笔记整理:沈小力,东南大学硕士,研究方向为知识图谱
链接:https://dl.acm.org/doi/pdf/10.1145/3511808.3557275
动机
情感分析是自然语言处理的基础任务,它包含介绍了细粒度情感分析中的一个常见任务——基于方面的情感分析(ABSA,Aspect-Based Sentiment Analysis)。在ABSA任务中,输入模型的是一个标记序列,每个标记代表一个词或短语,任务是在这些标记中准确地识别出表示方面和情感的词或短语。标记有五种类型:表示方面的开始和内部标记(B-A和I-A)、表示情感的开始和内部标记(B-O和I-O)以及不属于方面或情感的标记(N)。当前已有的ABSA研究主要关注单领域情况下的方面提取,即训练和测试数据来自同一分布。然而,当训练(源)领域与测试(目标)领域不同时,传统方法的性能通常较差,因为不同领域之间使用的方面差异很大,重叠部分较少。针对这些挑战,该论文提出了一种新方法,使用领域特定的知识图谱增强预训练的Transformer模型,以提高跨领域方面抽取的性能。为了构建领域特定的知识图谱,该方法使用了一个大规模的通识知识图谱(ConceptNet)和一个fine-tuned的生成式知识源(COMET),并结合了句法信息来决定何时注入外部知识。
亮点
本文的主要亮点有:
(1)引入了一种从未标注的文本构建特定领域知识图谱的方法,该方法使用了一个现有的常识知识图谱(ConceptNet)和一个专门针对预测领域内关系的Transformer模型(COMET)。
(2)提出了一种基于句法信息的方法,用于确定何时将外部知识注入到Transformer模型中进行方面提取,并探索了两种将知识注入到语言模型中的替代方法:插入查询丰富的中间标记和通过分离的注意力机制实现。
(3)在跨领域方面提取任务上,该方法取得了最先进的性能,并在三个不同领域(餐厅,笔记本电脑和数字设备)的消费者评论基准数据集上进行了验证。
(4)为未来的情感分析研究贡献了一个改进的数字设备基准数据集。
方法
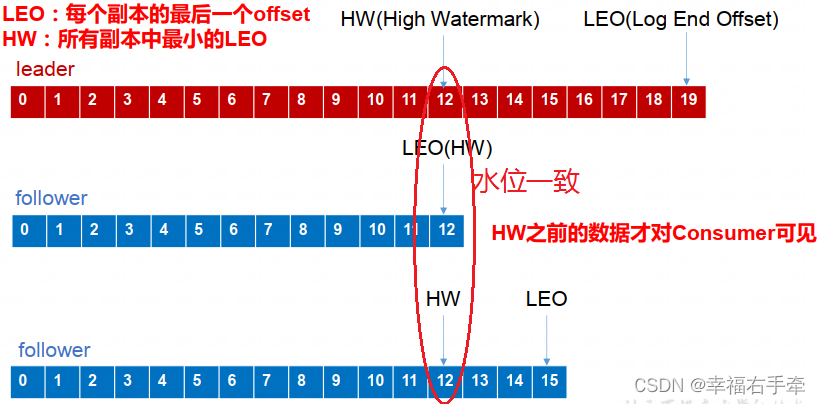
总体框架如图1所示,方法包括三个步骤:(1)为每个目标领域准备一个领域特定的知识图谱,即知识图谱准备部分(2)确定模型何时可以从外部信息中受益,即知识注入时机部分(3)在适用时注入从知识图谱中检索到的知识,即知识注入机制部分。该方法探索了最终知识注入步骤的两种替代方法:将一个中心词条插入原始查询和通过分离的注意力机制将知识注入到隐藏状态表示中。
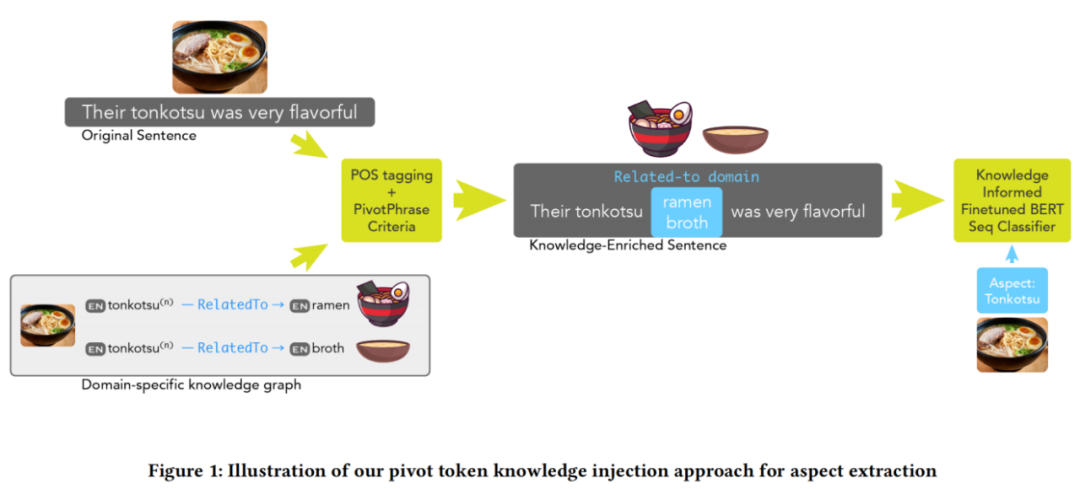
图1 总体框架图
1)知识图谱准备部分
a.子图查询
知识子图构建的第一步是基于特定域的种子术语列表,通过对 ConceptNet 的查询构建一个原始的知识子图。
具体来说,对于每一个目标域d,通过将TF-IDF应用于域d中所有的未标记文本并取得分最高的前k个名词短语,即可得到种子术语列表 。然后,对 中的每一个种子术语s,查询在ConceptNet中通过边连接到s的所有节点,并将它们与种子术语s一起添加到特定域的子图中。最后,通过迭代查询这些附加节点进一步扩展子图,直到子图中边缘节点与种子术语的最大距离达到h。
b.子图剪枝
为了增加查询子图与目标域的相关性,需要对与种子术语h的相关性得分较低的生成节点进行剪枝。
作者首先将这个通过 ConceptNet 构建的子图结构与Word2vec 等词嵌入技术相结合,进而将相关性得分定义为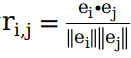 ,其中 是对于子图中给定节点i的嵌入向量。基于 作者将子图中给定路径 的最小路径相关分数 定义为
,其中 是对于子图中给定节点i的嵌入向量。基于 作者将子图中给定路径 的最小路径相关分数 定义为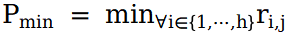 ,而满足 的路径上的所有节点都会被剪枝,这本质上是以牺牲覆盖率为代价减少子图中的不相关节点。
,而满足 的路径上的所有节点都会被剪枝,这本质上是以牺牲覆盖率为代价减少子图中的不相关节点。
c.子图扩充
对子图进行剪枝可能会影响其覆盖率,为此作者通过生成式的常识模型 COMET 来对子图进行扩充。对于给定的头部h和关系r,COMET 可以对尾部t进行预测进而实现对三元组(h,r,t)的补全。为了提高 COMET 的跨域能力,对于每一个目标域d,作者通过 spaCy 识别出文本中出现的所有名词和名词短语,然后在 ConceptNet 中查询包含这些名词之一的三元组,进而基于这些三元组对 COMET 进行微调。
2)知识注入部分
为了确定何时注入知识,需要使用 spaCy 提取词性和依赖关系,进而识别潜在的方面 token。因为方面一般是名词或名词短语,作者通过识别输入序列中的名词格式筛选出候选的 token 集合。然后,将此 token 集与特定域的 KG 进行比较,以确定应将哪些标记为与该领域相关联。最终,可以得到一个经过筛选的候选 token 集,它们将在下一步中被使用。
3)知识注入机制
作者提到了两种将知识注入到 Transformer 中的方法。第一种是通过在被识别为潜在方面的 token 后面插入一个 pivot token 来丰富查询。第二种是利用分离的注意力的分解来调节每个 token 在枢轴信息上的分布。
a.通过 pivot token 进行知识注入
pivot token 包括 [DOMAIN-B] 和 [DOMAIN-I],是一种特殊的 token,作者将 pivot token 插入在指定的 token 后面,用于向模型指示它前面的 token 更有可能被标记为方面。例如 “It was the best pad [DOMAIN-B] thai [DOMAIN-I] I’ve ever had.”。在这一步作者通过对 Transformer 进行训练以避免插入过程的不确定性以及源域和目标域之间的依赖性。
b.通过分离的注意力机制进行知识注入
通过注意力机制来进行知识注入可以避免插入导致的句子序列变化,同时粒度更细。
实验
作者采用了 restaurant(Pontiki et al., 2015)、laptop(Pontiki et al., 2014)和 digital devices(Wang et al., 2016)三个数据集作为实验数据集。
作者将跨域设置表示为 ,其中每一个元组的第一个元素是源域,第二个是目标域,模型会在源域中进行训练和微调并在目标域中进行实验。实验结果如下所示,其中-PT表示使用 pivot token 进行知识注入,-MA表示通过修改后的注意方案进行知识注入。
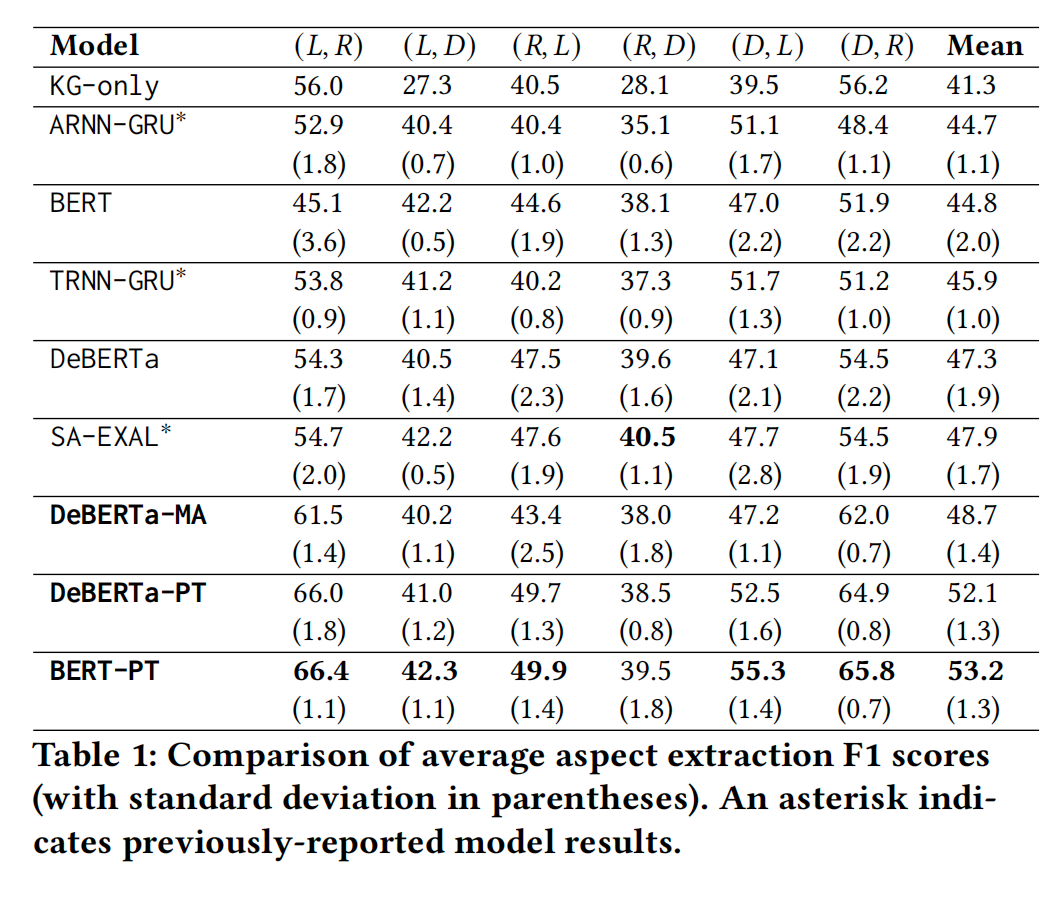
表1 基于方面的情感分析结果
可以发现,基于 pivot token 的方法效果更好,作者认为这是由于分离的注意力机制提高了模型的复杂性,而用来识别候选方面的二元指标所提供的信息不足以抵消这样的复杂性开销。此外,尽管 DeBERTa 模型的效果优于 BERT,但实际上 BERT 对于 pivot token 的适应性更好,作者认为这是因为标记的插入会破坏 DeBERTa 中的相对位置信息,而 BERT 的绝对位置受此影响较小。
相比较之下,模型在餐厅数据集作为目标域时效果最好,这主要是因为 ConceptNet 中有关餐饮的信息最多,能够将相关方面更好地覆盖。
总结
本文提出了一种综合方法,用于构建领域特定的知识图谱(KG),并确定在何时将知识注入到Transformer中进行方面提取更加有用。此外,作者们还介绍了两种注入知识的替代方法:通过查询扩展和使用解耦的注意力机制。他们的实验结果表明,注入知识的变压器在跨领域方面提取任务上优于现有的最先进模型。最后,作者们发布了改进版的基准数字设备评论数据集,以支持未来在方面为基础的情感分析方面的研究。
虽然该研究的重点是识别ABSA方面,但是他们构建的领域特定KG和知识注入方法可以应用于其他需要外部知识的NLP任务。在未来的研究中,他们打算探索将其方法扩展到这些应用程序,并研究注入知识到语言模型的替代方法。
此外,该研究的代码已开源至https://github.com/intellabs/nlp-architect。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。