分布式缓存
单节点Redis问题
- 数据丢失:数据持久化
- 并发能力弱:搭建主从集群,实现读写分离
- 故障恢复问题:哨兵实现健康检测,自动恢复
- 存储能力:搭建分片集群,利用插槽机制实现动态扩容
Redis持久化
RDB持久化
数据库备份文件,也叫快照,把内存数据存到磁盘。使用save进行主动RDB,会阻塞所有命令。建议使用bgsave开启子进程执行RDB。Redis停机时会被动执行一次RDB。
RDB:
bgsave开始会fork主进程得到子进程,子进程共享主进程的内存数据,完成fork后读取内存数据并写入RDB文件。
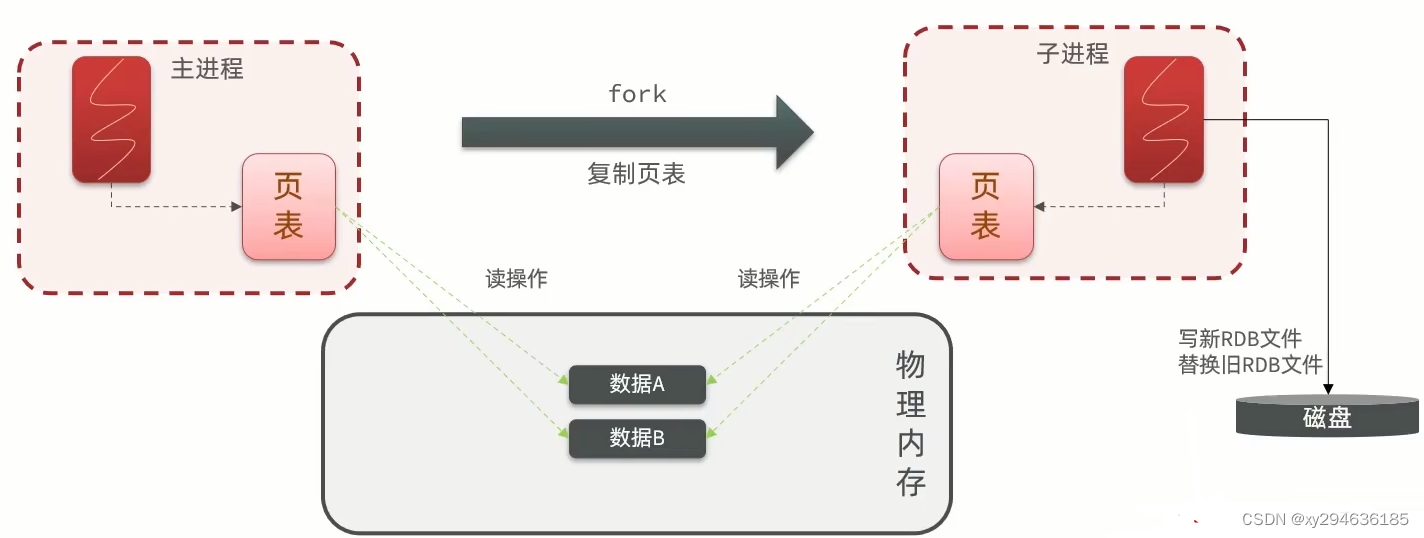
注:在fork时插入的数据会影响一致性,所以采用copy-on-write技术,当主进程执行读操作,刚问共享内存。当主进程执行写操作,则拷贝一份数据,执行写。
配置 :
Redis内部可在redis.conf配置RDB触发机制。
总结:
- RDB方式bgsave基本流程?
-fork主进程得到子进程,共享内存空间。
-子进程读取内存数据,并写入RDB。
-用新RDB文件替换旧的RDB文件。 - RDB会在什么时候执行?save60 1000代表什么?
-手动save或bgsave,被动服务停止时。代表60s内至少修改1000次才触发RDB。 - RDB缺点?
-RDB执行间隔时间长,两次RDB之间写入数据有丢失风险。
-fork子进程,压缩,写出RDB文件都比较耗时。
AOF:
AOF持久化
追加文件。redis每一条写命令都记录在AOF文件,是命令日志文件。
配置:
Redis的AOF默认关闭,需修改redis.conf的appendonly来开启AOF。可配置appendfsync改变刷盘策略的记录频率:always,everysec(默认),no(由操作系统决定)。
- always 同步刷盘 可靠性高,几乎不丢失数据 性能差
- everysec 每秒刷盘 性能中 最多丢失1s数据
- no 操作系统控制 性能好 可靠性差,丢失数据大
auto-aof-rewrite-percentage 100 文件比上次增长超过几%则触发重写
auto-aof-rewrite-min-size 64mb 文件多大重写
问题:
AOF会比RDB大很多,而且对同一个KEY多次写操作,只有最后一次才有意义,通过执行bgrewriteaof命令,可以让AOF文件执行重写。
RDB和AOF对比
如果对数据安全性要求高,则需结合两者使用

Redis主从集群
搭建主从架构
单节点Reds并发不高,就需要主从集群,实现读写分离。
准备
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录。开启RDB关闭AOF。拷贝redis.conf到三个目录。
问题:为什么Redis是主从集群而不是负载均衡集群?
Redis读多写少,主节点做写操作,从节点做读操作。
开启主从关系
使用replicaof或者slaveof命令,有临时和永久两种模式。
数据同步原理
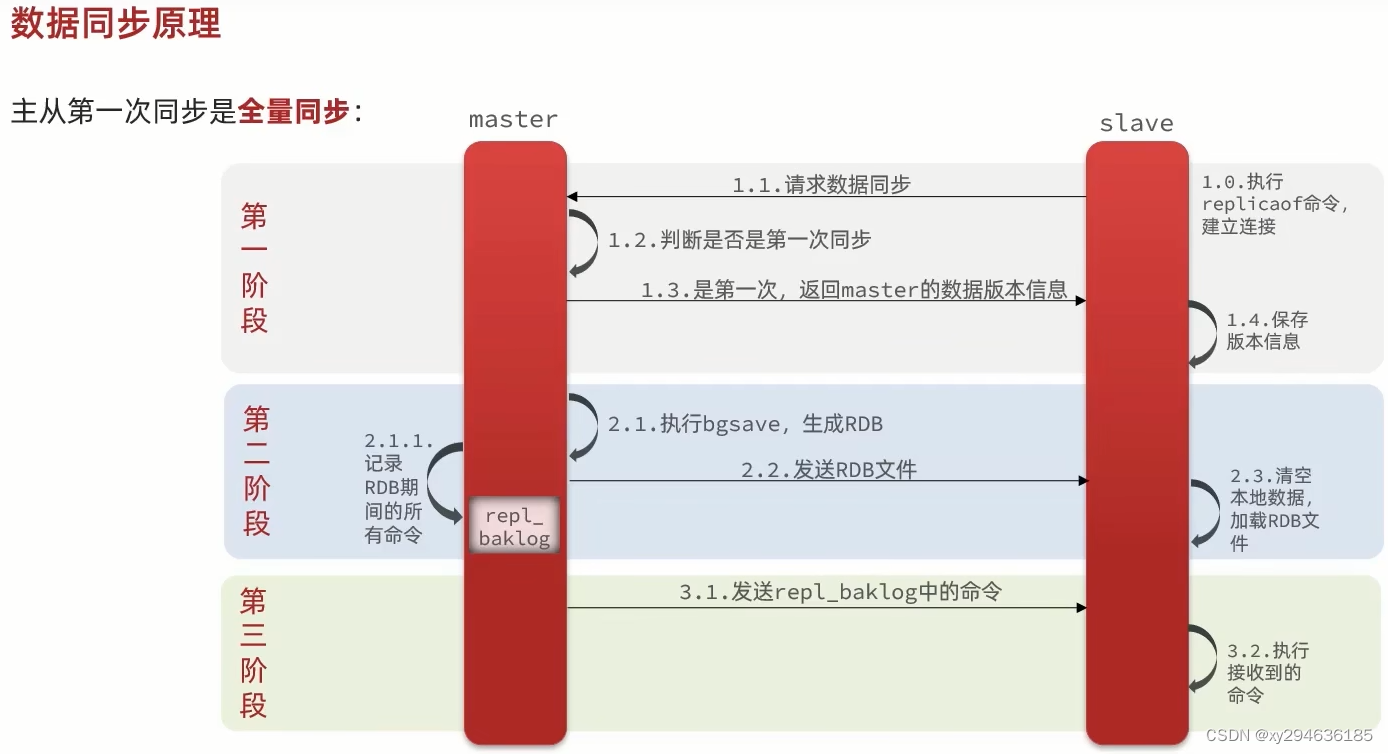
主从第一次同步是全量同步,第二次是同步记录rdb期间的所有命令,第三次发送repl_baklog中的命令。
问题:master如何判断slave是不是第一次来同步数据?
- replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集,每一次master都有唯一的replid,slave会继承master节点的replid。
- offset:偏移量,如果slave的offset小于master的offset,说明lave的数据落后于master,需要更新。
因此salve做数据同步,必须想master声明replicationId和offset,master才能判断传输的数据。
全量同步流程
master将完整内存数据生成rdb,发送给slave,后续命令则记录在repl_baklog,逐个发给slave
注:slave节点第一次链接master时进行全量同步,或者slave断开太久repl_baklog中的offset已被覆盖
- slave节点请求增量同步
- master节点判断replid,不一致则拒绝增量同步
- master将完整的内存数据生成rdb,发送到slave
- slave清空本地数据,加载master的rdb
- master将rdb期间的命令记录在repl_baklog中,并持续将log中的命令发送slave。
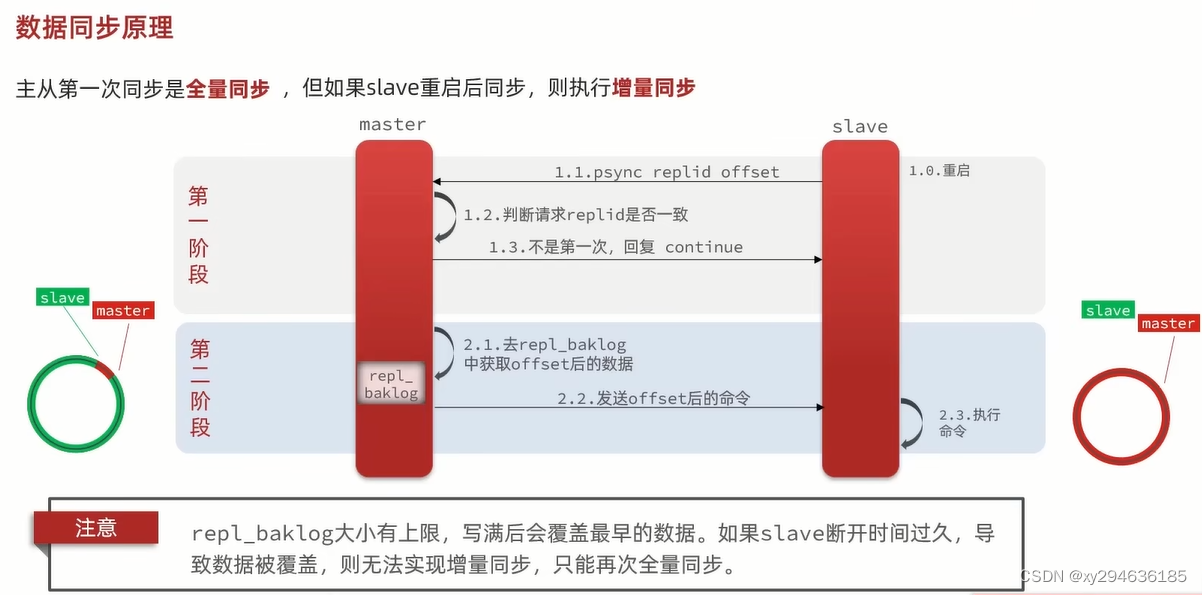
增量同步
slave将自己的offset提交到master,master获取repl_baklog中从offset之后的命令给slave
注:slave节点断开又恢复,并在repl_baklog中找到offset时
优化Redis主从集群
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO
- Redis单节点上的内存占用不要太大,减少RDB导致的磁盘IO
- 适当提高repl_baklog的大小,发展slave宕机尽快回复,避免全量
- 限制一个master上的slave数量,太多salve建议采用主-从-从链式结构,减少master压力
问题:salve宕机可以找master同步数据,master宕机怎们办呢?
哨兵机制-主从切换
Redis哨兵
哨兵作用和原理 重要
Redis哨兵(Sentinel)机制实现主从集群的自动故障恢复。

- 监控:Sentinel会不断检查master和slave是否按预期工作。
- 故障恢复:master故障哨兵会将一个新的slave提升为master。当故障实例恢复后也以新的master为主。
- 通知:Sentinel充当Redis客户端服务发现来源,当集群发生故障转移时,会将最新消息推送给Redis的客户端。
服务状态监控
Sentinel基于心跳机制检测服务状态,每1s向集群的每个实例发送ping命令:
- 主观下线:如果sentinel节点发现某个实例未在规定时间响应,则认为该实例主动下线。
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线,quorum值最好超过sentinel实例的一半。
选举新的master规则:
- 首先判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds*10)则会排除该slave几点
- 判断slave节点的slave-priority值,越小优先级越高,为0则永不参与选举。
- 如slave-priority一样,则判断slave节点的offset值,越大说明值越新,优先级越高。
- 最后是判断slave节点的运行id大小,越小优先级越高。
如何实现故障转移(当选择slave1为新master后):
- sentinel给备选的slave1发送slaveofnoone(别当奴隶了)命令,让该节点成为新的master。
- sentinel给其他slave发送slaveof slave1的ip+端口号,让他们成为slave1的从节点,从新的master上同步数据。
- sentinel将故障节点标记为slave发送slaveod命令,当故障节点恢复后会自动成为新的master的slave节点。
搭建哨兵集群
具体搭建流程参考百度:《Redis集群.md》
RedisTemplate的哨兵模式
spring的RedisTemplate底层利用lettuce实现节点的感知和自动切换。
- pom:spring-boot-starter-data-redis
- 配置sentinel信息
- 启动类配置主从读写分离
/**
* MASTER:从主节点读取
* MASTER_PREFERRED:优先master读取,不可用读取replica
* REPLICA:从slave读取
* ERPLICA_PREFERRED:优先从slave节点读取,所有的slave都不可用才读取master
*/
@Bean
public LettuceClientConfigurationBuilderCustomizer configurarionBuilderCustomizer(){
return configBuilder -> configBuilder.readFrom(ReadFrom.ERPLICA_PREFERRED);
}
Redis分片集群
为什么需要分片集群?
主从和哨兵可以解决高可用,高并发读问题,但依然还有两个问题没有解决:
- 海量数据存储问题
- 高并发写问题
使用分片集群可以解决上述问题,分片集群特征:
- 集群中有多个master,每个master保存不同的数据。
- 每个master都可以有多个slave节点。
- master之间通过ping检测彼此之间健康状态。
- 客户端请求可以访问任何集群任意节点,最终都会被转发到正确的节点。
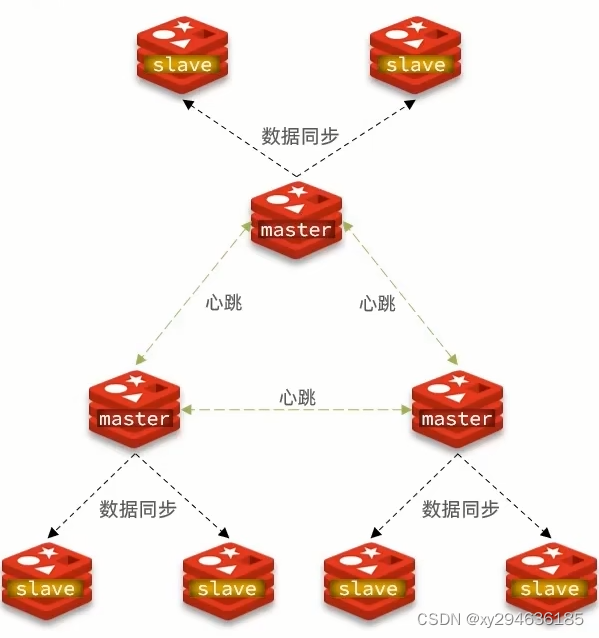
搭建分片集群
具体搭建流程参考百度:《Redis分片集群.md》
散列插槽
Redis会把每一个master节点映射到0~16383个插槽(hash slot)上去,查看集群信息时就能看到。
数据的key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,计算方式为CRC16算法得到一个hash值,然后对16384取余得到slot值,分两种情况:
- key中包含{},且{}中至少包含1个字符,{}中的部分是有效部分(key是{test}num,则根据test计算)
- key中不包含{},整个key都是有效部分。(key是num,则根据num计算)
问题:为什么数据要绑定插槽上呢?
数据跟着插槽走,宕机时对应插槽可以转移到活着的节点。
问题:如何将同一类的数据固定的保存在同一个redis实例?
使用相同{key}。
集群伸缩
添加一个节点到集群:redis -cli --cluster add -node
需求:向集群中添加一个新的master节点,并向其中存储num=10
- 启动一个新的redis实例,指定端口:redis-server port/redis.conf
- 添加实例端口到之前的集群,作为一个master节点:redis-cli --cluster add-node ip:port ip:port(已存在的)
- 给实例端口节点分配插槽,使得num这个key可以存储到实例端口(难点):redis-cli --cluster reshard ip:port(已存在的) num(插槽数量) 然后根据提示配置好插槽即可。
练习:删除集群中的一个节点。
故障转移
当集群中有一个master宕机后会发生什么事情?(自动)
- 首先该实例与其他实例失去连接
- 然后疑似宕机
- 最后确定下线,自动提升一个slave为新的master。
数据转移(手动)
利用cluster failover命令可以手动让集群中的某个master宕机,切换到cluster failover命令的这个slave节点,实现无感知的数据迁移。《图:分片集群手动数据迁移》
Failover三种模式:缺省,force,takeover
案例:在7002这个slave节点执行手动故障转移,重回master低位:
- 利用redis-cli连接7002
- 执行cluster failover命令
RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持而使用的步骤和哨兵模式基本一致:
- 引入redis的starter依赖
- 配置分片集群地址
- 配置读写分离
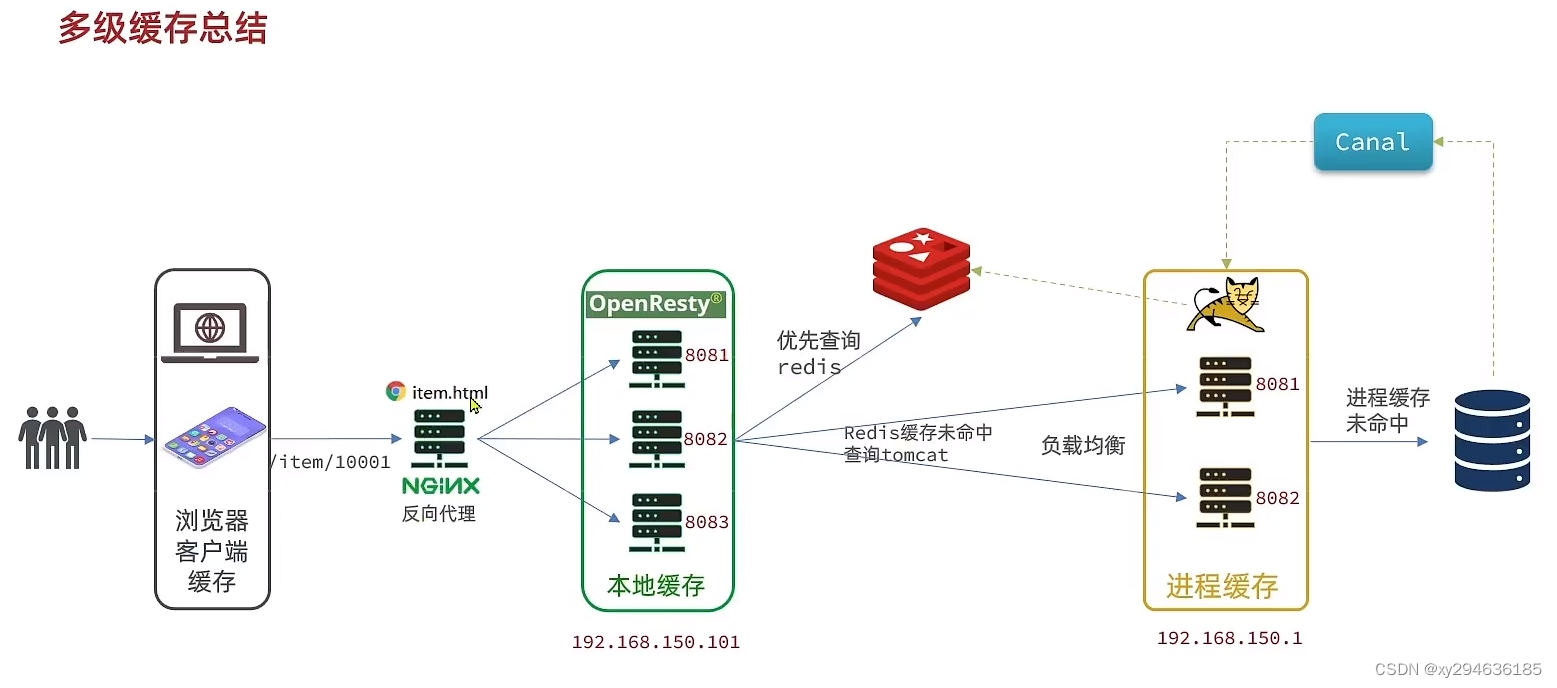
多级缓存-亿级流量的缓存方案
传统缓存的问题:传统缓存策略一般是请求到tomcat后,先查询redis,如果未命中则查询数据库。
- 请求要经过tomcat处理,tomcat性能不如redis成为整个系统的瓶颈
- redis缓存失效,对数据库产生冲击。
多级缓存方案:利用处理请求的每个环节,分别添加缓存,减轻Tomcat压力。
用户–浏览器端缓存(静态资源渲染:检验码304,90%请求可拦截)–nginx(反向代理)–nginx本地缓存(集群)–nginx端redis缓存–tomcat进程缓存–mysql
JVM进程缓存(tomcat进程缓存)
缓存分为两类:
- 分布式缓存(Redis):优点:量大 ,可靠性高,可以集群。缺点:有网络开销。场景:数据量大,可靠性高,集群间共享。
- 本地进程缓存(Caffeine,HashMap,GuavaCache):优点:本地,无网络,速度快。缺点:量小,可靠性低,无法共享。场景:性能要求高,数据量小
初识Caffeine:java8开发Spring内部缓存使用(本地缓存中最优)。Cache<String, String> cache = Caffeine.newBuilder().build();利用工厂模式构造cache对象。
Caffine缓存驱逐策略:基于容量,基于时间,基于引用(性能差,不建议)。在一次读写操作后或空闲时间完成数据驱逐。
Lua语法入门(nginx+Lua)
Lua:标准C编写的脚本语言,用于嵌入应用程序中,为应用程序提供灵活的扩展和定制功能。
Lua数据结构:nil,boolean,number,string,function(c或Lua编写的函数),table(hashmap)。可用type函数返回变量类型。
Lua定义变量:local str = ‘test’,local arr = {‘java’,‘py’},local map = {name = ‘Jack’,age = 32}
Lua获取变量:arr1,map[‘name’],map.name
Lua遍历数组:for index,value in ipairs(arr) do //todo end
Lua遍历table:for key,value in pairs(map) do //todo end
Lua函数:function 函数名(arg1,arg2…) //函数体 return nil end
Lua条件控制:类似javaif,else
实现多级缓存
OpenResty:基于Nginx的高性能web平台。用于搭建处理高并发,扩展性高的动态web应用,web服务和动态网关。功能:
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的Lua库,第三方模块
- 允许使用Lua自定义业务逻辑,自定义库
OpenResty构思:前端请求被nginx反向代理到虚拟机OpenResty集群,请求在OpenResty中接收这个请求,并返回数据。
OpenResty流程:
- 修改nginx.conf文件:在http下面添加对OpenResty的Lua模块的加载;在server下面添加对path路径的监听(响应类型和响应数据)。
- 编写item.lua文件
OpenResty获取请求参数:
nginx向tomcat获取数据(暂不加redis缓存)
nginx内部发送Http请求:
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, --请求方式
args = {a=1,b=2}, --get方式传参
body = "c=3&d=4" -- post方式传参
})
//注意:这里的/path是路径,并不包含ip和端口。这个请求会被nginx内部的server监听并处理
暂时不经过redis缓存,直接向tomcat服务器访问获取数据,还需一个server对这个路径做反向代理:
location /path {
#这里是windows电脑的ip和java服务端口,需确保windows防火墙处关闭状态
proxy_pass http://192.168.150.1:8081
}
返回响应内容:resp.status(状态码),resp.header(响应头,table),resp.body(响应数据)
封装http查询的函数:我们可以把http查询请求封装为一个函数,放到openresty函数库中,方便后面使用。
- 在/usr/local/openresty/lualib目录下创建common.lua文件
- 在common.lua中封装http查询函数
--封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
--记录错误信息,返回404
ngx.log(ngx.ERR, "http查询失败, path: ",path,",args:",args)
ngx.exit(404)
end
return resp.body
end
--将方法导出为table
local _M = {
read_http = read_http
read_redis = read_redis //预留:后面需要加载redis模块
}
return _M
使用http查询函数:
--导入封装的common函数
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
--导入cjson库
local cjson = require('cjson')
--导入共享字典
local item_cache = ngx.shared.item_cache
--获取路径参数
local id = ngx.var[1]
--查询商品信息
local itemJSON = read_http("/item/" .. id, nil)
--查询库存信息
local stockJSON = read_http("/iem/stock/" .. id, nil)
--JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
--组合数据
item.stock = stock.stock
item.sold = stock.sold
--把item序列化为json返回结果
ngx.say(cjson.encode(item))
JSON处理结果:
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
- 引入json模块: local cjson = require “cjson”
- 序列化:local obj = {name=‘jack’,age = 21} local json = cjson.encode(obj)
- 反序列化:local json = ‘{“name”: “jack”, “age”,21}’ -反序列化 local obj = cjson.decode(json) print(obj.name)
tomcat端做负载均衡:
每个tomcat的实例缓存都在本地,需要做hash映射。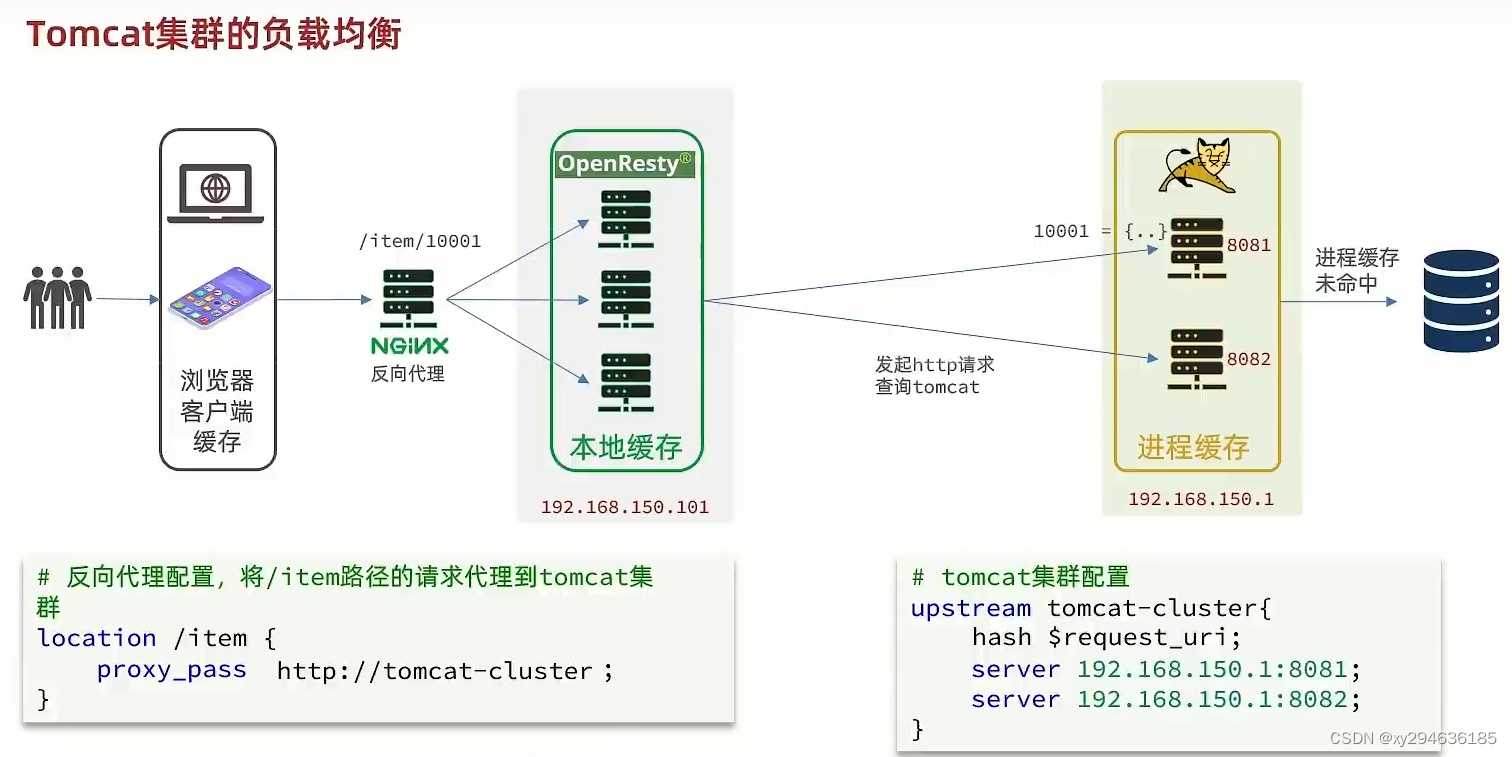
upstream tomcat-clusrer{
hash $request_uri; --基于requestUri做hash映射
server ip:port1
server ip:port2
}
server{
listen 8081;
server_name = loclahost;
location / item {
proxy_pass http://tomcat-cluster
}
location ~ /api/item/(\d+) {
#默认的响应类型
default_type application/json
#响应结果由lua/item.lua文件决定
content_by_lua_file lua/item.lua
}
}
nginx加redis缓存
添加Redis缓存(冷启动与缓存预热):
- 冷启动:启动服务时Redis没有缓存,如果第一次加载全量数据缓存,会给数据库带来压力
- 缓存预热:利用大数据统计用户访问热点数据,在启动时就将这些数据加载到Redis中
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private Service service;
private static final ObjectMapper MAPPER = new ObjectMapper(); //json序列化
@Override
public void afterPropertiesSet() throws Exception{
//初始化缓存
//1.查询信息
List<Bean> list = service.list();
//2.放入缓存
for(Bean bean : list){
String json = MAPPER.writeValueAsString(bean);
redisTemplate.opsForValue.set("KEY",json);
}
}
}
OpenResty加载Redis模块,放入common模块,并在lcoal _M{}中将read_redis方法暴露出去:
- 引起如Redis模块,初始化Reids对象:
local redis = require('resty.redis')
local red = redis::new()
red:set_timeout(1000,1000,1000)
- 封装函数,用来释放Redis连接,其实是放入连接池:
local function close_redis(red)
local pool_max_idle_time = 10000
local pool_size = 100
local ok,err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, '放入Redis连接池失败:', e)
end
end
- 封装函数,从Redis读取数据并返回
local function read_redis(ip, port, key)
local ok,err = red:connect(ip,port) --获取一个连接
if not ok then
ngx.log(ngx.ERR, "连接Redis失败:", e)
return nil
end
//查
lcoal resp,err = red.get(key)
if not resp then
ngx.log(ngx.ERR, "查询Redis失败:", e)
end
if resp == ngx.null then
resp = nil;
ngx.log(ngx.ERR, "查询Redis为空:", e)
end
closr_redis(red)
return resp
end
- 封装函数,查询加载Redis
local function read_data(key, path, params)
localresp = read_redis("127.0.0.1", 6379, key)
if not resp then
resp = read_http(path, params)
end
return resp
end
nginx本地缓存
OpenResty为Nginx提供了shard dict功能,可在nginx的多个worker间共享数据,实现缓存功能。
- 开启共享字典:在nginx.conf的http下添加配置:lua_shared_dict item_cache 150m;
- 操作共享字典:
local item_cache = ngx.shared.item_cache
item_cache:set(‘key’,‘value’,1000)
local var = item_cache:get(‘key’)
需求:1.修改item.lua中的read_data函数,优先查询本地缓存,未命中再查redis,tomcat。2.查redis或tomcat写入本地设置有效期。
缓存同步策略
- 设置有效期:给缓存设置有效期,到期自动查询,再次查询时更新。(差,缓存不一致,更新频率低)
- 同步双写:修改数据库同时修改缓存。(强,一致,有代码入侵,耦合度高)
- 异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据。(一般,中间状态不一致,可通知多个服务)
基于canal的异步通知
canal基于数据库增量日志解析,提供增量数据订阅&消费。可监听mysql数据库binlog通知缓存服务,更新redis,代码侵入低。
canal基于mysql的主从同步实现。
- mysql master将数据变更写入二进制日志(binary log),其中数据为binary log events
- mysql slave将master的binary log events拷贝到他的中继日志(relay log)
- mysql slave重放relay log中事件,将数据同步。
canal就是把自己伪装成mysql的一个slave节点,从而监听master的binlog变化。
开启canal需要修改mysql主从。
Canal客户端
坐标:<artifactId>canal-spring-boot-starter</artifactId>
配置:
canal:
destination: xuy
server: ip:port
编写监听类,监听canal:
canal推送给canal-client的是被修改的这一行数据,其会把行数据转换成Item实体类。需要在字段上加@TableName,@Id,@Column,@TableField(exist=false)+@Transient(非数据库字段)等注解
/**
* 监听增,改,删的消息
*/
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {
@Autowired
private RedisHandler redisHandler;
@Autowired
private Cache<Long, Item> itemCache;
@Override
public void insert(Item item) {//新增数据到redis}
@Override
public void update(Item before, Item after) {//更新reids,本地缓存}
@Override
public void delete(Item item) {//删除reids,本地缓存}
}
多级缓存架构图