FeatureHasher(特征哈希器)是一种用于处理高维分类特征(如文本或类别特征)的方法。它将特征转换为固定长度的数值向量,以便在机器学习模型中使用。特征哈希通过哈希函数将特征映射到较低维度的向量空间,可以有效地处理大规模和高维数据集。
特征哈希的主要优点是内存效率和计算速度。由于它不需要存储词汇表或其他映射信息,因此可以处理大规模数据集。同时,特征哈希在转换过程中具有较高的计算速度。
特征哈希的主要缺点是信息损失。由于哈希函数可能将不同的特征映射到相同的索引,因此会出现哈希冲突。这种冲突可能导致特征信息的损失,从而影响模型性能。通过增加哈希向量的维度,可以降低哈希冲突的概率,但这会增加存储和计算成本。
特征哈希广泛应用于文本分类、推荐系统和在线学习等领域。例如,在处理文本数据时,特征哈希可以将单词或短语转换为固定长度的向量,而无需构建词袋模型(Bag-of-Words model)或使用词嵌入(Word Embeddings)。尽管特征哈希在某些情况下可能不如其他方法准确,但其内存和计算效率使其在处理大规模数据集时非常有用。
特征哈希器 #
FeatureHasher 将一组分类或数字特征转换为指定维度的稀疏向量。哈希分类列和数字列的规则如下:
对于数值列,该特征在输出向量中的索引为列名的哈希值,其对应值与输入相同。
对于分类列,该特征在输出向量中的索引是字符串“column_name=value”的哈希值,对应的值为1.0。
如果将多个特征投影到同一列中,则累加输出值。有关散列技巧,请参阅 https://en.wikipedia.org/wiki/Feature_hashing 了解详细信息。
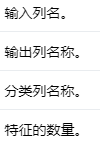
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.featurehasher.FeatureHasher;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates a FeatureHasher instance and uses it for feature engineering. */
public class FeatureHasherExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> dataStream =
env.fromCollection(
Arrays.asList(Row.of(0, "a", 1.0, true), Row.of(1, "c", 1.0, false)));
Table inputDataTable = tEnv.fromDataStream(dataStream).as("id", "f0", "f1", "f2");
// Creates a FeatureHasher object and initializes its parameters.
FeatureHasher featureHash =
new FeatureHasher()
.setInputCols("f0", "f1", "f2")
.setCategoricalCols("f0", "f2")
.setOutputCol("vec")
.setNumFeatures(1000);
// Uses the FeatureHasher object for feature transformations.
Table outputTable = featureHash.transform(inputDataTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Object[] inputValues = new Object[featureHash.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = row.getField(featureHash.getInputCols()[i]);
}
Vector outputValue = (Vector) row.getField(featureHash.getOutputCol());
System.out.printf(
"Input Values: %s \tOutput Value: %s\n",
Arrays.toString(inputValues), outputValue);
}
}
}
Python
# Simple program that creates a FeatureHasher instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.featurehasher import FeatureHasher
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(0, 'a', 1.0, True),
(1, 'c', 1.0, False),
],
type_info=Types.ROW_NAMED(
['id', 'f0', 'f1', 'f2'],
[Types.INT(), Types.STRING(), Types.DOUBLE(), Types.BOOLEAN()])))
# create a feature hasher object and initialize its parameters
feature_hasher = FeatureHasher() \
.set_input_cols('f0', 'f1', 'f2') \
.set_categorical_cols('f0', 'f2') \
.set_output_col('vec') \
.set_num_features(1000)
# use the feature hasher for feature engineering
output = feature_hasher.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in feature_hasher.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(feature_hasher.get_input_cols())):
input_values[i] = result[field_names.index(feature_hasher.get_input_cols()[i])]
output_value = result[field_names.index(feature_hasher.get_output_col())]
print('Input Values: ' + str(input_values) + '\tOutput Value: ' + str(output_value))
HashingTF(哈希术语频率,Hashing Term Frequency)是一种处理文本数据的方法,将文本转换为固定长度的数值向量,以便在机器学习模型中使用。它利用哈希技巧(hashing trick)将文本中的单词映射到一个较低维度的向量空间,从而避免了维持一个完整词汇表的内存开销。HashingTF通常用于创建词袋模型(Bag-of-Words model)或TF-IDF表示,计算文本中各个单词的出现频率。
HashingTF的工作流程如下:
分词(Tokenization):将文本分解为单词(tokens)或其他基本文本单位。
哈希函数:对每个单词应用哈希函数,将其映射到一个固定范围内的整数。这个范围由用户定义的特征向量维度决定。
词频计数:计算每个哈希桶中单词的出现次数,将其作为特征向量的值。
HashingTF的主要优点是内存效率和计算速度。由于不需要存储词汇表,HashingTF可以有效地处理大规模文本数据集。此外,哈希函数的计算速度通常较快,使得HashingTF在处理实时或在线数据时具有优势。
然而,HashingTF的一个缺点是哈希冲突。由于哈希函数可能将不同的单词映射到相同的索引,因此会出现哈希冲突。这种冲突可能导致文本信息的损失,从而影响模型性能。通过增加特征向量的维度,可以降低哈希冲突的概率,但这会增加存储和计算成本。
尽管如此,在处理大规模数据集时,HashingTF仍然是一种有效且高效的文本表示方法。它广泛应用于文本分类、聚类、情感分析等自然语言处理任务中。
哈希TF #
HashingTF 使用散列技巧将一系列术语(字符串、数字、布尔值)映射到具有指定维度的稀疏向量。如果将多个特征投影到同一列中,默认情况下会累加输出值。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.hashingtf.HashingTF;
import org.apache.flink.ml.linalg.SparseVector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
/** Simple program that creates a HashingTF instance and uses it for feature engineering. */
public class HashingTFExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(
Arrays.asList(
"HashingTFTest", "Hashing", "Term", "Frequency", "Test")),
Row.of(
Arrays.asList(
"HashingTFTest", "Hashing", "Hashing", "Test", "Test")));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a HashingTF object and initializes its parameters.
HashingTF hashingTF =
new HashingTF().setInputCol("input").setOutputCol("output").setNumFeatures(128);
// Uses the HashingTF object for feature transformations.
Table outputTable = hashingTF.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
List<Object> inputValue = (List<Object>) row.getField(hashingTF.getInputCol());
SparseVector outputValue = (SparseVector) row.getField(hashingTF.getOutputCol());
System.out.printf(
"Input Value: %s \tOutput Value: %s\n",
Arrays.toString(inputValue.stream().toArray()), outputValue);
}
}
}
Python
# Simple program that creates a HashingTF instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.hashingtf import HashingTF
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data_table = t_env.from_data_stream(
env.from_collection([
(['HashingTFTest', 'Hashing', 'Term', 'Frequency', 'Test'],),
(['HashingTFTest', 'Hashing', 'Hashing', 'Test', 'Test'],),
],
type_info=Types.ROW_NAMED(
["input", ],
[Types.OBJECT_ARRAY(Types.STRING())])))
# Creates a HashingTF object and initializes its parameters.
hashing_tf = HashingTF() \
.set_input_col('input') \
.set_num_features(128) \
.set_output_col('output')
# Uses the HashingTF object for feature transformations.
output = hashing_tf.transform(input_data_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(hashing_tf.get_input_col())]
output_value = result[field_names.index(hashing_tf.get_output_col())]
print('Input Value: ' + ' '.join(input_value) + '\tOutput Value: ' + str(output_value))
IDF(逆文档频率,Inverse Document Frequency)是一种在自然语言处理和信息检索领域中常用的统计度量,用于衡量一个词语在文档集合中的重要性。IDF与TF(术语频率,Term Frequency)共同构成了TF-IDF方法,是一种广泛应用于文本表示的加权技术。
IDF的基本思想是:如果一个词在许多文档中出现,那么它对于区分文档的能力较低。相反,如果一个词仅在少数文档中出现,那么它可能具有较高的区分能力。因此,IDF的目的是降低常见词的权重,提高稀有词的权重。
IDF的计算公式为:
IDF(t) = log(N / (1 + DF(t)))
其中:
t:一个词语(term)。
N:文档集合中文档的总数。
DF(t):包含词语t的文档数量。
log:自然对数。
在TF-IDF方法中,一个词语的权重由其在文档中的术语频率(TF)和在文档集合中的逆文档频率(IDF)相乘得到:
TF-IDF(t, d) = TF(t, d) * IDF(t)
这里,TF(t, d)表示词语t在文档d中的频率。通过计算每个词语的TF-IDF权重,可以将文档表示为一个向量,用于在机器学习模型中进行文本分类、聚类、相似性计算等任务。
需要注意的是,TF-IDF方法不能捕捉上下文信息和词语之间的关系,因此在处理复杂文本问题时可能不够准确。针对这类问题,可以使用词嵌入(Word Embeddings)等更先进的文本表示方法。
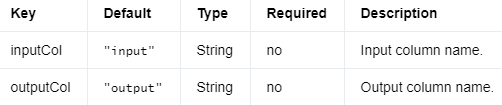
IDF 计算输入文档的逆文档频率 (IDF)。IDF 计算如下 idf = log((m + 1) / (d(t) + 1)),其中m是文档总数,d(t)是包含 的文档数t。
IDFModel 进一步使用计算出的逆文档频率来计算tf-idf。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.idf.IDF;
import org.apache.flink.ml.feature.idf.IDFModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains an IDF model and uses it for feature engineering. */
public class IDFExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(0, 1, 0, 2)),
Row.of(Vectors.dense(0, 1, 2, 3)),
Row.of(Vectors.dense(0, 1, 0, 0)));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates an IDF object and initializes its parameters.
IDF idf = new IDF().setMinDocFreq(2);
// Trains the IDF Model.
IDFModel model = idf.fit(inputTable);
// Uses the IDF Model for predictions.
Table outputTable = model.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(idf.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(idf.getOutputCol());
System.out.printf("Input Value: %s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains an IDF model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.idf import IDF
from pyflink.table import StreamTableEnvironment
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input for training and prediction.
input_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(0, 1, 0, 2),),
(Vectors.dense(0, 1, 2, 3),),
(Vectors.dense(0, 1, 0, 0),),
],
type_info=Types.ROW_NAMED(
['input', ],
[DenseVectorTypeInfo(), ])))
# Creates an IDF object and initializes its parameters.
idf = IDF().set_min_doc_freq(2)
# Trains the IDF Model.
model = idf.fit(input_table)
# Uses the IDF Model for predictions.
output = model.transform(input_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_index = field_names.index(idf.get_input_col())
output_index = field_names.index(idf.get_output_col())
print('Input Value: ' + str(result[input_index]) +
'\tOutput Value: ' + str(result[output_index]))
Imputer(插值器)是一种用于处理缺失数据的方法,通过插值或估算的方式填补数据集中的缺失值。在数据预处理阶段,处理缺失值是一项重要任务,因为许多机器学习算法无法直接处理含有缺失值的数据。
Imputer根据不同的策略来填补缺失值,常见的策略包括:
均值插补(Mean imputation):使用特征列的均值填补缺失值。这种方法适用于连续数值特征,但可能会导致数据分布偏斜。
中位数插补(Median imputation):使用特征列的中位数填补缺失值。这种方法适用于连续数值特征,对异常值和偏斜分布的数据更具鲁棒性。
众数插补(Mode imputation):使用特征列的众数填补缺失值。这种方法适用于分类特征。
常数插补(Constant imputation):使用一个常数值填补缺失值。这种方法可以用于分类或数值特征,但可能会导致数据分布偏斜。
K近邻插补(K-Nearest Neighbors imputation):使用与具有缺失值的样本最近的K个样本的平均值或众数填补缺失值。这种方法可以用于分类或数值特征,但计算成本较高。
除了上述策略,还可以使用更复杂的方法处理缺失值,如使用回归模型预测缺失值、基于矩阵分解的插补方法等。在处理缺失值时,选择合适的插值策略取决于数据类型、数据分布以及实际问题的需求。
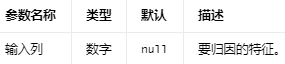
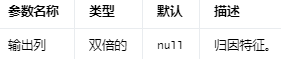
用于完成输入列缺失值的输入。
可以使用缺失值所在的每一列的统计数据(mean/median/most均值、中值或最频繁值)来估算缺失值。输入列应该是数字类型。
注意mean//值是在过滤掉缺失值和空值后计算的,空值始终被median视为most frequent缺失,因此也被估算。
注意该参数relativeError仅在策略为 时有效median。
Input Columns #
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #
编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
缺失值的占位符。所有出现的缺失值都将被估算。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
策略与相对误差

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.imputer.Imputer;
import org.apache.flink.ml.feature.imputer.ImputerModel;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that trains a {@link Imputer} model and uses it for feature engineering. */
public class ImputerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(Double.NaN, 9.0),
Row.of(1.0, 9.0),
Row.of(1.5, 9.0),
Row.of(2.5, Double.NaN),
Row.of(5.0, 5.0),
Row.of(5.0, 4.0));
Table trainTable = tEnv.fromDataStream(trainStream).as("input1", "input2");
// Creates an Imputer object and initialize its parameters
Imputer imputer =
new Imputer()
.setInputCols("input1", "input2")
.setOutputCols("output1", "output2")
.setStrategy("mean")
.setMissingValue(Double.NaN);
// Trains the Imputer model.
ImputerModel model = imputer.fit(trainTable);
// Uses the Imputer model for predictions.
Table outputTable = model.transform(trainTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
double[] inputValues = new double[imputer.getInputCols().length];
double[] outputValues = new double[imputer.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = (double) row.getField(imputer.getInputCols()[i]);
outputValues[i] = (double) row.getField(imputer.getOutputCols()[i]);
}
System.out.printf(
"Input Values: %s\tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# Simple program that creates an Imputer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.imputer import Imputer
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_data = t_env.from_data_stream(
env.from_collection([
(float('NaN'), 9.0,),
(1.0, 9.0,),
(1.5, 7.0,),
(1.5, float('NaN'),),
(4.0, 5.0,),
(None, 4.0,),
],
type_info=Types.ROW_NAMED(
['input1', 'input2'],
[Types.DOUBLE(), Types.DOUBLE()])
))
# Creates an Imputer object and initializes its parameters.
imputer = Imputer()\
.set_input_cols('input1', 'input2')\
.set_output_cols('output1', 'output2')\
.set_strategy('mean')\
.set_missing_value(float('NaN'))
# Trains the Imputer Model.
model = imputer.fit(train_data)
# Uses the Imputer Model for predictions.
output = model.transform(train_data)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_values = []
output_values = []
for i in range(len(imputer.get_input_cols())):
input_values.append(result[field_names.index(imputer.get_input_cols()[i])])
output_values.append(result[field_names.index(imputer.get_output_cols()[i])])
print('Input Values: ' + str(input_values) + '\tOutput Values: ' + str(output_values))
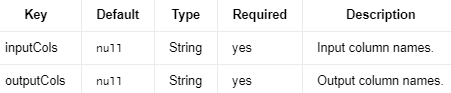
IndexToString(索引到字符串)是一种在数据预处理和后处理过程中使用的转换方法,用于将数值索引映射回原始的类别标签(通常是字符串)。这种转换通常在编码和解码类别特征或机器学习模型的预测结果时使用。
在许多机器学习任务中,特征和标签需要以数值形式表示。对于类别数据(如文本标签),可以使用StringIndexer(字符串到索引)等编码方法将类别标签转换为整数索引。然后,可以将这些数值输入到机器学习模型中进行训练和预测。
在模型预测完成后,可能需要将预测结果(数值索引)转换回原始的类别标签。这时可以使用IndexToString方法进行转换。这种转换依赖于在编码过程中创建的映射关系(即字符串标签与数值索引之间的对应关系),通常需要将这些映射关系存储以便在后处理过程中使用。
例如,在文本分类任务中,可能需要将文本标签(如“positive”和“negative”)转换为数值索引(如0和1),然后将预测结果(数值索引)转换回原始的文本标签。通过使用IndexToString方法,可以在数据预处理和后处理过程中实现这种转换。
IndexToStringModel使用 StringIndexer 计算的模型数据将输入索引列转换为字符串列。它是 StringIndexerModel 的反向操作。
Input Columns #
Output Columns #
Parameters #
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.stringindexer.IndexToStringModel;
import org.apache.flink.ml.feature.stringindexer.StringIndexerModelData;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/**
* Simple program that creates an IndexToStringModelExample instance and uses it for feature
* engineering.
*/
public class IndexToStringModelExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Creates model data for IndexToStringModel.
StringIndexerModelData modelData =
new StringIndexerModelData(
new String[][] {{"a", "b", "c", "d"}, {"-1.0", "0.0", "1.0", "2.0"}});
Table modelTable = tEnv.fromDataStream(env.fromElements(modelData)).as("stringArrays");
// Generates input data.
DataStream<Row> predictStream = env.fromElements(Row.of(0, 3), Row.of(1, 2));
Table predictTable = tEnv.fromDataStream(predictStream).as("inputCol1", "inputCol2");
// Creates an indexToStringModel object and initializes its parameters.
IndexToStringModel indexToStringModel =
new IndexToStringModel()
.setInputCols("inputCol1", "inputCol2")
.setOutputCols("outputCol1", "outputCol2")
.setModelData(modelTable);
// Uses the indexToStringModel object for feature transformations.
Table outputTable = indexToStringModel.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
int[] inputValues = new int[indexToStringModel.getInputCols().length];
String[] outputValues = new String[indexToStringModel.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = (int) row.getField(indexToStringModel.getInputCols()[i]);
outputValues[i] = (String) row.getField(indexToStringModel.getOutputCols()[i]);
}
System.out.printf(
"Input Values: %s \tOutput Values: %s\n",
Arrays.toString(inputValues), Arrays.toString(outputValues));
}
}
}
Python
# Simple program that creates an IndexToStringModelExample instance and uses it
# for feature engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.stringindexer import IndexToStringModel
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
predict_table = t_env.from_data_stream(
env.from_collection([
(0, 3),
(1, 2),
],
type_info=Types.ROW_NAMED(
['input_col1', 'input_col2'],
[Types.INT(), Types.INT()])
))
# create an index-to-string model and initialize its parameters and model data
model_data_table = t_env.from_data_stream(
env.from_collection([
([['a', 'b', 'c', 'd'], [-1., 0., 1., 2.]],),
],
type_info=Types.ROW_NAMED(
['stringArrays'],
[Types.OBJECT_ARRAY(Types.OBJECT_ARRAY(Types.STRING()))])
))
model = IndexToStringModel() \
.set_input_cols('input_col1', 'input_col2') \
.set_output_cols('output_col1', 'output_col2') \
.set_model_data(model_data_table)
# use the index-to-string model for feature engineering
output = model.transform(predict_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in model.get_input_cols()]
output_values = [None for _ in model.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(model.get_input_cols())):
input_values[i] = result[field_names.index(model.get_input_cols()[i])]
output_values[i] = result[field_names.index(model.get_output_cols()[i])]
print('Input Values: ' + str(input_values) + '\tOutput Values: ' + str(output_values))
Interaction(交互作用)是指在统计建模和机器学习中,两个或多个特征之间的相互影响。当特征之间的关系不仅仅是各自独立的线性关系,而是它们相互影响和改变对结果的影响时,就称为存在交互作用。在建模过程中,识别并处理交互作用是提高模型准确性的一个关键步骤。
例如,在房价预测问题中,假设有两个特征:房屋面积(A)和距离市中心的距离(B)。单独考虑这两个特征时,可能会发现面积越大,房价越高;距离市中心越近,房价越高。然而,当同时考虑这两个特征时,可能会发现一个交互作用:对于靠近市中心的房屋,面积对房价的影响可能更大。在这种情况下,模型需要捕捉到这种交互作用以获得更准确的预测。
在机器学习中,有多种方法可以处理交互作用:
特征组合:将具有交互作用的特征进行组合,创建新的特征。例如,对于数值特征,可以通过相乘或相除等操作创建新的特征。对于类别特征,可以通过将两个或多个特征的类别组合成新的类别来捕捉交互作用。
高阶特征:在多项式回归和支持向量机(SVM)等模型中,可以通过引入高阶特征来捕捉交互作用。例如,在多项式回归中,可以包含特征的平方项和交叉项,以表示特征之间的非线性关系。
树模型:决策树和基于树的集成模型(如随机森林和梯度提升树)能够自然地捕捉特征之间的交互作用,因为树结构可以表示特征组合的条件关系。
处理交互作用的关键在于理解数据的结构和特征之间的关系。通过观察数据、计算特征之间的相关性或使用特征选择方法,可以识别和处理潜在的交互作用,从而提高模型的性能。
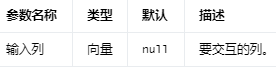
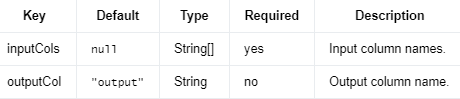
Interaction 采用向量或数字列,并生成一个向量列,其中包含每个输入列中一个值的所有组合的乘积。
例如,当输入特征值为 Double(2) 和 Vector(3, 4) 时,输出将为 Vector(6, 8)。当输入特征值为 Vector(1, 2) 和 Vector(3, 4) 时,输出将为 Vector(3, 4, 6, 8)。如果更改这两个输入向量的位置,则输出将为 Vector(3, 6, 4, 8)。
Input Columns #
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.interaction.Interaction;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates an Interaction instance and uses it for feature engineering. */
public class InteractionExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(0, Vectors.dense(1.1, 3.2), Vectors.dense(2, 3)),
Row.of(1, Vectors.dense(2.1, 3.1), Vectors.dense(1, 3)));
Table inputTable = tEnv.fromDataStream(inputStream).as("f0", "f1", "f2");
// Creates an Interaction object and initializes its parameters.
Interaction interaction =
new Interaction().setInputCols("f0", "f1", "f2").setOutputCol("outputVec");
// Transforms input data.
Table outputTable = interaction.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Object[] inputValues = new Object[interaction.getInputCols().length];
for (int i = 0; i < inputValues.length; i++) {
inputValues[i] = row.getField(interaction.getInputCols()[i]);
}
Vector outputValue = (Vector) row.getField(interaction.getOutputCol());
System.out.printf(
"Input Values: %s \tOutput Value: %s\n",
Arrays.toString(inputValues), outputValue);
}
}
}
Python
# Simple program that creates an Interaction instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.interaction import Interaction
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1,
Vectors.dense(1, 2),
Vectors.dense(3, 4)),
(2,
Vectors.dense(2, 8),
Vectors.dense(3, 4))
],
type_info=Types.ROW_NAMED(
['f0', 'f1', 'f2'],
[Types.INT(), DenseVectorTypeInfo(), DenseVectorTypeInfo()])))
# create an interaction object and initialize its parameters
interaction = Interaction() \
.set_input_cols('f0', 'f1', 'f2') \
.set_output_col('interaction_vec')
# use the interaction for feature engineering
output = interaction.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
input_values = [None for _ in interaction.get_input_cols()]
for result in t_env.to_data_stream(output).execute_and_collect():
for i in range(len(interaction.get_input_cols())):
input_values[i] = result[field_names.index(interaction.get_input_cols()[i])]
output_value = result[field_names.index(interaction.get_output_col())]
print('Input Values: ' + str(input_values) + '\tOutput Value: ' + str(output_value))
KBinsDiscretizer(K分箱离散化器)是一种用于将连续数值特征转换为离散类别特征的方法。通过将特征值分布划分为K个等宽或等深的区间(即“箱子”),KBinsDiscretizer可以将连续特征转换为有序的离散特征。在某些情况下,离散化可以提高模型的性能,特别是在处理非线性关系或减少噪声的情况下。
KBinsDiscretizer通常支持以下几种离散化策略:
等宽分箱(Uniform width bins):将特征值的整个范围均匀地划分为K个等宽区间。这种方法简单易用,但对于有异常值或偏斜分布的数据可能不够准确。
等深分箱(Quantile bins):将特征值划分为具有相等数量数据点的K个区间。这种方法可以更好地适应数据的分布,尤其是对于偏斜分布的数据具有较好的效果。
K均值分箱(K-means bins):使用K-means聚类算法将特征值划分为K个区间。这种方法可以根据数据的分布自动确定区间边界,但计算成本较高。
在使用KBinsDiscretizer时,需要选择合适的K值和离散化策略。选择较小的K值可以降低模型的复杂度,但可能导致信息损失;选择较大的K值可以保留更多信息,但可能导致模型过拟合。通过交叉验证或其他模型选择方法,可以确定最佳的K值和离散化策略。
需要注意的是,离散化可能会导致一定程度的信息损失,因此在应用KBinsDiscretizer之前,需要根据实际问题和数据特点权衡利弊。在某些情况下,使用其他特征工程方法(如特征缩放或特征转换)可能更加合适。
Bucketizer 允许用户自定义分箱边界,即指定每个桶的范围。这使得用户可以根据实际问题和数据特点灵活地设定离散化策略。而 KBinsDiscretizer 则提供了三种自动确定分箱边界的策略:uniform(等宽),quantile(等位)和 kmeans(基于 k-均值聚类)。这使得用户无需事先了解数据分布,就能进行离散化。
Bucketizer 将离散化后的数据直接映射为整数值,这些整数值表示原始数据所属的桶索引。而 KBinsDiscretizer 则提供了多种编码选项,如:ordinal(顺序编码,类似于 Bucketizer),onehot(独热编码)和 onehot-dense(独热编码的密集表示)。这使得 KBinsDiscretizer 更灵活,能满足更多种场景的需求。
KBinsDiscretizer #
KBinsDiscretizer 是一种实现离散化(也称为量化或合并)以将连续特征转换为离散特征的算法。输出值在 [0, numBins) 中。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
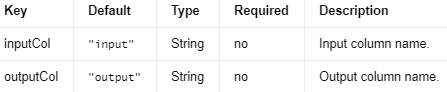
编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.kbinsdiscretizer.KBinsDiscretizer;
import org.apache.flink.ml.feature.kbinsdiscretizer.KBinsDiscretizerModel;
import org.apache.flink.ml.feature.kbinsdiscretizer.KBinsDiscretizerParams;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a KBinsDiscretizer model and uses it for feature engineering. */
public class KBinsDiscretizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(1, 10, 0)),
Row.of(Vectors.dense(1, 10, 0)),
Row.of(Vectors.dense(1, 10, 0)),
Row.of(Vectors.dense(4, 10, 0)),
Row.of(Vectors.dense(5, 10, 0)),
Row.of(Vectors.dense(6, 10, 0)),
Row.of(Vectors.dense(7, 10, 0)),
Row.of(Vectors.dense(10, 10, 0)),
Row.of(Vectors.dense(13, 10, 3)));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a KBinsDiscretizer object and initializes its parameters.
KBinsDiscretizer kBinsDiscretizer =
new KBinsDiscretizer().setNumBins(3).setStrategy(KBinsDiscretizerParams.UNIFORM);
// Trains the KBinsDiscretizer Model.
KBinsDiscretizerModel model = kBinsDiscretizer.fit(inputTable);
// Uses the KBinsDiscretizer Model for predictions.
Table outputTable = model.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(kBinsDiscretizer.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(kBinsDiscretizer.getOutputCol());
System.out.printf("Input Value: %s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a KBinsDiscretizer model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.kbinsdiscretizer import KBinsDiscretizer
from pyflink.table import StreamTableEnvironment
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input for training and prediction.
input_table = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(1, 10, 0),),
(Vectors.dense(1, 10, 0),),
(Vectors.dense(1, 10, 0),),
(Vectors.dense(4, 10, 0),),
(Vectors.dense(5, 10, 0),),
(Vectors.dense(6, 10, 0),),
(Vectors.dense(7, 10, 0),),
(Vectors.dense(10, 10, 0),),
(Vectors.dense(13, 10, 0),),
],
type_info=Types.ROW_NAMED(
['input', ],
[DenseVectorTypeInfo(), ])))
# Creates a KBinsDiscretizer object and initializes its parameters.
k_bins_discretizer = KBinsDiscretizer() \
.set_input_col('input') \
.set_output_col('output') \
.set_num_bins(3) \
.set_strategy('uniform')
# Trains the KBinsDiscretizer Model.
model = k_bins_discretizer.fit(input_table)
# Uses the KBinsDiscretizer Model for predictions.
output = model.transform(input_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
print('Input Value: ' + str(result[field_names.index(k_bins_discretizer.get_input_col())])
+ '\tOutput Value: ' +
str(result[field_names.index(k_bins_discretizer.get_output_col())]))
MaxAbsScaler(最大绝对值缩放器)是一种特征缩放方法,用于将数值特征的数据范围缩放到[-1, 1]区间。这种缩放方法通过将每个特征的值除以该特征的最大绝对值来实现。MaxAbsScaler对于稀疏数据集和那些零中心化不适用的数据集特别有用,因为它不会破坏数据的稀疏性。
MaxAbsScaler的计算公式为:
X_scaled = X / max(abs(X))
其中:
X:原始特征值。
abs(X):特征值的绝对值。
max(abs(X)):特征列中最大的绝对值。
X_scaled:缩放后的特征值。
最大绝对值缩放是一种简单且适用于多种情况的特征缩放方法。然而,它对于存在异常值的数据可能不够鲁棒,因为异常值可能导致其他数据点被压缩到一个非常小的范围内。在这种情况下,可以考虑使用其他特征缩放方法,如标准化(StandardScaler)或最小-最大缩放(MinMaxScaler)。
在许多机器学习算法中,特征缩放是一个重要的预处理步骤。通过将特征缩放到相同的范围,可以确保所有特征在模型中具有相同的权重,从而提高模型的性能。特别是对于依赖于特征距离或梯度下降的算法(如K-近邻、支持向量机和神经网络),特征缩放至关重要。
MaxAbsScaler #
MaxAbsScaler 是一种算法,通过除以每个特征中的最大最大绝对值,将特征值重新缩放到范围 [-1, 1]。它不会移动/居中数据,因此不会破坏任何稀疏性。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
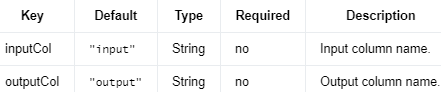
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.maxabsscaler.MaxAbsScaler;
import org.apache.flink.ml.feature.maxabsscaler.MaxAbsScalerModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a MaxAbsScaler model and uses it for feature engineering. */
public class MaxAbsScalerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(0.0, 3.0)),
Row.of(Vectors.dense(2.1, 0.0)),
Row.of(Vectors.dense(4.1, 5.1)),
Row.of(Vectors.dense(6.1, 8.1)),
Row.of(Vectors.dense(200, 400)));
Table trainTable = tEnv.fromDataStream(trainStream).as("input");
DataStream<Row> predictStream =
env.fromElements(
Row.of(Vectors.dense(150.0, 90.0)),
Row.of(Vectors.dense(50.0, 40.0)),
Row.of(Vectors.dense(100.0, 50.0)));
Table predictTable = tEnv.fromDataStream(predictStream).as("input");
// Creates a MaxAbsScaler object and initializes its parameters.
MaxAbsScaler maxAbsScaler = new MaxAbsScaler();
// Trains the MaxAbsScaler Model.
MaxAbsScalerModel maxAbsScalerModel = maxAbsScaler.fit(trainTable);
// Uses the MaxAbsScaler Model for predictions.
Table outputTable = maxAbsScalerModel.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(maxAbsScaler.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(maxAbsScaler.getOutputCol());
System.out.printf("Input Value: %-15s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a MaxAbsScaler model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.maxabsscaler import MaxAbsScaler
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(0.0, 3.0),),
(Vectors.dense(2.1, 0.0),),
(Vectors.dense(4.1, 5.1),),
(Vectors.dense(6.1, 8.1),),
(Vectors.dense(200, 400),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])
))
predict_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(150.0, 90.0),),
(Vectors.dense(50.0, 40.0),),
(Vectors.dense(100.0, 50.0),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])
))
# create a maxabs scaler object and initialize its parameters
max_abs_scaler = MaxAbsScaler()
# train the maxabs scaler model
model = max_abs_scaler.fit(train_data)
# use the maxabs scaler model for predictions
output = model.transform(predict_data)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(max_abs_scaler.get_input_col())]
output_value = result[field_names.index(max_abs_scaler.get_output_col())]
print('Input Value: ' + str(input_value) + ' \tOutput Value: ' + str(output_value))
MinHashLSH(MinHash局部敏感哈希)是一种用于处理大规模数据集中的相似性搜索问题的技术。它基于MinHash(最小哈希)算法和局部敏感哈希(Locality Sensitive Hashing,LSH)的概念。MinHashLSH主要用于处理高维数据(如文本、图像等),可以在短时间内找到相似的数据点。
MinHash是一种用于估计集合相似性的哈希方法,特别适用于处理稀疏集合(如文本数据)。它通过将集合中的元素映射到多个哈希签名来工作,这些哈希签名可以用于估计集合之间的Jaccard相似性(两个集合交集与并集之比)。
局部敏感哈希(LSH)是一种将高维数据映射到低维空间的哈希方法,旨在保留相似数据点之间的距离关系。在LSH中,相似的数据点有更高的概率映射到相同的哈希桶。这种方法可以有效地降低搜索空间,从而提高相似性搜索的速度。
MinHashLSH结合了MinHash和LSH的优点,可以在大规模高维数据集中快速找到相似的数据点。在实际应用中,MinHashLSH可用于处理各种相似性搜索问题,如文档去重、文本相似性检测、图像搜索等。由于其在大规模数据集上的高效性能,MinHashLSH在推荐系统、信息检索、数据挖掘等领域具有广泛的应用。
MinHashLSH #
MinHashLSH 是 Jaccard 距离度量的局部敏感散列 (LSH) 方案。输入特征是表示为向量的非零索引的自然数集,可以是密集向量,也可以是稀疏向量。通常,稀疏向量更有效。
除了将输入特征向量转换为多个哈希值外,MinHashLSH 模型还支持数据集中关于关键向量的近似最近邻搜索和两个数据集之间的近似相似连接。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
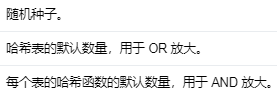
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.ml.feature.lsh.MinHashLSH;
import org.apache.flink.ml.feature.lsh.MinHashLSHModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.SparseVector;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.commons.collections.IteratorUtils;
import java.util.Arrays;
import java.util.List;
import static org.apache.flink.table.api.Expressions.$;
/**
*简单的程序,用于训练 MinHashLSH 模型,并用于近似最近邻和相似性连接。
*/
public class MinHashLSHExample {
public static void main(String[] args) throws Exception {
// Creates a new StreamExecutionEnvironment.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Creates a StreamTableEnvironment.
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates two datasets.
Table dataA =
tEnv.fromDataStream(
env.fromCollection(
Arrays.asList(
Row.of(
0,
Vectors.sparse(
6,
new int[] {0, 1, 2},
new double[] {1., 1., 1.})),
Row.of(
1,
Vectors.sparse(
6,
new int[] {2, 3, 4},
new double[] {1., 1., 1.})),
Row.of(
2,
Vectors.sparse(
6,
new int[] {0, 2, 4},
new double[] {1., 1., 1.}))),
Types.ROW_NAMED(
new String[] {"id", "vec"},
Types.INT,
TypeInformation.of(SparseVector.class))));
Table dataB =
tEnv.fromDataStream(
env.fromCollection(
Arrays.asList(
Row.of(
3,
Vectors.sparse(
6,
new int[] {1, 3, 5},
new double[] {1., 1., 1.})),
Row.of(
4,
Vectors.sparse(
6,
new int[] {2, 3, 5},
new double[] {1., 1., 1.})),
Row.of(
5,
Vectors.sparse(
6,
new int[] {1, 2, 4},
new double[] {1., 1., 1.}))),
Types.ROW_NAMED(
new String[] {"id", "vec"},
Types.INT,
TypeInformation.of(SparseVector.class))));
// 创建 MinHashLSH 估计器对象并初始化其参数。
MinHashLSH lsh =
new MinHashLSH()
.setInputCol("vec")
.setOutputCol("hashes")
.setSeed(2022)
.setNumHashTables(5);
// Trains the MinHashLSH model.
MinHashLSHModel model = lsh.fit(dataA);
// Uses the MinHashLSH model for transformation.
Table output = model.transform(dataA)[0];
// Extracts and displays the results.
List<String> fieldNames = output.getResolvedSchema().getColumnNames();
for (Row result :
(List<Row>) IteratorUtils.toList(tEnv.toDataStream(output).executeAndCollect())) {
Vector inputValue = result.getFieldAs(fieldNames.indexOf(lsh.getInputCol()));
DenseVector[] outputValue = result.getFieldAs(fieldNames.indexOf(lsh.getOutputCol()));
System.out.printf(
"Vector: %s \tHash values: %s\n", inputValue, Arrays.toString(outputValue));
}
// 查找关键字的近似最近邻。
Vector key = Vectors.sparse(6, new int[] {1, 3}, new double[] {1., 1.});
output = model.approxNearestNeighbors(dataA, key, 2).select($("id"), $("distCol"));
for (Row result :
(List<Row>) IteratorUtils.toList(tEnv.toDataStream(output).executeAndCollect())) {
int idValue = result.getFieldAs(fieldNames.indexOf("id"));
double distValue = result.getFieldAs(result.getArity() - 1);
System.out.printf("ID: %d \tDistance: %f\n", idValue, distValue);
}
// 大致找到距离小于阈值的两个数据集的对。
output = model.approxSimilarityJoin(dataA, dataB, .6, "id");
for (Row result :
(List<Row>) IteratorUtils.toList(tEnv.toDataStream(output).executeAndCollect())) {
int idAValue = result.getFieldAs(0);
int idBValue = result.getFieldAs(1);
double distValue = result.getFieldAs(2);
System.out.printf(
"ID from left: %d \tID from right: %d \t Distance: %f\n",
idAValue, idAValue, distValue);
}
}
}
Python
# 简单的程序,用于训练 MinHashLSH 模型,并用于近似最近邻和相似性连接。
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
from pyflink.ml.linalg import Vectors, SparseVectorTypeInfo
from pyflink.ml.feature.lsh import MinHashLSH
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates two datasets.
data_a = t_env.from_data_stream(
env.from_collection([
(0, Vectors.sparse(6, [0, 1, 2], [1., 1., 1.])),
(1, Vectors.sparse(6, [2, 3, 4], [1., 1., 1.])),
(2, Vectors.sparse(6, [0, 2, 4], [1., 1., 1.])),
], type_info=Types.ROW_NAMED(['id', 'vec'], [Types.INT(), SparseVectorTypeInfo()])))
data_b = t_env.from_data_stream(
env.from_collection([
(3, Vectors.sparse(6, [1, 3, 5], [1., 1., 1.])),
(4, Vectors.sparse(6, [2, 3, 5], [1., 1., 1.])),
(5, Vectors.sparse(6, [1, 2, 4], [1., 1., 1.])),
], type_info=Types.ROW_NAMED(['id', 'vec'], [Types.INT(), SparseVectorTypeInfo()])))
# 创建 MinHashLSH 估计器对象并初始化其参数。
lsh = MinHashLSH() \
.set_input_col('vec') \
.set_output_col('hashes') \
.set_seed(2022) \
.set_num_hash_tables(5)
# Trains the MinHashLSH model.
model = lsh.fit(data_a)
# Uses the MinHashLSH model for transformation.
output = model.transform(data_a)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(lsh.get_input_col())]
output_value = result[field_names.index(lsh.get_output_col())]
print(f'Vector: {input_value} \tHash Values: {output_value}')
# 查找关键字的近似最近邻。
key = Vectors.sparse(6, [1, 3], [1., 1.])
output = model.approx_nearest_neighbors(data_a, key, 2).select("id, distCol")
for result in t_env.to_data_stream(output).execute_and_collect():
id_value = result[field_names.index("id")]
dist_value = result[-1]
print(f'ID: {id_value} \tDistance: {dist_value}')
# 大致找到距离小于阈值的两个数据集的对。
output = model.approx_similarity_join(data_a, data_b, .6, "id")
for result in t_env.to_data_stream(output).execute_and_collect():
id_a_value, id_b_value, dist_value = result
print(f'ID from left: {id_a_value} \tID from right: {id_b_value} \t Distance: {dist_value}')
MinMaxScaler(最小-最大缩放器)是一种用于将数值特征的数据范围缩放到指定区间(通常为[0, 1])的特征缩放方法。这种缩放方法通过将每个特征的值减去该特征的最小值,然后除以该特征的最大值和最小值之差来实现。
MinMaxScaler的计算公式为:
X_scaled = (X - min(X)) / (max(X) - min(X))
其中:
X:原始特征值。
min(X):特征列中的最小值。
max(X):特征列中的最大值。
X_scaled:缩放后的特征值。
最小-最大缩放是一种简单且适用于多种情况的特征缩放方法。然而,它对于存在异常值的数据可能不够鲁棒,因为异常值可能导致其他数据点被压缩到一个非常小的范围内。在这种情况下,可以考虑使用其他特征缩放方法,如标准化(StandardScaler)或最大绝对值缩放(MaxAbsScaler)。
在许多机器学习算法中,特征缩放是一个重要的预处理步骤。通过将特征缩放到相同的范围,可以确保所有特征在模型中具有相同的权重,从而提高模型的性能。特别是对于依赖于特征距离或梯度下降的算法(如K-近邻、支持向量机和神经网络),特征缩放至关重要。
最小最大缩放器 #
MinMaxScaler 是一种将特征值重新缩放到用户定义的公共范围 [min, max] 的算法。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.minmaxscaler.MinMaxScaler;
import org.apache.flink.ml.feature.minmaxscaler.MinMaxScalerModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a MinMaxScaler model and uses it for feature engineering. */
public class MinMaxScalerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(0.0, 3.0)),
Row.of(Vectors.dense(2.1, 0.0)),
Row.of(Vectors.dense(4.1, 5.1)),
Row.of(Vectors.dense(6.1, 8.1)),
Row.of(Vectors.dense(200, 400)));
Table trainTable = tEnv.fromDataStream(trainStream).as("input");
DataStream<Row> predictStream =
env.fromElements(
Row.of(Vectors.dense(150.0, 90.0)),
Row.of(Vectors.dense(50.0, 40.0)),
Row.of(Vectors.dense(100.0, 50.0)));
Table predictTable = tEnv.fromDataStream(predictStream).as("input");
// Creates a MinMaxScaler object and initializes its parameters.
MinMaxScaler minMaxScaler = new MinMaxScaler();
// Trains the MinMaxScaler Model.
MinMaxScalerModel minMaxScalerModel = minMaxScaler.fit(trainTable);
// Uses the MinMaxScaler Model for predictions.
Table outputTable = minMaxScalerModel.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(minMaxScaler.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(minMaxScaler.getOutputCol());
System.out.printf("Input Value: %-15s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a MinMaxScaler model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.minmaxscaler import MinMaxScaler
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(0.0, 3.0),),
(Vectors.dense(2.1, 0.0),),
(Vectors.dense(4.1, 5.1),),
(Vectors.dense(6.1, 8.1),),
(Vectors.dense(200, 400),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])
))
predict_data = t_env.from_data_stream(
env.from_collection([
(Vectors.dense(150.0, 90.0),),
(Vectors.dense(50.0, 40.0),),
(Vectors.dense(100.0, 50.0),),
],
type_info=Types.ROW_NAMED(
['input'],
[DenseVectorTypeInfo()])
))
# create a min-max-scaler object and initialize its parameters
min_max_scaler = MinMaxScaler()
# train the min-max-scaler model
model = min_max_scaler.fit(train_data)
# use the min-max-scaler model for predictions
output = model.transform(predict_data)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(min_max_scaler.get_input_col())]
output_value = result[field_names.index(min_max_scaler.get_output_col())]
print('Input Value: ' + str(input_value) + ' \tOutput Value: ' + str(output_value))
n-gram(n元组)是一种在自然语言处理(NLP)和文本挖掘中常用的方法,用于表示文本或序列数据中连续的n个元素(如字符或单词)。n-gram用于捕捉文本中的局部模式和依赖关系,有助于分析和建模文本数据。在实际应用中,n-gram可以用于语言建模、文本分类、机器翻译、拼写检查等任务。
n-gram的类型通常取决于元素的粒度。以下是两种常见的n-gram类型:
字符n-gram(Character n-gram):将文本分割为连续的n个字符的序列。例如,对于文本“hello”,2-gram(即bigram)为["he", "el", "ll", "lo"]。
单词n-gram(Word n-gram):将文本分割为连续的n个单词的序列。例如,对于文本“The quick brown fox”,2-gram(即bigram)为["The quick", "quick brown", "brown fox"]。
n的选择取决于实际应用和数据的特点。较小的n值可以捕捉局部信息,但可能丢失长距离依赖;较大的n值可以捕捉更多的上下文信息,但可能导致数据稀疏和计算成本增加。在实际应用中,通常需要根据问题和数据特点选择合适的n值,或使用多个n值的组合。
使用n-gram时,需要注意数据稀疏性和计算成本的问题。随着n的增加,可能的n-gram组合数量会呈指数级增长,导致计算成本增加和数据稀疏性问题。为了解决这些问题,可以使用特征选择、降维或压缩技术来减少特征空间的大小。此外,还可以使用更高效的表示方法(如词嵌入)来捕捉文本的语义信息。
NGram 将输入字符串数组转换为 n-gram 数组,其中每个 n-gram 由空格分隔的单词字符串表示。如果输入数组的长度小于n,则不返回任何 n-gram。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #
编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑
添加图片注释,不超过 140 字(可选)
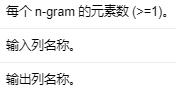
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.ngram.NGram;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates an NGram instance and uses it for feature engineering. */
public class NGramExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of((Object) new String[0]),
Row.of((Object) new String[] {"a", "b", "c"}),
Row.of((Object) new String[] {"a", "b", "c", "d"}));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates an NGram object and initializes its parameters.
NGram nGram = new NGram().setN(2).setInputCol("input").setOutputCol("output");
// Uses the NGram object for feature transformations.
Table outputTable = nGram.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
String[] inputValue = (String[]) row.getField(nGram.getInputCol());
String[] outputValue = (String[]) row.getField(nGram.getOutputCol());
System.out.printf(
"Input Value: %s \tOutput Value: %s\n",
Arrays.toString(inputValue), Arrays.toString(outputValue));
}
}
}
Python
# Simple program that creates an NGram instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.ngram import NGram
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data_table = t_env.from_data_stream(
env.from_collection([
([],),
(['a', 'b', 'c'],),
(['a', 'b', 'c', 'd'],),
],
type_info=Types.ROW_NAMED(
["input", ],
[Types.OBJECT_ARRAY(Types.STRING())])))
# Creates an NGram object and initializes its parameters.
n_gram = NGram() \
.set_input_col('input') \
.set_n(2) \
.set_output_col('output')
# Uses the NGram object for feature transformations.
output = n_gram.transform(input_data_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(n_gram.get_input_col())]
output_value = result[field_names.index(n_gram.get_output_col())]
print('Input Value: ' + ' '.join(input_value) + '\tOutput Value: ' + str(output_value))
Normalizer(规范化器)是一种特征预处理方法,用于将数据点缩放到单位范数。规范化可以确保每个数据点在不同特征之间具有相同的权重,从而提高机器学习模型的性能。特别是对于基于距离度量或梯度下降的算法(如K-近邻、支持向量机和神经网络),规范化至关重要。
规范化通常有以下几种范数:
L1范数(Manhattan范数):每个数据点的特征值之和等于1。计算公式为:||x||_1 = Σ|x_i|。
L2范数(欧几里得范数):每个数据点的特征值平方和等于1。计算公式为:||x||_2 = √(Σx_i^2)。
Max范数(无穷范数):每个数据点的最大特征值绝对值等于1。计算公式为:||x||_∞ = max(|x_i|)。
在规范化过程中,需要根据实际问题和数据特点选择合适的范数。L1范数和L2范数通常用于处理稀疏数据和平滑数据,而Max范数用于处理偏斜分布的数据。
需要注意的是,规范化与特征缩放(如最小-最大缩放和标准化)是不同的概念。特征缩放关注于将特征列缩放到相同的范围,以确保所有特征在模型中具有相同的权重;规范化关注于将数据点缩放到单位范数,以确保每个数据点在不同特征之间具有相同的权重。根据实际问题和数据特点,可以选择合适的预处理方法以提高模型性能。
使用给定的 p 范数将向量归一化为具有单位范数的 Transformer。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
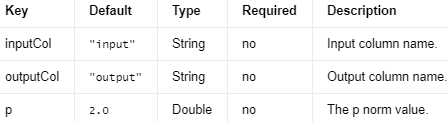
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.normalizer.Normalizer;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that creates a Normalizer instance and uses it for feature engineering. */
public class NormalizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(2.1, 3.1, 1.2, 3.1, 4.6)),
Row.of(Vectors.dense(1.2, 3.1, 4.6, 2.1, 3.1)));
Table inputTable = tEnv.fromDataStream(inputStream).as("inputVec");
// Creates a Normalizer object and initializes its parameters.
Normalizer normalizer =
new Normalizer().setInputCol("inputVec").setP(3.0).setOutputCol("outputVec");
// Uses the Normalizer object for feature transformations.
Table outputTable = normalizer.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector inputValue = (Vector) row.getField(normalizer.getInputCol());
Vector outputValue = (Vector) row.getField(normalizer.getOutputCol());
System.out.printf("Input Value: %s \tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates a Normalizer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.normalizer import Normalizer
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(2.1, 3.1, 1.2, 2.1)),
(2, Vectors.dense(2.3, 2.1, 1.3, 1.2)),
],
type_info=Types.ROW_NAMED(
['id', 'input_vec'],
[Types.INT(), DenseVectorTypeInfo()])))
# create a normalizer object and initialize its parameters
normalizer = Normalizer() \
.set_input_col('input_vec') \
.set_p(1.5) \
.set_output_col('output_vec')
# use the normalizer model for feature engineering
output = normalizer.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(normalizer.get_input_col())]
output_value = result[field_names.index(normalizer.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
OneHotEncoder(独热编码器)是一种常用的特征编码方法,用于将分类特征(categorical features)转换为数值形式,以便在机器学习模型中使用。分类特征通常表示为字符串或整数标签,但并非连续数值。因此,需要通过一种编码方法将这些特征转换为可以在模型中使用的数值形式。
独热编码的基本思想是将每个分类特征的每个类别都表示为一个二进制向量,其中只有与该类别对应的位置为1,其余位置为0。例如,假设有一个分类特征“颜色”,其取值范围为{红色,绿色,蓝色}。对于这个特征,独热编码将其转换为以下三个二进制向量:
红色:[1, 0, 0]
绿色:[0, 1, 0]
蓝色:[0, 0, 1]
独热编码的优点是它将分类特征转换为数值形式,同时不引入任何偏序关系(ordinal relationship),因为每个类别都是独立表示的。这对于不具有明确顺序关系的分类特征特别有用。
然而,独热编码的缺点是它可能导致数据维度的显著增加,尤其是在具有大量类别的分类特征的情况下。这可能会导致计算成本增加和数据稀疏性问题。为了解决这些问题,可以考虑使用降维方法(如主成分分析)或更高效的特征编码方法(如目标编码或实体嵌入)。
目标编码(Target Encoding):
目标编码是一种基于目标变量(响应变量)的分类特征编码方法。对于每个类别,它计算该类别与目标变量之间的平均关联,并用这个平均值替换原始类别。这种编码方法有助于捕捉类别与目标变量之间的关系,从而提高模型性能。
目标编码的一个常见应用是处理高基数分类特征,即具有大量不同类别的特征。这种情况下,独热编码可能导致数据维度的显著增加,从而导致计算成本增加和模型泛化能力下降。目标编码可以有效地降低数据维度,同时保留类别与目标变量之间的信息。
需要注意的是,目标编码可能导致数据泄露(data leakage),因为它直接使用了目标变量的信息。为了避免这个问题,可以使用 K 折交叉验证等技术在训练集内部进行目标编码。
实体嵌入(Entity Embeddings):
实体嵌入是一种将离散特征(通常是分类特征)映射到低维连续向量空间的方法。这种映射可以捕捉特征之间的相似性和关系,从而提高模型的表现和泛化能力。
实体嵌入的核心思想是通过神经网络(通常是深度学习模型)学习连续向量表示,这些表示能够捕捉到原始特征之间的复杂关系。这种方法的一个典型应用是在自然语言处理中,词嵌入(word embeddings)就是实体嵌入的一种。
实体嵌入通常用于处理具有较高基数的分类特征,因为这些特征在独热编码后可能导致过高的数据维度。通过实体嵌入,可以将高维的离散特征压缩为低维连续特征,从而降低计算成本,同时保留特征之间的信息。
在实际应用中,独热编码通常与其他预处理方法(如特征缩放和规范化)结合使用,以提高机器学习模型的性能。在处理分类特征时,需要根据实际问题和数据特点选择合适的编码方法。
OneHotEncoder 将一个分类特征(表示为标签索引)映射到一个二元向量,该向量最多具有一个单值,表示所有特征值集合中特定特征值的存在。这种编码允许期望连续特征的算法(例如 Logistic 回归)使用分类特征。
OneHotEncoder 可以转换多个列,为每个输入列返回一个单热编码输出向量列。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)
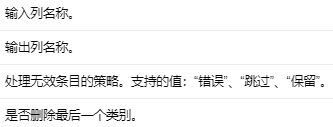
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.onehotencoder.OneHotEncoder;
import org.apache.flink.ml.feature.onehotencoder.OneHotEncoderModel;
import org.apache.flink.ml.linalg.SparseVector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a OneHotEncoder model and uses it for feature engineering. */
public class OneHotEncoderExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(Row.of(0.0), Row.of(1.0), Row.of(2.0), Row.of(0.0));
Table trainTable = tEnv.fromDataStream(trainStream).as("input");
DataStream<Row> predictStream = env.fromElements(Row.of(0.0), Row.of(1.0), Row.of(2.0));
Table predictTable = tEnv.fromDataStream(predictStream).as("input");
// Creates a OneHotEncoder object and initializes its parameters.
OneHotEncoder oneHotEncoder =
new OneHotEncoder().setInputCols("input").setOutputCols("output");
// Trains the OneHotEncoder Model.
OneHotEncoderModel model = oneHotEncoder.fit(trainTable);
// Uses the OneHotEncoder Model for predictions.
Table outputTable = model.transform(predictTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Double inputValue = (Double) row.getField(oneHotEncoder.getInputCols()[0]);
SparseVector outputValue =
(SparseVector) row.getField(oneHotEncoder.getOutputCols()[0]);
System.out.printf("Input Value: %s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that trains a OneHotEncoder model and uses it for feature
# engineering.
from pyflink.common import Row
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.onehotencoder import OneHotEncoder
from pyflink.table import StreamTableEnvironment, DataTypes
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input training and prediction data
train_table = t_env.from_elements(
[Row(0.0), Row(1.0), Row(2.0), Row(0.0)],
DataTypes.ROW([
DataTypes.FIELD('input', DataTypes.DOUBLE())
]))
predict_table = t_env.from_elements(
[Row(0.0), Row(1.0), Row(2.0)],
DataTypes.ROW([
DataTypes.FIELD('input', DataTypes.DOUBLE())
]))
# create a one-hot-encoder object and initialize its parameters
one_hot_encoder = OneHotEncoder().set_input_cols('input').set_output_cols('output')
# train the one-hot-encoder model
model = one_hot_encoder.fit(train_table)
# use the one-hot-encoder model for predictions
output = model.transform(predict_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(one_hot_encoder.get_input_cols()[0])]
output_value = result[field_names.index(one_hot_encoder.get_output_cols()[0])]
print('Input Value: ' + str(input_value) + ' \tOutput Value: ' + str(output_value))
OnlineStandardScaler(在线标准化缩放器)是一种特征预处理方法,用于实时或在线计算数据的均值和标准差,以便将特征缩放到相同的范围。在线标准化缩放器适用于处理大规模数据集和数据流,因为它可以在不存储整个数据集的情况下实时更新均值和标准差。
在线标准化缩放器的工作原理是使用增量算法计算数据的均值和标准差。当新的数据点到达时,它会更新当前的均值和标准差,而无需重新计算整个数据集。在线标准化缩放器将特征值减去当前的均值,然后除以当前的标准差,从而将特征缩放到均值为0,标准差为1的范围。
在线标准化缩放器的主要优点是可以处理大规模数据集和数据流,从而节省存储和计算资源。此外,它可以随时适应数据的变化,使模型更具鲁棒性。然而,与批量标准化方法相比,在线标准化缩放器可能会受到数据的顺序和噪声的影响,导致性能略有下降。
在实际应用中,在线标准化缩放器通常与其他在线预处理方法(如在线规范化和在线特征选择)结合使用,以提高大规模数据集和数据流上的机器学习模型性能。
在线规范化(Online Normalization):
在线规范化是一种实时处理和规范化数据特征的技术。在传统的批量学习中,我们通常在训练开始前对整个数据集进行预处理,如标准化(Standardization)或归一化(Normalization),以消除特征之间的尺度差异。然而,在在线学习中,数据是逐个或逐批次到达的,因此需要对数据进行实时规范化。
在线规范化的常用方法包括在线标准化(Online Standardization)和在线归一化(Online Normalization)。这些方法通常使用滑动窗口或指数加权平均来估计数据的均值和标准差,从而实时地对新到达的数据进行规范化处理。在线规范化可以帮助模型更快地收敛,提高在线学习的性能。
在线特征选择(Online Feature Selection):
在线特征选择是一种在在线学习过程中实时选择和优化特征子集的技术。在许多应用中,特征数量可能非常大,这会导致计算复杂度高、训练时间长以及模型泛化能力下降。在线特征选择旨在通过保留最具信息价值的特征来减小模型的复杂度和计算成本。
在线特征选择的方法通常基于贪婪算法、梯度信息或正则化技术。例如,在线梯度下降法(Online Gradient Descent)可以通过只使用梯度信息的一部分来进行模型更新,从而实现在线特征选择。另外,LASSO 和 Elastic Net 等稀疏正则化方法也可以用于在线特征选择。
在线标准缩放器 #
实现在线标准缩放算法的 Estimator,它是 StandardScaler 的在线版本。
OnlineStandardScaler 通过用户指定的窗口策略拆分输入数据。对于每个窗口,它使用到目前为止看到的数据(即,不仅是当前窗口中的数据,还有历史数据)计算均值和标准偏差。OnlineStandardScaler 生成的模型数据是一个模型流。每个窗口有一个模型数据。
在推理阶段(即使用 OnlineStandardScalerModel 进行预测),用户可以输出用于预测每个数据点的模型版本。而且,
当训练数据和测试数据都包含事件时间时,用户可以指定输入数据和模型数据的时间戳之间的最大差异,强制使用相对较新的模型进行预测。
否则,预测过程总是使用当前模型数据进行预测。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
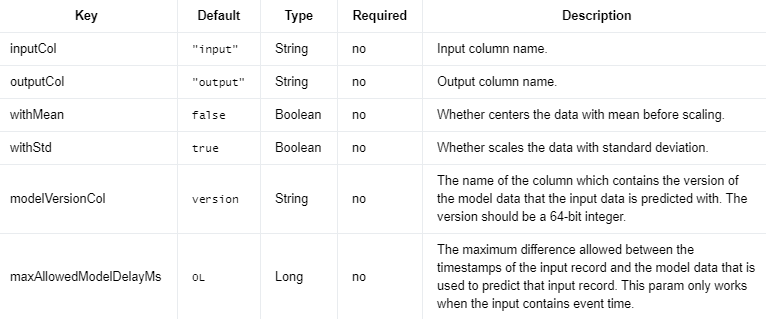
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
确定如何从输入数据创建小批量的窗口策略。
Java
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.ml.common.window.EventTimeTumblingWindows;
import org.apache.flink.ml.feature.standardscaler.OnlineStandardScaler;
import org.apache.flink.ml.feature.standardscaler.OnlineStandardScalerModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.ml.linalg.typeinfo.DenseVectorTypeInfo;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
import java.util.List;
/** Simple program that trains a OnlineStandardScaler model and uses it for feature engineering. */
public class OnlineStandardScalerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
List<Row> inputData =
Arrays.asList(
Row.of(0L, Vectors.dense(-2.5, 9, 1)),
Row.of(1000L, Vectors.dense(1.4, -5, 1)),
Row.of(2000L, Vectors.dense(2, -1, -2)),
Row.of(6000L, Vectors.dense(0.7, 3, 1)),
Row.of(7000L, Vectors.dense(0, 1, 1)),
Row.of(8000L, Vectors.dense(0.5, 0, -2)),
Row.of(9000L, Vectors.dense(0.4, 1, 1)),
Row.of(10000L, Vectors.dense(0.3, 2, 1)),
Row.of(11000L, Vectors.dense(0.5, 1, -2)));
DataStream<Row> inputStream = env.fromCollection(inputData);
DataStream<Row> inputStreamWithEventTime =
inputStream.assignTimestampsAndWatermarks(
WatermarkStrategy.<Row>forMonotonousTimestamps()
.withTimestampAssigner(
(SerializableTimestampAssigner<Row>)
(element, recordTimestamp) ->
element.getFieldAs(0)));
Table inputTable =
tEnv.fromDataStream(
inputStreamWithEventTime,
Schema.newBuilder()
.column("f0", DataTypes.BIGINT())
.column("f1", DataTypes.RAW(DenseVectorTypeInfo.INSTANCE))
.columnByMetadata("rowtime", "TIMESTAMP_LTZ(3)")
.watermark("rowtime", "SOURCE_WATERMARK()")
.build())
.as("id", "input");
// Creates an OnlineStandardScaler object and initializes its parameters.
long windowSizeMs = 3000;
OnlineStandardScaler onlineStandardScaler =
new OnlineStandardScaler()
.setWindows(EventTimeTumblingWindows.of(Time.milliseconds(windowSizeMs)));
// Trains the OnlineStandardScaler Model.
OnlineStandardScalerModel model = onlineStandardScaler.fit(inputTable);
// Uses the OnlineStandardScaler Model for predictions.
Table outputTable = model.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(onlineStandardScaler.getInputCol());
DenseVector outputValue =
(DenseVector) row.getField(onlineStandardScaler.getOutputCol());
long modelVersion = row.getFieldAs(onlineStandardScaler.getModelVersionCol());
System.out.printf(
"Input Value: %s\tOutput Value: %s\tModel Version: %s\n",
inputValue, outputValue, modelVersion);
}
}
}
Python
# Simple program that trains an OnlineStandardScaler model and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.common.time import Time, Instant
from pyflink.java_gateway import get_gateway
from pyflink.table import Schema
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
from pyflink.table.expressions import col
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.onlinestandardscaler import OnlineStandardScaler
from pyflink.ml.common.window import EventTimeTumblingWindows
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input data.
dense_vector_serializer = get_gateway().jvm.org.apache.flink.table.types.logical.RawType(
get_gateway().jvm.org.apache.flink.ml.linalg.DenseVector(0).getClass(),
get_gateway().jvm.org.apache.flink.ml.linalg.typeinfo.DenseVectorSerializer()
).getSerializerString()
schema = Schema.new_builder()
.column("ts", "TIMESTAMP_LTZ(3)")
.column("input", "RAW('org.apache.flink.ml.linalg.DenseVector', '{serializer}')"
.format(serializer=dense_vector_serializer))
.watermark("ts", "ts - INTERVAL '1' SECOND")
.build()
input_data = t_env.from_data_stream(
env.from_collection([
(Instant.of_epoch_milli(0), Vectors.dense(-2.5, 9, 1),),
(Instant.of_epoch_milli(1000), Vectors.dense(1.4, -5, 1),),
(Instant.of_epoch_milli(2000), Vectors.dense(2, -1, -2),),
(Instant.of_epoch_milli(6000), Vectors.dense(0.7, 3, 1),),
(Instant.of_epoch_milli(7000), Vectors.dense(0, 1, 1),),
(Instant.of_epoch_milli(8000), Vectors.dense(0.5, 0, -2),),
(Instant.of_epoch_milli(9000), Vectors.dense(0.4, 1, 1),),
(Instant.of_epoch_milli(10000), Vectors.dense(0.3, 2, 1),),
(Instant.of_epoch_milli(11000), Vectors.dense(0.5, 1, -2),)
],
type_info=Types.ROW_NAMED(
['ts', 'input'],
[Types.INSTANT(), DenseVectorTypeInfo()])),
schema)
# Creates an online standard-scaler object and initialize its parameters.
standard_scaler = OnlineStandardScaler()
.set_windows(EventTimeTumblingWindows.of(Time.milliseconds(3000)))
.set_max_allowed_model_delay_ms(0)
# Trains the online standard-scaler model.
model = standard_scaler.fit(input_data)
# Use the standard-scaler model for predictions.
output = model.transform(input_data)[0]
# extract and display the results
output = output.select(col("input"), col("output"), col("version"))
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(standard_scaler.get_input_col())]
output_value = result[field_names.index(standard_scaler.get_output_col())]
model_version = result[field_names.index(standard_scaler.get_model_version_col())]
print('Input Value: ' + str(input_value) + ' \tOutput Value: ' + str(output_value) +
'\tModel Version: ' + str(model_version))
PolynomialExpansion(多项式扩展)是一种特征预处理方法,用于生成原始特征的多项式组合。通过将原始特征扩展到高维空间,多项式扩展可以帮助捕捉特征之间的非线性关系,从而提高模型的预测能力。它通常用于提高线性模型(如线性回归、逻辑回归和支持向量机)在非线性问题上的性能。
多项式扩展通过生成特征的所有多项式组合来实现,具体包括原始特征、两两特征的乘积、特征的幂等。多项式扩展的度(degree)是一个重要参数,用于控制生成的多项式组合的最高阶数。例如,对于二维特征向量(x1, x2),二阶多项式扩展将生成以下特征向量:
1, x1, x2, x1^2, x1*x2, x2^2
需要注意的是,多项式扩展会导致特征空间的维度显著增加,尤其是在具有大量特征和高阶多项式的情况下。这可能会导致计算成本增加和数据稀疏性问题。为了解决这些问题,可以考虑使用降维方法(如主成分分析)或更高效的非线性特征转换方法(如核方法)。
在实际应用中,多项式扩展通常与其他预处理方法(如特征缩放和规范化)结合使用,以提高模型的性能。在处理非线性问题时,需要根据实际问题和数据特点选择合适的特征扩展方法。
多项式展开 #
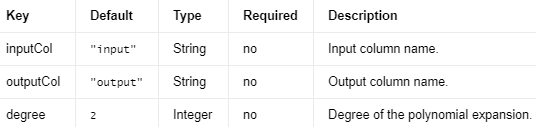
在多项式空间中扩展输入向量的 Transformer。
以一个二维向量为例:(x, y),如果我们想对其进行 2 次展开,则得到(x, x * x, y, x * y, y * y)。
有关多项式展开的更多信息,请参阅 http://en.wikipedia.org/wiki/Polynomial_expansion。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
编辑
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.polynomialexpansion.PolynomialExpansion;
import org.apache.flink.ml.linalg.Vector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that creates a PolynomialExpansion instance and uses it for feature engineering. */
public class PolynomialExpansionExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(Vectors.dense(2.1, 3.1, 1.2)),
Row.of(Vectors.dense(1.2, 3.1, 4.6)));
Table inputTable = tEnv.fromDataStream(inputStream).as("inputVec");
// Creates a PolynomialExpansion object and initializes its parameters.
PolynomialExpansion polynomialExpansion =
new PolynomialExpansion().setInputCol("inputVec").setDegree(2).setOutputCol("outputVec");
// Uses the PolynomialExpansion object for feature transformations.
Table outputTable = polynomialExpansion.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
Vector inputValue = (Vector) row.getField(polynomialExpansion.getInputCol());
Vector outputValue = (Vector) row.getField(polynomialExpansion.getOutputCol());
System.out.printf("Input Value: %s \tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates a PolynomialExpansion instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.polynomialexpansion import PolynomialExpansion
from pyflink.table import StreamTableEnvironment
# create a new StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
# create a StreamTableEnvironment
t_env = StreamTableEnvironment.create(env)
# generate input data
input_data_table = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(2.1, 3.1, 1.2, 2.1)),
(2, Vectors.dense(2.3, 2.1, 1.3, 1.2)),
],
type_info=Types.ROW_NAMED(
['id', 'input_vec'],
[Types.INT(), DenseVectorTypeInfo()])))
# create a polynomial expansion object and initialize its parameters
polynomialExpansion = PolynomialExpansion() \
.set_input_col('input_vec') \
.set_degree(2) \
.set_output_col('output_vec')
# use the polynomial expansion model for feature engineering
output = polynomialExpansion.transform(input_data_table)[0]
# extract and display the results
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(polynomialExpansion.get_input_col())]
output_value = result[field_names.index(polynomialExpansion.get_output_col())]
print('Input Value: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
RandomSplitter(随机分割器)是一种用于将数据集分割为训练集和测试集(或验证集)的方法,通常在机器学习和数据挖掘中用于评估模型的性能。随机分割器通过随机抽样的方式将数据集划分为两个或多个互斥的子集,以实现对模型的训练和评估。
随机分割器的主要优点是可以确保训练集和测试集(或验证集)之间的独立性,从而提高模型性能评估的可靠性。此外,随机分割器可以适应不同的数据分布和模型需求,通过调整训练集和测试集(或验证集)之间的划分比例来平衡模型的训练和评估。
然而,随机分割器的缺点是它可能受到数据的随机性和不平衡的影响,导致模型性能评估的不稳定。为了解决这些问题,可以使用交叉验证(cross-validation)等更高级的模型评估方法,或采用分层抽样(stratified sampling)等策略来保持类别分布的均衡。
在实际应用中,随机分割器通常与其他模型评估方法(如交叉验证)和预处理方法(如特征缩放和规范化)结合使用,以提高模型的性能。在处理不同问题和数据集时,需要根据实际需求选择合适的数据分割方法
随机分配器 #
一个 AlgoOperator,它根据给定的权重将一个表拆分为 N 个表。
Parameters #

编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.randomsplitter.RandomSplitter;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that creates a RandomSplitter instance and uses it for data splitting. */
public class RandomSplitterExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(
Row.of(1, 10, 0),
Row.of(1, 10, 0),
Row.of(1, 10, 0),
Row.of(4, 10, 0),
Row.of(5, 10, 0),
Row.of(6, 10, 0),
Row.of(7, 10, 0),
Row.of(10, 10, 0),
Row.of(13, 10, 3));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a RandomSplitter object and initializes its parameters.
RandomSplitter splitter = new RandomSplitter().setWeights(4.0, 6.0);
// Uses the RandomSplitter to split inputData.
Table[] outputTables = splitter.transform(inputTable);
// Extracts and displays the results.
System.out.println("Split Result 1 (40%)");
for (CloseableIterator<Row> it = outputTables[0].execute().collect(); it.hasNext(); ) {
System.out.printf("%s\n", it.next());
}
System.out.println("Split Result 2 (60%)");
for (CloseableIterator<Row> it = outputTables[1].execute().collect(); it.hasNext(); ) {
System.out.printf("%s\n", it.next());
}
}
}
Python
# Simple program that creates a RandomSplitter instance and uses it for data splitting.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.randomsplitter import RandomSplitter
from pyflink.table import StreamTableEnvironment
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input table.
input_table = t_env.from_data_stream(
env.from_collection([
(1, 10, 0),
(1, 10, 0),
(1, 10, 0),
(4, 10, 0),
(5, 10, 0),
(6, 10, 0),
(7, 10, 0),
(10, 10, 0),
(13, 10, 0)
],
type_info=Types.ROW_NAMED(
['f0', 'f1', "f2"],
[Types.INT(), Types.INT(), Types.INT()])))
# Creates a RandomSplitter object and initializes its parameters.
splitter = RandomSplitter().set_weights(4.0, 6.0)
# Uses the RandomSplitter to split the dataset.
output = splitter.transform(input_table)
# Extracts and displays the results.
print("Split Result 1 (40%)")
for result in t_env.to_data_stream(output[0]).execute_and_collect():
print(str(result))
print("Split Result 2 (60%)")
for result in t_env.to_data_stream(output[1]).execute_and_collect():
print(str(result))
RegexTokenizer(正则表达式分词器)是一种用于将文本数据分割成单词或标记(tokens)的文本预处理方法。正则表达式分词器使用正则表达式来定义文本的分割规则,从而灵活地处理不同语言和文本格式的数据。它通常用于自然语言处理(NLP)和文本挖掘任务,如文本分类、情感分析和主题建模。
正则表达式分词器的主要优点是可以自定义分词规则,以适应不同的文本数据和处理需求。例如,可以使用正则表达式来捕捉字母数字单词、标点符号、特殊字符等。此外,正则表达式分词器可以处理复杂的文本格式和编码,如多语言文本、混合文本和特殊符号。
然而,正则表达式分词器的缺点是它可能受到正则表达式复杂性和性能的影响,尤其是在处理大规模文本数据和复杂分词规则的情况下。为了解决这些问题,可以考虑使用基于词典或语法的分词器(如空格分词器、NLTK分词器和spaCy分词器),或采用机器学习和深度学习方法(如序列标注和Transformer模型)进行更高效的文本处理。
设计目标:
NLTK是一个功能丰富的NLP库,它提供了许多用于文本处理、语言学分析和机器学习的工具。NLTK分词器更适用于教学和研究目的,因为它包含了各种分词算法,可以让用户尝试和比较不同的方法。
spaCy则专注于高性能和实用性,它的设计目标是为生产环境和大规模数据处理提供高效的NLP工具。spaCy分词器在实现上进行了优化,以便在实际应用中提供更好的性能。
性能:
通常,spaCy分词器比NLTK分词器的性能更高。这是因为spaCy针对性能进行了优化,并使用了Cython扩展来提高处理速度。NLTK虽然功能丰富,但在大规模数据处理时可能较慢。
易用性和扩展性:
NLTK分词器提供了多种分词方法,例如基于正则表达式的分词器、基于Punkt算法的分词器等。这使得NLTK更灵活,能够满足各种需求。然而,这也意味着用户可能需要了解不同的分词算法以选择合适的方法。
spaCy分词器则内置了对多种语言的支持,用户只需加载适当的语言模型即可进行分词。此外,spaCy允许用户自定义分词规则和扩展其词汇表,以适应特定领域的需求。
与其他NLP任务的集成:
spaCy分词器与其他NLP任务(如词性标注、命名实体识别等)的集成更紧密。在spaCy中,分词只是文本处理流程的第一步,后续任务可以直接在分词结果的基础上进行。
而在NLTK中,分词和其他任务之间的关联相对较弱,用户需要自行将分词结果传递给其他处理模块。
序列标注(Sequence Labeling)是一种自然语言处理(NLP)任务,其目标是为输入序列中的每个元素分配一个类别标签。输入序列通常是文本中的单词或字符序列,而标签通常表示某种语言学属性或实体。序列标注在许多NLP任务中具有重要应用,例如词性标注、命名实体识别(NER)和分块。
在序列标注任务中,预测的标签之间可能存在依赖关系。例如,在命名实体识别中,相邻的单词可能属于同一个实体,因此它们的标签应该是相关的。为了捕捉这种依赖关系,序列标注算法通常需要考虑上下文信息。
常见的序列标注方法包括:
隐马尔可夫模型(HMM):
HMM是一种统计模型,它假设观察序列中的每个元素都是由一个隐藏状态生成的,而隐藏状态之间存在马尔可夫链。在序列标注任务中,观察序列是输入文本,隐藏状态则是标签。HMM可以通过预测隐藏状态序列来实现序列标注。
条件随机场(CRF):
CRF是一种判别式模型,它可以直接建模标签序列与输入序列之间的条件概率。与HMM相比,CRF可以更灵活地捕捉输入特征与标签之间的复杂关系。线性链CRF是序列标注中最常用的CRF形式。
深度学习方法:
深度学习方法,如循环神经网络(RNN)、长短时记忆网络(LSTM)和门控循环单元(GRU)等,已在序列标注任务中取得了显著的成功。这些方法可以捕捉长距离依赖关系,并自动学习输入序列的表示。此外,双向LSTM(Bi-LSTM)和双向GRU(Bi-GRU)等双向结构可以同时考虑上下文信息,从而进一步提高序列标注的性能。
Transformer-based 方法:
最近,基于Transformer的预训练模型(如BERT、GPT和RoBERTa等)在各种NLP任务中取得了显著的成功,包括序列标注。这些模型可以捕捉到输入序列的丰富上下文信息,并在预训练阶段学习到通用的语言表示。在微调阶段,预训练模型可以很容易地适应特定的序列标注任务,从而取得优异的性能。
词性标注(Part-of-Speech Tagging):为文本中的每个单词分配一个词性标签,如名词、动词、形容词等。词性标注有助于理解句子的句法结构和语义。
命名实体识别(Named Entity Recognition,NER):识别文本中的命名实体(如人名、地名、组织名等),并为它们分配相应的类别标签。NER是信息抽取、问答系统和知识图谱构建等任务的基础。
分块(Chunking):将文本分割成短语块(如名词短语、动词短语等),这有助于捕捉句子的局部结构和语义。
文本分割(Text Segmentation):将文本分割成单词或句子。这在某些语言(如中文)中尤为重要,因为这些语言的文本中没有明确的单词分隔符。
在处理序列标注任务时,有一些技巧可以帮助提高模型性能:
数据预处理:对输入文本进行预处理,如大小写转换、词干提取、去除停用词等。这有助于减小噪音并简化模型。
特征工程:除了原始文本之外,还可以引入其他特征,如词性标签、字符级特征、句法特征等。这些特征可以帮助模型捕捉更丰富的上下文信息。
预训练词嵌入:使用预训练词嵌入(如Word2Vec、GloVe等)作为输入特征,可以帮助模型捕捉词汇级别的语义信息。对于深度学习模型,这种做法可以加速模型收敛并提高泛化性能。
模型集成:将多个模型的预测结果进行融合,可以提高序列标注的性能。集成方法包括投票、平均、加权平均等。
交叉验证与超参数调优:使用交叉验证(如K折交叉验证)进行模型评估和超参数调优,可以提高模型在未知数据上的泛化能力。
通过结合这些技巧,可以有效地改进序列标注任务的性能,从而实现更准确的文本分析和处理。
词嵌入(Word Embedding)是一种将单词或短语从词汇表中映射到向量空间的技术,它将文本数据转换为数值表示,以便于计算机处理。词嵌入方法的主要目标是捕捉词汇项之间的语义和句法关系,从而为各种自然语言处理(NLP)任务提供有意义的输入特征。
词嵌入向量通常具有较低的维度(例如50、100、200或300维),这使得词嵌入表示相对稀疏,并可以有效地减少计算复杂度。在向量空间中,语义上相似的单词将具有相似的词向量表示,这有助于捕捉文本数据的潜在结构。
常见的词嵌入方法包括:
Word2Vec:由Google开发的一种无监督学习算法,用于生成词向量表示。Word2Vec有两种变体:Skip-gram(通过中心词预测周围词)和Continuous Bag of Words(CBOW,通过周围词预测中心词)。Word2Vec可以捕捉词汇项之间的线性关系,并在多种NLP任务中取得了很好的效果。
GloVe(Global Vectors for Word Representation):一种基于全局共现统计信息的词嵌入方法,由斯坦福大学的研究人员开发。GloVe通过优化目标函数,使得词向量的点积接近共现矩阵中相应单词对的对数值。
FastText:由Facebook AI Research开发的一种词嵌入方法,它将单词表示为子词(n-grams)的组合。FastText可以处理词汇表之外的单词(即未登录词),并在多种语言和领域的NLP任务中取得了很好的效果。
ELMo、BERT等上下文词嵌入:这些基于深度学习的词嵌入方法可以生成上下文相关的词向量表示。与静态词嵌入方法(如Word2Vec和GloVe)相比,上下文词嵌入可以捕捉单词在不同上下文中的多义性。
词嵌入在各种NLP任务中具有广泛应用,包括文本分类、情感分析、命名实体识别、关系抽取、问答系统等。通过使用预训练词嵌入作为输入特征,可以加速深度学习模型的收敛过程,并提高模型的泛化性能。
GloVe(Global Vectors for Word Representation)是一种用于自然语言处理(NLP)的无监督学习算法,用于生成词向量表示。GloVe由斯坦福大学的研究人员于2014年提出。与其他词嵌入方法(如Word2Vec)相比,GloVe更关注单词共现统计信息,从而捕捉单词之间的语义和句法关系。
GloVe的训练过程分为以下几个步骤:
构建共现矩阵:首先,在大规模语料库中统计单词对的共现次数,得到一个共现矩阵。共现矩阵的每个元素表示一对单词在特定窗口大小内共同出现的次数。
优化目标函数:GloVe定义了一个目标函数,旨在学习词向量,使得它们的点积接近共现矩阵中相应单词对的对数值。目标函数还包括一个加权函数,以处理不同频率范围内的共现次数。
随机梯度下降:通过随机梯度下降(SGD)优化目标函数,学习得到单词向量。训练结束后,可以将每个单词的主向量和上下文向量相加,得到最终的词向量表示。
GloVe的主要优点如下:
有效捕捉语义和句法关系:由于GloVe关注全局共现统计信息,因此它能有效地捕捉单词之间的语义和句法关系。
可解释性:GloVe的目标函数和优化过程具有较强的可解释性,可以直观地理解词向量学习的过程。
可扩展性:GloVe可以处理大规模语料库,并生成高质量的词向量表示。GloVe已经在多种NLP任务中取得了很好的效果。
GloVe词向量可以作为NLP任务的输入特征,例如文本分类、情感分析、序列标注等。通过使用GloVe预训练词嵌入,可以在训练深度学习模型时加速收敛过程,并提高模型的泛化性能。
在实际应用中,正则表达式分词器通常与其他文本预处理方法(如词干提取、词形还原和停用词过滤)和特征提取方法(如词袋模型、TF-IDF和词嵌入)结合使用,以提高自然语言处理和文本挖掘任务的性能。在处理不同文本数据和任务时,需要根据实际需求选择合适的分词方法。
RegexTokenizer #
RegexTokenizer 是一种将输入字符串转换为小写,然后根据正则表达式按空格拆分的算法。
Input Columns #

编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
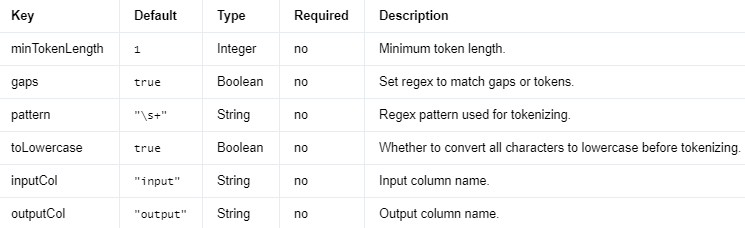
编辑切换为居中
添加图片注释,不超过 140 字(可选)
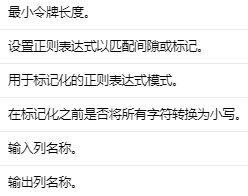
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.regextokenizer.RegexTokenizer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.Arrays;
/** Simple program that creates a RegexTokenizer instance and uses it for feature engineering. */
public class RegexTokenizerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input data.
DataStream<Row> inputStream =
env.fromElements(Row.of("Test for tokenization."), Row.of("Te,st. punct"));
Table inputTable = tEnv.fromDataStream(inputStream).as("input");
// Creates a RegexTokenizer object and initializes its parameters.
RegexTokenizer regexTokenizer =
new RegexTokenizer()
.setInputCol("input")
.setOutputCol("output")
.setPattern("\\w+|\\p{Punct}");
// Uses the Tokenizer object for feature transformations.
Table outputTable = regexTokenizer.transform(inputTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
String inputValue = (String) row.getField(regexTokenizer.getInputCol());
String[] outputValues = (String[]) row.getField(regexTokenizer.getOutputCol());
System.out.printf(
"Input Value: %s \tOutput Values: %s\n",
inputValue, Arrays.toString(outputValues));
}
}
}
Python
# Simple program that creates a RegexTokenizer instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.ml.feature.regextokenizer import RegexTokenizer
from pyflink.table import StreamTableEnvironment
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(env)
# Generates input data.
input_data_table = t_env.from_data_stream(
env.from_collection([
('Test for tokenization.',),
('Te,st. punct',),
],
type_info=Types.ROW_NAMED(
['input'],
[Types.STRING()])))
# Creates a RegexTokenizer object and initializes its parameters.
regex_tokenizer = RegexTokenizer() \
.set_input_col("input") \
.set_output_col("output")
# Uses the Tokenizer object for feature transformations.
output = regex_tokenizer.transform(input_data_table)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_value = result[field_names.index(regex_tokenizer.get_input_col())]
output_value = result[field_names.index(regex_tokenizer.get_output_col())]
print('Input Values: ' + str(input_value) + '\tOutput Value: ' + str(output_value))
RobustScaler(鲁棒缩放器)是一种特征预处理方法,用于将特征缩放到相同的范围,同时减小异常值和离群点的影响。鲁棒缩放器通过使用中位数和四分位数范围(IQR,即第三四分位数与第一四分位数之差)来缩放特征,从而提高模型在具有异常值和离群点的数据上的鲁棒性。它通常用于处理具有不同尺度和分布的特征,以提高机器学习模型的性能。
鲁棒缩放器的工作原理是将特征值减去中位数,然后除以四分位数范围,从而将特征缩放到一个相对稳定的范围。例如,对于特征向量(x1, x2, x3),鲁棒缩放器将其转换为以下形式:
(x1 - median(x1)) / IQR(x1),
(x2 - median(x2)) / IQR(x2),
(x3 - median(x3)) / IQR(x3)
鲁棒缩放器的主要优点是可以减小异常值和离群点的影响,提高模型在嘈杂数据上的鲁棒性。此外,鲁棒缩放器可以适应不同尺度和分布的特征,通过调整中位数和四分位数范围来平衡特征之间的重要性。
然而,与其他特征缩放方法(如最小-最大缩放器和标准化缩放器)相比,鲁棒缩放器可能受到数据的偏度和峰度的影响,导致性能略有下降。在实际应用中,需要根据实际问题和数据特点选择合适的特征缩放方法。
在实际应用中,鲁棒缩放器通常与其他预处理方法(如特征选择和规范化)结合使用,以提高模型的性能。在处理具有不同尺度和分布的特征时,需要根据实际需求选择合适的特征缩放方法。
鲁棒缩放器 #
RobustScaler 是一种算法,它使用对异常值具有鲁棒性的统计数据来缩放特征。
此缩放器删除中位数并根据分位数范围(默认为 IQR:四分位数范围)缩放数据。IQR 是第一个四分位数(第 25 个分位数)和第 3 个四分位数(第 75 个分位数)之间的范围,但可以配置。
通过计算训练集中样本的相关统计数据,在每个特征上独立进行居中和缩放。然后使用转换方法存储中值和分位数范围以用于以后的数据。
数据集的标准化是许多机器学习估算器的共同要求。通常这是通过移除均值并缩放到单位方差来完成的。但是,异常值通常会对样本均值/方差产生负面影响。在这种情况下,中位数和四分位数间距通常会提供更好的结果。
请注意,在计算中位数和范围时会忽略 NaN 值。
Input Columns #
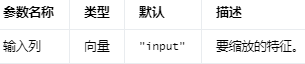
编辑
添加图片注释,不超过 140 字(可选)
Output Columns #

编辑
添加图片注释,不超过 140 字(可选)
Parameters #
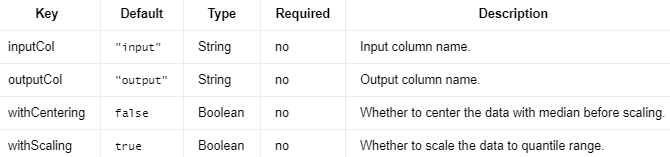
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
相对误差
编辑
添加图片注释,不超过 140 字(可选)
Java
import org.apache.flink.ml.feature.robustscaler.RobustScaler;
import org.apache.flink.ml.feature.robustscaler.RobustScalerModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
/** Simple program that trains a {@link RobustScaler} model and uses it for feature selection. */
public class RobustScalerExample {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
// Generates input training and prediction data.
DataStream<Row> trainStream =
env.fromElements(
Row.of(1, Vectors.dense(0.0, 0.0)),
Row.of(2, Vectors.dense(1.0, -1.0)),
Row.of(3, Vectors.dense(2.0, -2.0)),
Row.of(4, Vectors.dense(3.0, -3.0)),
Row.of(5, Vectors.dense(4.0, -4.0)),
Row.of(6, Vectors.dense(5.0, -5.0)),
Row.of(7, Vectors.dense(6.0, -6.0)),
Row.of(8, Vectors.dense(7.0, -7.0)),
Row.of(9, Vectors.dense(8.0, -8.0)));
Table trainTable = tEnv.fromDataStream(trainStream).as("id", "input");
// Creates a RobustScaler object and initializes its parameters.
RobustScaler robustScaler =
new RobustScaler()
.setLower(0.25)
.setUpper(0.75)
.setRelativeError(0.001)
.setWithScaling(true)
.setWithCentering(true);
// Trains the RobustScaler model.
RobustScalerModel model = robustScaler.fit(trainTable);
// Uses the RobustScaler model for predictions.
Table outputTable = model.transform(trainTable)[0];
// Extracts and displays the results.
for (CloseableIterator<Row> it = outputTable.execute().collect(); it.hasNext(); ) {
Row row = it.next();
DenseVector inputValue = (DenseVector) row.getField(robustScaler.getInputCol());
DenseVector outputValue = (DenseVector) row.getField(robustScaler.getOutputCol());
System.out.printf("Input Value: %-15s\tOutput Value: %s\n", inputValue, outputValue);
}
}
}
Python
# Simple program that creates a RobustScaler instance and uses it for feature
# engineering.
from pyflink.common import Types
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment
from pyflink.ml.linalg import Vectors, DenseVectorTypeInfo
from pyflink.ml.feature.robustscaler import RobustScaler
# Creates a new StreamExecutionEnvironment.
env = StreamExecutionEnvironment.get_execution_environment()
# Creates a StreamTableEnvironment.
t_env = StreamTableEnvironment.create(env)
# Generates input training and prediction data.
train_data = t_env.from_data_stream(
env.from_collection([
(1, Vectors.dense(0.0, 0.0),),
(2, Vectors.dense(1.0, -1.0),),
(3, Vectors.dense(2.0, -2.0),),
(4, Vectors.dense(3.0, -3.0),),
(5, Vectors.dense(4.0, -4.0),),
(6, Vectors.dense(5.0, -5.0),),
(7, Vectors.dense(6.0, -6.0),),
(8, Vectors.dense(7.0, -7.0),),
(9, Vectors.dense(8.0, -8.0),),
],
type_info=Types.ROW_NAMED(
['id', 'input'],
[Types.INT(), DenseVectorTypeInfo()])
))
# Creates an RobustScaler object and initializes its parameters.
robust_scaler = RobustScaler()\
.set_lower(0.25)\
.set_upper(0.75)\
.set_relative_error(0.001)\
.set_with_scaling(True)\
.set_with_centering(True)
# Trains the RobustScaler Model.
model = robust_scaler.fit(train_data)
# Uses the RobustScaler Model for predictions.
output = model.transform(train_data)[0]
# Extracts and displays the results.
field_names = output.get_schema().get_field_names()
for result in t_env.to_data_stream(output).execute_and_collect():
input_index = field_names.index(robust_scaler.get_input_col())
output_index = field_names.index(robust_scaler.get_output_col())
print('Input Value: ' + str(result[input_index]) +
'\tOutput Value: ' + str(result[output_index]))