python 基础入门
一、python介绍和安装
1. python语言的特点
- 语法简洁
- 类库丰富
- 跨平台
- 可扩展
- 源码开放
2. python版本
-
官方版本
只包含python的解释程序和一些标准库
https://www.python.org/downloads/,安装后打开终端输入python,显示python版本即为安装成功 -
发行版Anaconda
除了解释程序和标准库还会集成很多第三方的软件包,不需要考虑软件包之间的依赖关系
https://www.anaconda.com/
3. python解释器
-
启用解释器
终端输入python即可启动python解释器,输入exit()命令退出解释器 -
交互模式
终端输入指令python后解释器启动并在交互模式中运行,交互模式下会显示主提示符>>>,这时可以输入python指令;输入连续行时会显示次要提示符...
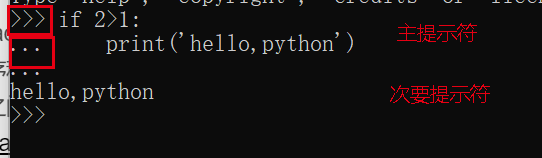
交互模式下,上次输出的表达式会赋给变量_,最好把该变量当作只读类型,不要为它显式赋值,否则会创建一个同名独立局部变量,该变量会用它的魔法行为屏蔽内置变量。

-
解释器字符编码
默认情况下,Python 源码文件的编码是 UTF-8,但是可移植代码、标准库只用常规的ASCLL字符作为变量名或者函数名
# 如果不使用默认编码,则要声明文件的编码,文件的 第一 行要写成特殊注释。句法如下:
# -*- coding: encoding -*-
4. PyCharm编译器安装使用
-
安装
进入官网下载社区版本的PyCharm即可,https://www.jetbrains.com/pycharm/download/#section=windows
-
使用
New Project: 创建项目 Open: 导入并打开本地项目 Get from VCS: 配置GitHub/SVN仓库地址 Plugins: 安装的插件
5. python3 基础语法
- 注释
# 这是一个注释
# 多行注释
'''
注释
注释
注释
注释
'''
"""
注释
注释
"""
- 缩进
python使用缩进来表示代码块,不需要使用大括号 {} 。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数
if True:
print ("True")
else:
print ("False")
- 多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠 \ 来实现多行语句
testList = item_one + \
item_two + \
item_three
-
空行
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。 类和函数入口之间也用一行空行分隔,以突出函数入口的开始。 空行与代码缩进不同,空行并不是 Python 语法的一部分。书写时不插入空行,Python 解释器运行也不会出错。 空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。空行也是程序代码的一部分 -
输入
input("请输入内容")
- 输出
print('这是一个输出')
# print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=""
print('a', end=" ")
print('b', end=" ")
- 导入
-
在 python 用
import或者from...import来导入相应的模块。 -
将整个模块(somemodule)导入,格式为:
import somemodule -
从某个模块中导入某个函数,格式为:
from somemodule import somefunction -
从某个模块中导入多个函数,格式为:
from somemodule import firstfunc, secondfunc, thirdfunc -
将某个模块中的全部函数导入,格式为:
from somemodule import *
6. 编码风格
-
缩进,用 4 个空格,不要用制表符。
-
4 个空格是小缩进(更深嵌套)和大缩进(更易阅读)之间的折中方案。制表符会引起混乱,最好别用。
-
换行,一行不超过 79 个字符。
-
这样换行的小屏阅读体验更好,还便于在大屏显示器上并排阅读多个代码文件。
-
用空行分隔函数和类,及函数内较大的代码块。
-
最好把注释放到单独一行。
-
使用文档字符串。
-
运算符前后、逗号后要用空格,但不要直接在括号内使用
-
类和函数的命名要一致;按惯例,命名类用 UpperCamelCase,命名函数与方法用 lowercase_with_underscores。命名方法中第一个参数总是用 self 。
-
编写用于国际多语环境的代码时,不要用生僻的编码。Python 默认的 UTF-8 或纯 ASCII 可以胜任各种情况。
-
同理,就算多语阅读、维护代码的可能再小,也不要在标识符中使用非 ASCII 字符。
二、数据类型
1. 基本数据类型
(1) Number 数字
python3 有四种数字类型分别是 int、bool、float、complex(复数),其中bool类型为int的子类,True 和 False 可以和数字相加, True == 1、False == 0
(2) String(字符串)
Python中的字符串用单引号 ’ 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符,如果不希望前置 \ 的字符转义成特殊字符,可以使用 原始字符串,在引号前添加 r 即可
a = '123'
b = '123'
print(type(a))
print(type(b))
print('this\'s python')
print(r'c:\user\ahua')
(3) 类型转换

2. 列表
Python 中没有数组,而是加入了功能更强大的列表(list),列表可以存储任何类型的数据,同一个列表中的数据类型还可以不同;列表是mutable (可变的),可迭代访问。可以进行序列结构的基本操作:索引、切片、加、乘、检查成员等。列表存储的数据可以变更。
(1) 创建
列表中所有元素都放在一个中括号 [] 中,相邻元素之间用逗号分割
L = [1, 0.12, 'Python']
(2) 访问
通过索引访问列表中的值,使用 : 截取范围内的元素
print(L[0]) # 1
print(L[0:2]) # [1,0.12]
(3) 修改
L[1] = '0'
print(L) # [1, 0, 'Python']
(4) 添加
使用 append() 向列表中添加新元素
L = [1, 0.12, 'Python']
print(L) # [1, 0.12, 'Python']
L.append('阿花')
print(L) # [1, 0.12, 'Python', '阿花']
(5) 删除
使用 del 删除列表中元素,del 语句也可以从列表中移除切片,或清空整个列表
L = [1, 0.12, 'python']
del L[1:2]
print(L) # [1, 'python']
# 切片
del L[1:2]
print(L) # [1, 'python']
# 删除列表
del L
print(L) # NameError: name 'L' is not defined
(6) 列表常用方法
① count():统计列表中某个元素出现的次数
print(L.count) # 3
② index():查找某个元素在列表中首次出现的位置(即索引)
print(L.index(1)) # 0
③ remove():移除列表中某个值的首次匹配项
L.remove(0.12)
print(L) # [1,'python']
④ sort():对列表中元素进行排序,参数中可以传入自定义排序的规则
a = [2,4,1,3]
b = ['b','c','a','d']
a.sort()
b.sort()
print(a) # [1,2,3,4]
print(b) # ['a','b','c','d']
⑤ copy():复制列表
c = L.copy()
print(c) # [1, 0.12, 'Python']
⑥ len():计算列表个数
print(len(L)) # 3
⑦ max() 和 min():返回元组中元素最大、最小值
L = [1, 2, 4]
print(max(L)) # 4
print(min(L)) # 1
⑧ insert(index,x):在指定位置插入元素,第一个参数是插入元素的索引,第二个元素是插入的内容
l = [1, 2, 3, 4, 5]
l.insert(2, 6)
print(l) # [1, 2, 6, 3, 4, 5]
⑨ remove(x):删除列表中第一个值为x的元素,如果列表中没有指定元素时触发 ValueError 异常。
l = [1, 2, 3, 4, 5]
l.remove(2)
print(l) # [1, 3, 4, 5]
l.remove(6) # ValueError: list.remove(x): x not in list
⑩ pop(index):删除列表中指定位置的元素,并返回被删除的元素。未指定位置时,a.pop() 删除并返回列表的最后一个元素。
l = [1, 2, 3, 4, 5]
l.pop(2)
print(l) # [1, 3, 4, 5]
l.pop()
print(l) # [1, 2, 4]
(7) 列表推导式
推导式comprehensions(又称解析式),是Python的一种独有特性。推导式对序列或可迭代对象中的每个元素应用某种操作,可以从一个数据序列构建另一个新的数据序列的结构体。
# 生成l平方的列表
# 正常代码
l = [1, 2, 3, 4, 5]
l1 = []
for i in l:
l1.append(i*i)
print(l1) # [1, 4, 9, 16, 25]
# 列表推导式
l = [1, 2, 3, 4, 5]
l1 = [i*i for i in l]
print(l1) # [1, 4, 9, 16, 25]
① [ ] 声明最终结果会是一个列表
② i*i 是表达式<==>要放入列表中的元素
③ for i in l,遍历 l,与普通 for 循环一样
3. 元组
元组(tuple)与列表类似,但元组是 immutable (不可变的),一般可通过解包或索引访问。可简单将其看作是不可变的列表。
(1) 创建
元组中所有元素都放在一个小括号 () 中,相邻元素之间用逗号分隔
t = (1, 0.12, 'Python')
(2) 访问
与访问列表中元素类似
print(t[1]) # 0.12
(3) 修改
元组中的数据不可修改,只能通过重新赋值
t = ('你好','阿花')
print(t) # ('你好','阿花')
(4) 删除
元组中的元素不能被删除,我们只能删除整个元组
del t
print(t) # NameError: name 't' is not defined
(5) 转换
tuple()将列表转换为元组
print(tuple(L)) # (1, 0.12, 4)
(6) 常用方法
下面这些方法的使用和列表一致
① index
② count
③ copy
④ len
4. 序列
所有成员都是有序排列的(三种基本序列类型:list, tuple 和 range 对象)
序列的基本操作
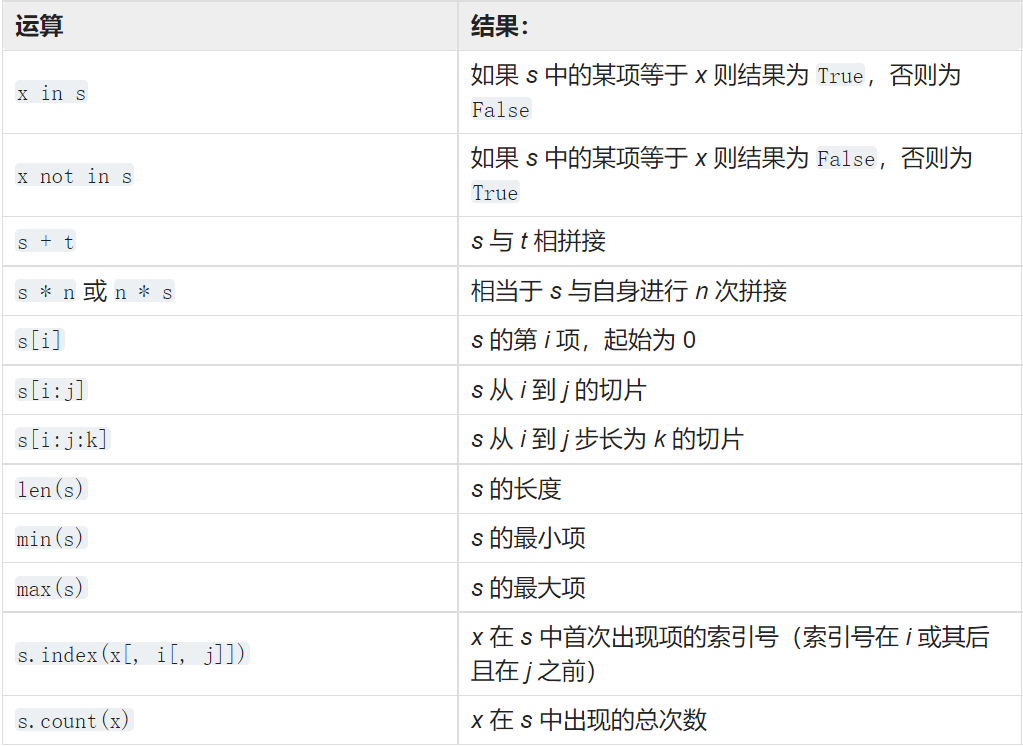
注:
- 在专门化序列str中也可以使用in或者not in进行成员监测
ptint('a' in 'abc') # True
- 符号*在包含空列表的单元素列表进行重复操作时会存在数据引用问题
l = [[]] * 3
print(l) # [[], [], []]
l[1].append(1)
print(l) # [[1], [1], [1]]
因为[[]] * 3 结果中的三个元素其实都是对一个空列表的引用。 修改 lists 中的任何一个元素实际上都是对这一个空列表的修改
创建不同列表为元素的列表可以使用下列方法
lists = [[] for i in range(3)]
5. 字典
dict字典以键值的形式存在,dict 拥有良好的查询速度,dict 中的值可以是任意 Python 对象,多次对一个 key 赋 value,字典的键必须是唯一的,后面的 value 会把前面的 value 覆盖
字典的关键字通常是字符串或数字,也可以是其他任意的不可变类型。比如只包含字符串、数字、元组的元组,但如果元组直接或间接地包含了可变对象就不能用作关键字
(1) 定义
字典的内容在花括号 {} 内,键-值(key-value)之间用冒号 : 分隔,键值对之间用逗号 分隔
# 字面量形式
d = {'name': '阿花', 'age': 18}
print(d) # {'name': '阿花', 'age': 18}
# 使用 dict 函数
# 方式一
l1 = [('name', '阿花'), ('age', 18)]
t1 = (('name', '阿花'), ('age', 18))
d1 = dict(l1)
d2 = dict(t1)
print(d1) # {'name': '阿花', 'age': 18}
print(d2) # {'name': '阿花', 'age': 18}
# 方式二
d3 = dict(name='阿花', age=18)
print(d3) # {'name': '阿花', 'age': 18}
# 空字典
d4 = dict()
d4 = {}
print(d4) # {}
(2) 访问
字典中的值通过 key 进行访问
d = {'name': '阿花', 'age': 18}
print(d['name']) # 阿花
print(d.get('name')) # 阿花
(3) 修改
d = {'name': '阿花', 'age': 18}
print(d) # {'name': '阿花', 'age': 18}
d['name'] = 'Ryan'
print(d) # {'name': 'Ryan', 'age': 18}
del d['name']
print(d) # {'age': 18}
d.clear()
print(d) # {}
(4) 获取长度
print(len(d)) # 2
(5) 返回键值的视图对象
视图对象( view objects)提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
# dict.keys() 返回字典dict中键的视图对象
# dict.values() 返回字典dict中值的视图对象
# dict.items() 返回一个可遍历的key/value 的视图对象
d = {'name': '阿花', 'age': 18}
print(d.keys()) # dict_keys(['name', 'age'])
print(d.values()) # dict_values(['阿花', 18])
print(d.items()) # dict_items([('name', '阿花'), ('age', 18)])
l = list(d.items()) # 将视图对象转换为列表
print(l) #[('name', '阿花'), ('age', 18)]
(6) 字典推导式
# 互换字典d中键和值的位置
# 原始方法
d = {'name': '阿花', 'age': '18'}
d1 = {}
for key, value in d.items():
d1[value] = key
print(d1) # {'阿花': 'name', '18': 'age'}
# 字典推导式
d2 = {value: key for key, value in d.items()}
print(d2) # {'阿花': 'name', '18': 'age'}
6. 集合
集合(set)是由不重复元素组成的无序容器
(1) 创建集合
集合使用花括号 {} 或者 set() 函数创建,如果创建空集合只能使用 set() 函数,字面量形式的空{}创建出来的是空字典
# 字面量形式
s = {'a', 'b', 'c'}
# 使用 set 函数
s = set(['a', 'b', 'c'])
# 空集合
s = set()
(2) 添加元素
使用add和update可以为集合添加元素,如果元素已经存在则不再继续进行操作
s = {'1', 'a', 'b', '2'}
s.update('e')
s.add('m')
print(s) # {'2', 'm', 'a', 'b', 'e', '1'}
s.add('1')
print(s) # {'2', 'm', 'a', 'b', 'e', '1'}
(3) 删除元素、获取集合长度、清空集合
s = {'1', 'a', 'b', '2'}
s.remove('a')
print(s) # {'2', '1', 'b'}
print(len(s)) # 3
s.clear()
print(s) # set()
(4) 集合推导式
集合也支持推导式
s = {x for x in 'abracadabra' if x not in 'abc'}
print(s) # {'r', 'd'}
三、语句
1. 条件语句
进行逻辑判断时需要用到条件语句,python提供if、else、elif进行逻辑判断
if 判断条件1:
执行语句1...
elif 判断条件2:
执行语句2...
elif 判断条件3:
执行语句3...
else:
执行语句4...
2. 循环语句
需要多次重复时,python为循环提供了for循环和while循环
(1) for循环
for循环可以遍历任何序列
str = 'python'
for s in str:
print(s)
# p
# y
# t
# h
# o
# n
(2) while循环
while在满足条件时进行循环,不满足条件时退出循环
sum = 0
m = 5
while m > 0:
sum = sum + 1
m = m - 1
print(sum)
# 1
# 2
# 3
# 4
# 5
(3) break
用在 for 循环和 while 循环语句中,用来终止整个循环
str = 'python'
for s in str:
if s == 't':
break
print(s)
# p
# y
(4) continue
用在 for 循环和 while 循环语句中,用来终止本次循环
str = 'python'
for s in str:
if s == 't':
continue
print(s)
# p
# y
# h
# o
# n
3. 其他语句
(1) pass语句
pass语句是空语句,它不做任何事情,一般用做占位语句,作用是保持程序结构的完整性。
if True:
pass
(2) match语句
将一个目标值与一个或多个字面值进行比较,类似c、Java或者JavaScript中的switch语句。最后一个case的比较变量 _ 被作为 通配符 并必定会匹配成功
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
四、函数
对程序逻辑进行结构化的一种编程方法
1. 定义函数
函数定义规则:
- 函数代码块以 def 关键词开头,后跟函数名与括号内的形参列表。
- 函数的第一行语句可以选择性地使用文档字符串,用于存放函数说明。
def doc():
''' This is doc
it doesn't do anything
'''
pass
print(doc.__doc__)
# this is doc
#
# it doesn't do anything
- 函数内容以冒号 : 起始,并且缩进。
return [表达式]结束函数,选择性地返回一个值给调用方,不带表达式的 return 相当于返回 None。
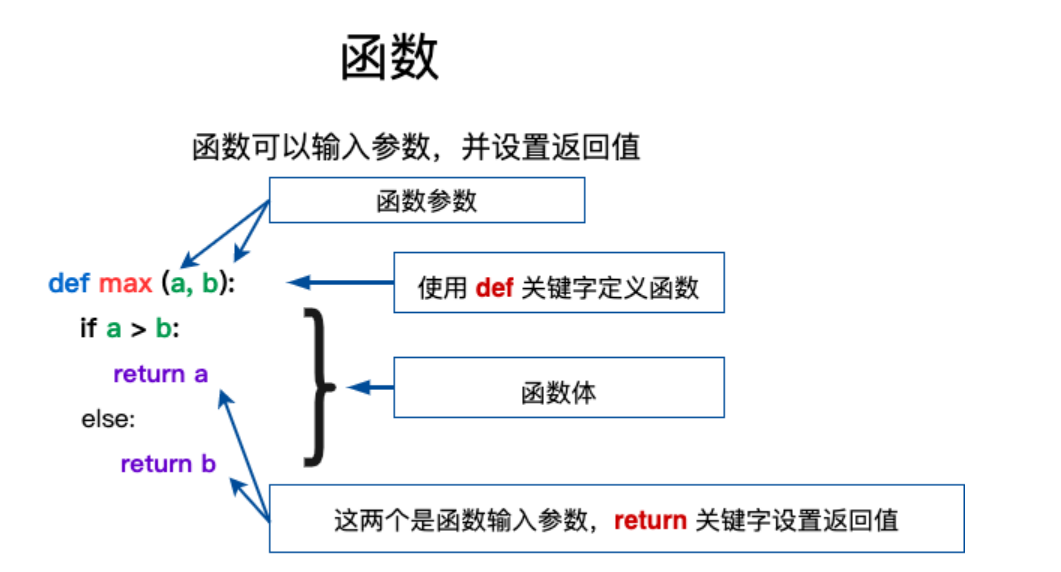
def max(a, b):
if a > b:
return a
else:
return b
print(max (3, 9)) # 9
2. 函数作用域
函数执行时使用函数局部变量,引用变量时首先在局部变量中查找,然后是外部函数变量,再是全局变量。虽然可以引用外部函数变量和全局变量,但是最好不要在函数中给他们赋值
python中global关键字还支持在函数中指定全局变量
g = 1
def fn():
a = 2
global b
b = 3
print('函数外:', g)
print('函数内:', a)
fn()
print('global变量', b)
# 函数外: 1
# 函数内: 2
# global变量 3
3. 函数参数
(1) 关键字参数
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值
def printStr(str, str1):
print(str1)
print(str)
# 调用printStr函数
printStr(str1='你好', str="阿花")
# 你好
# 阿花
(2) 默认参数、默认值共享
调用函数时,如果没有传递参数,则会使用默认参数
def printStr(name, age=18):
print(name)
print(age)
# 调用printStr函数
printStr(name="阿花")
# 阿花
# 18
默认值只计算一次。默认值为列表、字典或类实例等可变对象时,函数会累积后续调用时传递的参数
def f(a, L=[]):
L.append(a)
return L
print(f(1)) # [1]
print(f(2)) # [1, 2]
print(f(3)) # [1, 2, 3]
# 解决后续调用之间不共享默认值
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
(3) 不定长参数
- 当函数需要处理的参数不确定数目时可以使用不定长参数,参数前面加上*,会以元组(tuple)的形式导入,存放所有未命名的变量参数
def printStr(num, *tuple):
print(num)
print(tuple)
# 调用printStr函数
printStr(1,2,3,4,5)
# 1
# (2, 3, 4, 5)
- 参数前加两个星号 ** ,会以字典的形式导入
def printStr(num, **dict):
print(num)
print(dict)
# 调用printStr函数
printStr(1,a=2,b=3)
# 1
# {'a': 2, 'b': 3}
(4) 解包不定长参数
- 如果函数调用时传递的参数不是独立的,可以使用
*操作符把实参从列表或元组解包出来
l = [1, 2, 3]
def fn(a, b, c):
print(a, b, c)
fn(*l)
- 字典可以用 ** 操作符进行解包
d = {'a': 1, 'b': 2, 'c': 3}
def fn(a, b, c):
print(a, b, c)
fn(**d)
(5) 仅限位置参数和仅限关键字参数
-
声明函数时参数中如果有
/正斜杠出现,则正斜杠前的参数为仅限位置形参,必须按照指定的顺序传入参数,其后可以通过位置形参传入参数也可以通过关键字形参传入参数 -
声明函数时参数中如果有
*星号出现,则星号后面的参数为仅限关键字参数,必须采用关键字形式传入 -
/和*之间的参数可以是位置参数也可以是关键字参数
def f(position_only, /, standard, *, key_only):
print(pos_only)
print(standard)
print(key_oly)
f(1, 2, key_oly=3)
f(1, standard=2, key_oly=3)
f(1,2,3)
# 第三个参数key_only只能是关键字形参
f(position_only=1, standard=2, key_oly=3)
# 第一个参数position_only必须为位置形参
# 注:函数参数不包含'/'和'*',所以函数f只有三个参数'position_only'、'standard'、'key_only'
(6) 匿名函数
- Python 可以使用 lambda 来创建匿名函数。
- lambda 的主体是一个表达式,而不是一个代码块,仅仅能在 lambda 表达式中封装有限的逻辑进去
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
# 一个参数
fn = lambda a : a + 10
print(fn(5)) # 15
# 两个参数
sum = lambda a1, a2: a1 + a2
print(sum(1, 1))
print(sum(2, 2))
五、模块
-
在编写较长程序时,建议用文本编辑器代替解释器,将定义好的函数和变量等python代码编写在后缀为
.py的文件中,供一些脚本或者交互式解释器实例使用,这个文件就被称为模块。 -
每个模块都有自己的私有命名空间,因此,即使不同模块之间使用相同的变量名定义全局变量,而不必担心发生意外冲突。
-
而且模块可以导入其他模块,进而使用该模块中的函数、变量等功能
1. import语句
-
要想在一个python文件中导入另一个python文件的内容需要使用import语句
-
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入,但是无论执行多少次import语句,一个模块只会被导入一次
-
导入的模块将被添加到当前模块的全局命名空间中,而模块中的函数名、变量名可以通过导入的模块名访问
# module.py文件
a = 3
def print_func(par):
print("Hello : ", par)
return
# main.py文件
import module
module.print_func('ahua') # Hello : ahua
print(module.a) # 3
2. from … import 语句
from 语句支持从模块中导入一个指定的部分(一个变量或者函数)到当前命名空间中,未导入的部分报NameError的错误
from module import print_func
print_func('ahua') # Hello : ahua
print(moudle.a) # NameError: name 'moudle' is not defined
# 不会把整个module 模块导入到当前的命名空间中,它只会将module 里的print_func函数引入进来。
3. from … import * 语句
将一个模块的所有内容(除了由单一下划线_开头的名字)全都导入到当前的命名空间中,如果当前环境和导入的模块有同名函数或者变量时,导入的内容会被覆盖
# module.py文件
a = 3
def print_func(par):
print("Hello : ", par)
return
# main.py文件
from module import *
a = 666
print_func('ahua') # Hello : ahua
print(a) # 3
4. _ _name_ _属性
_ _name_ _属性可以标识模块的名字,显示一个模块的某功能是被自己执行(__name__ == '__main__')还是被别的文件调用执行(__ name__== 模块名),如果我们想在模块被引用时某一程序不执行,我们可以通过该属性来判断
# moudle.py
if __name__ == '__main__':
print('程序自身运行 %s' %__name__)
else:
print('我来自模块 %s' %__name__)
# test_name.py
from module import *
# 直接执行moudle.py的输出是 程序自身运行 __main__
# 执行test_name.py的输出是 我来自模块 module
5. dir()函数
dir函数用于查找模块定义的名称,返回的结果会罗列出当前定义的所有名称
# modul.py
a = 3
def fnc():
print('我来自module模块')
# test_dir.py
import module
print(dir(module))
# ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'fnc']
6. 标准模块
Python 自带一个标准模块的库,这些模块直接被构建在解析器里,这些组件会根据不同的操作系统进行不同形式的配置,比如 winreg 这个模块就只会提供给 Windows 系统。
比如sys模块是与python解释器交互的一个接口 ,它内置在每一个 Python 解析器中。sys 模块提供了许多函数和变量来处理 Python 运行时环境的不同部分。
import sys
# 当前py文件本身的路径或名称(当前所执行的脚本)
print(sys.argv) # ['D:/CodeFilder/python/main.py']
# 获取Python解释程序的版本信息
print(sys.version) # 3.10.4 | packaged by conda-forge | (main, Mar 30 2022, 08:38:02) [MSC v.1916 64 bit (AMD64)]
# 返回操作系统平台名称
print(sys.platform) # win32
# sys.path 是字符串列表,用于确定解释器的模块搜索路径。以环境变量 PYTHONPATH 提取的默认路径进行初始化,如未设置 PYTHONPATH,则使用内置的默认路径
print(sys.path) # ['D:\\CodeFilder\\python', 'D:\\CodeFilder\\python', 'D:\\Anaconda3\\envs\\python\\python310.zip', 'D:\\Anaconda3\\envs\\python\\DLLs', 'D:\\Anaconda3\\envs\\python\\lib', 'D:\\Anaconda3\\envs\\python', 'D:\\Anaconda3\\envs\\python\\lib\\site-packages']
7. 包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称",类似于使用模块时不用担心模块中的全局变量会相互污染一样,点模块名称的形式也不用担心不同库之间的模块重名问题。
例如你引入一个模块a.b,那么他表示的意思是包a下面的模块b,和导入模块类似,可以使用import和from import两种方式进行导入
可以导入模块名也可以直接导入模块中的变量名或者函数名
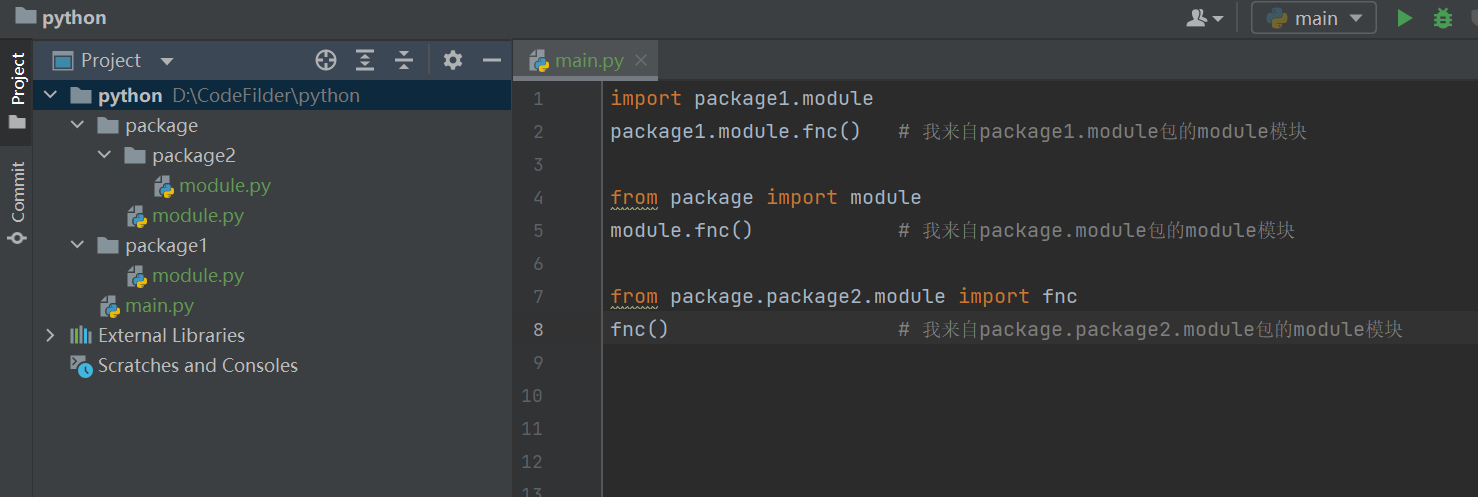
module.py、module1.py、module2.py文件中的代码
def fnc():
print('我来自s%包的module模块' %__name__)
8. *导入和__init__.py文件
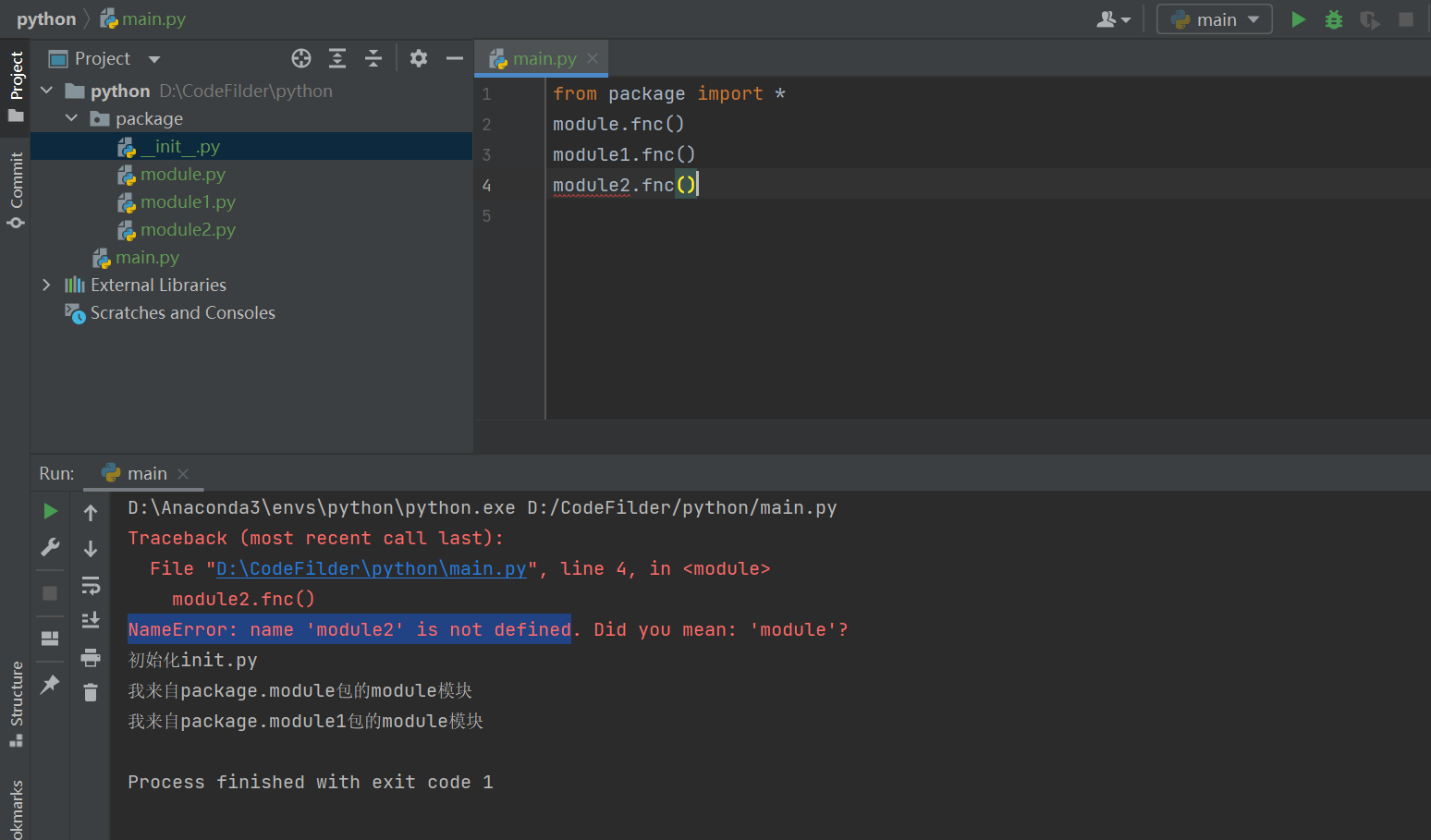
使用from package import *时Python 会进入文件系统,找到这个package包(当前py文件同级的package包)里面所有的子模块,将其全部导入
from package import *
module.fnc()
module1.fnc()
module2.fnc()
注:
1、import可以通过点号'.'导入多层级下的模块
2、from import中间书写层级,import后面只能跟具体模块或者变量
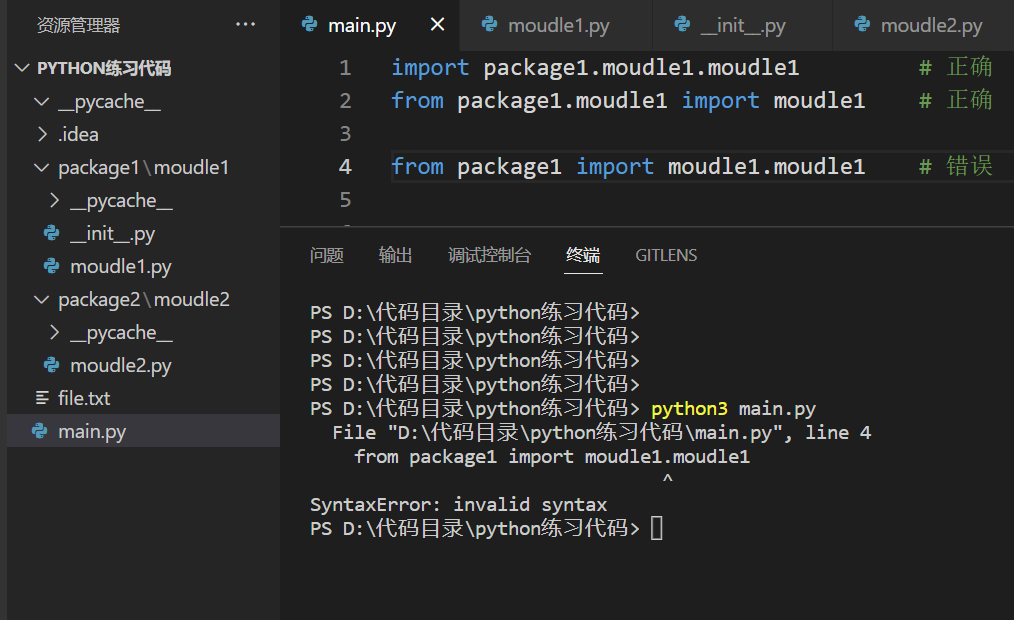
python规定在文件夹中添加一个__init__.py的文件,每当有外部import导入时,就会自动执行__init__.py文件中的内容。其作用是将自身所在的整个文件夹当做一个包来管理
因此我们可以通过__init__.py来执行一些默认动作或者默认导入一些模块
__init__.py文件内容
# 该包被导入时默认执行
import sys
sys.path.append("../../")
# 将__init__.py文件的上上级目录加到sys.path中
from package2.moudle2 import moudle2
导入moudle1包时默认执行__init__.py文件
Windows 是一个不区分大小写的系统,区分不出来Package.py文件和package.py文件,因此我们需要一个更精确的包索引。
__init__.py文件中的变量__all__会关联一个模块列表,当执行 from xx import * 时,会导入该模块列表中的模块。
__init__.py文件内容
print("初始化init.py")
__all__ = ["module", "module1"]
因为模块列表中没有module2.py所以*导入时不会包含module2模块
六、错误和异常
1. 错误
python中的错误指的是语法错误,编写的代码不符合解释器或者编译器语法
# for循环少一个:
l = [1,3,4,9]
for i in l
print(i)
# SyntaxError: expected ':'
语法错误又称解析错误,简单来说是基本语法结构写错了
2. 异常的产生
执行时检测到的错误称为 异常,大多数的异常都不会被程序处理,以错误信息的形式展现
当熟悉python语法后可以避免语法错误,但是代码常会发生异常,如果异常对象没有被捕获或者处理,程序就会回溯(traceback)终止执行
1/0
# Traceback (most recent call last):
# File "D:\CodeFilder\python\main.py", line 1, in <module>
# 1/0
# ZeroDivisionError: division by zero
2 + a
# Traceback (most recent call last):
# File "D:\CodeFilder\python\main.py", line 7, in <module>
# 2 + a
# NameError: name 'a' is not defined
1+'ahua'
# Traceback (most recent call last):
# File "D:\CodeFilder\python\main.py", line 13, in <module>
# 1+'ahua'
# TypeError: unsupported operand type(s) for +: 'int' and 'str'
错误信息的最后一行说明程序遇到了什么类型的错误。异常有不同的类型,而类型名称会作为错误信息中的一部分打印出来
(1) 异常的层次结构
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
(2) 异常对应的详细说明
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
3. 异常处理
(1) 捕捉异常
异常捕捉可以使用 try/except 语句。

下面例子为:当用户输入一个合法的整数时退出程序,如果用户输入不合法则提示输入不合法
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
try 语句的工作方式为:
-
首先,执行 try 子句 (在 try 和 except 关键字之间的部分);
-
如果没有异常发生, except 子句 在 try 语句执行完毕后就被忽略了;
-
如果在 try 子句执行过程中发生了异常,那么该子句其余的部分就会被忽略;
-
如果异常匹配于 except 关键字后面指定的异常类型,就执行对应的except子句,然后继续执行 try 语句之后的代码;
-
如果发生了一个异常,在 except 子句中没有与之匹配的分支,它就会传递到上一级 try 语句中;
-
如果最终仍找不到对应的处理语句,它就成为一个 未处理异常,终止程序运行,显示提示信息。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
try:
10 / 0
except NameError:
print('Error: NameError argument.')
except ZeroDivisionError:
print('Error: ZeroDivisionError argument.')
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
(2) 处理多个异常
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组
except (RuntimeError, TypeError, NameError):
print('捕获异常')
except捕获到异常后还可以重命名该异常然后打印出来
try:
10/0
except ZeroDivisionError as err:
print('零不能做除数 %s' %err)
最后一个except子句可以忽略异常的名称,它将被当作通配符使用
import sys
try:
10 / 0
except NameError as err:
print("error %s" %err)
except ValueError:
print("ValueError")
except:
# sys.exc_info()返回当前正在处理异常的信息
print(sys.exc_info()[0])
try/except 语句还有一个可选的 else 子句和finally子句,这两个子句必须放在所有的 except 子句之后。
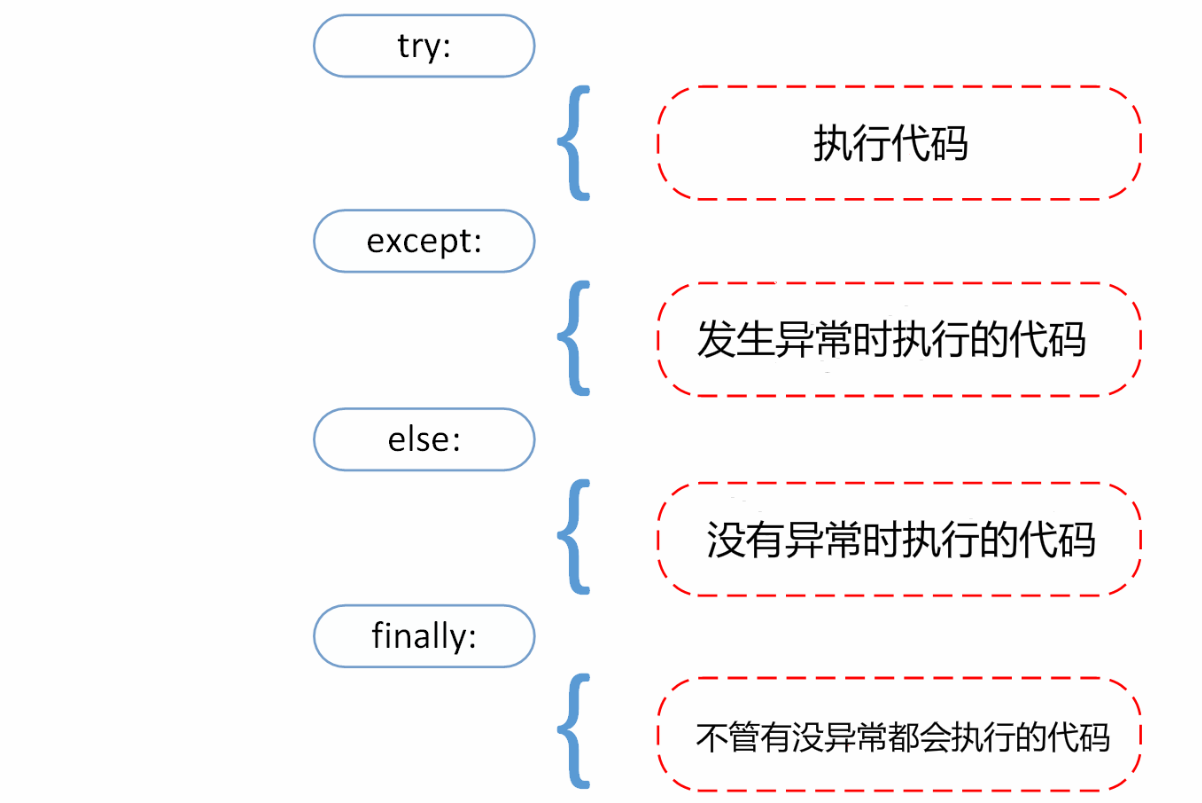
try:
# print('try --> ', 10 / 0)
print('try --> ', 10 / 5)
except ZeroDivisionError:
print('except --> Error: ZeroDivisionError')
else:
print('else子句在except未捕获到错误时才会执行')
finally:
print('finally子句一定会执行')
(3) 基类(子类)兼容
如果当前发生的异常与 except 子句中的类是同一个类或是它的基类(子类)时,则该类与该异常相兼容(该异常会执行except子句中的内容)
下面的代码会分别触发三个except子句,打印出 B, C, D
class B(Exception):
pass
class C(B):
pass
class D(C):
pass
for err in [B, C, D]:
try:
raise err()
except D:
print("D")
except C:
print("C")
except B:
print("B")
# B
# C
# D
如果颠倒except子句的位置,则会输出B B B(即触发第一个except子句三次)
class B(Exception):
pass
class C(B):
pass
class D(C):
pass
for err in [B, C, D]:
try:
raise err()
except B:
print("B")
except C:
print("C")
except D:
print("D")
# B
# B
# B
4. 抛出异常
raise 语句允许强制抛出一个指定的异常,抛出的异常由 raise 的唯一参数标识,它必需是一个异常实例或异常类(继承自 Exception 的类)
raise NameError('这是自己抛出的异常')
# Traceback (most recent call last):
# File "D:\CodeFilder\python\main.py", line 1, in <module>
# raise NameError('这是自己抛出的异常')
# NameError: 这是自己抛出的异常
5. 异常链
6. 用户自定义异常
你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承
#自定义异常类 MyExc
class MyExc(Exception): #继承Exception类
def __init__(self, value):
self.value = value
def __str__(self):
if self.value == 0:
return '被除数不能为0'
#自定义方法
def getNum(n):
try:
if n == 0:
exc = MyExc(n)
print(exc)
else:
print(10 / n)
except:
pass
# 1、调用 getNum(1),输出结果为:
# 10.0
# 2、调用 getNum(0),输出结果为:
# 被除数不能为0
在这个自定义的异常例子中,当参数 n 不为 0 时,则正常,当 n 等于 0,则抛出异常
七、输入、输出
1. 格式化输出
我们希望输出并不只是简单的打印值,而是控制数据按指定的格式输出,如果原数据格式不一致则进行转换
(1) 格式化字符串字面量
- 格式化字符串字面值需要在字符串开头的引号/三引号前添加 f 或 F 。通过·
{}表达式,将python表达式中的值添加到字符串内。
name = '阿花'
age = 18
print(f'my name is {name},i\'m {age} years old')
- 在
{}中表达式的后面加上符号:和格式说明符,可以更好的控制格式化值的方式
# f表示保留输出结果为浮点数
# 8表示输出内容占据的宽度
# .5表示小数点后面保留5位小数
# 因为输出的数据为3.14159占据7为,所以前面要补一个空格
import math
print(f'The value of pi is approximately {math.pi:8.5f}')
# The value of pi is approximately 3.14159
{}后面跟数字时表示为该字段设置最小宽度,常用于列对齐
dist = {'Stephen': 18, 'Jack': 40, 'Ryan': 22}
for name, phone in dist.items():
print(f'{name:10} ==> {phone:10d}') # d用来限制输出的格式为整数类型
# Stephen ==> 18
# Jack ==> 40
# Ryan ==> 22
- 字符串插值(% 运算符)也可以格式化字符串。类似c语言中的printf,value中%实例会替换string中的%实例
print('hello %s' %'阿花') # hello 阿花
(2) 字符串format()方法
花括号{}及之内的字符(称为格式字段)按顺序被替换为传递给 str.format() 方法中的对象。
print('my name is {},i\'m {} years old'.format('阿花', 20))
# my name is 阿花,i'm 20 years old
花括号中的数字表示传递给 str.format() 方法的对象所在的位置。
print('my name is {1},i\'m {0} years old'.format('阿花', 20))
# my name is 20,i'm 阿花 years old
str.format() 方法中使用关键字参数名引用值
print('my name is {name},i\'m {age} years old'.format(name='阿花', age=20))
# my name is 阿花,i'm 20 years old
str.format() 方法也支持位置参数和关键字参数任意组合
print('my name is {0},i\'m {age} years old'.format('阿花', age=20))
# my name is 阿花,i'm 20 years old
对于较长的字典格式数据,可以按名称引用变量进行格式化。
dist = {'AHua': 18, 'Jack': 21, 'Amie': 20}
dist1 = {'Ryan': 20, 'Jennie': 28, 'Deaf': 30}
print('Jack: {0[Jack]:5d}; AHua: {0[AHua]:5d}; Amie: {0[Amie]:5d}; Ryan: {1[Ryan]:5d};'
'Jennie: {1[Jennie]:5d}; Deaf: {1[Deaf]:5d};'.format(dist, dist1))
也可以使用 ** 操作符将字典解包为关键字参数传递
dist = {'AHua': 18, 'Jack': 21, 'Amie': 20}
print('Jack: {Jack:5d}; AHua: {AHua:5d}'.format(**dist))
# Jack: 21; AHua: 18
(3) 手动格式化字符串
字符串对象有 str.rjust() 、str.ljust() 和 str.center(),表示在字符串str左侧、右侧和左右两侧分别添加空格,这些方法不写入内容,只返回一个新字符串。输入字符串太长时,不会截断字符串,而是原样返回;截断字符串可以使用 x.ljust(n)[:n] 进行切片操作
for x in range(1, 11):
print(str(x).rjust(2), str(x*x).rjust(3), str(x * x * x).rjust(4))
另一种方法是 str.zfill() ,该方法在数字字符串左边填充零,且能识别正负
print('51'.zfill(5))
print('-12'.zfill(5))
print('3.141592653'.zfill(5))
(4) 格式化操作符%
包含 % 的字符串,被称为 格式化字符串,% 通过和不同的字符连用来限制输出的数据类型
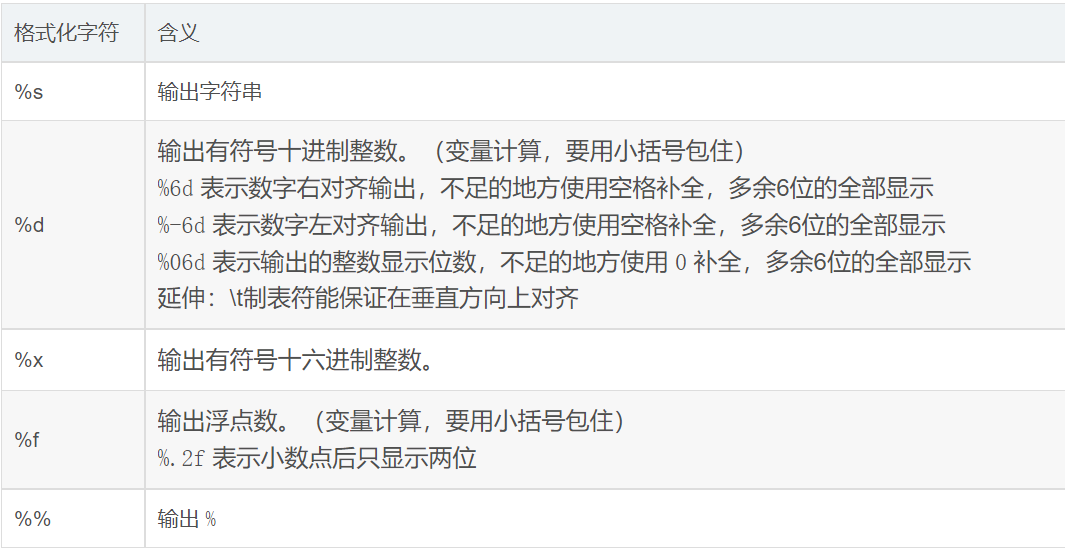
print('%10.6f' %1.6)
# 1.600000
第一个百分号后面是对需要输出内容的说明,f表示要显示的内容为浮点数,10表示输出的内容占据的宽度,.6表示小数点后面保留6位小数
第二个百分号后面是输出的内容,1.6小数点后面只有1位,所以会补5个0,但是因为前面10规定输出结果需要占据10个位置,而1.600000只占了8个位置,所以结果会在1.600000前面补上2个空格
2. 文件操作
(1) 创建文件
open() 可以打开或者创建文件
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
-
file:表示将要打开的文件的路径,也可以是要被封装的整数类型文件描述符。
-
mode:是一个可选字符串,用于指定打开文件的模式,默认值是 ‘r’(以文本模式打开并读取)。可选模式如下

-
buffering:是一个可选的整数,用于设置缓冲策略。
-
encoding:用于解码或编码文件的编码的名称(不能在二进制模式下使用)。
-
errors:是一个可选的字符串,用于指定如何处理编码和解码错误(不能在二进制模式下使用)。
-
newline:区分换行符。
-
closefd:如果 closefd 为 False 并且给出了文件描述符而不是文件名,那么当文件关闭时,底层文件描述符将保持打开状态;如果给出文件名,closefd 为 True (默认值),否则将引发错误。
-
opener:可以通过传递可调用的 opener 来使用自定义开启器。
# 下列代码创建了一个file.txt的空文件
open('file.txt', mode='w',encoding='utf-8')
在文本模式下读取文件时,默认把平台特定的行结束符(Unix 上为 \n, Windows 上为 \r\n)转换为 \n,写入数据时,也会默认把 \n 转换回平台特定结束符。但操作 JPEG 或 EXE 等二进制文件中时会破坏其中的数据,所以在读写此类文件时,一定要使用二进制模式。
(2) 文件读取
文件读取包含三个函数
(1)read(size):读取指定的字节数,size可选,表示从文件中读取的字符数(文本模式)或字节数(二进制模式),省略 size 或 size 为负数时,读取并返回整个文件的内容,只要 f.readline() 返回空字符串,就表示已经到达了文件末尾,空行使用 ‘\n’ 表示,该字符串只包含一个换行符
(2)readline():读取一行,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符
(3)readlines():读取所有行并返回列表
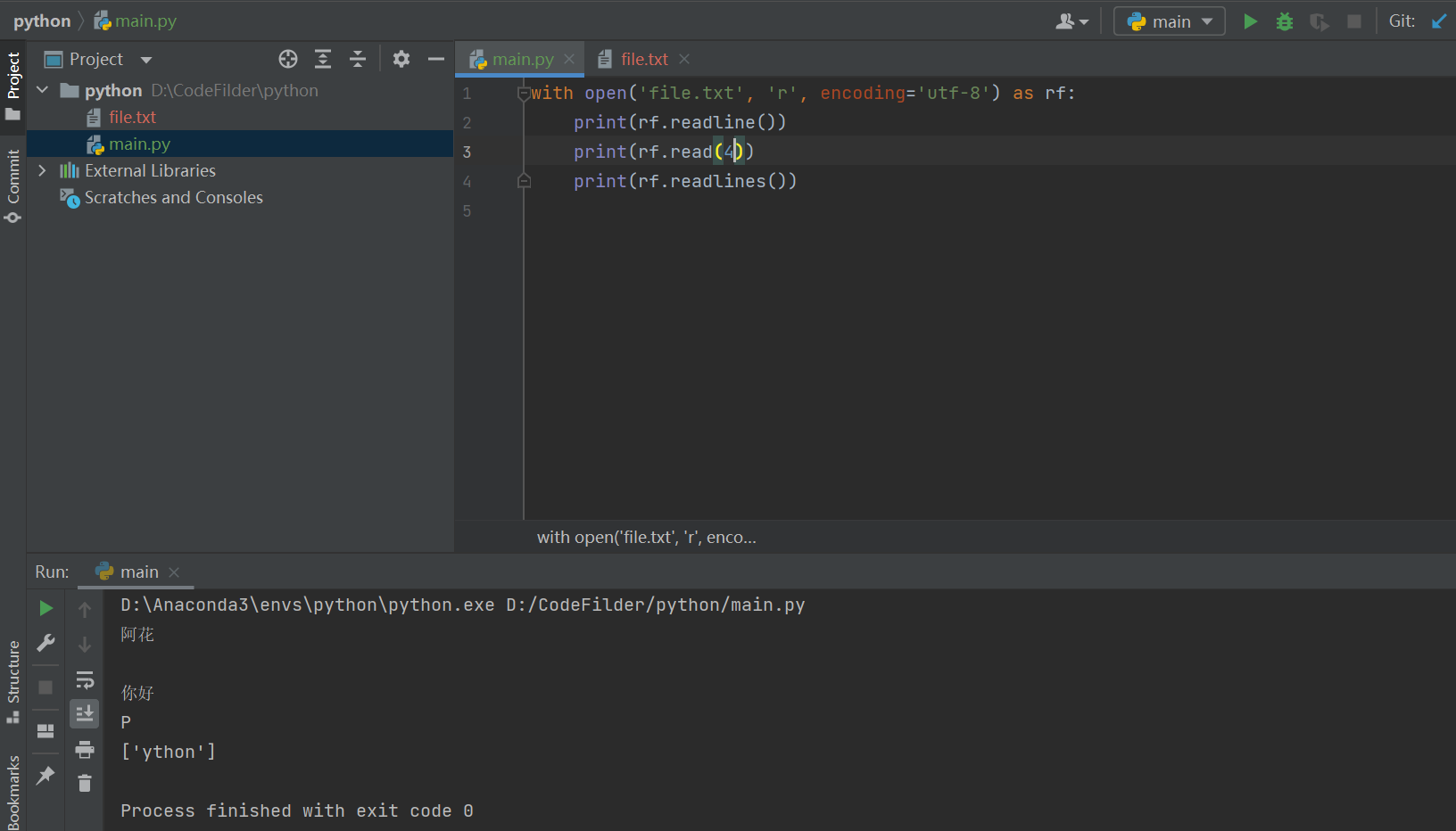
# 读取file.tet文件中的信息
with open('file.txt', 'r', encoding='utf-8') as rf:
print( rf.readline())
print( rf.read(6))
print( rf.readlines())
使用 with as 语句,程序执行完成后会自动关闭已经打开的文件
with open('file.txt', 'w', encoding='utf-8') as wf:
wf.write('阿花\n')
wf.writelines(['你好\n', 'Python'])
(3) 文件写入
文件写入包含两个函数
(1)writer:将字符串写入文件,返回写入字符长度
(2)writelines(s):向文件写入一个字符串列表
wf = open('file.txt', 'w', encoding='utf-8')
wf.write('阿花\n')
wf.writelines(['你好\n', 'Python'])
# 关闭文件
wf.close()
写入其他类型的对象前,需要先把它们转化为字符串(文本模式)或字节对象(二进制模式)
f = open('file.txt', 'w', encoding='utf-8')
value = ('阿花', 18)
s = str(value) # convert the tuple to string
print(type(s))
f.write(s)
f.close()
(4) 定位
和文件对象位置相关的函数有
(1)tell():返回文件对象在文件中的当前位置(二进制模式下时从文件开始到当前位置的字节数)
(2)seek(): 移动文件读取指针到指定位置
-
offset:开始的偏移量,也就是代表需要移动偏移的字节数,如果是负数表示从倒数第几位开始。
-
whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
with open('file.txt', 'rb+') as f:
# 在模式后面加上一个 'b' ,表示用 binary mode 打开文件
f.write(b'123456789')
# 文件对象位置
print(f.tell())
# 移动到文件的第四个字节
f.seek(3)
# 读取一个字节,文件对象向后移动一位
print(f.read(1))
# 返回文件读取指针所在位置
print(f.tell())
# 移动到倒数第二个字节
f.seek(-2, 2)
# 返回文件读取指针所在位置
print(f.tell())
# 读取一个字节,文件对象向后移动一位
print(f.read(1))
(5) 使用json保存结构化数据
json 标准模块将 Python中的数据结构转换为字符串表示形式的这个过程称为 serializing (序列化)。dumps()函数可以将数据结构序列号为字符串
import json
x = [1, 2, 'python']
d = json.dumps(x)
print(d) # ‘[1, 2, "python"]’
print(type(x)) # <class 'list'>
print(type(d)) # <class 'str'>
loads()函数可以将字符串从表示中回复原始数据结构称为 deserializing (解序化)
import json
z = '[1, 2, "python"]'
print(type(z)) # <class 'str'>
zz = json.loads(z)
print(type(zz)) # <class 'list'>
3. 读取键盘输入
Python 提供了 input() 内置函数从标准输入读入一行文本,默认的标准输入是键盘。
str = input("请输入:");
print ("你输入的内容是: ", str)
八、类
1. 作用域和命名空间
(1) 命名空间
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
命名空间是项目中避免名字冲突的一种方法。各个命名空间是独立的,没有任何关系的,一个命名空间中不能有重名,但不同的命名空间是可以重名而没有任何影响。
以计算机中的文件夹为例,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
命名空间一般可以分为三种
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、print 等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
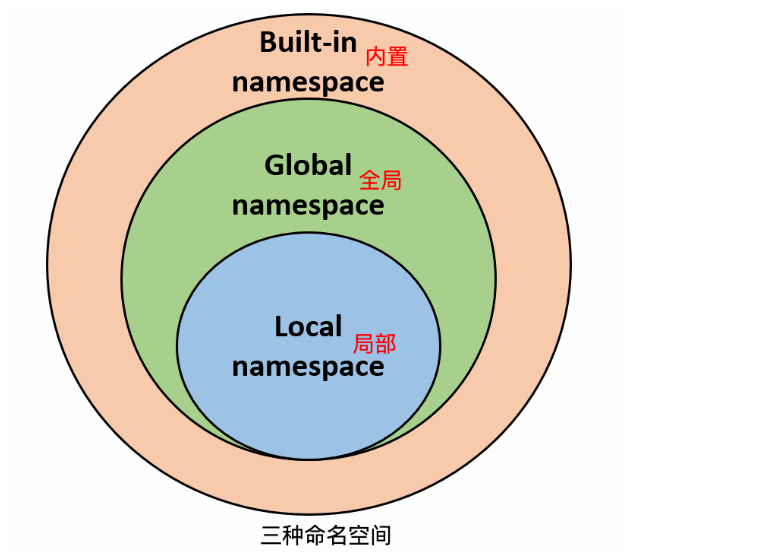
假设我们要使用变量 a,则 Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。如果找不到变量a,它将放弃查找并引发一个 NameError 异常
NameError: name 'a' is not defined
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此,我们无法从外部命名空间访问内部命名空间的对象。
(2) 作用域
python作用域是静态的,变量被赋值、创建的位置决定了其被访问的范围,即变量作用域由其所在位置决定
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种
- Local:最内层,包含局部变量,比如一个函数/方法内部。
- nonlocal & nonglobal:包含了 非局部也非全局的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- Global:当前脚本的最外层,比如当前模块的全局变量。
- Built-in: 包含了内建的变量/关键字等,最后被搜索。
访问一个变量时会由内而外的查找,在局部找不到,便会去局部外的局部找,再找不到就会去全局找,再者去内置中找。
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,这些语句内定义的变量,外部也可以访问。
Python中使用一个变量时并不严格要求需要预先声明它,但是在真正使用它之前必须被绑定到某个内存对象(被定义、赋值);这种变量名的绑定将在当前作用域中引入新的变量,同时屏蔽外层作用域中的同名变量
a = 1
def local():
a = 2 #由于python不需要预先声明,因此a = 2相当于在局部作用域中引入新的变量,而没有修改全局变量a
local()
print(a) # 1
(3) 全局变量和局部变量
定义在函数内部的变量的作用域范围为局部作用域,定义在函数外的变量作用域范围为全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到其局部作用域中。
a = 1
def test():
b = 2
print('局部变量', b) # 2
print('全局变量', a) # 1
test()
print('全局变量', a) # 1
print('局部变量', b) # NameError: name 'b' is not defined
(4) global 和 nonlocal关键字
当在外部作用域中想修改内部作用域的变量时,可以使用global和nonlocal
b = 1
def test():
global b
b = 2
test()
print('global关键字声明全局变量', b) # 2
嵌套作用域中可以使用nonlocal
def test():
b = 1
def inside():
nonlocal b
b = 2
inside()
print('nonlocal关键字修改嵌套作用域', b) # 2
test()
2. 初识类
(1) 类定义语法
当进入类定义时,将创建一个新的命名空间,并将其用作局部作用域
class MyClass:
...
(2) Class对象
类对象支持两种操作,属性引用和实例化,属性引用所使用的标准语法: obj.name
class MyClass:
i = 1
def f(self):
return 'hello world'
print(MyClass.i) # 1
print(MyClass.f) # <function MyClass.f at 0x000001C76FB8AC20>
MyClass.i = 2
print(MyClass.i)
MyClass.i 和 MyClass.f 就是有效的属性引用,分别返回一个整数和一个函数对象。 类属性也可以被赋值,因此可以通过赋值来更改 MyClass.i 的值
类中也可以使用''' '''或者""" """来初始化类的说明
class test:
''' this's test doc '''
i = 3
print(test.__doc__) # this's test doc
print(i) # 3
(3) 类的实例化
python中使用函数表示法来实例化类。 可以把类对象视为能返回该类的一个新实例的 不带参数的函数
x = MyClass() # 将新创建的实例赋给x
我们还可以通过__init__()方法来创建有特定初始状态的自定义实例,而且__init__() 方法还可以有额外参数, 提供给类实例化运算符的参数将被传递给 __init__()
class MyClass:
def __init__(self, x, y):
self.i = x
self.j = y
x = MyClass(1,2)
print(x.i) # 1
print(x.j) # 2
(4) 实例对象
实例对象所能理解的唯一操作是属性引用。一共有两种有效的属性名称
- 数据属性
数据属性不用声明,和局部变量一样将在第一次赋值时产生 - 方法
实例对象的有效方法名称依赖于所属的类,根据定义,一个类中所有是函数对象的属性都是其实例中定义的相应方法。
class MyClass:
i = 1
def f(self):
return 'hello world'
x = MyClass()
a = x.f
print(x.f()) # 'hello world'
print(a()) # 'hello world'
上面例子中x.f 是方法对象, MyClass.f 是函数对象,方法对象可以被保存起来等待后期需要的时候调用
虽然MyClass类中函数f需要一个参数,但是我们调用实例的f方法时却没有传参数,这是因为方法调用时会将实例对象作为第一个参数,x.f()相当于MyClass.f(x)
(5) 类变量和实例变量
-
初始化实例时的变量是每个实例的唯一数据
-
类变量是所有实例共享的属性和方法
class person:
sex: man
def __init__(self, name):
self.name = name
a = preson('阿花')
b = person('ryan')
a.sex == b.sex # true
print(a.name) # '阿花'
print(b.name) # 'ryan'
(6) 列表、字典等可变对象用作类变量
类变量是可变类型时可能会导致数据共享
class persons:
names = []
def __init__(self, sex):
self.sex = sex
def add_name(self, name):
self.names.append(name)
a = persons('man')
b = persons('woman')
a.add_name('阿花')
b.add_name('ryan')
print(b.names) # ['阿花', 'ryan']
所以类变量是可变类型时要使用实例变量
class person:
def __init__(self,name):
self.names = [] # create a new list for each person instance
self.name = name
def add_name(self,name):
self.names.append(name)
a = person('woman')
b = person('man')
a.add_name('阿花')
b.add_name('ryan')
print(a.names) # ['阿花']
当类和实例中出现同名属性时,会优先在实例属性中查找
class MyClass:
i = 1
j = 2
sonClass = MyClass()
sonClass.i = 'python'
print(sonClass.i, sonClass.j)
3. 继承
类继承语法如下
class inheritClass(baseClass)
pass
其中baseClass为基类,inheritClass为派生类,派生类会继承基类的属性和方法,当然派生类中也可以对基类的属性和方法进行重写(不影响基类)
class MyClass:
i = 1
j = 2
def fn(self):
print(self.i)
class inheritClass(MyClass):
a = 11
def inheritFn(self):
MyClass.fn(self)
print(self.a)
print(self.j)
ww = inheritClass()
ww.inheritFn()
(1) 实例判断
-
issubclass(son, father)用于判断实例和类的继承关系,son是father的实例或者派生类的实例则返回True,不是则返回False
-
isaubclass(son,father)
(2) 多重继承
在最简单的情况下,可以认为搜索从父类所继承属性的操作是深度优先、从左至右的,当层次结构中存在重叠时不会在同一个类中搜索两次
注:做笔记用,无实际意义