时序预测 | MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元时间序列预测
目录
- 时序预测 | MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元时间序列预测
- 效果一览
- 基本介绍
- 模型描述
- 程序设计
- 参考资料
效果一览







基本介绍
基于贝叶斯(bayes)优化卷积神经网络-门控循环单元(CNN-GRU)时间序列预测,BO-CNN-GRU/Bayes-CNN-GRU时间序列预测模型。基于贝叶斯算法(bayes)优化卷积神经网络-门控循环单元(CNN-GRU)时间序列预测,单列数据集.
1.优化参数为:学习率,隐含层节点,正则化参数。
2.评价指标包括:R2、MAE、MSE、RMSE和MAPE等,方便学习和替换数据。
3.运行环境matlab2020b及以上。
模型描述
-
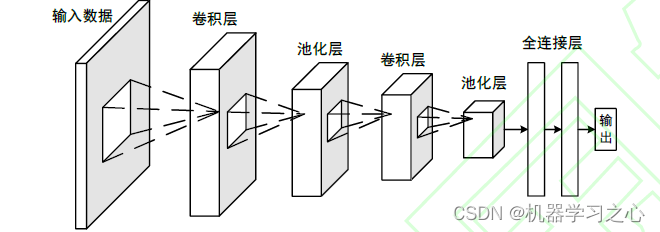
CNN 是通过模仿生物视觉感知机制构建而成,能够进行有监督学习和无监督学习。隐含层的卷积核参数共享以及层间连接的稀疏性使得CNN 能够以较小的计算量从高维数据中提取深层次局部特征,并通过卷积层和池化层获得有效的表示。CNN 网络的结构包含两个卷积层和一个展平操作,每个卷积层包含一个卷积操作和一个池化操作。第二次池化操作后,再利用全连接层将高维数据展平为一维数据,从而更加方便的对数据进行处理。
-
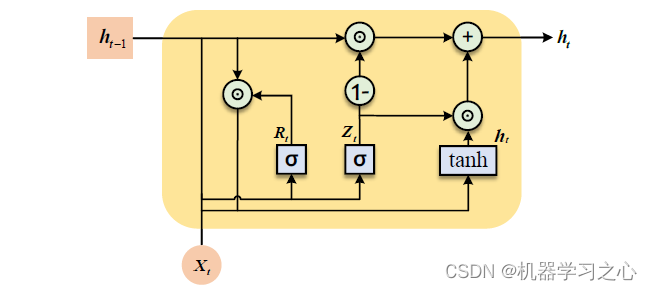
当时间步数较大时,RNN 的历史梯度信息无法一直维持在一个合理的范围内,因此梯度衰减或爆炸几乎是不可避免的,从而导致RNN 将很难从长距离序列中捕捉到有效信息。LSTM 作为一种特殊的RNN,它的提出很好的解决了RNN 中梯度消失的问题。而GRU 则是在LSTM 的基础上提出的,其结构更简单,参数更少,训练时间短,训练速度也比LSTM更快。
-
为使模型具有自动提取特征的功能,一般采用深度学习的方法来进行构建。其中,CNN 在提取特征这方面能力较强,它通常依靠卷积核来对特征进行提取。但是,卷积核的存在又限制了CNN 在处理时间序列数据时的长期依赖性问题。
-
在这项研究中,GRU 的引入可以有效地解决这个问题,并且我们可以捕获时间序列前后的依赖关系。另一方面, GRU 模块的目的是捕获长期依赖关系,它可以通过存储单元长时间学习历史数据中的有用信息,无用的信息将被遗忘门遗忘。另外,直接用原始特征进行处理,会极大的占用模型的算力,从而降低模型的预测精度,CNN-GRU模型结合了CNN和GRU的优点。
-
通常,在模型训练过程中需要对超参数进行优化,为模型选择一组最优的超参数,以提高预测的性能和有效性。 凭经验设置超参数会使最终确定的模型超参数组合不一定是最优的,这会影响模型网络的拟合程度及其对测试数据的泛化能力。
-
伪代码

-
通过调整优化算法调整模型参数,学习重复率和贝叶斯优化超参数来调整模型参数。
程序设计
- 完整程序和数据获取方式1:私信博主,同等价值程序兑换;
- 完整程序和数据下载方式2(资源处直接下载):MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元时间序列预测
- 完整程序和数据下载方式3(订阅《组合优化》专栏,同时获取《组合优化》专栏收录的所有程序,数据订阅后私信我获取):MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元时间序列预测
%% 优化算法参数设置
%参数取值上界(学习率,隐藏层节点,正则化系数)
%% 贝叶斯优化参数范围
optimVars = [
optimizableVariable('NumOfUnits', [10, 50], 'Type', 'integer')
optimizableVariable('InitialLearnRate', [1e-3, 1], 'Transform', 'log')
optimizableVariable('L2Regularization', [1e-10, 1e-2], 'Transform', 'log')];
%% 贝叶斯优化网络参数
BayesObject = bayesopt(fitness, optimVars, ... % 优化函数,和参数范围
'MaxTime', Inf, ... % 优化时间(不限制)
'IsObjectiveDeterministic', false, ...
'MaxObjectiveEvaluations', 10, ... % 最大迭代次数
'Verbose', 1, ... % 显示优化过程
'UseParallel', false);
%% 创建混合CNN-GRU网络架构
% 创建"CNN-GRU"模型
layers = [...
% 输入特征
sequenceInputLayer([numFeatures 1 1],'Name','input')
sequenceFoldingLayer('Name','fold')
% CNN特征提取
convolution2dLayer([FiltZise 1],32,'Padding','same','WeightsInitializer','he','Name','conv','DilationFactor',1);
batchNormalizationLayer('Name','bn')
eluLayer('Name','elu')
averagePooling2dLayer(1,'Stride',FiltZise,'Name','pool1')
% 展开层
sequenceUnfoldingLayer('Name','unfold')
% 平滑层
flattenLayer('Name','flatten')
% GRU特征学习
gruLayer(50,'Name','gru1','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
% GRU输出
gruLayer(NumOfUnits,'OutputMode',"last",'Name','bil4','RecurrentWeightsInitializer','He','InputWeightsInitializer','He')
dropoutLayer(0.25,'Name','drop3')
% 全连接层
fullyConnectedLayer(numResponses,'Name','fc')
regressionLayer('Name','output') ];
layers = layerGraph(layers);
layers = connectLayers(layers,'fold/miniBatchSize','unfold/miniBatchSize');
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229










![[创新工具和方法论]-01- DOE课程基础知识](https://img-blog.csdnimg.cn/img_convert/2be39d9d93d4d74633a5f19aaeff8b99.jpeg)