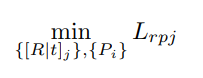文章目录
- 解决的问题
- 实施细节
- 总结

会议/期刊:2023 AAAI
论文题目:《Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning》
论文链接:[JeffWang987/MOVEDepth: AAAI 2023]Crafting Monocular Cues and Velocity Guidance for Self-Supervised Multi-Frame Depth Learning (github.com)
开源代码:AutoAILab/DynamicDepth(github.com)
解决的问题
MOVEDepth不再使用MonoDepth的decoder直接从cost volume中解码出深度,而是follow MVS领域的范式,从cost volume中回归得到深度,MOVEDepth认为显示利用cost volume能够最大程度保留几何信息,得到更准确的深度估计结果。然而如ManyDepth和DepthFormer中提到的,直接从cost volume回归出深度结果并不理想,这是因为在单目多帧深度估计领域,有很多“不确定因素”,例如相机静止(static frame),弱纹理、反光区域,动态场景等。
为了解决这些问题,MOVEDepth利用单帧深度先验以及预测的车身速度等信息,构建了一个轻量的cost volume以解码深度。
实施细节
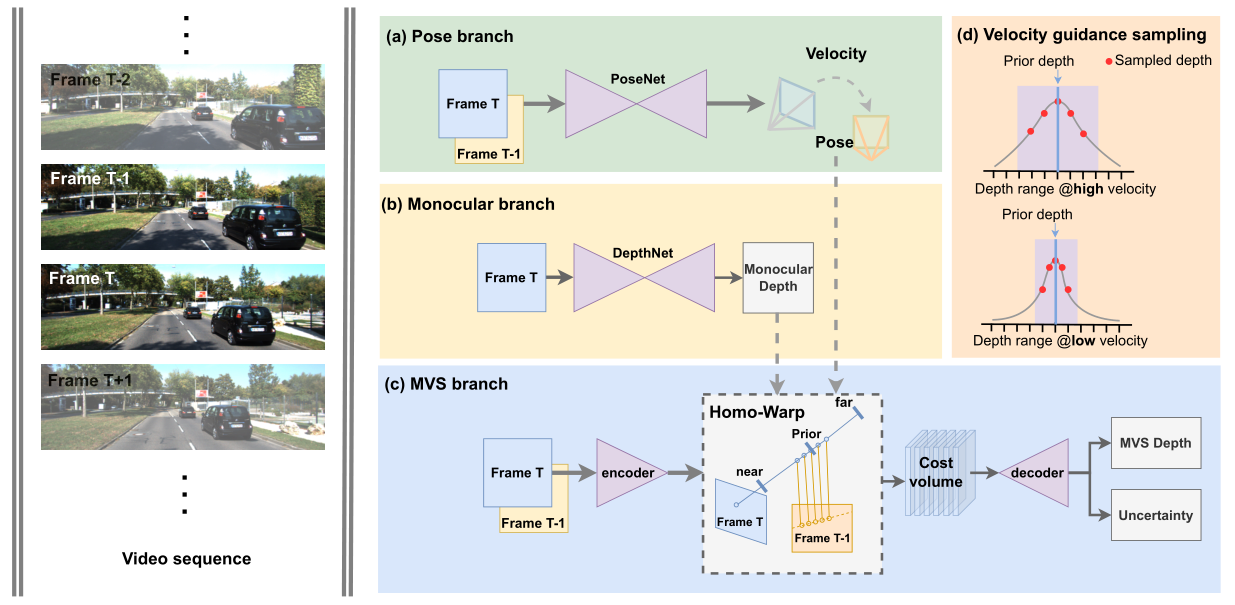
-
Pose branch利用posenet估计相机外参,这部分和之前的工作一致。
-
Monocular branch利用单目深度估计网络预测出“粗糙”的先验深度,其中DepthNet可以是现在的任意一款单目模型,作者在实验部分给出了MonoDepth2和PackNet两种模型。
-
MVS branch遵循了传统的MVSNet范式,唯一不同点在于在Homo-warp阶段,MOVEDepth不在再全局采样深度,而是在单目先验深度(monocular priority)附近进行采样,如下图所示。(注意到ManyDepth和DepthFormer分别使用了96和128个先验深度,而MOVEDepth由于有了先验深度,所以仅采样了16个depth candidates)
-
Velocity guidance sampling,上文提到了MOVEDepth在深度先验附近采样16个深度点,但是并没有约束深度采样的范围。与ManyDepth不同的是,MOVEDepth不再使用学习的方案学习出要采样的范围,而是根据预测的车身速度(posenet估计得到)动态调整深度搜索范围。其Motivation是:如果相机移动速度大,那么前后两帧的stereo baseline就较大,这样比较符合MVS的triangulation prior,可以得到更准确的深度,也就是说MVS会更加的可靠,所以本文增加深度搜索范围。相反,如果相机移动速度较慢,甚至是静止的,那么前后两帧拍摄的场景并没有变化,也没有MVS的几何关联。所以MVS在此时并不可靠,我们要缩小深度搜索范围,让MVS的输出接近单目深度估计的结果,具体的深度搜索范围公式如下(值得一提的是,作者在附录部分给出了具体的几何推导,推导出前后两帧stereo basleine和相机运动速度是线性相关的):
d min = D Mono ( 1 − β T ( v ) ) d max = D Mono ( 1 + β T ( v ) ) \begin{aligned} d_{\min } & =D_{\text {Mono }}(1-\beta \mathcal{T}(v)) \\ d_{\max } & =D_{\text {Mono }}(1+\beta \mathcal{T}(v)) \end{aligned} dmindmax=DMono (1−βT(v))=DMono (1+βT(v))
v = α ∥ T ∥ 2 v=\alpha\|\mathbf{T}\|_{2} v=α∥T∥2,T是由posenet估计的相机平移矩阵,α是相机帧速率, β是超参数,T(·)是将v转换为真实世界中的尺度函数 -
为了解决动态场景等问题,MOVEDepth提出了Uncertainty-Based Depth Fusing,具体来说,从cost volume的熵函数中学习出MVS局部区域的可靠程度,然后作为权重将单帧深度先验和多帧深度进行融合:
U ( p ) = θ u ( ∑ j = 0 D − 1 − p j log p j ) D Fuse = U ⊙ D Mono + ( 1 − U ) ⊙ D M V S \begin{array}{c} \mathbf{U}(\mathbf{p})=\theta_{\mathrm{u}}\left(\sum_{j=0}^{D-1}-\mathbf{p}_{j} \log \mathbf{p}_{j}\right) \\ D_{\text {Fuse }}=\mathbf{U} \odot D_{\text {Mono }}+(\mathbf{1}-\mathbf{U}) \odot D_{\mathrm{MVS}} \end{array} U(p)=θu(∑j=0D−1−pjlogpj)DFuse =U⊙DMono +(1−U)⊙DMVS
从可视化可以看出,深度融合部分的网络从cost volume中学到的不确定区域在动态的车辆、行人上,这有助于缓解动态场景对多帧深度估计带来的问题:
右边的图像是学习到的不确定性地图(白色:确定,黑色:不确定)
总结
MOVEDepth利用单目深度先验和预测的车速信息,动态构建cost volume并按照MVS领域的范式回归出深度,并探究了如何更好的结合单帧深度估计和多帧深度估计得到更精准的预测结果。但MOVEDepth可能存在的问题有:
-
虽然在MVS部分只采用了16个深度假设点,但是依旧需要单目先验网络,这无疑增加了学习负担。
pth可能存在的问题有: -
虽然在MVS部分只采用了16个深度假设点,但是依旧需要单目先验网络,这无疑增加了学习负担。
-
在处理动态部分,依旧是“曲线救国”,从cost volume的熵函数入手,学习动态物体带来的不可信区域,并不是直接处理动态物体,所以性能还有待提升。(值得一提的是,目前的处理动态物体的方法除了类似于这种“曲线救国”的方案,就是利用预训练的分割网络,并不“美观”,效果也不经验,所以如何elegent地处理动态物体将会是一个open problem)