文章目录
- 第四章 文件管理
- [4.1.1] 初识文件管理
- (一)文件的属性
- (二)文件内部的数据应该怎样组织起来
- (三)文件之间应该怎样组织起来
- (四)操作系统应该向上提供哪些功能
- (五)从上往下看,文件应如何存放在外存
- (六)其他需要由操作系统实现的文件管理功能
- 小结
- [4.1.2] 文件的逻辑结构
- (一)无结构文件
- (二)有结构文件
- (三)有结构文件的逻辑结构
- (1)顺序文件
- (2)索引文件
- (3)索引顺序文件
- (4)多级索引顺序文件
- 小结
- [4.1.3] 文件目录
- (一)文件控制块
- (二)目录结构
- (1)单级目录结构
- (2)两级目录结构
- (3)多级目录结构
- (4)无环图目录结构
- (三)索引结点(FCB的改进)
- 小结
第四章 文件管理
[4.1.1] 初识文件管理

计算机中存放了各种各样的文件,一个文件有哪些属性?
文件内部的数据应该怎样组织起来?
文件之间又应该怎么组织起来?
从下往上看,操作系统应提供哪些功能,才能为它的上层,即方便用户、应用程序使用文件?
从上往下看,文件数据应该怎么存放在外存(磁盘)上?
从最熟悉的Windows操作系统出发。
(一)文件的属性
一个文件有哪些属性?
文件名:由创建文件的用户决定文件名,主要是为了方便用户找到文件,同一目录下不允许有重名文件。
标识符:一个系统内的各文件标识符唯一,对用户来说毫无可读性,因此标识符只是操作系统用于区分各个文件的一种内部名称(所以这个名称不向用户展示,右键-属性里也没有,这是操作系统内部自己用的)。(比如,虽然我同一目录下不能有重名文件,但是不同目录下可以有,比如两个目录下都有test.txt文件,那么该怎么区分他俩?就需要唯一标识符)
类型:指明文件的类型。
位置:文件存放的路径(让用户使用)、在外存中的地址(操作系统使用,对用户不可见)。
大小:指明文件大小。
创建时间、上次修改时间、文件所有者信息。
保护信息:对文件进行保护的访问控制信息。(用户组)
(二)文件内部的数据应该怎样组织起来
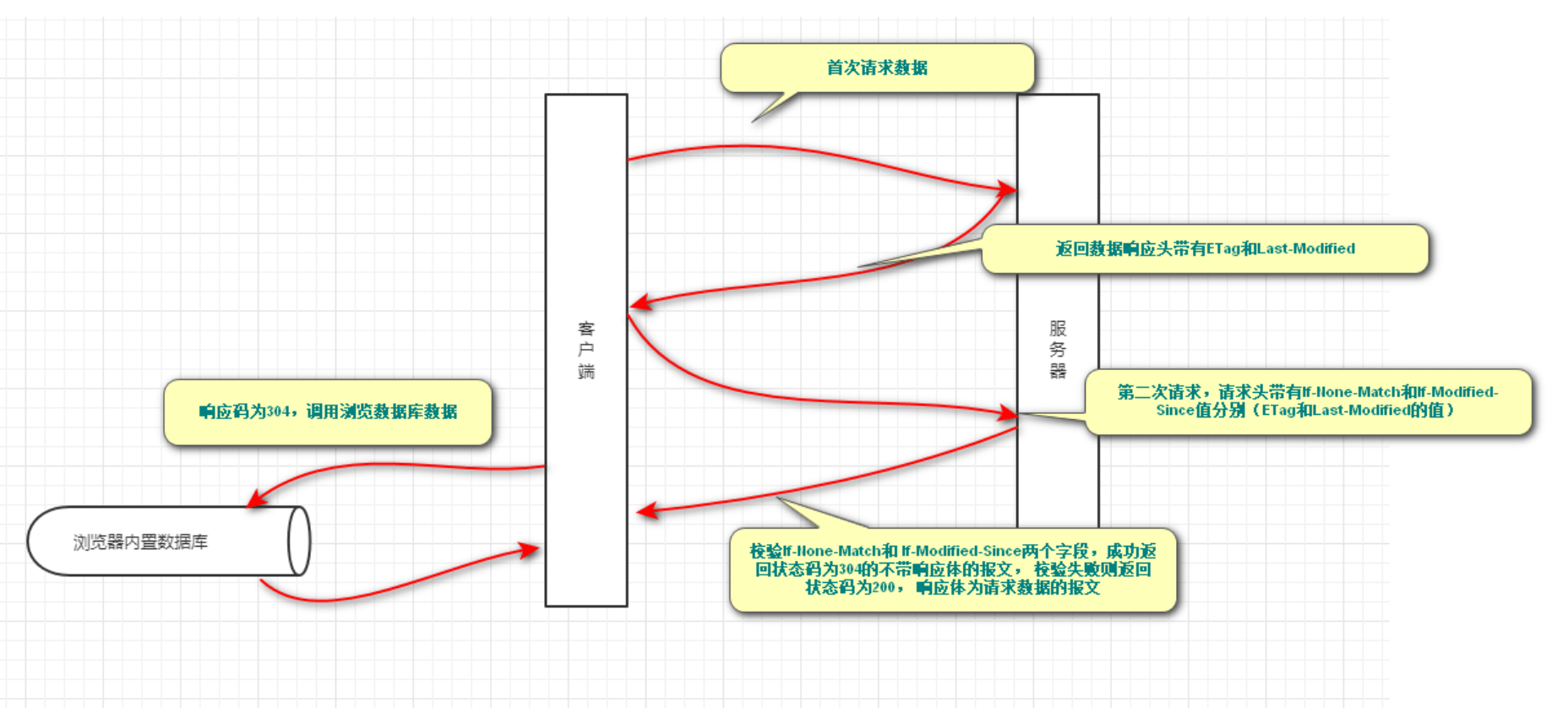
无结构文件(如文本文件)——由一些二进制或字符流组成,又称“流式文件”。
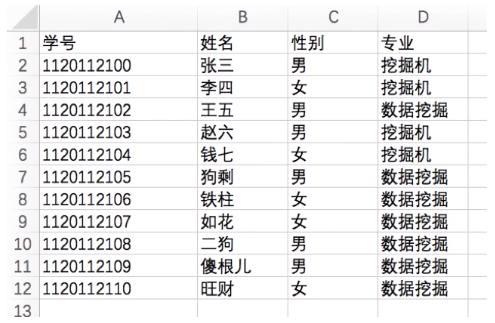
有结构文件(如数据库表)——由一组相似的记录组成,又称“记录式文件”。
记录是一组相关数据项的集合。(如上图中的一行就是一个记录)
数据项是文件系统中最基本的数据单位。(如上图中的某行某列)
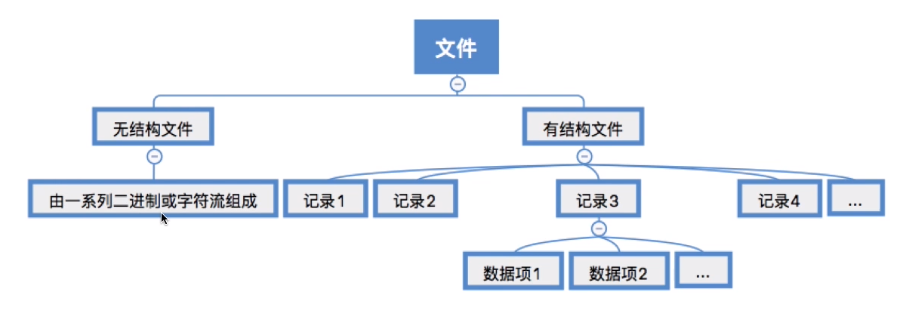
有结构文件中,各个记录间应该如何组织的问题——应该顺序存放?还是用索引表来表示记录间的顺序?——这是“文件的逻辑结构”重点要探讨的问题。
(三)文件之间应该怎样组织起来
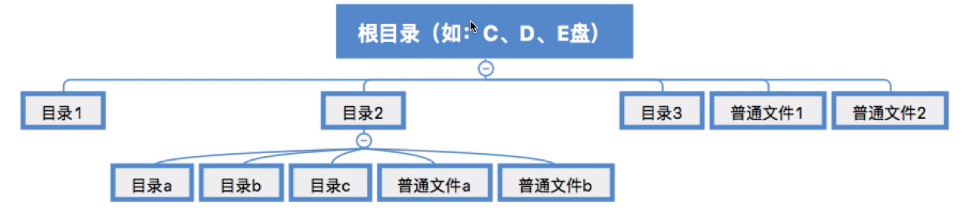
所谓的“目录”其实就是我们熟悉的“文件夹”。
用户可以自己创建一层一层的目录,各层目录中存放相应的文件。系统中的各个文件就通过一层一层的目录合理有序的组织起来了。
目录其实也是一种特殊的有结构文件(由记录组成),如何实现文件目录是之后会重点探讨的问题。
(四)操作系统应该向上提供哪些功能
向上提供的几个最基本的功能
创建文件(create系统调用)
删除文件(delete系统调用)
读文件(read系统调用)
写文件(write系统调用)
打开文件(open系统调用)
关闭文件(close系统调用)
(这里的打开、关闭文件,和我们理解的双击某文件打开、点叉号关闭是不太一样的,后续再说)
读/写文件之前,需要“打开文件”。读/写文件结束之后,需要“关闭文件”。
可以用几个基本操作完成更复杂的操作,比如“复制文件”,先创建一个新的空文件,再把原文件读入内存,再将内存中的数据写到新文件中。
操作系统在背后做的处理会在以后进行探讨。
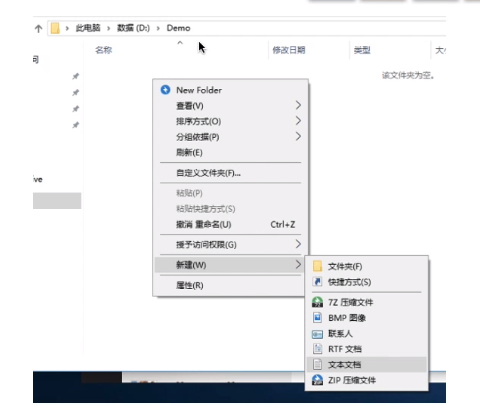
可以“创建文件”,点击新建后,图形化交互进程在背后调用了“create系统调用”。
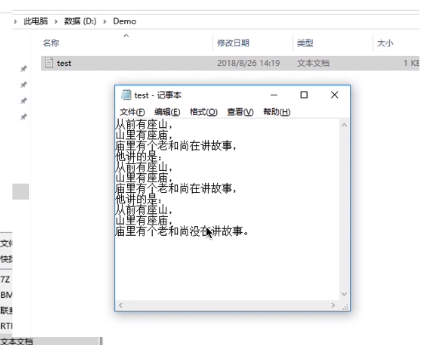
可以“读文件”,将文件数据读入内存,才能让CPU处理(双击后,“记事本”应用程序通过操作系统提供的“读文件”功能,即read系统调用,将文件数据从外存读入内存,并显示在屏幕上)。
可以“写文件”,将更改过的文件数据写回外存(我们在“记事本”应用程序中编辑文件内容,点击“保存”后,“记事本”应用程序通过操作系统提供的“写文件”功能,即write系统调用,将文件数据从内存写回外存)。
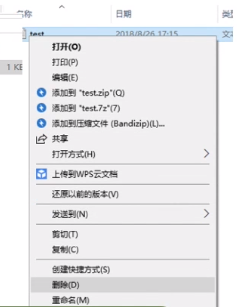
可以“删除文件”(点了“删除”之后,图形化交互进程通过操作系统提供的“删除文件”功能,即delete系统调用,将文件数据从外存中删除)。
(五)从上往下看,文件应如何存放在外存
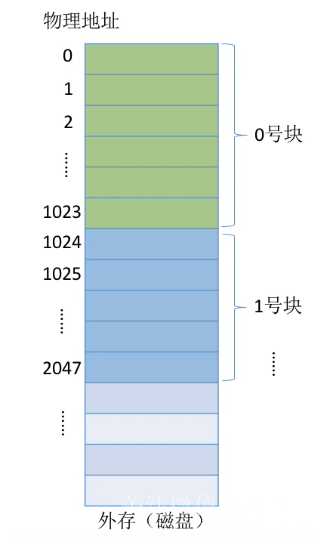
与内存一样,外存也是由一个个存储单元组成的,每个存储单元可以存储一定量的数据(如1B)。每个存储单元对应一个物理地址。
类似于内存分为一个个的“内存块”,外存会分为一个个“块/磁盘块/物理块”。每个磁盘块的大小是相等的,每块一般包含2的整数幂个地址(如本例中,一块包含 2 10 2^{10} 210个地址,即1KB)。同样类似的是,文件的逻辑地址也可以分为(逻辑块号,块内地址),操作系统同样需要将逻辑地址转换为外存的物理地址(物理块号,块内地址)的形式。块内地址的位数取决于磁盘块的大小。
操作系统以“块”为单位为文件分配存储空间,因此即使一个文件大小只有10B,但它依然需要占用1KB的磁盘块。外存中的数据读入内存时同样以块为单位。
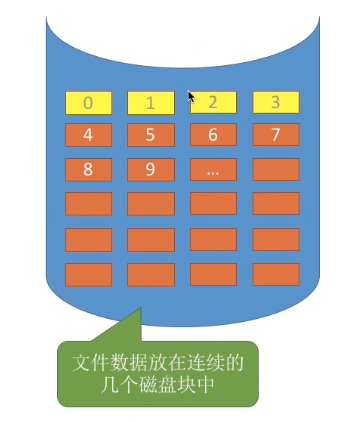
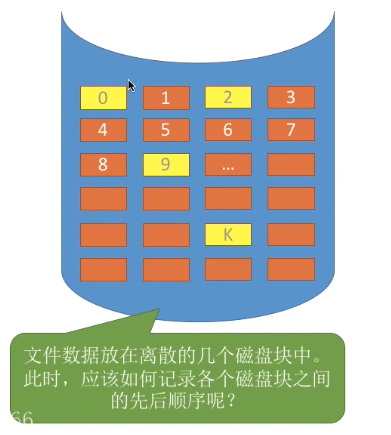
文件是否应该需要存放在连续的几个磁盘块中?
文件如果比较大,是不是应该存放在离散的几个磁盘块中?
对于空闲的磁盘块,操作系统又应该怎样管理?
这些是在“文件的物理结构”部分会探讨的内容。
(六)其他需要由操作系统实现的文件管理功能
文件共享:使多个用户可以共享使用一个文件。
文件保护:如何保证不同的用户对文件有不同的操作权限。
之后会结合Windows操作系统的实际应用进行探讨。
小结

[4.1.2] 文件的逻辑结构
文件的逻辑结构
- 无结构文件
- 有结构文件
- 顺序文件
- 索引文件
- 索引顺序文件
所谓的“逻辑结构”,就是指在用户看来,文件内部的数据应该是如何组织起来的。
而“物理结构”指的是在操作系统看来,文件的数据是如何存放在外存中的。
其实在数据结构当中,我们也接触过“逻辑结构”和“物理结构”,如“线性表”就是一种逻辑结构,在用户角度看来,线性表就是一组有先后关系的元素序列。
但是,对于一种逻辑结构来说,是可以用不同的物理结构来实现的。如:顺序表、链表。顺序表的各个元素在逻辑上相邻,在物理上也相邻;而链表的各个元素在物理上可以是不相邻的。因此,顺序表可以实现“随机访问”,而“链表”无法实现随机访问。
可见,算法的具体实现与逻辑结构、物理结构都有关(文件也一样,文件操作的具体实现与文件的逻辑结构、物理结构都有关)
(一)无结构文件
按文件是否有结构分类,可以分为无结构文件、有结构文件两种。
无结构文件:文件内部的数据就是一系列二进制流或字符流组成。又称“流式文件”。如:Windows操作系统中的.txt文件。
文件内部的数据其实就是一系列字符流,没有明显的结构特性。因此也不用探讨无结构文件的“逻辑结构”问题。
因此我们重点关注的是有结构文件。
(二)有结构文件
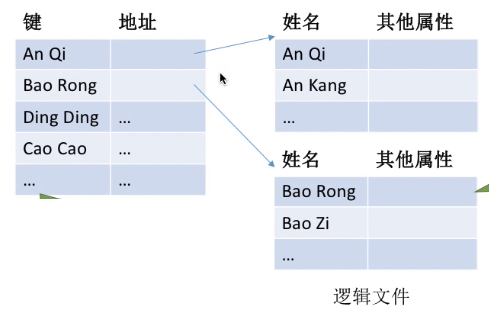
有结构文件:由一组相似的记录组成,又称“记录式文件”。每条记录由若干个数据项组成。如:数据库表文件。一般来说,每条记录有一个数据项可作为关键字(作为识别不同记录的ID)。
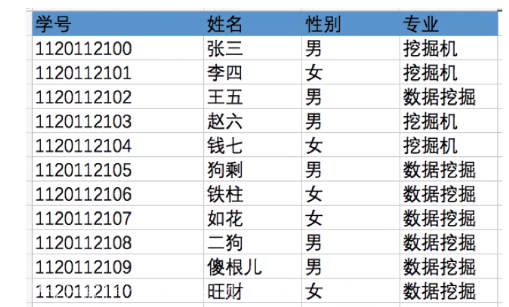
这是一张数据库表,记录了各个学生的信息。
每个学生对应一条记录,每条记录由若干个数据项组成。
在本例中,“学号”即可作为各个记录的关键字。
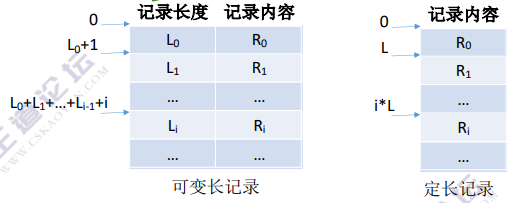
根据各条记录的长度(占用的存储空间)是否相等,又可分为定长记录和可变长记录两种。
定长记录
如上例中,设置学号占32字节,姓名占32字节,性别占4字节,专业占60字节。

这个有结构文件由定长记录组成,每条记录的长度都相同(共128B)。各数据项都处在记录中相同的位置,具有相同的顺序和长度(前32B一定是学号,之后32B一定是姓名…)
可变长记录
其实可变长记录才是我们生活中最常见的。


这个有结构文件由可变长记录组成,由于各个学生的特长存在很大区别,因此“特长”这个数据项的长度不确定,这就导致了各条记录的长度也不确定。当然,没有特长的学生甚至可以去掉“特长”数据项。
(三)有结构文件的逻辑结构
有结构文件的逻辑结构
- 顺序文件
- 索引文件
- 索引顺序文件
根据有结构文件中的各条记录在逻辑上如何组织,可以分为这三类。
(1)顺序文件
顺序文件:文件中的记录一个接一个地顺序排列(逻辑上),记录可以是定长的或可变长的。各个记录在物理上可以顺序存储或链式存储。

顺序存储——逻辑上相邻的记录,物理上也相邻(类似于顺序表)。
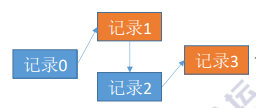
链式存储——逻辑上相邻的记录,物理上不一定相邻(类似于链表)。
顺序文件
串结构
记录之间的顺序与关键字无关。通常按照记录存入的时间决定记录的顺序。
顺序结构
记录之间的顺序按关键字顺序排列。
假设:已经知道了文件的起始地址(也就是第一个记录存放的位置)
思考1:能否快速找到第i个记录对应的地址?(即能否实现随机存取)
思考2:能否快速找到某个关键字对应的记录存放的位置?
我们直接给出结论,如下。
顺序文件
-
链式存储
无论是定长/可变长记录,都无法实现随机存取,每次只能从第一个记录开始依次往后查找。
-
顺序存储
-
可变长记录
无法实现随机存取。每次只能从第一个记录开始依次往后查找。
-
定长记录
- 可实现随机存取。记录长度为L,则第i个记录存放的相对位置是
i*L; - 若采用串结构,无法快速找到某关键字对应的记录;
- 若采用顺序结构,可以快速找到某关键字对应的记录(如折半查找)。
- 可实现随机存取。记录长度为L,则第i个记录存放的相对位置是
-
结论:定长记录的顺序文件,若物理上采用顺序存储,则可实现随机存取;若能再保证记录的顺序结构,则可实现快速检索(即根据关键字快速找到对应记录)
注:一般来说,考试题目中所说的“顺序文件”指的是物理上顺序存储的顺序文件(即不是链式存储)。之后的讲解中提到的顺序文件也默认如此。
可见,顺序文件的缺点是增加/删除一个记录比较困难(如果是串结构则相对简单)。
(2)索引文件
对于可变长记录文件,要找到第i个记录,必须先顺序的查找前i-1个记录,但是很多应用场景中又必须使用可变长记录。如何解决这个问题?
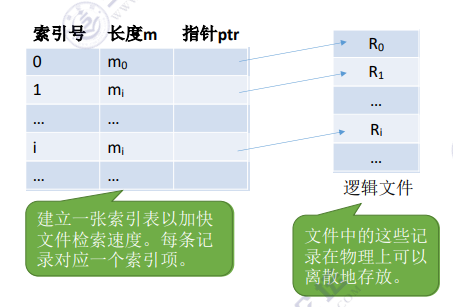
索引表本身是定长记录的顺序文件。因此可以快速找到第i个记录对应的索引项。
可将关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字折半查找。
每当要增加/删除一个记录时,需要对索引表进行修改。由于索引文件有很快的检索速度,因此主要用于对信息处理的及时性要求比较高的场合。
另外,可以用不同的数据项建立多个索引表。如:学生信息表中,可用关键字“学号”建立一张索引表。也可用“姓名”建立一张索引表。这样就可以根据“姓名”快速地检索文件了。
(3)索引顺序文件
思考索引文件的缺点:每个记录对应一个索引表项,因此索引表可能会很大。
比如:文件的每个记录平均只占8B,而每个索引表项占32个字节,那么索引表项都要比文件内容本身大4倍,这样对存储空间的利用率就太低了。
索引顺序文件是索引文件和顺序文件思想的结合。索引顺序文件中,同样会为文件建立一张索引表,但不同的是:并不是每个记录对应一个索引表项,而是一组记录对应一个索引表项。
首先将文件记录进行分组。在本例中,学生记录按照学生姓名的开头字母进行分组。每个分组就是一个顺序文件,分组内的记录不需要按关键字排序。
之后,每个分组对应索引顺序文件中的一个索引项。索引顺序文件的索引项也不需要按关键字顺序排列,这样可以极大地方便新表项的插入。(定长记录、串结构)
用这种策略,确实可以让索引表“瘦身”,但是是否会出现不定长记录的顺序文件检索速度慢的问题呢?
索引顺序文件——检索效率分析
若一个顺序文件有10000个记录,则根据关键字检索文件,只能从头开始顺序查找(这里指的并不是定长记录、顺序结构的顺序文件),平均需查找5000个记录。
若采用索引顺序文件结构,可把10000个记录分为 10000 = 100 \sqrt{10000}=100 10000=100组,每组100个记录。则需要先顺序查找索引表找到分组(共100个分组,因此索引表长度为100,平均需要查50次),找到分组后,再在分组中顺序查找记录(每个分组100个记录,因此平均需要查50次)。可见,采用索引顺序文件结构后,平均查找次数减少为50+50=100次。
同理,若文件共有 1 0 6 10^6 106个记录,则可分为1000个分组,每个分组1000个记录。根据关键字检索一个记录平均需要查找500+500=1000次。这个查找次数依然很多,如何解决呢?
(4)多级索引顺序文件
为了进一步提高检索效率,可以为顺序文件建立多级索引表。例如,对于一个含 1 0 6 10^6 106个记录的文件,可先为该文件建立一张低级索引表,每100个记录为一组,故低级索引表中共有10000个表项(即10000个定长记录),再把这10000个定长记录分组,每组100个,为其建立顶级索引表,故顶级索引表中共有100个表项。
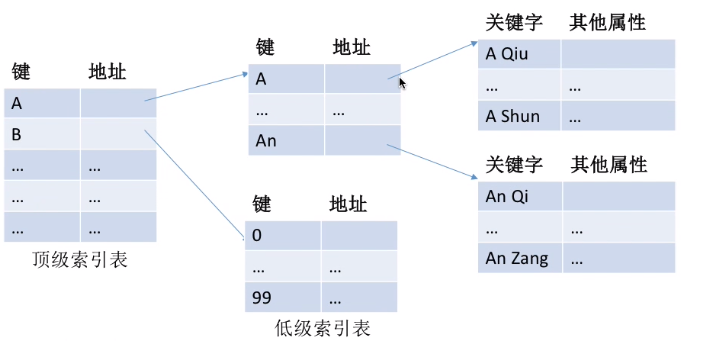
此时,检索一个记录平均需要查找50+50+50=150次。
小结


[4.1.3] 文件目录
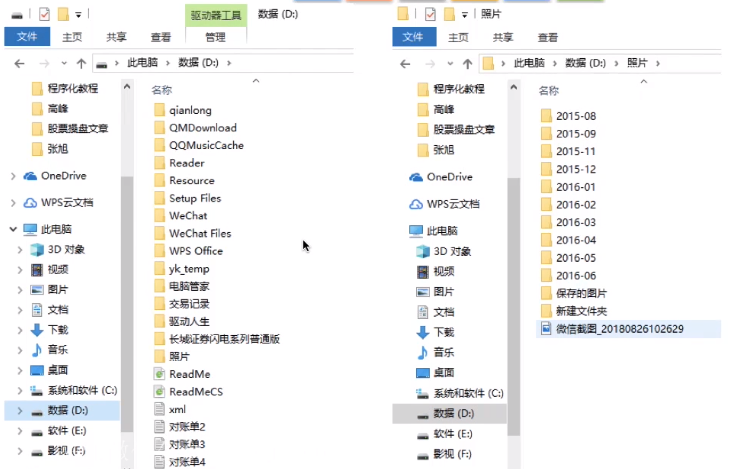
这种目录结构对于用户来说有什么好处?
文件之间的组织结构清晰,易于查找。
编程时也可以很方便地用文件路径找到一个文件。如下。这样,用户可以轻松实现“按名存取”。
FILE *fp;
fp = fopen("F:\data\myfile.dat");
从操作系统的角度来看,这些目录结构应该是如何实现的?
文件目录
(就是我们很熟悉的Windows操作系统的“文件夹”)
- 文件控制块(实现文件目录的关键数据结构)
- 目录结构
- 单级目录结构
- 两级目录结构
- 多级目录结构(树形目录结构)
- 无环图目录结构
- 索引结点(对文件控制块的优化)
(一)文件控制块
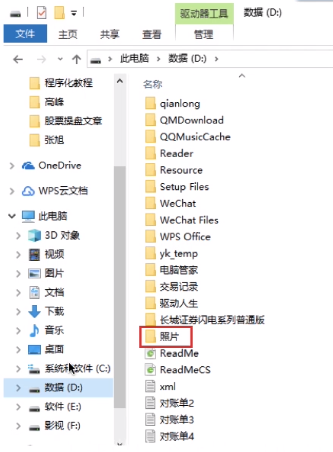
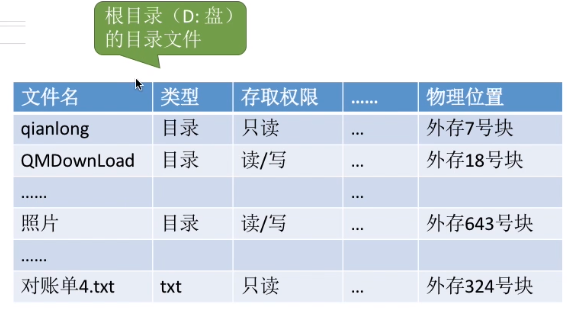
用一个所谓的“目录表”,来表示这个目录下存放了哪些东西。每一个文件、文件夹,都会对应其中一个表项。(目录/文件夹是一种特殊的文件了)
目录本身就是一种有结构文件,由一条条记录组成。每条记录对应一个放在该目录下的文件。
当我们双击“照片”后,操作系统会在这个目录表中找到关键字“照片”对应的目录项(也就是记录),然后从外存中将“照片”目录的信息读入内存,于是,“照片”目录中的内容就可以显示出来了。
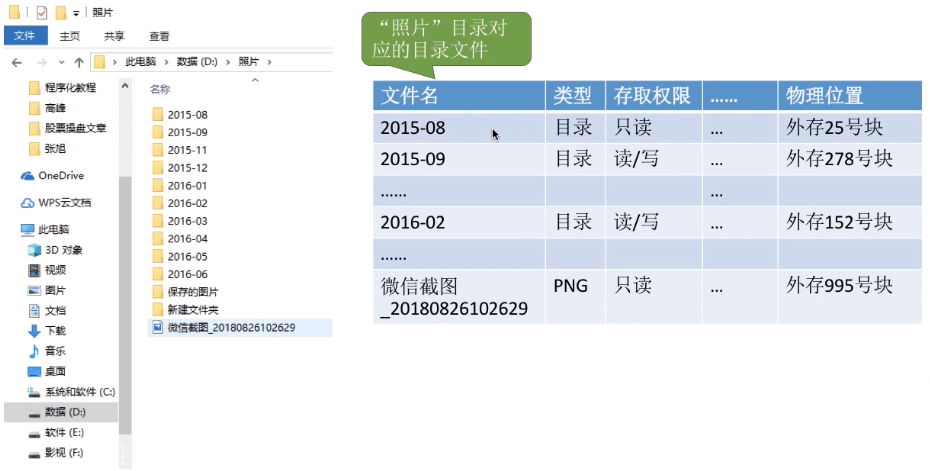
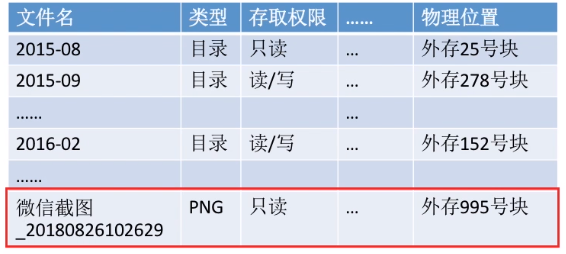
目录文件中的一条记录就是一个“文件控制块(FCB)”。(就是上图所谓“目录表”里面的一行)
FCB的有序集合称为“文件目录”,一个FCB就是一个文件目录项。
FCB中包含了文件的基本信息(文件名、物理地址、逻辑结构、物理结构等),存取控制信息(是否可读/可写、禁止访问的用户名单等),使用信息(如文件的建立时间、修改时间等)。
最重要、最基本的还是文件名、文件存放的物理地址。
FCB最终要的是实现了文件名和文件之间的映射。使用户(用户程序)可以实现“按名存取”。
需要对目录进行哪些操作?
搜索:当用户要使用一个文件时,系统要根据文件名搜索目录,找到该文件对应的目录项。
创建文件:创建一个新文件时,需要在其所属的目录中增加一个目录项。
删除文件:当删除一个文件时,需要在目录中删除相应的目录项。
显示目录:用户可以请求显示目录的内容,如显示该目录中的所有文件及相应属性。
修改目录:某些文件属性保存在目录中,因此这些属性变化时需要修改相应的目录项(如:文件重命名)。
(二)目录结构
(1)单级目录结构
早期操作系统并不支持多级目录,整个系统中只建立一张目录表,每个文件占一个目录项。
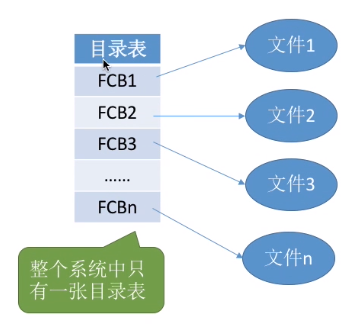
单级目录实现了“按名存取”,但是不允许文件重名。
在创建一个文件时,需要先检查目录表中有没有重名文件,确定不重名后才能允许建立文件,并将新文件对应的目录项插入目录表中。
显然,单级目录结构不适用于多用户操作系统。(多个用户使用一个系统时,很容易使文件名重复)
(2)两级目录结构
早期的多用户操作系统,采用两级目录结构。分为主文件目录(MFD,Master File Directory)和用户文件目录(UFD,User File Directory)。
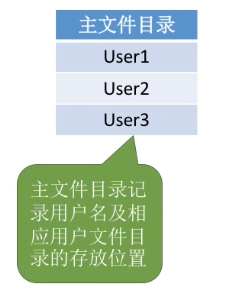
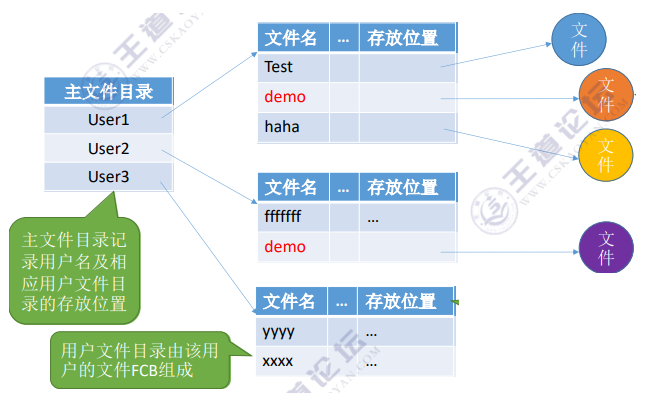
允许不同用户的文件重名。文件名虽然相同,但是对应的其实是不同的文件。
除了允许重名之外,在采用了两级目录结构之后,也能够对不同用户实现访问限制。可以在目录上实现访问限制,检查此时登录的用户名是否匹配。但是两级目录结构依然缺乏灵活性,用户不能对自己的文件进行分类。
(3)多级目录结构
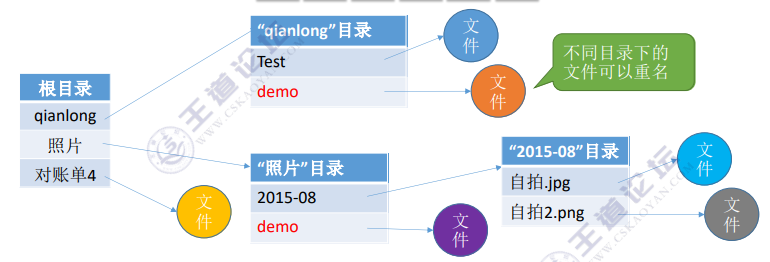
又称树形目录结构。
用户(或用户进程)要访问某个文件时要用文件路径名标识文件,文件路径名是个字符串。各级目录之间用“/”隔开。从根目录出发的路径称为绝对路径。
例如:自拍.jpg的绝对路径是"/照片/2015-08/自拍.jpg"。
系统根据绝对路径一层一层地找到下一级目录。刚开始从外存读入根目录的目录表;找到“照片”目录的存放位置后,从外存读入对应的目录表;再找到“2015-08”目录的存放位置,再从外存读入对应目录表;最后才找到文件“自拍.jpg”的存放位置。整个过程需要3次读磁盘I/O操作。
很多时候,用户会连续访问同一目录内的多个文件(比如:接连查看“2015-08”目录内的多个照片文件),显然,每次都从根目录开始查找,是很低效的。因此可以设置一个“当前目录”。
例如,此时已经打开了“照片”的目录文件,也就是说,这张目录表已调入内存,那么可以把它设置为“当前目录”。当用户想要访问某个文件时,可以使用从当前目录出发的“相对路径”。
在Linux中,“.”表示当前目录,因此如果“照片”是当前目录,则“自拍.jpg”的相对路径为:“./2015-08/自拍.jpg”。从当前路径出发,只需要查询内存中的“照片”目录表,即可知道"2015-08"目录表的存放位置,从外存调入该目录,即可知道"自拍.jpg"存放的位置了。
可见,引入“当前目录”和“相对路径”后,磁盘I/O的次数减少了。这就提升了访问文件的效率。
树形目录结构可以很方便地对文件进行分类,层次结构清晰,也能够更有效地进行文件的管理和保护。但是,树形结构不便于实现文件的共享。为此,提出了“无环图目录结构”。
(4)无环图目录结构
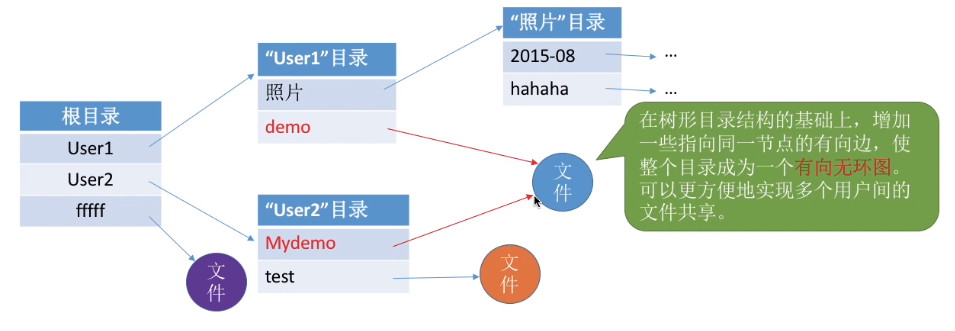
可以用不同的文件名指向同一个文件,甚至可以指向同一个目录(共享同一目录下的所有内容)(目录其实本身也是一种特殊的文件了)。
那么在引用了共享功能之后,对于文件的删除就不能像以前那样了(只要删除一个文件就直接把这个文件的实际数据给删除),因为这个文件有可能是被多个用户使用的。所以,为了解决这一问题,需要为每个共享结点设置一个共享计数器,用于记录此时有多少个地方在共享该结点。用户提出删除结点的请求时,只是删除该用户的FCB、并使共享计数器减1,并不会直接删除共享结点。
只有共享计数器减为0时,才删除结点。
注意:共享文件不同于复制文件。在共享文件中,由于各用户指向的是同一个文件,因此只要其中一个用户修改了文件数据,那么所有用户都可以看到文件数据的变化。
(三)索引结点(FCB的改进)
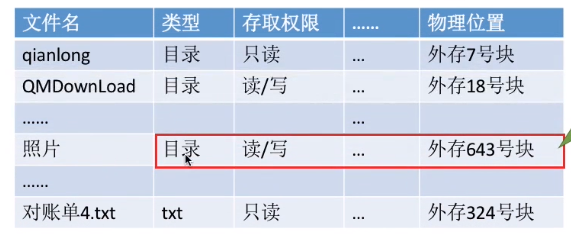
由一系列的FCB组成了文件目录。但是其实操作系统在查找各级目录的过程当中,只需要使用“文件名”这个信息就可以了,而其他的那些冗余的信息暂时不需要,而只有文件名匹配时,才需要去关心文件的其他信息,读出物理位置等。因此可以考虑让目录表简化来提升效率。
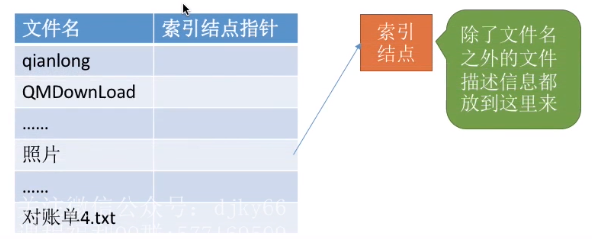
由于在查找各级目录结构的时候不用关心除文件名外其他的信息,那么就可以把这些其他的信息先存放到另外一个地方(文件对应的索引结点当中)。每个文件都有一个唯一的索引结点。
而采用了索引结点机制后,文件目录中只包含文件名、索引结点指针这两个信息。这样一来,目录表占用的空间就会小很多。
思考一下,这种机制到底是怎样提高我们查找一个文件的效率的呢?
假设一个FCB是64B,磁盘块的大小为1KB,则每个盘块中只能存放16个FCB。若一个文件目录中共有640个目录项,则共需要占用640/16=40个盘块。因此按照某文件名检索该目录,平均需要查询320个目录项,从而平均需要启动磁盘20次(每次磁盘I/O读入一块)。
若使用索引结点机制,文件名占14B,索引结点指针占2B,则每个盘块可存放64个目录项,那么按文件名检索目录平均只需要读入320/64=5个磁盘块。显然,这将大大提升文件检索速度。
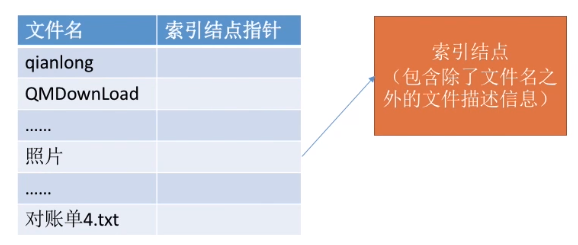
当找到文件名对应的目录项时,才需要将索引结点调入内存,索引结点中记录了文件的各种信息,包括文件在外存中的存放位置,根据“存放位置”即可找到文件。
存放在外存中的索引结点称为“磁盘索引结点”,当索引结点放入内存后称为“内存索引结点”。
相比之下内存索引结点中需要增加一些信息,比如:文件是否被修改、此时有几个进程正在访问该文件等。
小结