>- **🍨 本文为[🔗365天深度学习训练营]中的学习记录博客**
>- **🍖 原作者:[K同学啊]**
本人往期文章可查阅: 深度学习总结
一、准备工作
🏡 我的环境:
- 语言环境:Python3.11
- 编译器:Jupyter Lab
- 深度学习环境:Pytorch
-
- torch==2.0.0+cu118
-
- torchvision==0.18.1+cu118
- 显卡:NVIDIA GeForce GTX 1660
数据集包含2149名患者的广泛健康信息,每名患者的ID范围从4751到6900不等。该数据集包括人口统计详细信息、生活方式因素、病史、临床测量、认知和功能评估、症状以及阿尔茨海默病的诊断。
数据信息:
- PatientID:分配给每个患者(4751到6900)的唯一标识符。
- Age:患者的年龄从60岁到90岁不等。
- Gender:患者的性别,其中0代表男性,1代表女性。
- Ethnicity:患者的种族,编码如下:
-
- 0:高加索人
- 1:非裔美国人
- 2:亚洲
- 4:其他
- EducationLevel:患者的教育水平,编码如下:
-
- 0:无
- 1:高中
- 2:学士学位
- 3:更高
- BMI:患者的体重指数,范围从15到40
- Smoking:吸烟状态,其中0表示否,1表示是
- AlcoholConsumption(酒精消费量):每周酒精消费量(以0到20为单位),范围从0到20。
- PhysicalActivity:每周身体活动(以小时为单位),范围从0到10。
- DietQuality:饮食质量评分,范围从0到10。
- SleepQuality:睡眠质量分数,范围从4到10。
- FamilyHistoryAlzheimers:阿尔茨海默病家族史,其中0表示否,1表示是。
- CardiovascularDisease:存在心血管疾病,其中0表示否,1表示是。
- Diabetes:存在糖尿病,其中0表示否,1表示是。
- Depression:存在抑郁,其中0表示否,1表示是。
- HeadInjury:头部受伤史,其中0表示否,1表示是。
- Hypertension:存在高血压,其中0表示否,1表示是。
- SystolicBP:收缩压,范围为90至180mmHg。
- DiastolicBP:舒张压,范围60至120mmHg。
- CholesterolTotal:总胆固醇水平,范围为150至300mg/dL。
- CholesterolLDL:低密度脂蛋白胆固醇水平,范围为50至200mg/dL。
- CholesterolHDL:高密度脂蛋白胆固醇水平,范围为20至100mg/dL。
- CholesterolTriglycerides:甘油三酯水平,范围为50至400mg/dL。
- ……
- Diagnosis:阿尔茨海默病的诊断状态,其中0表示否,1表示是。
1.前期准备工作
1.1.设置硬件设备
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns
# 设置GPU训练,也可以使用CPU
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
device输出:
device(type='cuda')1.2.导入数据
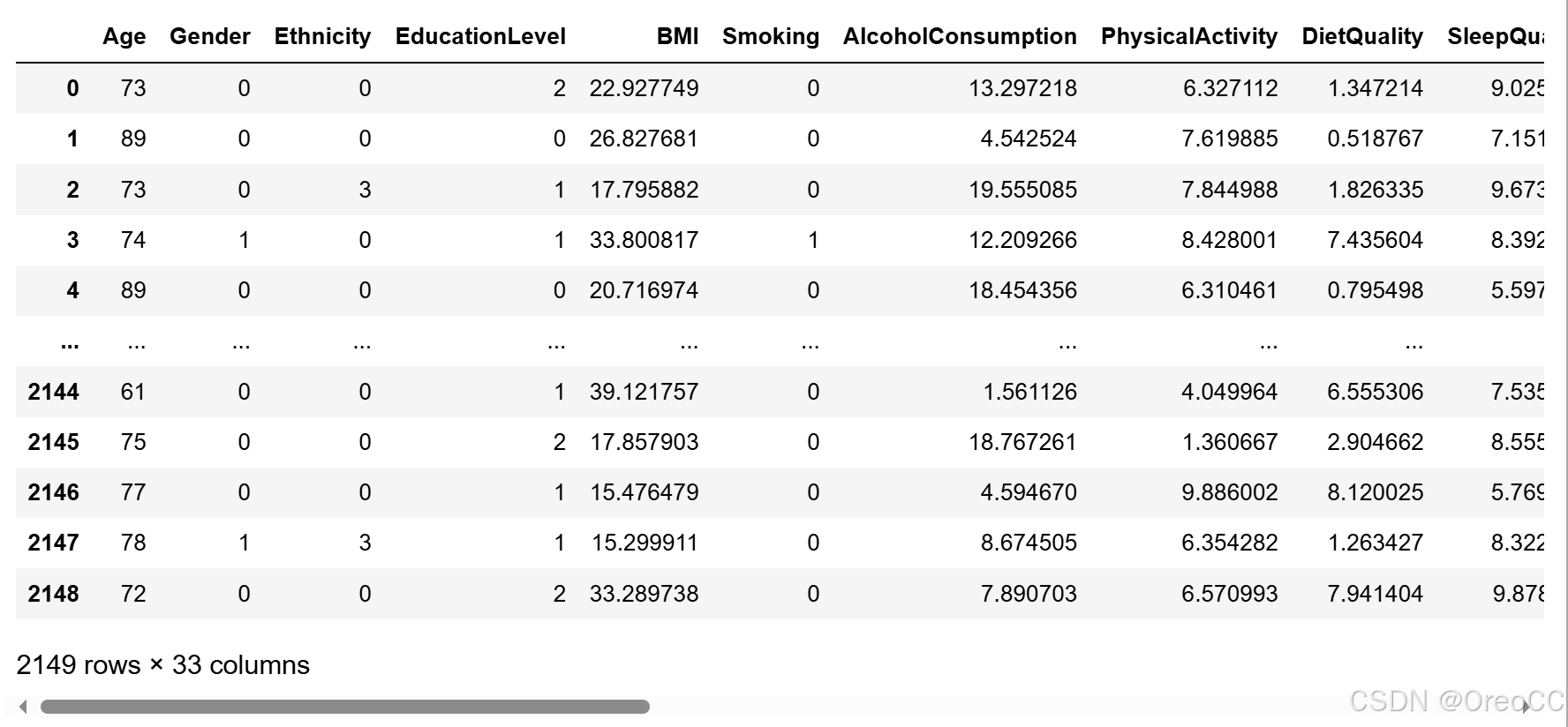
df=pd.read_csv(r"E:/DATABASE/RNN/R8/alzheimers_disease_data.csv")
# 删除第一列和最后一列
df=df.iloc[:,1:-1]
df输出:
2.构建数据集
2.1.标准化
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
x=df.iloc[:,:-1]
y=df.iloc[:,-1]
# 将每一列特征标准化为标准正态分布,注意,标准化是针对每一列而言的
sc=StandardScaler()
x=sc.fit_transform(x)2.2.划分数据集
x=torch.tensor(np.array(x),dtype=torch.float32)
y=torch.tensor(np.array(y),dtype=torch.int64)
x_train,x_test,y_train,y_test=train_test_split(
x,y,
test_size=0.1,
random_state=1
)
x_train.shape,y_train.shape输出:
(torch.Size([1934, 32]), torch.Size([1934]))2.3.构建数据加载器
from torch.utils.data import TensorDataset,DataLoader
train_dl=DataLoader(TensorDataset(x_train,y_train),
batch_size=64,
shuffle=False)
test_dl=DataLoader(TensorDataset(x_test,y_test),
batch_size=64,
shuffle=False)3.模型训练
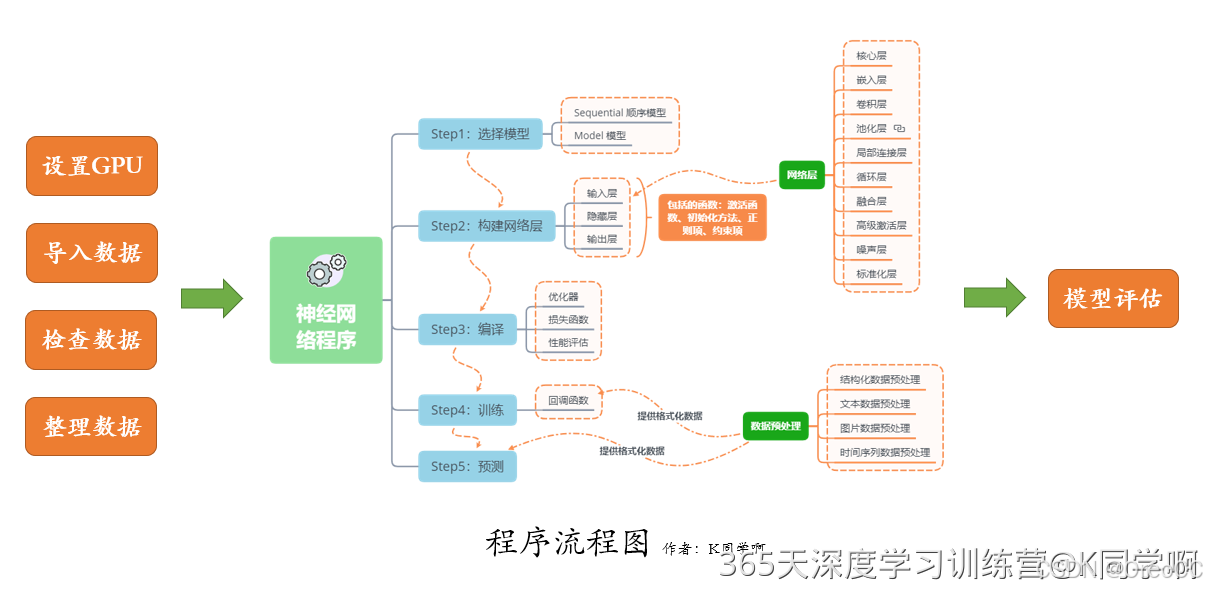
3.1.构建模型
class model_rnn(nn.Module):
def __init__(self):
super(model_rnn,self).__init__()
self.rnn0=nn.RNN(input_size=32,hidden_size=200,
num_layers=1,batch_first=True)
self.fc0=nn.Linear(200,50)
self.fc1=nn.Linear(50,2)
def forward(self,x):
out,hidden1=self.rnn0(x)
out=self.fc0(out)
out=self.fc1(out)
return out
model=model_rnn().to(device)
model输出:
model_rnn(
(rnn0): RNN(32, 200, batch_first=True)
(fc0): Linear(in_features=200, out_features=50, bias=True)
(fc1): Linear(in_features=50, out_features=2, bias=True)
)查看模型的输出数据集格式:
model(torch.rand(30,32).to(device)).shape输出:
torch.Size([30, 2])3.2.定义训练函数
# 训练循环
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset) # 训练集的大小
num_batches=len(dataloader) # 批次数目,(size/batch_size,向上取整)
train_loss,train_acc=0,0 # 初始化训练损失和正确率
for x,y in dataloader: # 获取图片及其标签
x,y=x.to(device),y.to(device)
# 计算预测误差
pred=model(x) # 网络输出
loss=loss_fn(pred,y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
#反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc+=(pred.argmax(1)==y).type(torch.float).sum().item()
train_loss+=loss.item()
train_acc/=size
train_loss/=num_batches
return train_acc,train_loss3.3.定义测试函数
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset) # 测试集的大小
num_batches=len(dataloader) # 批次数目,(size/batch_size,向上取整)
test_loss,test_acc=0,0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs,target in dataloader:
imgs,target=imgs.to(device),target.to(device)
# 计算loss
target_pred=model(imgs)
loss=loss_fn(target_pred,target)
test_loss+=loss.item()
test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()
test_acc/=size
test_loss/=num_batches
return test_acc,test_loss3.4.正式训练模型
loss_fn=nn.CrossEntropyLoss() # 创建损失函数
learn_rate=5e-5 # 学习率
opt=torch.optim.Adam(model.parameters(),lr=learn_rate)
epochs=50
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,opt)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr=opt.state_dict()['param_groups'][0]['lr']
template=('Epoch:{:2d},Train_acc:{:.1f}%,Train_loss:{:.3f},Test_acc:{:.1f}%,Test_loss:{:.3f},Lr:{:.2E}')
print(template.format(epoch+1,epoch_train_acc*100,epoch_train_loss,
epoch_test_acc*100,epoch_test_loss,lr))
print("="*20,'Done',"="*20)输出:
Epoch: 1,Train_acc:47.6%,Train_loss:0.700,Test_acc:54.0%,Test_loss:0.687,Lr:5.00E-05
Epoch: 2,Train_acc:65.0%,Train_loss:0.671,Test_acc:65.1%,Test_loss:0.659,Lr:5.00E-05
Epoch: 3,Train_acc:72.0%,Train_loss:0.642,Test_acc:69.8%,Test_loss:0.629,Lr:5.00E-05
Epoch: 4,Train_acc:70.0%,Train_loss:0.611,Test_acc:67.4%,Test_loss:0.600,Lr:5.00E-05
Epoch: 5,Train_acc:67.4%,Train_loss:0.585,Test_acc:66.5%,Test_loss:0.582,Lr:5.00E-05
Epoch: 6,Train_acc:68.3%,Train_loss:0.567,Test_acc:67.0%,Test_loss:0.568,Lr:5.00E-05
Epoch: 7,Train_acc:71.0%,Train_loss:0.548,Test_acc:69.8%,Test_loss:0.553,Lr:5.00E-05
Epoch: 8,Train_acc:73.7%,Train_loss:0.529,Test_acc:70.7%,Test_loss:0.538,Lr:5.00E-05
Epoch: 9,Train_acc:76.3%,Train_loss:0.509,Test_acc:72.1%,Test_loss:0.522,Lr:5.00E-05
Epoch:10,Train_acc:78.0%,Train_loss:0.489,Test_acc:75.8%,Test_loss:0.507,Lr:5.00E-05
Epoch:11,Train_acc:79.8%,Train_loss:0.470,Test_acc:76.7%,Test_loss:0.492,Lr:5.00E-05
Epoch:12,Train_acc:80.9%,Train_loss:0.452,Test_acc:78.1%,Test_loss:0.478,Lr:5.00E-05
Epoch:13,Train_acc:82.1%,Train_loss:0.435,Test_acc:78.1%,Test_loss:0.465,Lr:5.00E-05
Epoch:14,Train_acc:83.0%,Train_loss:0.419,Test_acc:79.1%,Test_loss:0.453,Lr:5.00E-05
Epoch:15,Train_acc:84.0%,Train_loss:0.405,Test_acc:79.1%,Test_loss:0.443,Lr:5.00E-05
Epoch:16,Train_acc:84.5%,Train_loss:0.393,Test_acc:79.5%,Test_loss:0.434,Lr:5.00E-05
Epoch:17,Train_acc:84.9%,Train_loss:0.382,Test_acc:79.5%,Test_loss:0.426,Lr:5.00E-05
Epoch:18,Train_acc:85.2%,Train_loss:0.372,Test_acc:79.5%,Test_loss:0.420,Lr:5.00E-05
Epoch:19,Train_acc:85.4%,Train_loss:0.364,Test_acc:79.5%,Test_loss:0.415,Lr:5.00E-05
Epoch:20,Train_acc:85.6%,Train_loss:0.357,Test_acc:79.1%,Test_loss:0.411,Lr:5.00E-05
Epoch:21,Train_acc:85.9%,Train_loss:0.351,Test_acc:79.1%,Test_loss:0.407,Lr:5.00E-05
Epoch:22,Train_acc:86.2%,Train_loss:0.345,Test_acc:77.7%,Test_loss:0.405,Lr:5.00E-05
Epoch:23,Train_acc:86.4%,Train_loss:0.340,Test_acc:78.6%,Test_loss:0.403,Lr:5.00E-05
Epoch:24,Train_acc:86.3%,Train_loss:0.336,Test_acc:78.6%,Test_loss:0.402,Lr:5.00E-05
Epoch:25,Train_acc:86.6%,Train_loss:0.332,Test_acc:78.6%,Test_loss:0.402,Lr:5.00E-05
Epoch:26,Train_acc:86.7%,Train_loss:0.329,Test_acc:78.1%,Test_loss:0.402,Lr:5.00E-05
Epoch:27,Train_acc:86.8%,Train_loss:0.326,Test_acc:78.6%,Test_loss:0.402,Lr:5.00E-05
Epoch:28,Train_acc:87.0%,Train_loss:0.323,Test_acc:77.7%,Test_loss:0.403,Lr:5.00E-05
Epoch:29,Train_acc:87.3%,Train_loss:0.320,Test_acc:77.7%,Test_loss:0.404,Lr:5.00E-05
Epoch:30,Train_acc:87.7%,Train_loss:0.318,Test_acc:77.2%,Test_loss:0.405,Lr:5.00E-05
Epoch:31,Train_acc:87.9%,Train_loss:0.315,Test_acc:77.2%,Test_loss:0.406,Lr:5.00E-05
Epoch:32,Train_acc:87.9%,Train_loss:0.313,Test_acc:77.2%,Test_loss:0.407,Lr:5.00E-05
Epoch:33,Train_acc:87.8%,Train_loss:0.311,Test_acc:77.7%,Test_loss:0.409,Lr:5.00E-05
Epoch:34,Train_acc:88.0%,Train_loss:0.309,Test_acc:78.1%,Test_loss:0.410,Lr:5.00E-05
Epoch:35,Train_acc:88.0%,Train_loss:0.307,Test_acc:78.1%,Test_loss:0.412,Lr:5.00E-05
Epoch:36,Train_acc:88.1%,Train_loss:0.306,Test_acc:78.1%,Test_loss:0.414,Lr:5.00E-05
Epoch:37,Train_acc:88.2%,Train_loss:0.304,Test_acc:78.6%,Test_loss:0.416,Lr:5.00E-05
Epoch:38,Train_acc:88.4%,Train_loss:0.302,Test_acc:78.6%,Test_loss:0.418,Lr:5.00E-05
Epoch:39,Train_acc:88.4%,Train_loss:0.301,Test_acc:78.6%,Test_loss:0.420,Lr:5.00E-05
Epoch:40,Train_acc:88.5%,Train_loss:0.299,Test_acc:79.1%,Test_loss:0.422,Lr:5.00E-05
Epoch:41,Train_acc:88.6%,Train_loss:0.297,Test_acc:78.6%,Test_loss:0.424,Lr:5.00E-05
Epoch:42,Train_acc:88.7%,Train_loss:0.296,Test_acc:78.6%,Test_loss:0.427,Lr:5.00E-05
Epoch:43,Train_acc:88.6%,Train_loss:0.294,Test_acc:78.1%,Test_loss:0.429,Lr:5.00E-05
Epoch:44,Train_acc:88.6%,Train_loss:0.292,Test_acc:78.1%,Test_loss:0.431,Lr:5.00E-05
Epoch:45,Train_acc:88.7%,Train_loss:0.291,Test_acc:78.1%,Test_loss:0.434,Lr:5.00E-05
Epoch:46,Train_acc:88.7%,Train_loss:0.289,Test_acc:78.1%,Test_loss:0.437,Lr:5.00E-05
Epoch:47,Train_acc:88.8%,Train_loss:0.287,Test_acc:78.6%,Test_loss:0.440,Lr:5.00E-05
Epoch:48,Train_acc:88.8%,Train_loss:0.286,Test_acc:78.6%,Test_loss:0.443,Lr:5.00E-05
Epoch:49,Train_acc:88.8%,Train_loss:0.284,Test_acc:78.6%,Test_loss:0.446,Lr:5.00E-05
Epoch:50,Train_acc:88.8%,Train_loss:0.283,Test_acc:79.1%,Test_loss:0.449,Lr:5.00E-05
==================== Done ====================4.模型评估
4.1.Loss与Accuracy图
import matplotlib.pyplot as plt
# 隐藏警告
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示符号
plt.rcParams['figure.dpi']=300 # 分辨率
epochs_range=range(epochs)
plt.figure(figsize=(12,3))
plt.subplot(1,2,1)
plt.plot(epochs_range,train_acc,label='Training Accuracy')
plt.plot(epochs_range,test_acc,label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,train_loss,label='Training Loss')
plt.plot(epochs_range,test_loss,label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()输出:
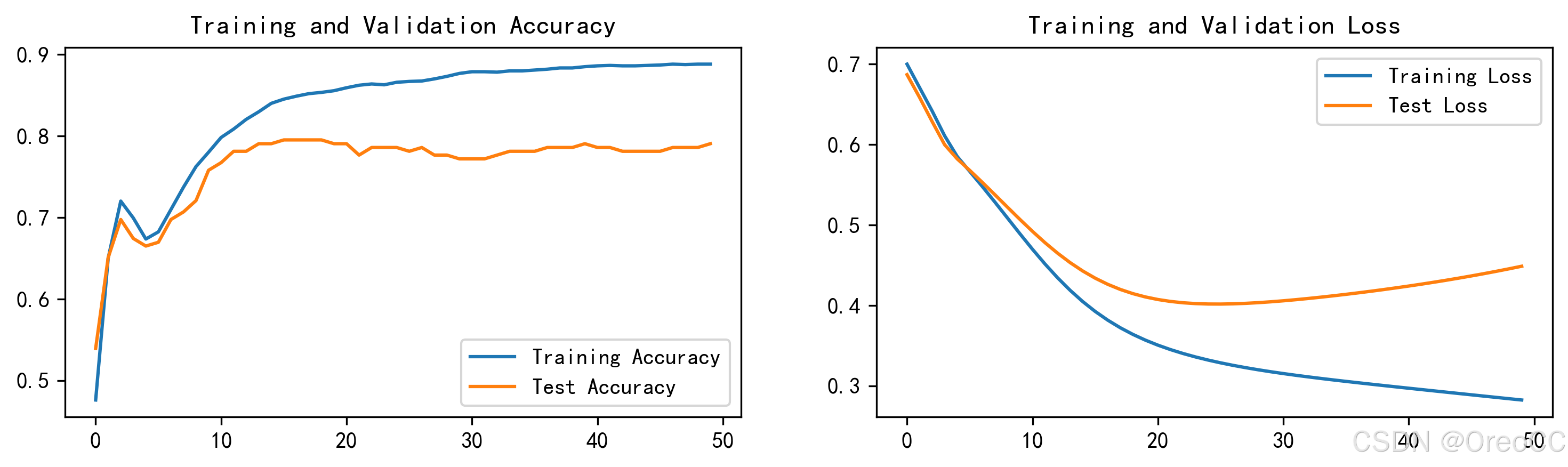
4.2.混淆矩阵
print("=============输入数据Shape为===============")
print("x_test.shape:",x_test.shape)
print("y_test.shape:",y_test.shape)
pred=model(x_test.to(device)).argmax(1).cpu().numpy()
print("=============输出数据Shape为===============")
print("pred.shape:",pred.shape)输出:
=============输入数据Shape为===============
x_test.shape: torch.Size([215, 32])
y_test.shape: torch.Size([215])
=============输出数据Shape为===============
pred.shape: (215,)import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,ConfusionMatrixDisplay
# 计算混淆矩阵
cm=confusion_matrix(y_test,pred)
plt.figure(figsize=(6,5))
plt.suptitle('')
sns.heatmap(cm,annot=True,fmt="d",cmap="Blues")
# 修改字体大小
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title("Confusion Matrix",fontsize=12)
plt.xlabel("Predicted Label",fontsize=10)
plt.ylabel("True Label",fontsize=10)
# 显示图
plt.tight_layout() # 调整布局防止重叠
plt.show()输出:
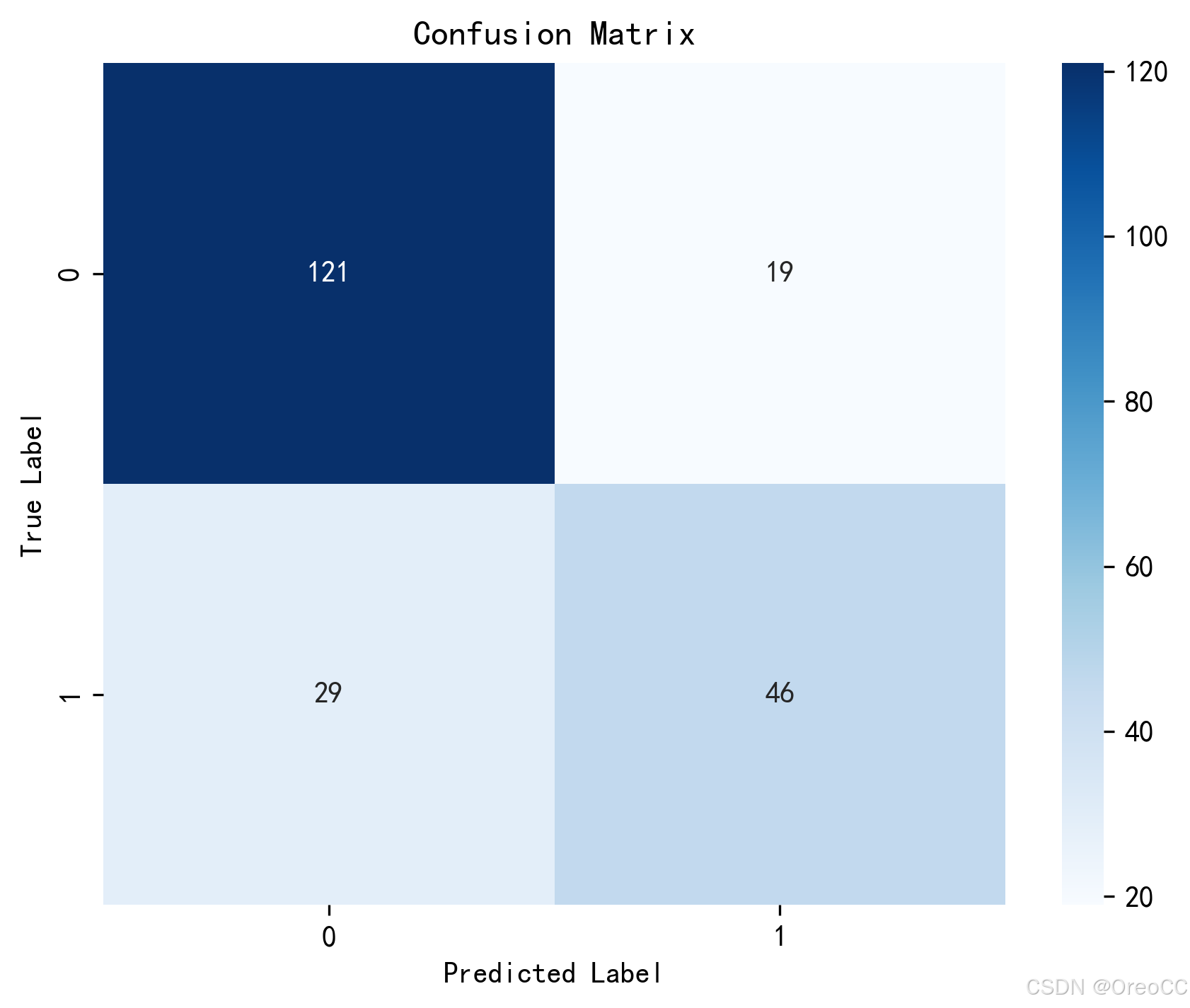
4.3.调用模型进行预测
test_x=x_test[0].reshape(1,-1) # x_test[0]即我们的输入数据
pred=model(test_x.to(device)).argmax(1).item()
print("模型预测结果为:",pred)
print("=="*20)
print("0:未患病")
print("1:已患病")输出:
模型预测结果为: 0
========================================
0:未患病
1:已患病