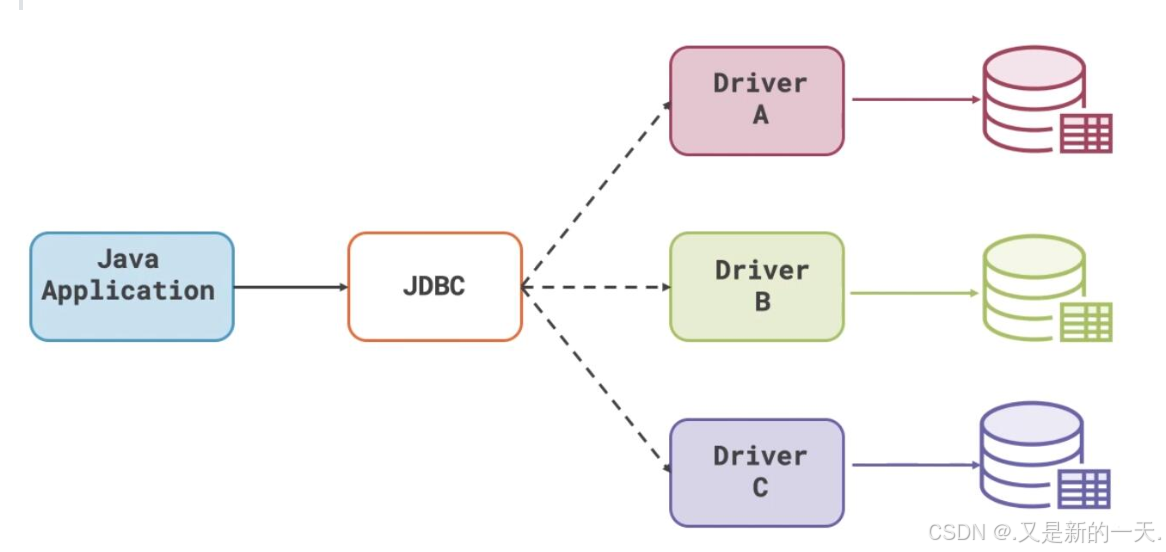
以下是用Java实现的雪花算法代码示例,包含详细注释和异常处理:
代码下面有解析
public class SnowflakeIdGenerator {
// 起始时间戳(2020-01-01 00:00:00)
private static final long START_TIMESTAMP = 1577836800000L;
// 各部分的位数
private static final long DATA_CENTER_ID_BITS = 5L; // 数据中心ID占5位
private static final long WORKER_ID_BITS = 5L; // 工作节点ID占5位
private static final long SEQUENCE_BITS = 12L; // 序列号占12位
// 最大值计算(位运算)
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
private static final long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);
// 左移位数
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
private final long dataCenterId; // 数据中心ID
private final long workerId; // 工作节点ID
private long sequence = 0L; // 序列号
private long lastTimestamp = -1L; // 上次生成时间
/**
* 构造函数
* @param dataCenterId 数据中心ID (0~31)
* @param workerId 工作节点ID (0~31)
*/
public SnowflakeIdGenerator(long dataCenterId, long workerId) {
if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {
throw new IllegalArgumentException("DataCenter ID 超出范围");
}
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException("Worker ID 超出范围");
}
this.dataCenterId = dataCenterId;
this.workerId = workerId;
}
/**
* 生成下一个ID(线程安全)
*/
public synchronized long nextId() {
long currentTimestamp = System.currentTimeMillis();
// 时钟回拨检查
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨,拒绝生成ID");
}
if (currentTimestamp == lastTimestamp) {
// 同一毫秒内序列号递增
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
// 当前毫秒序列号用完,等待下一毫秒
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
// 新毫秒重置序列号
sequence = 0L;
}
lastTimestamp = currentTimestamp;
// 组合各部分生成ID
return ((currentTimestamp - START_TIMESTAMP) << TIMESTAMP_SHIFT)
| (dataCenterId << DATA_CENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
/**
* 阻塞等待直到下一毫秒
*/
private long waitNextMillis(long lastTimestamp) {
long currentTimestamp = System.currentTimeMillis();
while (currentTimestamp <= lastTimestamp) {
currentTimestamp = System.currentTimeMillis();
}
return currentTimestamp;
}
public static void main(String[] args) {
// 示例用法
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);
for (int i = 0; i < 10; i++) {
System.out.println("生成的ID: " + idGenerator.nextId());
}
}
}
好的!我来用更简单的方式分步讲解雪花算法的分布式核心逻辑,以及Java代码的关键部分。
第一步:为什么需要分布式ID?
在单机系统中,可以用数据库自增ID。但在分布式系统中,多个节点同时生成ID时,自增ID会冲突。雪花算法通过结构划分,让每个节点独立生成全局唯一ID。
第二步:雪花ID的结构(64位)
想象把64位的数字分成四个部分,像切蛋糕一样:
- 符号位(1位):固定为0,保证ID是正数(蛋糕边角料,几乎不用管)。
- 时间戳(41位):记录ID生成的时间(精确到毫秒),保证ID随时间递增。
- 机器ID(10位):分配给不同机器的编号,确保不同机器的ID不冲突。
- 序列号(12位):同一毫秒内,如果生成多个ID,用序列号区分。

第三步:机器ID的分配(分布式核心)
• 问题:如果多台机器生成ID,如何确保它们的ID不重复?
• 解决方案:为每台机器分配一个唯一编号(比如:数据中心ID + 工作节点ID)。
• 示例:5位数据中心ID(031) + 5位工作节点ID(031) → 最多支持 32×32=1024 台机器。
• 分配方式:手动配置或通过ZooKeeper等工具动态分配。
第四步:Java代码关键点拆解
1. 定义各部分的位数
private static final long DATA_CENTER_ID_BITS = 5L; // 数据中心ID占5位
private static final long WORKER_ID_BITS = 5L; // 工作节点ID占5位
private static final long SEQUENCE_BITS = 12L; // 序列号占12位
2. 计算最大值(防止溢出)
// 5位最大值是 2^5-1 = 31
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
3. 生成ID的核心逻辑
public synchronized long nextId() {
long currentTimestamp = System.currentTimeMillis();
// 1. 检查时钟回拨(时间不能倒流)
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨!");
}
// 2. 同一毫秒内生成多个ID
if (currentTimestamp == lastTimestamp) {
sequence++; // 序列号+1
if (sequence > MAX_SEQUENCE) {
// 当前毫秒的序列号用完了,等待下一毫秒
currentTimestamp = waitNextMillis(lastTimestamp);
sequence = 0;
}
} else {
sequence = 0; // 新的一毫秒,序列号重置
}
lastTimestamp = currentTimestamp;
// 3. 拼接各部分(位运算)
return (时间戳部分) | (机器ID部分) | (序列号部分);
}
4. 位运算如何拼接?
假设时间差是 1000ms,数据中心ID=1,工作节点ID=1,序列号=0:
时间戳部分:1000ms << 22位(左移后占据高位)
机器ID部分:1 << 17位(左移后占据中间)
工作节点部分:1 << 12位(左移后占据中间)
序列号部分:0(占据最后12位)
最终二进制:
0000000000000000000000011111101000 00001 00001 000000000000
第五步:分布式场景示例
• 机器A:数据中心ID=1,工作节点ID=1
• 机器B:数据中心ID=1,工作节点ID=2
• 机器C:数据中心ID=2,工作节点ID=1
同一毫秒内,三台机器生成的ID:
机器A:时间戳 | 1(数据中心) | 1(工作节点) | 序列号
机器B:时间戳 | 1(数据中心) | 2(工作节点) | 序列号
机器C:时间戳 | 2(数据中心) | 1(工作节点) | 序列号
即使时间戳和序列号相同,机器ID不同 → 最终ID不同!
第六步:常见问题解答
1. 为什么时间戳占41位?
• 41位二进制能表示的时间范围是 2^41 / 1000 / 3600 / 24 / 365 ≈ 69年。
• 如果从2020年开始,可以用到2089年。
2. 时钟回拨怎么办?
• 原因:服务器时间被手动调整或NTP同步导致时间倒退。
• 处理:代码中直接抛出异常(生产环境可优化为等待时钟追上)。
3. 序列号为什么是12位?
• 12位支持每毫秒生成 4096个ID(2^12 = 4096),足够大多数场景使用。
总结
雪花算法的分布式核心就是:
- 分蛋糕:把64位分成时间、机器ID、序列号。
- 唯一机器ID:确保不同机器的ID不冲突。
- 时间有序:时间戳保证ID整体递增,适合数据库索引。
代码中的位运算就像拼乐高积木,把时间、机器编号、序列号拼成一个完整的ID。你提到的这一点非常重要!这里涉及到位运算和二进制补码的知识,我来详细拆解这个计算过程,保证彻底讲清楚。
问题聚焦
代码中的这两行:
private static final long MAX_DATA_CENTER_ID = ~(-1L << DATA_CENTER_ID_BITS);
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
为什么 DATA_CENTER_ID_BITS = 5 时,MAX_DATA_CENTER_ID = 31?如何通过位运算得出这个结果?
第一步:理解二进制补码
在计算机中,负数用补码表示。例如:
• -1 的二进制补码形式是:11111111 11111111 ... 11111111(64位全1)。
**第二步:分步计算 **~(-1L << 5)
以 DATA_CENTER_ID_BITS = 5 为例:
- **计算 **
-1L << 5
•-1L的二进制:11111111 11111111 ... 11111111(64位全1)。
• 左移5位后:
11111111 11111111 ... 11111111 00000
↑ 左侧丢弃5位,右侧补5个0
• 结果仍是一个负数(最高位是1)。
- 按位取反
~操作
• 对111...11100000取反:
00000000 00000000 ... 00000000 11111
↑ 所有位取反(0变1,1变0)
• 此时最高位是0,表示正数。
- 转换为十进制
• 二进制000...0011111的十进制是2^4 + 2^3 + 2^2 + 2^1 + 2^0 = 31。
通用公式
• 对于 n 位:~(-1L << n) = 2^n - 1
例如:
• n=5 → 2^5-1=31
• n=10 → 2^10-1=1023
为什么不用 2^n - 1 直接赋值?
代码中通过位运算动态计算最大值,有两个优点:
- 可读性:直接体现“用n位表示最大值”的逻辑。
- 可维护性:若未来调整位数(如改为6位),无需手动计算
2^6-1=63,代码自动适应。
代码中的验证逻辑
构造函数中检查数据中心ID和工作节点ID是否超过最大值:
public SnowflakeIdGenerator(long dataCenterId, long workerId) {
if (dataCenterId > MAX_DATA_CENTER_ID || dataCenterId < 0) {
throw new IllegalArgumentException("DataCenter ID 超出范围");
}
// 同理检查workerId
}
• 若传入 dataCenterId=32(超过31),会直接抛出异常,防止生成重复ID。
举例验证
假设 DATA_CENTER_ID_BITS = 3(最大值应为 2^3-1=7):
-1L << 3→111...11111111000(64位)。- 取反后 →
000...00000000111(二进制7)。 MAX_DATA_CENTER_ID = 7。
总结
• 核心逻辑:通过左移和取反计算n位能表示的最大正整数。
• 位运算技巧:利用补码和位移动态计算最大值,避免硬编码。
• 设计意图:确保机器ID在指定范围内,防止分布式系统中ID冲突。好的!我再用一个更生活化的比喻和分步拆解,确保彻底讲明白这段代码的逻辑。
比喻:楼层与房间号
想象你要为一家全球连锁酒店设计房间号,规则如下:
- 酒店编号:区分不同国家/城市的酒店(如北京=01,上海=02)。
- 分店编号:同一城市的不同分店(如北京分店A=001,分店B=002)。
- 时间戳:记录房间分配的日期(如20231025)。
- 序列号:同一天内分配的房间顺序(如0001, 0002)。
最终房间号格式:时间戳 + 酒店编号 + 分店编号 + 序列号,例如:
20231025 01 001 0001 → 北京分店A在2023年10月25日分配的第1个房间。
对应雪花算法
将上述规则映射到雪花算法的64位ID:
• 时间戳:占据高位(相当于日期)。
• 数据中心ID(酒店编号):区分不同数据中心。
• 工作节点ID(分店编号):同一数据中心的不同机器。
• 序列号:同一毫秒内的顺序号。
代码逐行拆解
1. 定义左移位数
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
private static final long DATA_CENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATA_CENTER_ID_BITS;
• 作用:计算每个部分在二进制中的起始位置。
• 示例(假设配置):
• 序列号占12位(SEQUENCE_BITS=12)
• 工作节点ID占5位(WORKER_ID_BITS=5)
• 数据中心ID占5位(DATA_CENTER_ID_BITS=5)
• 计算逻辑:
• 工作节点ID需要左移序列号的位数(12位),占据第13~17位。
• 数据中心ID需要左移序列号+工作节点ID位数(12+5=17位),占据第18~22位。
• 时间戳需要左移序列号+工作节点ID+数据中心ID位数(12+5+5=22位),占据第23~63位。

2. 成员变量
private final long dataCenterId; // 数据中心ID(如:1)
private final long workerId; // 工作节点ID(如:2)
private long sequence = 0L; // 序列号(每毫秒从0开始)
private long lastTimestamp = -1L; // 上一次生成ID的时间(毫秒级)
• 作用:
• dataCenterId和workerId:唯一标识一台机器(类似酒店和分店编号)。
• sequence:同一毫秒内的递增序号(解决并发问题)。
• lastTimestamp:记录上一次生成ID的时间,用于检测时钟回拨。
分步演示生成ID
假设数据:
• 当前时间戳:1609459205000(2020-01-01 00:00:05)
• 数据中心ID:1(二进制 00001)
• 工作节点ID:2(二进制 00010)
• 序列号:3(二进制 000000000011)
步骤1:计算时间差
long timestampDiff = currentTimestamp - START_TIMESTAMP;
// 1609459205000 - 1609459200000 = 5000(毫秒)
步骤2:各部分左移
• 时间戳部分
5000 << 22
二进制:0000000000000000000000000000000000000000010011100010000000000000
• 数据中心ID部分
1 << 17
二进制:0000000000000000000000000000000000000000000000000010000000000000
• 工作节点ID部分
2 << 12
二进制:0000000000000000000000000000000000000000000000000000001000000000
• 序列号部分
3
二进制:0000000000000000000000000000000000000000000000000000000000000011
步骤3:合并各部分(按位或运算)
时间戳部分 | 数据中心ID部分 | 工作节点ID部分 | 序列号部分
= 0000000000000000000000000000000000000000010011100010000000000000
| 0000000000000000000000000000000000000000000000000010000000000000
| 0000000000000000000000000000000000000000000000000000001000000000
| 0000000000000000000000000000000000000000000000000000000000000011
= 0000000000000000000000000000000000000000010011100010001000000011
十进制结果:5000 << 22 | 1 << 17 | 2 << 12 | 3 = 20971520000 + 131072 + 8192 + 3 = 20972852787
关键设计思想
- 唯一性:通过
dataCenterId和workerId区分不同机器。 - 有序性:时间戳在高位,整体ID趋势递增。
- 高性能:位运算和本地计算,无需网络请求。
总结
• 位移常量:决定每部分在ID中的位置(类似酒店房间号的“区段”)。
• 成员变量:存储机器标识和时间信息,通过位移拼接成唯一ID。
• 本质:把时间、机器、序列号信息编码到一个64位数字中,像拼图一样严丝合缝。