手写数字识别
MNIST数据集包含了一系列的手写数字图像,包括0到9的数字。每张图像都是灰度图像,尺寸为28x28像素。数据集共包含60000张训练图像和10000张测试图像。
MNIST数据集的目标是通过训练一个模型,使其能够正确地识别这些手写数字图像的标签。每张图像都有对应的标签,表示图像中显示的数字。因此,MNIST数据集是一个经典的监督学习问题,其中输入是图像,输出是对应的数字标签。

图 1 MNIST 数据集图像示例
本次实验,在跑完老师提供的 PaddlePaddle 代码的基础上,采用PaddlePaddle环境进一步训练模型,利用PaddlePaddle的可视化插件VisualDL进行训练模型过程的可视化。
另附代码见附录和.ipynb 文件。
本次实验,我主要比较了几种不同的经典神经网络在 MNIST数据集上的表现,包括经典模型如MLP,LeNet , AlexNet,VGGNet和ResNet。其中MLP,LeNet使用1*28*28图像,因为AlexNet经过卷积等操作之后的图像特征输出比较小,如果图像大小为28*28训练会发生报错return 0,因此AlexNet,VGGNet和ResNet三个模型使用1*224*224图像
-
-
- MLP
-
其中,MLP的网络设置如下:

 |
图 2 多层感知机网络结构
定义了三个全连接(线性)层 (fc1、fc2 和 fc3)。
输入张量 x 沿第二个轴展平。将展平后的输入通过第一个线性层 (fc1)。应用 ReLU 激活函数。将结果通过第二个线性层 (fc2)。再次应用 ReLU 激活函数。将结果通过第三个线性层 (fc3)。最后,在轴 1 上应用 softmax 激活函数,获得输出概率。
这个 MLP 架构包括两个带有 ReLU 激活的线性层,最后使用 softmax 激活进行多类别分类。
-
-
- LeNet
-
LeNet 是由 Yann Lecun 和他的同事于 1998 年提出的卷积神经网络(Convolutional Neural Network,CNN)架构。它是深度学习领域中的开创性网络之一,被广泛应用于手写字符识别等任务。以下是 LeNet 的一般介绍:
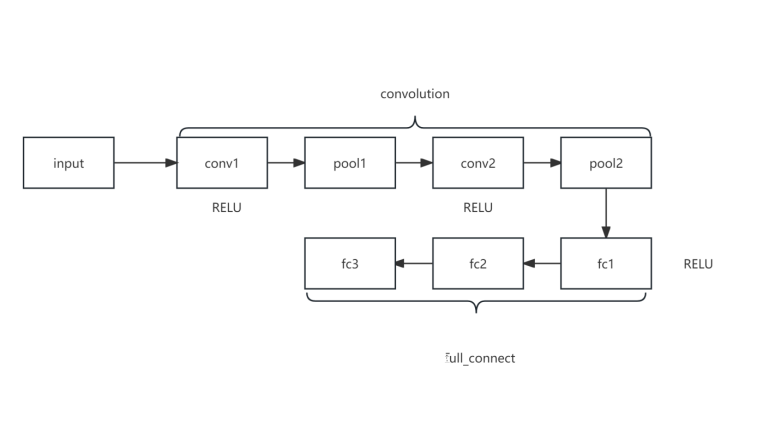

图 3 LeNet 结构
LeNet 结构:
LeNet 主要包含两个部分:卷积层和全连接层。
1.卷积层部分:
- 第一个卷积层 (self.conv1):输入通道数为1(因为手写数字识别数据集是单通道图像),输出通道数为6,卷积核大小为5x5,步长为1。接着应用ReLU激活函数。
- 第一个池化层 (self.pool1):使用最大池化操作,池化核大小为2x2,步长为2。
- 第二个卷积层 (self.conv2):输入通道数为6,输出通道数为16,卷积核大小为5x5,步长为1。接着应用ReLU激活函数。
- 第二个池化层 (self.pool2):使用最大池化操作,池化核大小为2x2,步长为2。
2.全连接层部分:
- 全连接层1 (self.fc1):输入特征数为256(经过两次池化后的图像大小),输出特征数为256。接着应用ReLU激活函数。
- 全连接层2 (self.fc2):输入特征数为256,输出特征数为84。接着应用ReLU激活函数。
- 全连接层3 (self.fc3):输入特征数为84,输出特征数为10(对应10个分类类别)。
关键点和创新:
1. 卷积和下采样: LeNet 首次引入了卷积操作和下采样(池化)操作,通过这些操作有效地减小了网络的参数数量。
2. 非线性激活函数:使用ReLU激活函数引入了非线性映射,增强了网络的表示能力。
3. 层次结构:LeNet 显示了通过层次结构构建深度网络的可行性,为后续深度学习模型奠定了基础。
尽管 LeNet 本身在今天的大规模图像分类任务中可能显得较为简单,但它为卷积神经网络的发展奠定了基础,为后来更深层次的网络(如 AlexNet、VGG、ResNet 等)的设计提供了灵感。
-
-
- AlexNet
-
AlexNet是一种深度卷积神经网络(CNN),由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出。它在ImageNet Large Scale Visual Recognition Challenge(ImageNet ILSVRC)比赛中取得了显著的突破,成为深度学习在计算机视觉领域的重要里程碑。
其网络结构如下:


图 4 AlexNet 网络结构
同时,在本实验中输入图像尺寸为 1*224*224 。
以下是AlexNet的主要特点和架构:
- 深度:AlexNet是一个相对较深的神经网络,它有8个可训练的卷积层和3个全连接层。在当时,它是迄今为止最深的神经网络之一。
- 卷积层:AlexNet的前5个层是卷积层,其中,前两个卷积层具有较大的卷积核尺寸(11x11和5x5),并且采用了步长为4和2的较大步幅。这些卷积层能够提取出更高级的特征。
- 激活函数:AlexNet使用了修正线性单元(ReLU)作为激活函数,这在当时是一种比较新颖的选择。ReLU函数能够有效地缓解梯度消失问题,并加速训练过程。
- 池化层:在卷积层之后,AlexNet使用了最大池化层来降低特征图的空间维度,减少模型的参数量,并提高模型的鲁棒性。
- 局部响应归一化(LRN):在卷积层和池化层之间,AlexNet引入了LRN层,用于增强模型的泛化能力。LRN层对局部神经元的活动做归一化,通过抑制相邻神经元的响应来增强更稀疏的特征。
- 全连接层:在卷积层之后,AlexNet有3个全连接层,其中最后一个全连接层是用于分类的输出层。全连接层具有大量的参数,能够捕捉高层次的语义特征。
- Dropout:为了减少过拟合,AlexNet在全连接层中引入了Dropout技术。Dropout通过随机丢弃部分神经元的输出来防止过拟合,从而提高模型的泛化能力。
- 分类任务:AlexNet最初是设计用于ImageNet ILSVRC比赛的分类任务,其中包含1000个不同类别的图像。它的最后一个全连接层输出1000维的向量,表示不同类别的概率分布。
总体而言,AlexNet通过引入深度、大型卷积核、ReLU激活函数、池化层、LRN层和Dropout技术等关键组件,极大地推动了深度学习在计算机视觉领域的发展,并在ImageNet ILSVRC比赛中取得了显著的突破。它的成功为后续的深度神经网络模型奠定了基础,对现代深度学习的发展产生了重要影响。
-
-
- VGGNet
-
VGGNet是一种深度卷积神经网络,由牛津大学的研究团队于2014年提出。它在ImageNet图像分类挑战赛中取得了出色的成绩,并成为卷积神经网络设计中的重要里程碑之一。VGGNet的主要贡献在于通过增加网络的深度来提高模型性能,并将深度和宽度作为关键设计元素。
其网络结构如下:

图 5 VGGNet 网络结构
以下是VGGNet的主要特点和设计原理:
1. 网络结构:VGGNet的整体结构非常简单和规整,它由多个卷积层和池化层交替堆叠而成,最后是几个全连接层。VGGNet的核心是使用了非常小的3x3卷积核,以较小的步幅进行卷积操作。通过堆叠多个卷积层,VGGNet可以达到比较大的感受野,从而能够捕捉到更全局的图像特征。
2. 深度和宽度:VGGNet以其深度和宽度的设计而闻名。它引入了不同层数和参数量的变体,其中最著名的是VGG16和VGG19。VGG16具有16个卷积层(包括13个卷积层和3个全连接层),VGG19更进一步,具有19个卷积层(包括16个卷积层和3个全连接层)。这种深度和宽度的设计使得VGGNet能够更好地捕捉图像中的细节和抽象特征。
3. 小卷积核:VGGNet采用了较小的3x3卷积核,这是一项重要的设计选择。通过使用小卷积核,VGGNet可以增加网络的深度,减少参数数量,并且具有更强的非线性表达能力。多个3x3卷积层的堆叠等效于一个更大感受野的卷积层,但参数量更少。
4. 池化层:VGGNet使用了最大池化层来减小特征图的空间大小。池化层有助于减少特征图的空间维度,提取更为鲁棒的特征,并且在一定程度上具有平移不变性。
尽管VGGNet相对于其他模型而言较为简单,但它在计算机视觉任务中表现出色,并为后续更深层次和复杂的卷积神经网络的发展奠定了基础。本次采用VGG16。
-
-
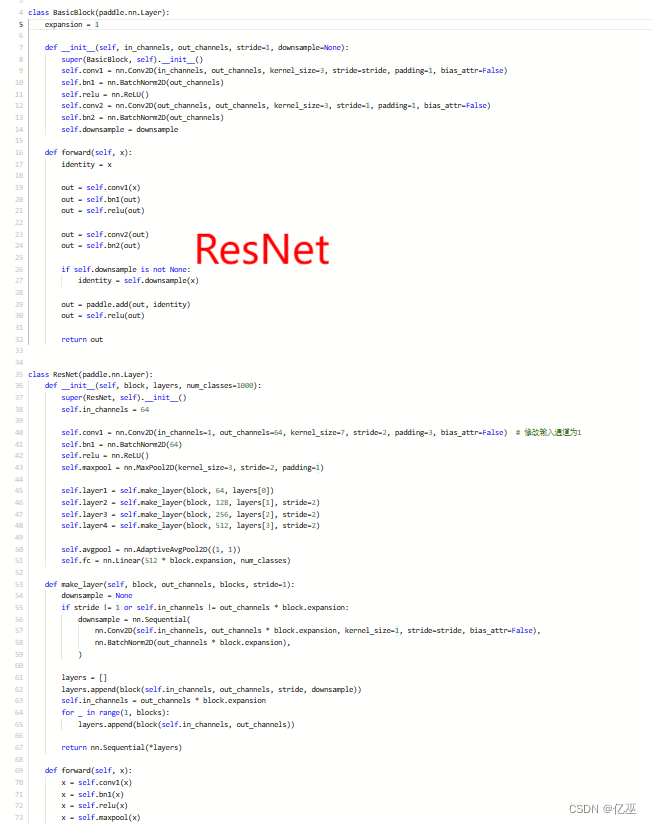
- ResNet
-
ResNet(Residual Network)是一种深度卷积神经网络架构,由微软研究院的研究团队于2015年提出。它在深度学习领域取得了巨大的成功,并成为许多计算机视觉任务的标准模型之一。ResNet的关键创新是引入了残差连接(residual connections),允许网络在训练过程中更轻松地学习到非常深的层次。
其网络结构如下:

图 6 Resnet-18网络结构
以下是ResNet的主要特点和设计原理:
1. 残差连接:残差连接是ResNet的核心概念。传统的卷积神经网络是通过堆叠多个卷积层构建深层网络,但随着网络层数的增加,出现了梯度消失和梯度爆炸等问题。为了解决这些问题,ResNet引入了跳跃连接(skip connections)或快捷连接(shortcut connections)。残差连接允许网络直接将输入信号绕过一个或多个卷积层,并将其与后续层的输出相加。这样,网络可以更轻松地学习到残差(Residual)信息,从而使得深层网络的训练更加容易。
2. 深度和宽度:ResNet的设计思想是通过增加网络的深度来提高性能。它以层的数量作为网络的关键指标。ResNet的变体包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152,其中数字表示网络的层数。较深的ResNet模型通常具有更好的性能,但也需要更多的计算资源和训练时间。
3. 卷积层堆叠:ResNet在每个卷积层堆叠中使用了相同的基本模块,称为残差块(Residual Block)。每个残差块由两个或三个卷积层组成,其中包括一个1x1卷积层用于降维和恢复维度,以及一个3x3卷积层用于特征提取。在ResNet-50及更深的模型中,还引入了一个额外的1x1卷积层用于进一步减少特征图的维度。
4. 全局平均池化和全连接层:在ResNet的最后,通常使用全局平均池化层将特征图转换为向量表示,然后使用全连接层进行分类或回归。全局平均池化层有助于减少特征图的空间维度,并保留最重要的特征。
ResNet以其深度、残差连接和优秀的性能在计算机视觉任务中获得了广泛的应用。它在图像分类、目标检测、语义分割等任务上取得了许多优秀的结果,并为后续深度神经网络的设计和发展提供了重要的启示。因restnet变体数字越大,网络层数越多,本次实验采用ResNet-18进行一个简单尝试,后续使用更深网络层进行探究。
2.1 准备数据

2.2 搭建网络
本次实验基于 PaddlePaddle搭建了MLP,LeNet , AlexNet,VGGNet和ResNet,其设计和改良如 1.3 所介绍,其
详细代码如下:
 |
 |
 |
 |
 |
 |
2.3 训练配置
接下来,定义训练函数
初始参数如下:
| Epochs | Batch_size | verbose | Log_freq | Learning_rate |
| 20 | 64 | 1 | 10 | 0.0005 |
 |
其中,利用 Adam优化器,更新模型的参数以最小化损失函数,使用交叉熵损失函数,利用 loss 和准确率对于模型进行评价。
训练方式如下:
 |
接下来,通过`paddle.callbacks.VisualDL(log_dir=model_name)`创建一个VisualDL日志写入器对象,其中`log_dir`参数指定了日志写入的目录。
然后,创建了MLP模型的实例,并将其打印输出。
接着,通过`paddle.Model(model)`将MLP模型封装到`paddle.Model`对象中,这样可以使用`paddle.Model`提供的训练和评估方法。
最后,调用了一个名为`train`的函数,并将模型和模型名称作为参数传递给该函数进行模型训练。
2.4 超参调节
为进一步得到更好的模型结果,且由于本数据集没有设置验证集,因此利用给定参数空间搜索在测试集上进行超参数的调节,其中,参数调节范围如下表所示:
因搜索最优参数耗时较长,且通过初次训练结果发现,在epoch>10以后的acc增幅较小,MLP,LeNet 两个模型都固定epochs=10,超参数范围如下所示:
'learning_rate': [0.001, 0.005, 0.01, 0.05]
'batch_size': [ 128, 256]
搜索代码如下:
 |
 |
对于每个模型搜索得到的最优参数为:
| 模型 | learning_rate | batch_size |
| MLP | 0.001 | 128 |
| LeNet | 0.001 | 256 |
对于学习率0.01和0.05模型的结果都比较差,经思考觉得是因为学习率过大,会产生振荡,导致训练达不到好的效果。
3.1 模型准确率比较
接下来,我比较了各模型在 echos=20 时的模型的表现
| 模型 | Loss | Train_acc | Test_acc |
| MLP | 1.4612 | 0.9835 | 0.9726 |
| LeNet | 1.4611 | 0.9955 | 0.9877 |
| AlexNet | 2.3097e-07 | 0.9959 | 0.9908 |
| VGGNet16 | 0.0061 | 0.9991 | 0.9937 |
| resnet18 | 1.5153e-05 | 0.9987 | 0.9935 |
同时,可视化模型表现如以下图:
 |
 |
 |
图 7 训练过程图
横坐标为step
从表格上的这些指标来看,不同模型在测试集上的表现相对较好,准确率都在较高的水平。其中,VGGNet16和ResNet18模型的测试准确率最高,分别达到了0.9937和0.9935。从训练过程图看,AlexNet,resnet18在刚开始训练的时候loss就急剧下降,acc也是迅速达到一个好的效果。不用怎么调参便能达到一个很好的效果。MLP和LeNet两模型的训练速度很快,但acc收敛速度慢,并且loss在较少的epoch中很难达到1以下。
3.2 内部数据集测试
预测结果标签与测试集标签吻合
 |
3.3 泛化能力测试
为了进一步比较模型的泛化能力,我测试了新添加的手写数字图片经过模型验证的结果。新
手写数字图片经过了灰度化处理,并 resize 到 28*28 的大小,通过已训练好的模型进行测试。测试内容包括自己手写数字照片、网上手写数字照片,经验证,模型可以正确输出结果。
 |
 |
在本次实验中,我完整的实现了MLP,LeNet , AlexNet,VGGNet和ResNet 的训练过程,并使用了自己制作的新手写数字图片进行测试。这让我对于深度学习高层 Api 的使用有了更深入的理解。同 时,在本次实验中我经过了很久的调参和反复的验证,这让我更加深入的理解了过拟合、正 则化等概念和参数增多在深度学习中的影响。最终,也通过自己写的代码在测试集上达到了 0.9935 的准确率。总得来说,本次实验让我收获颇多。



![[蓝桥杯 2017 国 C] 合根植物](https://img-blog.csdnimg.cn/img_convert/ad00c0180cf6d423af5e5f0c7b97a1a5.png)