计算机视觉研究院专栏
作者:Edison_G
深度特征学习方案将重点从具有细节的具体特征转移到具有语义信息的抽象特征。它通过构建多尺度深度特征学习网络 (MDFN) 不仅考虑单个对象和局部上下文,还考虑它们之间的关系。

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
论文获取|回复”MDFN“获取论文
1
前言
目前深度学习用于目标检测已经习以为常。从SSD到Yolo系列,其中:
深层网络的感受野比较大,语义信息表征能力强,但是特征图的分辨率低,几何信息的表征能力弱(空间几何特征细节缺乏);
低层网络的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱。
高层的语义信息能够帮助我们准确的检测出目标。

SSD框架

ASPP网络
Cascaded
下采样倍数小(一般是浅层)的特征感受野小,适合处理小目标,小尺度特征图(深层)分辨率信息不足不适合小目标。在yolov3中对多尺度检测的理解是,1/32大小的特征图(深层)下采样倍数高,所以具有大的感受野,适合检测大目标的物体,1/8的特征图(较浅层)具有较小的感受野,所以适合检测小目标。FPN中的处理在下面。对于小目标,小尺度feature map无法提供必要的分辨率信息,所以还需结合大尺度的feature map。还有个原因是在深层图做下采样损失过多信息,小目标信息或许已经被忽略。
2
背 景
Feature Extraction
作为许多视觉和多媒体处理任务的基础步骤,特征提取和表示得到了广泛的研究,特别是在网络结构层面,这在深度学习领域引起了很多关注。更深或更广的网络放大了体系结构之间的差异,并在许多计算机视觉应用中充分发挥了提高特征提取能力的作用。skip-connection技术通过在网络的不同层级之间传播信息,缩短它们的连接,在一定程度上解决了梯度消失的问题,这激发了构建更深网络的热点研究,并获得了性能的提升。从5层的LeNet5到16层的VGGNet,再到1000层以上的ResNet,网络的深度急剧增加。ResNet-101显示了其在特征提取和表示方面的优势,尤其是在用作对象检测任务的基础网络时。许多研究人员试图用ResNet-101替换基础网络。

SSD在PASCAL VOC2007上使用Residual-101取得了更好的性能。RRC采用ResNet作为其预训练的基础网络,并通过提出的循环滚动卷积架构产生了具有竞争力的检测精度。然而,SSD通过将VGG-16替换为Residual-101,对于mAP仅获得1%的提升,而其检测速度从19 FPS下降到6.6 FPS,几乎下降了3倍。VGG网络在ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 2014中获得第二名。它浅薄,只有16层,是另一个广泛使用的基础网络。它的优势在于提供了精度和运行速度之间的权衡。SSD通过将VGG-16作为特征提取器与端到端网络结构中提出的多目标检测器相结合,实现了最佳的总体性能。
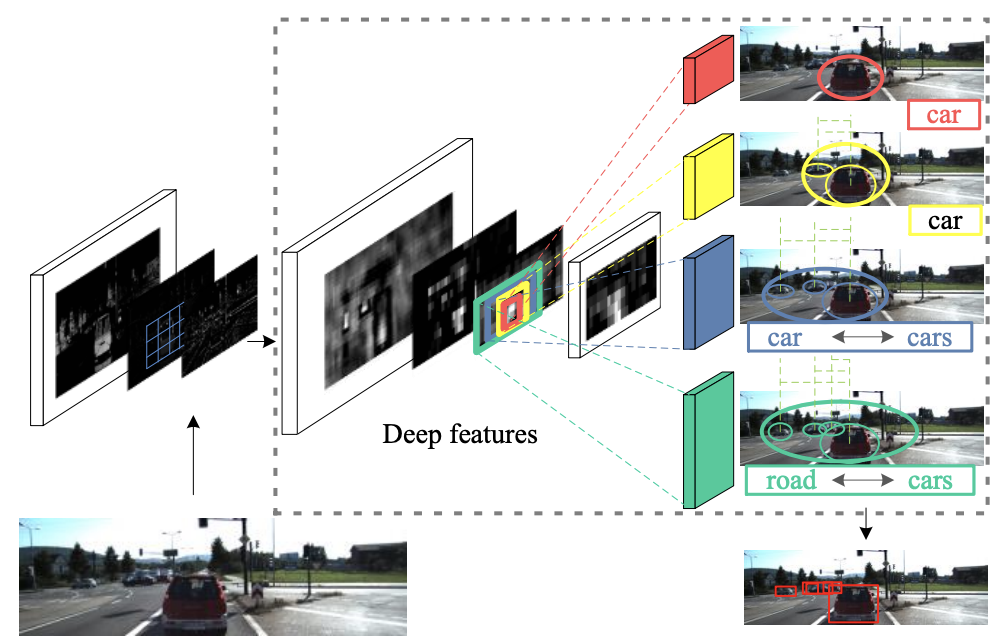
如上图所示,深度特征图上的多尺度感受野将激活对象的语义和上下文信息。红色、黄色、蓝色和绿色分量代表四种尺寸的过滤器,分别对应不同的对象表达。例如,红色的往往只对中间的红色车辆敏感,而黄色和蓝色的也可能覆盖周围的小型汽车,这是由于不同目标汽车之间相关性的语义表达。绿色的激活范围最大,它不仅可以检测所有车辆,还可以通过利用对象与其背景之间关系的语义描述来检测道路。这个提取各种语义信息的过程可以在深层实现,其中感受野能够覆盖更大的场景和深层产生的特征图,已经拥有语义表达的抽象能力。

我们发现大多数可用的经典网络都是强大的足够的特征提取,并能够提供必要的细节特征。受这些观察的启发,研究者采用迁移学习模型,并在靠近网络顶部的深层设计了一个高效的多尺度特征提取单元。提取的深层特征信息直接馈送到预测层。
研究者提出了四个inception模块,并在四个连续的深层中incept它们,用于提取上下文信息。这些模块显著扩展了各种特征表达的能力,由此实现了基于深度特征学习的多尺度目标检测器。
Attention to Deep Features
基于随机深度的ResNet通过随机dropping 层来改进深度CNN的训练,这凸显了传播过程中存在大量冗余。 有研究者实验证明,ResNet-101中的大多数梯度仅来自10到34层的深度。另一方面,基于小物体检测依赖于较早层产生的细节信息的论点,许多方法从不同的浅层中提取多尺度信息。虽然实验表明语义特征和目标的上下文也有助于小目标检测以及遮挡检测。DSSD采用反卷积层和skip connections来注入额外的上下文,从而在学习候选区域和池化特征之前增加特征图分辨率。Mask R-CNN添加了从目标的更精细空间布局中提取的掩码输出。它由深度卷积产生的小特征图提供的像素到像素对应关系解决。
3
新框架

假设:
这些特征图应该能够提供更加精确的细节特征,尤其是对于刚开始的浅层较;
转换特征图的功能应扩展到足够深的层,以便可以将目标的高级抽象语义信息构建到特征图中;
特征图应包含适当的上下文信息,以便可以准确推断出被遮挡的目标,小目标,模糊或重叠的目标并对其进行稳健的定位。
因此,浅层和深层的特征对于目标识别和定位起着必不可少的作用。为了有效地利用检测到的特征信息,应考虑另一约束条件,以防止特征被改变或覆盖。
今天内容暂时到这里,下一期我们将带领大家一起对新框架详细分析!
下面我通过一小段视频展示下多尺度深度特征学习的效果,主要基于单分支的YoloV3-Tiny网络,效果如下:

小型的篮球被检测到

科比投出的篮球被检测到

观众席的观众的领带被检测到
简单训练后,不同尺寸都是可以检测到,部分错检是因为没有该类型数据,被错检为相似目标
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
CVPR21小样本检测:蒸馏&上下文助力小样本检测(代码已开源)
又一个YOLO系列新框架!速度远远高于Yolov4(代码已开源)
ICCV2021目标检测:用图特征金字塔提升精度(附论文下载)
Pad-YoloV5:在便携终端上实时检测不再是难题
ICCV 2021:炼丹师的福音,训练更快收敛的绝佳方案(附源代码)
Yolo轻量级网络,超轻算法在各硬件可实现工业级检测效果(附源代码)
不再只有Yolo,现在轻量级检测网络层出不穷(框架解析及部署实践)
ICCV2021:阿里达摩院将Transformer应用于目标重识别,效果显著(附源代码)
人脸识别精度提升 | 基于Transformer的人脸识别(附源码)
CVPR21目标检测新框架:不再是YOLO,而是只需要一层特征(干货满满,建议收藏)
ICCV2021最佳检测之一:视频详细讲解框架及实验分析