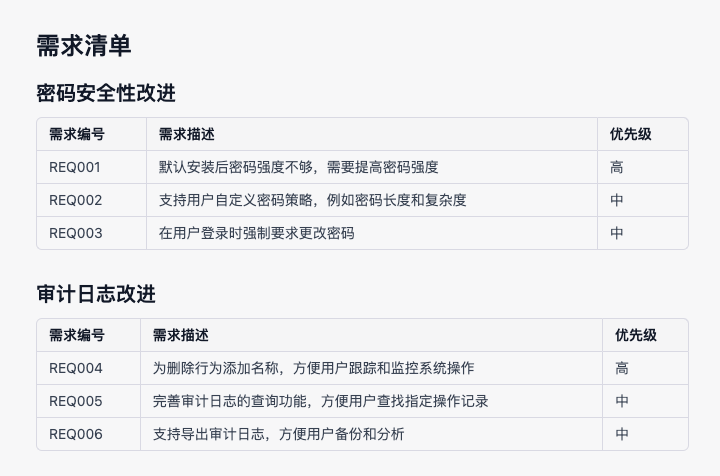
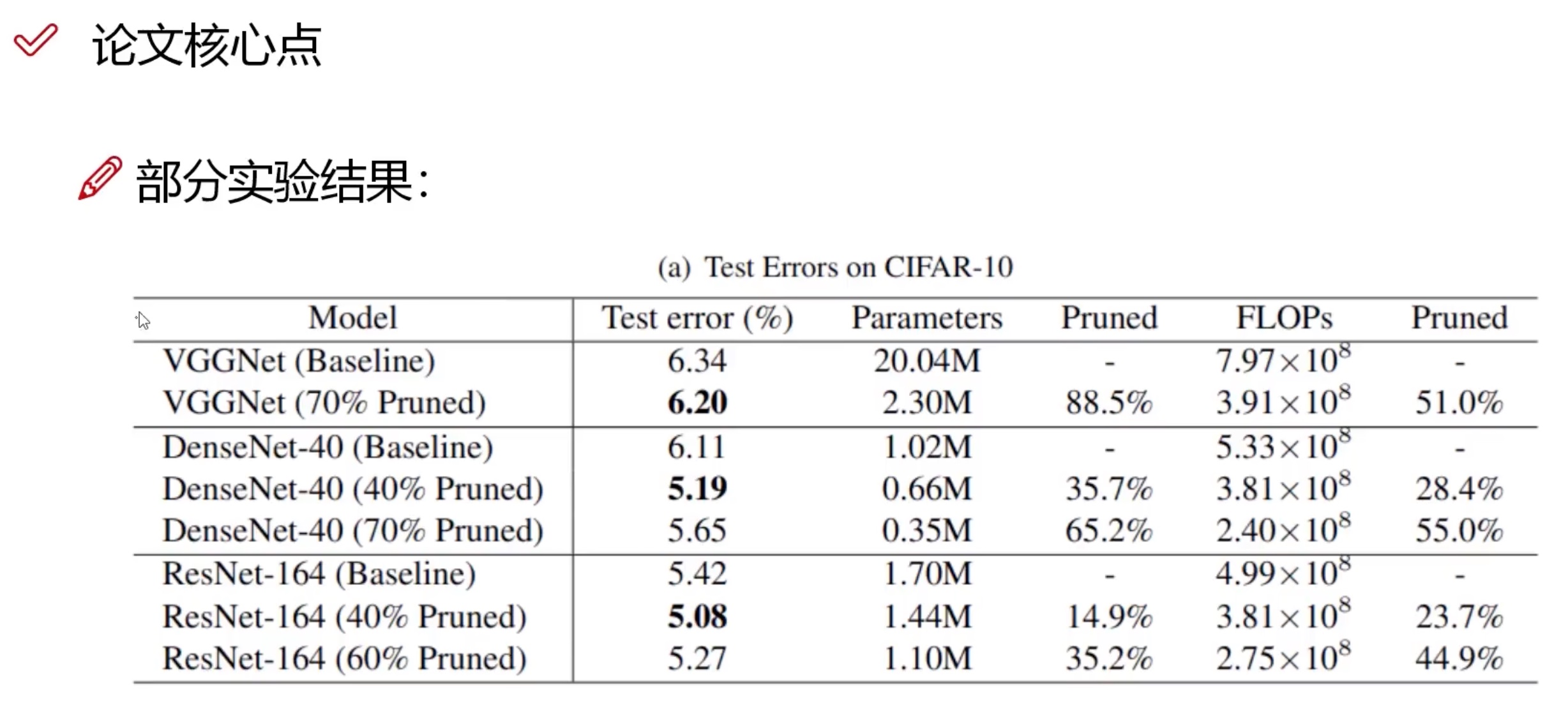
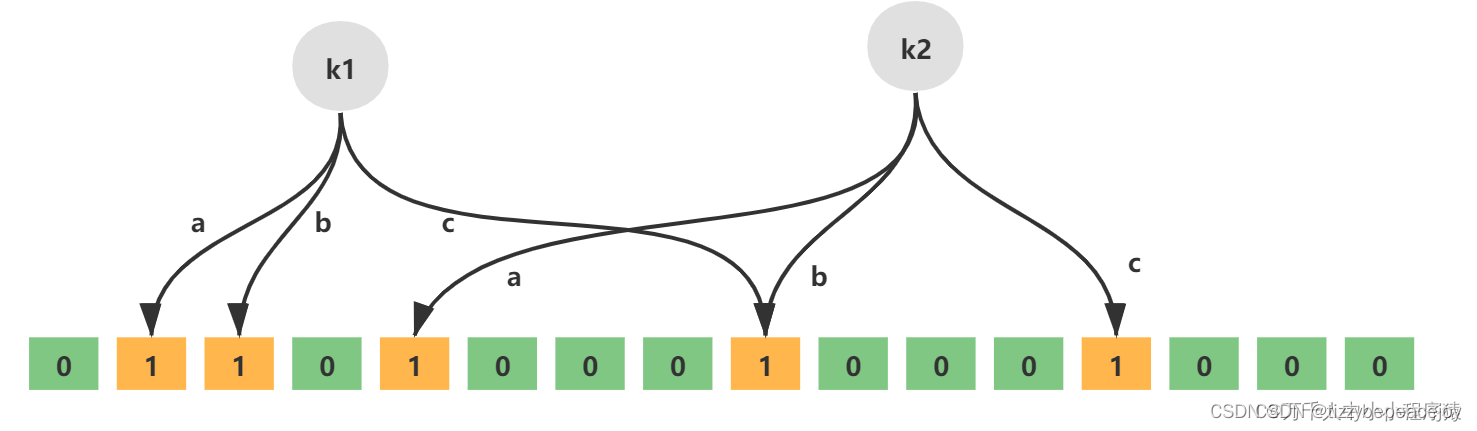
1、uboot命令体系基础
1.1、使用uboot命令
(1)uboot启动后进入命令行底下,在此输入命令并回车结束,uboot会接收这个命令并解析,然后执行。
1.2、uboot命令体系实现代码在哪里
(1)uboot命令体系的实现代码在uboot/common/下,其中若干个cmd_xxx.c、command.c、 main.c都是和命令有关的。
1.3、每个命令对应一个函数
(1)uboot中的每个命令都对应着一个函数。譬如说bootm内核启动命令对应着do_bootm函数,但我们执行bootm 30008000命令去启动内核时,背后实际调用的是do_bootm函数,这个函数就是这个命令的执行过程。
1.4、命令参数以argc&argv的方式传给函数
(1)有些uboot的命令还支持传递参数。也就是说命令背后对应的函数的参数列表中有argc和argv,命令体系会把我们执行命令时的命令+参数(md 30000000 10)以argc(3)和argv(argv[0]=md, argv[1]=30000000 argv[2]=10)的方式传递给执行这个命令的函数。
举例,以help命令为例:
help命令背后对应的函数名叫:do_help。在uboot/common/command.c的236行。
int do_help (cmd_tbl_t * cmdtp, int flag, int argc, char *argv[])
2、uboot命令解析和执行过程分析
2.1、从main_loop说起
(1)uboot启动的第二阶段的最后进入了一个死循环,死循环的循环体就是main_loop,main_loop函数在死循环中不断被执行。
(2)main_loop函数执行一遍,就是一个获取命令、解析命令、执行命令的过程。
(3)run_command函数就是用来执行命令的函数。
2.2、run_command函数详解:以下是简化版
//command.h 41~55行
struct cmd_tbl_s {
char *name; /* Command Name *///命令名字
int maxargs; /* maximum number of arguments *///命令最多可以接收的参数
int repeatable; /* autorepeat allowed? *///直接回车会自动执行上一条命令
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);//命令执行时调用的函数
char *usage; /* Usage message (short) *///使用说明(短)
#ifdef CFG_LONGHELP
char *help; /* Help message (long) *///使用说明(长)
#endif
#ifdef CONFIG_AUTO_COMPLETE
/* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
//main.c 1284~1441行
int run_command (const char *cmd, int flag)
{
cmd_tbl_t *cmdtp;
char cmdbuf[CFG_CBSIZE]; /* working copy of cmd */
char *str = cmdbuf;
char *argv[CFG_MAXARGS + 1]; /* NULL terminated */
int argc;
int repeatable = 1;
clear_ctrlc(); /* forget any previous Control C */
//crtl+c的实现
if (!cmd || !*cmd) {//cmd不指向空,并且cmd指向的地方有内容
return -1; /* empty command */
}
if (strlen(cmd) >= CFG_CBSIZE) {//CFG_CBSIZE = 256,这里的意思uboot的命令不可以超过256
puts ("## Command too long!\n");
return -1;
}
strcpy (cmdbuf, cmd);//命令复制一份到cmdbuf这个局部变量数组
/* Process separators and check for invalid
* repeatable commands
*/
//以下这个循环是在解析命令中的转义字符
while (*str) {
/*
* Find separator, or string end
* Allow simple escape of ';' by writing "\;"
*/
for (inquotes = 0, sep = str; *sep; sep++) {
if ((*sep=='\'') &&
(*(sep-1) != '\\'))
inquotes=!inquotes;
if (!inquotes &&
(*sep == ';') && /* separator */
( sep != str) && /* past string start */
(*(sep-1) != '\\')) /* and NOT escaped */
break;
}
/*
* Limit the token to data between separators
*/
token = str;
if (*sep) {
str = sep + 1; /* start of command for next pass */
*sep = '\0';
}
else
str = sep; /* no more commands for next pass */
//解析转义字符结束
/* Extract arguments */
if ((argc = parse_line (finaltoken, argv)) == 0) {
//parse_line函数把"md 30000000 10"解析成argv[0]=md, argv[1]=30000000 argv[2]=10;
rc = -1; /* no command at all */
continue;
}
/* Look up command in command table */
if ((cmdtp = find_cmd(argv[0])) == NULL) {
//find_cmd(argv[0])函数去uboot的命令集当中搜索有没有argv[0]这个命令
printf ("Unknown command '%s' - try 'help'\n", argv[0]);//没有找到命令就会打印这句
rc = -1; /* give up after bad command */
continue;
}
/* found - check max args */
if (argc > cmdtp->maxargs) {//超过命令所能接收的最大参数个数
printf ("Usage:\n%s\n", cmdtp->usage);//打印出这个命令的使用说明
rc = -1;
continue;
}
/* OK - call function to do the command */
if ((cmdtp->cmd) (cmdtp, flag, argc, argv) != 0) {//执行这个命令所对应的函数
rc = -1;
}
repeatable &= cmdtp->repeatable;
}
return rc ? rc : repeatable;
}
2.3、关键点分析
(1)控制台命令获取。在run_command函数中作为第一个参数cmd
(2)命令解析。parse_line函数把"md 30000000 10"解析成argv[0]=md, argv[1]=30000000 argv[2]=10;
(3)命令集中查找命令。find_cmd(argv[0])函数去uboot的命令集合当中搜索有没有argv[0]这个命令,
(4)执行命令。(cmdtp->cmd) (cmdtp, flag, argc, argv);最后用函数指针的方式调用执行了对应函数。
思考:关键点在于find_cmd函数如何从uboot的命令集中找到这个命令,判断这个命令是不是uboot支持的合法命令,uboot的命令集又是怎么样构成的?这些都取决于uboot的命令体系机制。
(uboot是如何完成命令的这一套设计的,命令如何去添加、存储、索引的。)
3、uboot的命令集是如何构成的
3.1、可能的构成方式
(1)数组。结构体数组,数组中每一个结构体就是一个命令的所有信息。坏处是数组的大小需要一开始就确定,不能动态添加命令来存储。
(2)链表。链表的每个节点就对应着一个命令的所有信息,所有的命令都被放在一条链表上。这样就解决了数组方式的不灵活。坏处是需要额外的内存开销(链表指针),并且链表的各种算法(遍历、插入、删除等)的代码都具有一定的时间复杂度。
(3)uboot没有使用数组和链表,而是使用了一种新的方式来实现这个功能。
3.2、命令结构体cmd_tbl_t
不管uboot以什么方式来构建命令集,都需要一个结构体来包含这个命令的所有信息。
struct cmd_tbl_s {
char name; /* Command Name */
int maxargs; /* maximum number of arguments */
int repeatable; /* autorepeat allowed? */
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);
char usage; /* Usage message (short) */
#ifdef CFG_LONGHELP
char help; /* Help message (long) */
#endif
#ifdef CONFIG_AUTO_COMPLETE /* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
typedef struct cmd_tbl_s cmd_tbl_t;
(1)name:命令名称,字符串格式。
(2)maxargs:命令最多可以接收的参数个数
(3)repeatable:指示这个命令是否可以重复执行。重复执行是uboot命令行的一种工作机制,就是直接按回车则会执行上一条执行的命令。
(4)cmd:函数指针,命令对应的函数的函数指针,将来执行这个命令的函数时使用这个函数指针来调用。
(5)usage:命令的短帮助信息。对命令的简单描述。
(6)help:命令的长帮助信息。对命令的细节信息。
(7)complete:函数指针,uboot中的命令的参数也可以实现自动补全的效果,背后是一个函数来实现的,这个函数指针就指向这里,但在uboot中一般没有使用。
总结:uboot的命令体系在工作时,一个命令对应一个cmd_tbl_t结构体的一个实例,然后uboot支持多少个命令,就需要多少个结构体实例。uboot的命令体系把这些结构体实例管理起来,当用户输入了一个命令时,uboot会去这些结构体实例中查找(查找方法和存储管理的方法有关)。如果找到则执行命令,如果未找到则提示命令未知。
3.3、uboot实现命令管理的思路
(1)每一个结构体实例构成一个命令
(2)使用链接脚本,给每个命令结构体实例添加特定段属性(用户自定义段),添加段属性后就标记着这个实例是属于我们自定义的某个段的,之后链接时链接器会将带有该段属性的所有内容都链接在一起排列(紧挨着,不会夹杂其他东西,也不会丢掉一个带有这种段属性的,但是顺序是乱序的)。相当于水果摊,将不同种类的水果放在一起,苹果放在一起,香蕉放在一起。。。,这个段属性就是起标记作用,我们给每个实例都附加一个段属性,就代表着他们是属于同一个段的。
(3)uboot第二阶段将整个uboot重定位到DDR中,那么这个段也会被加载到DDR中。加载到DDR中的uboot镜像中,带有特定段属性的这一段其实就是命令结构体的集合,有点像一个结构体数组。
(4)段的起始地址和结束地址 定义在链接脚本u-boot.lds中,决定了这些命令集的开始和结束地址。
4、uboot如何处理命令集
4.1、uboot命令结构体是如何实例化的
(1)通过一个宏 U_BOOT_CMD
这个宏定义在uboot/common/command.h中(89~101行)。
#define Struct_Section __attribute__ ((unused,section (".u_boot_cmd")))
//Struct_Section将来会被__attribute__ ((unused,section (".u_boot_cmd")))替换
#ifdef CFG_LONGHELP
#define U_BOOT_CMD(name,maxargs,rep,cmd,usage,help) \
cmd_tbl_t __u_boot_cmd_##name Struct_Section = {#name, maxargs, rep, cmd, usage, help}
/*
* cmd_tbl_t:变量类型
* __u_boot_cmd_##name:变量名,##name是gcc编译器的一种语法,这个##name将来会被宏中的name所替代
* Struct_Section:被__attribute__ ((unused,section (".u_boot_cmd")))替换,
* __attribute__这个宏是gcc编译器的一种语法,给前面的变量__u_boot_cmd_##name赋予一个段属性,
* 这里是指定这个变量属于哪个段,属于.u_boot_cmd段
*/
#else /* no long help info */
#define U_BOOT_CMD(name,maxargs,rep,cmd,usage,help) \
cmd_tbl_t __u_boot_cmd_##name Struct_Section = {#name, maxargs, rep, cmd, usage}
#endif /* CFG_LONGHELP */
举例:
U_BOOT_CMD(
version, 1, 1, do_version,
“version - print monitor version\n”,
NULL
);
这个宏替换后变成:
cmd_tbl_t u_boot_cmd_version attribute ((unused,section (“.u_boot_cmd”))) = {#name, maxargs, rep, cmd, usage, help}
总结:这个U_BOOT_CMD宏的理解,关键在于结构体变量的名字和段属性。名字使用##作为连字符,使用__attribute ((unused,section (“.u_boot_cmd”)))附加用户自定义段属性,以保证链接时将这些数据结构链接在一起排布。
(2)链接脚本 (56~58行)。
__u_boot_cmd_start = .;
.u_boot_cmd : { *(.u_boot_cmd) } #自定义了.u_boot_cmd段,这个段专门用来存放uboot的命令集
__u_boot_cmd_end = .;
4.2、find_cmd函数详解
//command.h (57~60行)
typedef struct cmd_tbl_s cmd_tbl_t;
extern cmd_tbl_t __u_boot_cmd_start;
extern cmd_tbl_t __u_boot_cmd_end;
//command.c (344~378行)
cmd_tbl_t *find_cmd (const char *cmd)
{
cmd_tbl_t *cmdtp;
cmd_tbl_t *cmdtp_temp = &__u_boot_cmd_start; /*Init value */
//__u_boot_cmd_start这个符号在uboot.lds链接脚本处定义,在command.h文件(57~60行)处使用extern声明
//这个符号的含义是:命令集的首地址
const char *p;
int len;
int n_found = 0;
/*
* Some commands allow length modifiers (like "cp.b");
* compare command name only until first dot.
*/
len = ((p = strchr(cmd, '.')) == NULL) ? strlen (cmd) : (p - cmd);
//查找,看输入的命令中是否有. , 因为有些命令是有.的, 有些则没有, 例如md.b 30000000 10
//这里是计算命令的长度, 以md.b命令为例, 如果没有. , 则是strlen(cmd) = 2; 如果有. ,则是(p - cmd) = 2。
for (cmdtp = &__u_boot_cmd_start;
cmdtp != &__u_boot_cmd_end;
cmdtp++) {
if (strncmp (cmd, cmdtp->name, len) == 0) {
//将命令结构体段中每个结构体的name属性取出与当前cmd比较,即查看这个命令是否存在
if (len == strlen (cmdtp->name))
return cmdtp; /* full match */
cmdtp_temp = cmdtp; /* abbreviated command ? */
n_found++;
}
}
if (n_found == 1) { /* exactly one match */
return cmdtp_temp;
}
return NULL; /* not found or ambiguous command */
}
(1)find_cmd函数的任务是从uboot的命令集中查找是否有某个命令。如果找到则返回这个命令结构体的指针,如果未找到返回NULL。
(2)函数的实现思路很简单,如果不考虑命令带点的情况(md.b md.w这种)就更简单了。查找命令的思路其实就是for循环遍历数组的思路,不同的是以指针增加的方式来遍历,数组中的每个元素是结构体变量类型。
4.3、U_BOOT_CMD宏详解
(1)这个宏其实就是定义了一个命令对应的结构体变量,这个变量名和宏的第一个参数有关,因此只要宏调用时传参的第一个参数不同则定义的结构体变量不会重名。
4.4、验证U_BOOT_CMD宏
验证方法:将前面的相关内容放到一个C文件,然后对这个C文件只预处理不编译(gcc test.c -E -o test.i)
test.c内容:
struct cmd_tbl_s {
char *name; /* Command Name *///命令名字
int maxargs; /* maximum number of arguments *///命令最多可以接收的参数
int repeatable; /* autorepeat allowed? *///直接回车会自动执行上一条命令
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);//命令执行时调用的函数
char *usage; /* Usage message (short) *///使用说明(短)
#ifdef CFG_LONGHELP
char *help; /* Help message (long) *///使用说明(长)
#endif
#ifdef CONFIG_AUTO_COMPLETE
/* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
typedef struct cmd_tbl_s cmd_tbl_t;
#define Struct_Section __attribute__ ((unused,section (".u_boot_cmd")))
#define U_BOOT_CMD(name,maxargs,rep,cmd,usage,help) \
cmd_tbl_t __u_boot_cmd_##name Struct_Section = {#name, maxargs, rep, cmd, usage, help}
int
do_version (cmd_tbl_t *cmdtp, int flag, int argc, char *argv[])
{
char version_string[] = "test";
printf ("\n%s\n", version_string);
return 0;
}
//对命令的结构体的填充使用了一个宏
U_BOOT_CMD(
version, 1, 1, do_version,
"version - print monitor version\n",
NULL
);
int main()
{
return 0;
}
生成的test.i内容:
struct cmd_tbl_s {
char *name; /* Command Name *///命令名字
int maxargs; /* maximum number of arguments *///命令最多可以接收的参数
int repeatable; /* autorepeat allowed? *///直接回车会自动执行上一条命令
/* Implementation function */
int (*cmd)(struct cmd_tbl_s *, int, int, char *[]);//命令执行时调用的函数
char *usage; /* Usage message (short) *///使用说明(短)
#ifdef CFG_LONGHELP
char *help; /* Help message (long) *///使用说明(长)
#endif
#ifdef CONFIG_AUTO_COMPLETE
/* do auto completion on the arguments */
int (*complete)(int argc, char *argv[], char last_char, int maxv, char *cmdv[]);
#endif
};
typedef struct cmd_tbl_s cmd_tbl_t;
#define Struct_Section __attribute__ ((unused,section (".u_boot_cmd")))
#define U_BOOT_CMD(name,maxargs,rep,cmd,usage,help) \
cmd_tbl_t __u_boot_cmd_##name Struct_Section = {#name, maxargs, rep, cmd, usage, help}
int
do_version (cmd_tbl_t *cmdtp, int flag, int argc, char *argv[])
{
char version_string[] = "test";
printf ("\n%s\n", version_string);
return 0;
}
//对命令的结构体的填充使用了一个宏
U_BOOT_CMD(
version, 1, 1, do_version,
"version - print monitor version\n",
NULL
);
int main()
{
return 0;
}
5、在uboot中增加自定义命令
5.1、在已有的c文件中直接添加命令
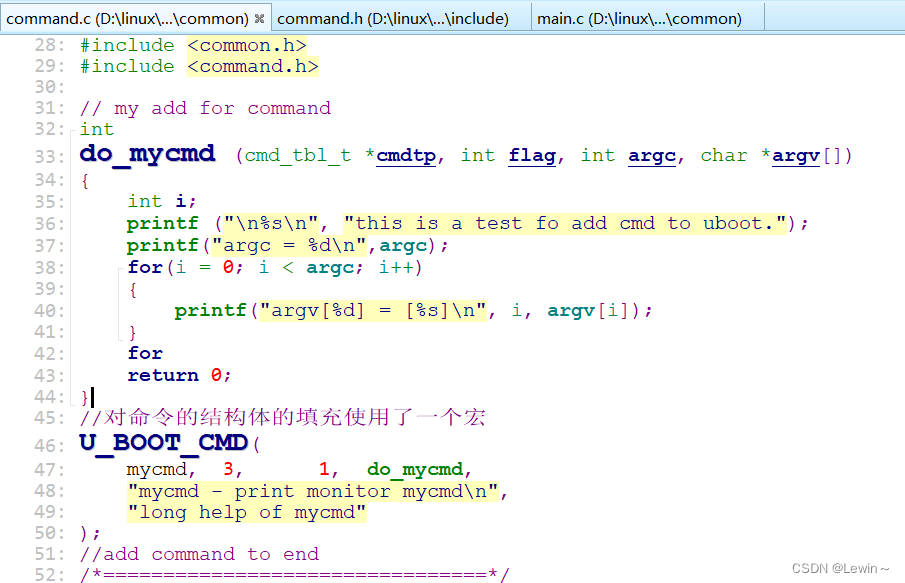
(1)在uboot/common/command.c中添加一个命令,叫:mycmd
(2)在已有的.c文件中添加命令比较简单,直接使用U_BOOT_CMD宏即可添加命令,并给命令提供一个do_xxx的对应的函数就完成了。
(3)添加完成后要重新编译工程(make distclean; make x210_sd_config; make),然后烧录uboot进开发板去使用这个命令。
(4)还可以在函数中使用argc和argv来验证命令行传参。
以下是uboot命令行下验证我们添加自定义命令是否成功
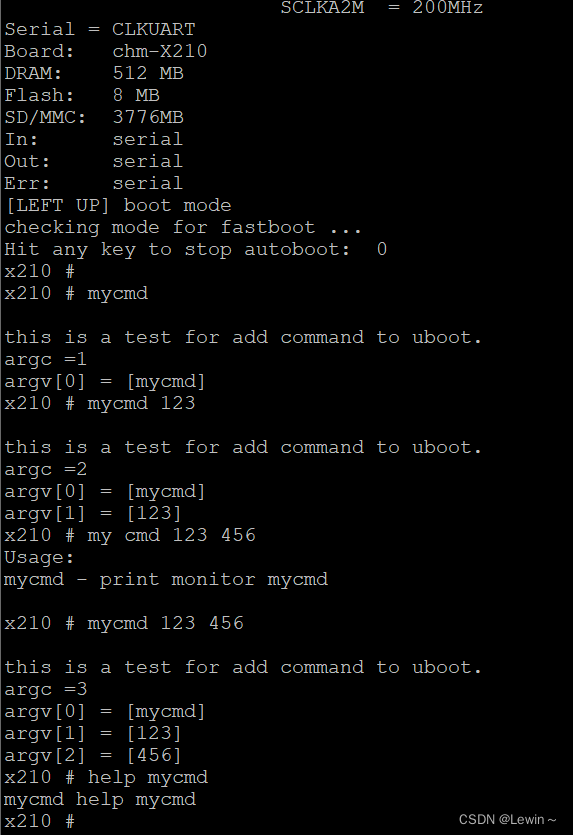
5.2、自建一个c文件并添加命令
(1)在uboot/common目录下新建一个命令文件,叫cmd_chm.c(对应的命令名就叫chm,对应的函数就叫do_chm函数),然后在c文件中添加命令对应的U_BOOT_CMD宏和函数。注意头文件包含不要漏掉。

(2)在uboot/common/Makefile中添加上cmd_chm.o,目的是让Make在编译时能否把cmd_chm.c编译链接进去。
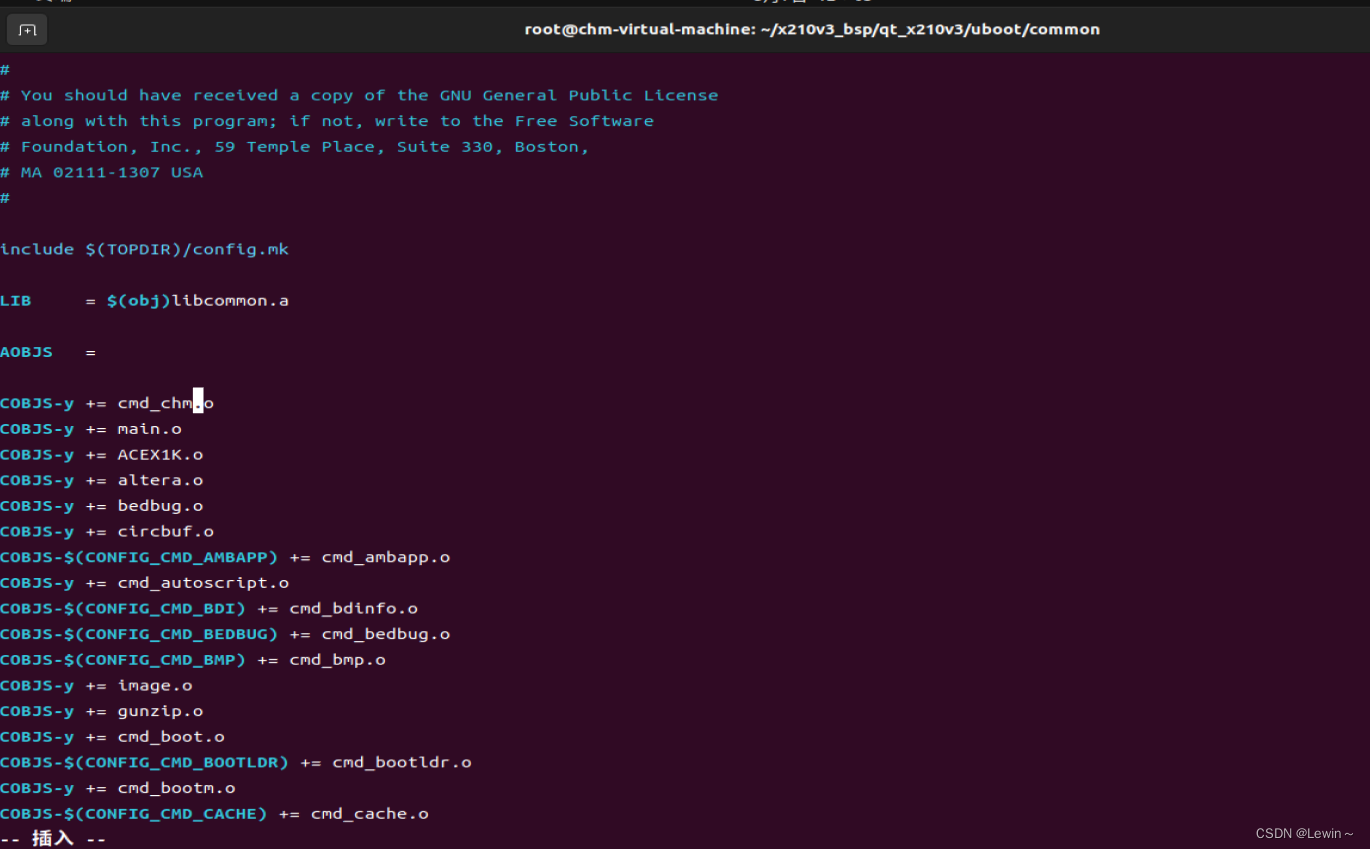
(3)重新编译烧录。重新编译步骤是:make distclean; make x210_sd_config; make
5.3、心得体会:uboot命令体系的优点
(1)uboot的命令体系本身稍微复杂,但是他写好之后就不用动了。我们后面在移植uboot时也不会去动uboot的命令体系。我们最多就是向uboot中去添加命令,向uboot中添加命令是非常简单的。



![[CF复盘] Codeforces Round 871 (Div. 4)20230506](https://img-blog.csdnimg.cn/fc0b0aa844344689bd7f9a5354d45717.png)