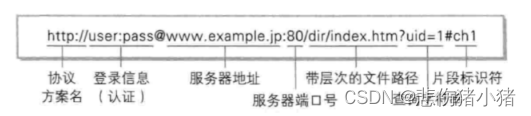
例如上图的URL:

剩下后面的一堆键值对结构的我们成为query string 这是一些参数,对请求资源进行细节上的补充,使用&分割键值对,使用=分割键和值。
版本号
HTTP的版本有:HTTP1.0、HTTP1.1、HTTP2.0、HTTP3,目前我们主要使用的HTTP1.1和HTTP2.0,之前讲HTTP协议往往是基于TCP进行传输的,但HTTP3基于UDP进行传输。
请求头
请求头header,键值对结构,每个键值对占一行,键和值之间使用冒号空格来分割。

下面介绍一下常见的一些属性:
HOST
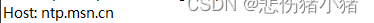
这个属性描述了浏览器这个请求要访问的服务器是谁,这里写的不仅仅是地址也可以写端口号。
Content-Type&Content-Length
Content-Type:描述了body的数据格式
Content-Length:描述了body的长度
此时我们这个请求body为空所以没有这两个参数,Content-Type有两种写法可以写成json格式,也可以写成类似于query string的格式。
json
{
“username”: “xxxxx”,
“password”: “xxxxxxxx”
}
query string
username=xxxxx&password=xxxxxxxx
User-Agent(简称UA)
这个属性描述的是用户的客户端使用的是什么样子的
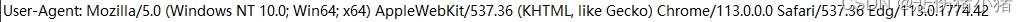
上述信息有操作系统的版本,浏览器的版本等信息,以前UA的用途是用来区分不同的浏览器,因为不同的浏览器功能不一样,告诉服务器客户使用的是什么浏览器,服务器返回对应的页面,现在浏览器之间的区别越来越小,UA的用途变成了区分手机、PC、平板了。
Referer
这个描述记录了,当前这个页面是从哪个页面跳转来的。
Cookie
这么长一串看不懂的东西就是Cookie,这里的键值对都是程序员自定义数据,不同的网站功能不一样。
Cookie的本质是浏览器在本地存储用户自定义数据的一种关键机制。
浏览器提供Cookie机制,允许网页往浏览器这边存储一些固定的键值对,这些数据通过浏览器提供的api写入特定的文件中。同一个网站的不同页面共享一个Cookie,不同的网站有不同的Cookie。
经典夺命三连问:我是谁?我在哪?我在干啥?
Cookie从哪里来
从服务器来,在HTTP响应里会返回一个Set-Cookie字段给浏览器,此时浏览器收到这个数据,储存在本地。
Cookie到哪里去
回到服务器,会在下次发送请求时发送给服务器,这个数据真正发挥作用实在服务器里。
Cookie有什么用
是浏览器的本地存储数据的机制,可以存任何数据,最经典的就是用户身份信息,由于客户端有很多,每个客户端需要的服务不一样,此时就可以根据Cookie进行区分,每次客户端发送请求时带着自己的Cookie,此时服务器就知道这个客户端时干嘛的了。
HTTP响应
状态行
版本号
版本号与请求相同。
状态码
状态码是一个数字,这个数字是用来表示这次的请求执行是否成功,如果失败,失败的原因是什么?
常见的状态码有:
1、200:表示请求成功
2、404Not Found:表示要访问的资源不存在
3、403Forbidden:访问被拒绝,没有权限
4、500Internal Server Error:服务器内部错误
5、504Gateway Timeout:服务器访问超时了
6、302Move temporarlly:临时重定向
7、301Moved Permanently 永久重定向
重定向的意思就是呼叫转移,就是访问旧的地址,被自动引导到新的地址上。
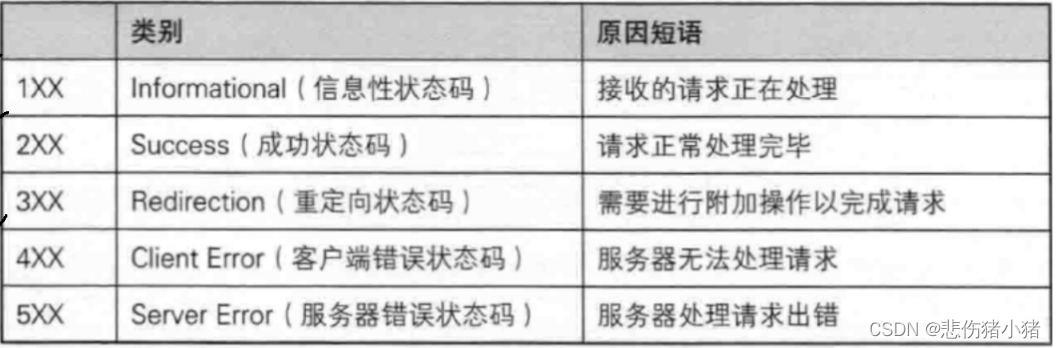
服务器的状态码大致可以分为:
剩下的内容响应报头和body正文跟请求都差不多,不在进行赘述了。







![[比赛简介]Parkinson‘s Freezing of Gait Prediction](https://img-blog.csdnimg.cn/dd70510ee47d41f09c316dfcaa87f64d.png)