spaCy 中文教程:自然语言处理核心操作指南(进阶)
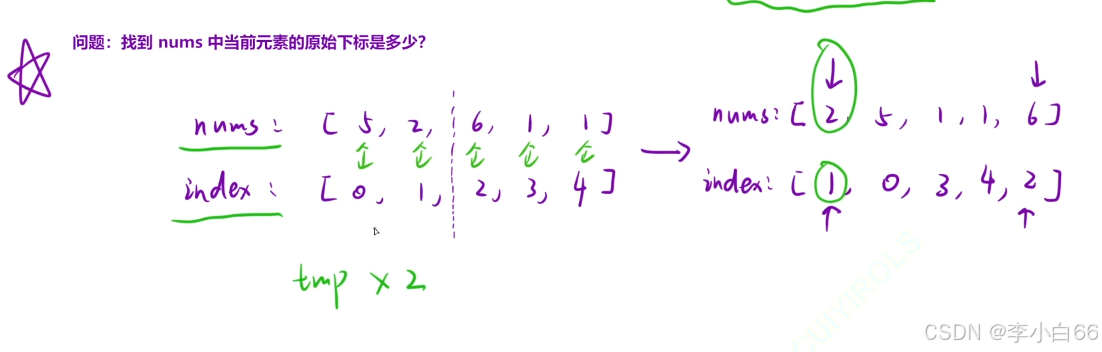
1. 识别文本中带有“百分号”的数字
import spacy
# 创建一个空的英文语言模型
nlp = spacy.blank("en")
# 处理输入文本
doc = nlp("In 1990, more than 60% of people in East Asia were in extreme poverty. Now less than 4% are.")
# 遍历文档中的每个词
for token in doc:
if token.like_num: # 判断该词是否看起来像一个数字
# 获取下一个词
next_token = doc[token.i + 1]
if next_token.text == "%":
print("找到百分比:", token.text)
📌 2. 词性标注与依存关系分析
import spacy
# 加载英文小模型
nlp = spacy.load("en_core_web_sm")
# 输入文本
doc = nlp("She ate the pizza")
# 打印每个词的词性标签
for token in doc:
print(token.text, token.pos_, token.pos)
# 输出依存结构信息(包括该词依赖于哪个词)
for token in doc:
print(token.text, token.pos_, token.dep_, token.head.text)
📌 3. 命名实体识别(NER)
# 输出识别出来的命名实体及其类型
for ent in doc.ents:
print(ent.text, ent.label_)
📌 4. 比较不同模型之间的差异(词性与依存关系)
# 假设 doc_small 和 doc_medium 是使用不同模型处理的结果
for i in range(len(doc_small)):
print("词:", doc_small[i])
if doc_small[i].pos_ != doc_medium[i].pos_:
print("词性不同:", doc_small[i].pos_, doc_medium[i].pos_)
if doc_small[i].dep_ != doc_medium[i].dep_:
print("依存关系不同:", doc_small[i].dep_, doc_medium[i].dep_)
📌 5. 使用 Matcher 匹配自定义文本模式
示例一:识别“购买”某物的句子结构
from spacy.matcher import Matcher
import spacy
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
# 定义匹配“购买某物”的结构
pattern = [{"LEMMA": "buy"}, {"POS": "DET", "OP": "?"}, {"POS": "NOUN"}]
matcher.add("BUY_ITEM", [pattern])
doc = nlp("I bought a smartphone. Now I'm buying apps.")
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print("匹配结果:", span.text)
示例二:识别“love + 名词”的组合
pattern = [{"LEMMA": "love", "POS": "VERB"}, {"POS": "NOUN"}]
matcher.add("LOVE_PATTERN", [pattern])
doc = nlp("I loved vanilla but now I love chocolate more.")
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print("匹配:", span.text)
示例三:匹配 “COLORS10”, “COLORS11” 等结构
text = """After the iOS update you won’t notice big changes. Most of iOS 11's layout remains the same as iOS 10."""
matcher = Matcher(nlp.vocab)
pattern = [{"TEXT": "COLORS"}, {"IS_DIGIT": True}]
matcher.add("IOS_VERSION", [pattern])
doc = nlp(text)
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print("识别出的版本:", span.text)
示例四:识别“download + 专有名词”的结构
text = """I downloaded Fortnite on my laptop. Should I download WinZip too?"""
pattern = [{"LEMMA": "download"}, {"POS": "PROPN"}]
matcher.add("DOWNLOAD_PATTERN", [pattern])
doc = nlp(text)
matches = matcher(doc)
for match_id, start, end in matches:
print("下载内容:", doc[start:end].text)
示例五:匹配“形容词 + 名词”结构
text = "Features include a beautiful design, smart search, and voice responses."
pattern = [{"POS": "ADJ"}, {"POS": "NOUN"}, {"POS": "NOUN", "OP": "?"}]
matcher.add("ADJ_NOUN", [pattern])
doc = nlp(text)
matches = matcher(doc)
for match_id, start, end in matches:
print("形容词短语:", doc[start:end].text)
📌 6. 使用 Vocab 和 Lexeme 操作词汇表
nlp = spacy.blank("en")
# 将字符串转换为 hash 值
word_hash = nlp.vocab.strings["hat"]
print("字符串 'hat' 的哈希值为:", word_hash)
# 再将 hash 值反向转换为字符串
word_text = nlp.vocab.strings[word_hash]
print("哈希反查:", word_text)
# 获取词汇的详细属性
lexeme = nlp.vocab["tea"]
print(lexeme.text, lexeme.orth, lexeme.is_alpha)
✨ 7. 手动创建 Doc 和 Span
在 spaCy 中,Doc 是处理文本的核心对象。我们可以使用 Doc 类手动创建文档,而不是通过 nlp() 处理字符串。
from spacy.tokens import Doc, Span
import spacy
nlp = spacy.blank("en") # 创建一个空的英文模型
tokens = ["Hello", "world", "!"]
spaces = [True, False, False] # 单词之间是否有空格
doc = Doc(nlp.vocab, words=tokens, spaces=spaces)
print("创建的文档:", doc)
接着我们可以用 Span 创建一个实体片段,并加上标签:
span = Span(doc, 0, 2, label="GREETING") # "Hello world"
doc.ents = [span] # 设置 doc 的实体
print("命名实体:", doc.ents)
🛠️ 8. 查看与修改 NLP 管道组件
spaCy 的 NLP 模型是一个管道(pipeline),包含多个组件(如分词、实体识别等)。
print("管道组件名称:", nlp.pipe_names)
print("组件详细信息:", nlp.pipeline)
你也可以向管道中添加自定义组件,例如:
from spacy.language import Language
@Language.component("length_logger")
def log_doc_length(doc):
print(f"文档长度:{len(doc)}")
return doc
nlp.add_pipe("length_logger", first=True) # 插入为第一个组件
print("修改后的管道组件:", nlp.pipe_names)
doc = nlp("A sample sentence.")
🐛 9. 自定义实体识别器(基于词性和词形)
我们用 Matcher 组件来匹配特定词汇(比如“moth”、“fly”、“mosquito”),并用 Span 标记为实体:
from spacy.matcher import Matcher
text = "Qantas flies all sorts of cargo! That includes moths, mosquitos, and even the occasional fly."
nlp = spacy.load("en_core_web_sm")
matcher = Matcher(nlp.vocab)
# 添加匹配规则
for insect in ["moth", "fly", "mosquito"]:
matcher.add("INSECT", [[{"LEMMA": insect, "POS": "NOUN"}]])
@Language.component("insect_finder")
def mark_insects(doc):
matches = matcher(doc)
doc.ents = [Span(doc, start, end, label="INSECT") for _, start, end in matches]
return doc
nlp.add_pipe("insect_finder", after="ner") # 放在命名实体识别之后
doc = nlp(text)
print("识别到的昆虫实体:", [(ent.text, ent.label_) for ent in doc.ents])
🔍 10. 文本向量与相似度计算
spaCy 中的 en_core_web_md 或 en_core_web_lg 模型提供了词向量。我们可以比较词、句子的相似度:
nlp = spacy.load("en_core_web_md")
doc1 = nlp("I like fast food")
doc2 = nlp("I like pizza")
print("句子相似度:", doc1.similarity(doc2))
doc = nlp("I like pizza and pasta")
print("词语相似度(pizza vs pasta):", doc[2].similarity(doc[4]))
📚 11. 使用 nlp.pipe 批量处理文本
如果你需要处理大量文本,nlp.pipe() 是更高效的选择:
texts = ["First example!", "Second example."]
for doc in nlp.pipe(texts):
print("处理结果:", doc)
🧩 12. 给 Doc 添加自定义属性(Context 扩展)
使用 Doc.set_extension() 可以添加自定义字段,例如 id 或 page_number:
from spacy.tokens import Doc
data = [
("This is a text", {"id": 1, "page_number": 15}),
("And another text", {"id": 2, "page_number": 16}),
]
# 只设置一次,重复设置会报错
try:
Doc.set_extension("id", default=None)
Doc.set_extension("page_number", default=None)
except ValueError:
pass
# 给每个 doc 添加上下文属性
for doc, context in nlp.pipe(data, as_tuples=True):
doc._.id = context["id"]
doc._.page_number = context["page_number"]
print(f"{doc.text} | ID: {doc._.id} | 页码: {doc._.page_number}")
🔧 13. 控制管道的运行组件(select_pipes)
你可以临时禁用某些组件,加快处理速度或避免不必要的分析:
text = """Chick-fil-A is an American fast food restaurant chain headquartered in
College Park, Georgia."""
with nlp.select_pipes(disable=["tagger", "parser"]): # 临时关闭组件
doc = nlp(text)
print("命名实体:", doc.ents)
print("词性标注(关闭 tagger 后):", [token.tag_ for token in doc])