7.1 在 Broker 端进行消息过滤
在 Broker 端进行消息过滤,可以减少无效消息发送到 Consumer ,少占用网络带宽从而提高吞吐量。 Broker 端有三种方式进行消息过滤 。
7.1.1 消息的 Tag 和 Key
对一个应用来说,尽可能只用一个 Topic ,不同的消息子类型用 Tag 来标识(每条消息只能有一个 Tag ),服务器端基于 Tag 进行过滤,并不需要读取消息体的内容,所以效率很高。 发送消息设置了 Tag 以后,消费方在订阅消息时,才可以利用 Tag 在 Broker 端做消息过滤。
其次是消息的 Key 。 对发送的消息设置好 Key ,以后可以根据这个 Key 来查找消息 。 所以这个 Key 一般用消息在业务层面的唯一标识码来表示,这样后续查询消息异常,消息丢失等都很方便。 Broker 会创建专门的索引文件,来存储 Key 到消息的映射,由于是哈希索引,应尽量使 Key 唯一 ,避免潜在的哈希冲突 。
Tag 和 Key 的主要差别是使用场景不同, Tag 用在 Consumer 的代码中,用来进行服务端消息过滤, Key 主要用于通过命令行查询消息 。
7.1.2 通过 Tag 进行过滤
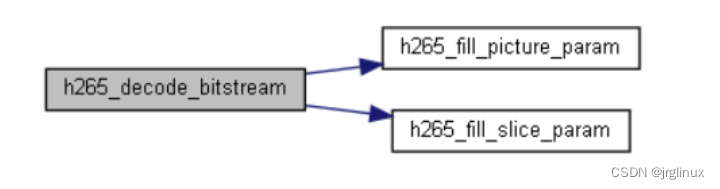
用 Tag 方式进行过滤的方法是传人感兴趣的 Tag 标签, Tag 标签是一个普通字符串,是在创建 Message 的时候添加的, 一个 Message 只能有一个 Tag 。使用 Tag 方式过滤非常高效,Broker 端可以在 ConsumeQueue 中做这种过滤 ,只从 CommitLog 里读取过滤后被命中的消息。 看一下 ConsumerQueue 的存储格式。
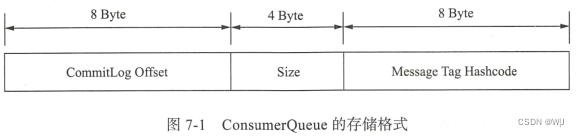
Consume Queue 的第 三部分存储的是 Tag 对应的 hash code ,是一个定长的字符串,通过 Tag 过滤的过程就是对比定长的 hash code 。 经过 hash code 对比 ,符合要求的消息被从 CommitLog 读取出来,不用担心 Hash 冲突问题,消息在被消费前会对比完整的 Message Tag 字符串,消除 Hash 冲突造成的误读。
7.1.3 用 SQL 表达式的方式进行过滤
使用 Tag 方式过滤虽然高效,但是支持的逻辑比较简单,在构造 Message的时候,还可以通过 putU serProperty 函数来增加多个自定义的属性,基于这些属性可以做复杂的过滤逻辑。
类似 SQL 的过滤表达式, 支持如下语法 :
- 数字对比 , 比如 >、>=、<、<= 、 BETWEEN 、 =;
- 字符串对比,比如=、<>、 IN;
- IS NULL or IS NOT NULL;
- 逻辑符号 AND 、 OR 、 NOT。
支持的数据类型:
- 数字型,比如 123 、 3.1415;
- 字符型 ,比如 'abc' 、注意必须用单引 号 ;
- NULL ,这个特殊字符;
- 布尔型, TRUE or FALSE 。
SQL 表达式方式的过滤需 要 Broker 先读出消息里的属性内容, 然 后做SQL 计算,增大磁盘压力,没有 Tag 方式高效。
7.1.4 Filter Server 方式过滤
Filter Server 是 一 种比 SQL 表 达式更灵活的过滤方式,允许用户自定义Java 函数,根据 Java 函数的逻辑对消息进行过滤 。
要使用 Filter Server , 首先要在启动 Broker 前在配置文件里加上 filterServerNums = 3 这样的配置 , Broker 在 启动的时候 , 就会在本机启动 3 个 FilterServer 进程。 FilterServer 类 似 一 个 RocketMQ 的 Consumer 进程,它从本机Broker 获取消息,然后根据用户上传过来的 Java 函数进行过滤,过滤后的消息再传给远端的 Consumer 。 这种方式会占用很多 Broker 机器的 CPU 资源,要根据实际情况谨慎使用 。 上传的 java 代码也要经过检查 ,不能有申请大内存、创建线程等这样的操作,否则容易造成 Broker 服务器宕机 。
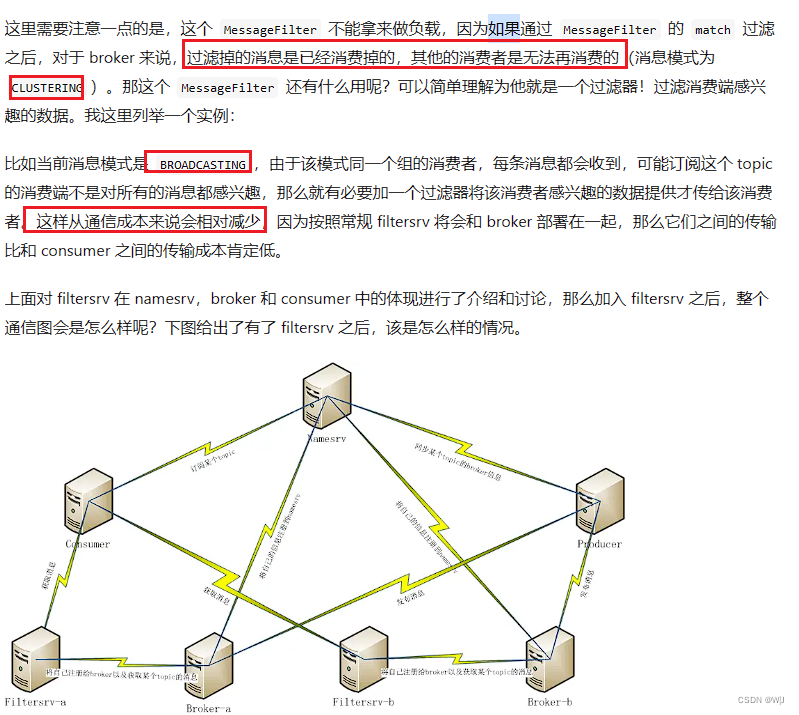
RocketMQ Filtersrv详解![]() https://my.oschina.net/bieber/blog/492988
https://my.oschina.net/bieber/blog/492988
7.2 提高 Consumer 处理能力
当 C onsumer 的处理速度眼不上消息的产生速度,会造成越来越多的消息积压,这个时候首先查看消费逻辑本身有
( 1 )提高消费并行度
在同一个 ConsumerGroup 下( Clustering 方式),可以通过增加 Consumer实例的数量来提高并行度,通过加机器,或者在已有机器中启动多个 Consumer进程都可以增加 Consumer 实例数。注意总的 Consumer 数量不要超过 Topic 下Read Queue 数量,超过的 Consumer 实例接收不到消息 。 此外,通过提高单个Consumer 实例中的并行处理的线程数 可以在同一个 Consumer 内增加并行度来提高吞吐量(设置方法是修改 consumeThreadMin 和 consumeThreadMax ) 。
( 2 )以批量方式进行消费
某些业务场景下,多条消息同时处理的时间会大大小于逐个处理的时间总和,比如消费消息中涉及 update 某个数据库, 一次 update IO 条的时间会大大小于十次 update 1 条数据的时间 。 这时可以通过批量方式消费来提高消费的吞吐量 。 实现方法是设置 Consumer 的 consume-MessageBatchMaxSize 这个参数 ,默认是 1 ,如果设置为 N,在消息多 的时候每次收到的是个长度为 N 的消息链表。
org.apache.rocketmq.client.impl.consumer.ConsumeMessageConcurrentlyService#submitConsumeRequest
Rocketmq源码分析: Rocketmq push 模式下 consumeMessageBatchMaxSize 和 pullBatchSize 两个参数的意义![]() https://blog.csdn.net/cliuyang/article/details/109221653( 3 )检测延时情况,跳过非重要消息
https://blog.csdn.net/cliuyang/article/details/109221653( 3 )检测延时情况,跳过非重要消息
Consumer 在消 费的过程中, 如果发现由于某种原因发生严重的消息堆积,短 时间无法消除堆积,这个时候可以选择丢弃不重要 的消息,使 Consumer 尽快追上 Producer 的进度没有优化空间,除此之外还有三种方法可 以提高 Consumer 的处理能力 。

当某个队列的消息数堆积到 90000 条以上,就直接丢弃,以便快速追上发送消息的进度。
7 .3 Consumer 的负载均衡
上一节中讲到,想要提高 Consumer 的处理速度,可以启动多个 Consumer并发处理,这个时候就涉及如何在多个 Consumer 之间负载均衡的问题,接下来结合源码分析 Consumer 的负载均衡实现。
要做负载均衡,必须知道一些全局信息,也就是一个 ConsumerGroup 里到底有多少个 Consumer , 知道了全局信息,才可以根据某种算法来分配,比如简单地平均分到各个 Consumer 。 在 RocketMQ 中,负载均衡或者消息分配是在Consumer 端代码中完成的, Consumer 从 Broker 处获得全局信息,然后自己做负载均衡,只处理分给自己的那部分消息 。
7.3.1 DefaultMQPushConsumer 的负载均衡
DefaultMQPushConsumer 的负载均衡过程不需要使用者操心,客户端程序会自动处理,每个 DefultMQPushConsumer 启动后,会马上会触发一个doRebalance 动作;而且在同一个 ConsumerGroup 里加入新的 DefaultMQPushConsumer 时,各个 Consumer 都会被触发 do Rebalance 动作。
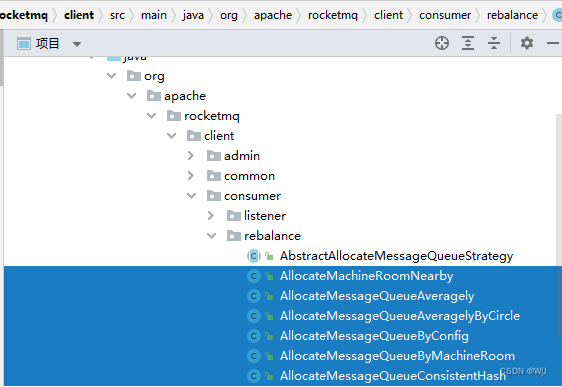
如图 7-2 所示,具体的负载均衡算法有五种,默认用的是第一种AllocateMessageQueueAveragely 。 负载均衡的结果与 Topic 的 Message Queue 数量,以及 ConsumerGroup 里的 Consumer 的数量有关。 负载均衡的分配粒度只到 Message Queue ,把 Topic 下的所有 Message Queue 分配到不同的Consumer 中,所以 Message Queue 和 Consumer 的数量关系,或者整除关系影响负载均衡结果。
以 AllocateMessageQueueAve ragely 策略为例,如果创建 Topic 的时候,把Message Queue 数设为 3 , 当 Consumer 数量为 2 的时候,有一个 Consumer 需要处理 Topic 三分之二的消息,另一个处理三分之一的消息;当 Consumer 数量为 4 的时候,有 一个 Consumer 无法收到消息,其他 3 7.3.2 DefaultMQPullConsumer 的负载均衡个 Consumer 各处理Topic 三分之一 的消息 。可见 Message Queue 数量设置过小不利于做负载均衡,通常情况下,应把一个 Topic 的 Message Queue 数设置为 16 。
RocketMQ负载均衡![]() https://blog.csdn.net/Weixiaohuai/article/details/123898841
https://blog.csdn.net/Weixiaohuai/article/details/123898841
7.3.2 DefaultMQPullConsumer 的负载均衡
Pull Consumer 可以看到所有的 Message Queue , 而且从哪个 MessageQueue 读取消息,读消息时的 Offset 都由使用者控制,使用者可以实现任何特殊方式的负载均衡。DefaultMQPullConsumer 有两个辅助方法可以帮助实现负载均衡,一个是registerMessageQueueListener 函数
registerMessageQueueListener 函数在有新的 Consumer 加入或退出时被触发。 另一个辅助工具是 MQPullConsumerScheduleService 类,使用这个 Class类 似使用 DefaultMQPushConsumer ,但是它把 Pull 消息的主动性留给了使用者。
import com.alibaba.rocketmq.client.consumer.MQPullConsumerScheduleService; //导入依赖的package包/类
public static void main(String[] args) throws MQClientException {
final MQPullConsumerScheduleService scheduleService = new MQPullConsumerScheduleService("GroupName1");
scheduleService.setMessageModel(MessageModel.CLUSTERING);
scheduleService.registerPullTaskCallback("TopicTest1", new PullTaskCallback() {
@Override
public void doPullTask(MessageQueue mq, PullTaskContext context) {
MQPullConsumer consumer = context.getPullConsumer();
try {
long offset = consumer.fetchConsumeOffset(mq, false);
if (offset < 0)
offset = 0;
PullResult pullResult = consumer.pull(mq, "*", offset, 32);
System.out.println(offset + "\t" + mq + "\t" + pullResult);
switch (pullResult.getPullStatus()) {
case FOUND:
break;
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
case OFFSET_ILLEGAL:
break;
default:
break;
}
consumer.updateConsumeOffset(mq, pullResult.getNextBeginOffset());
context.setPullNextDelayTimeMillis(100);
}
catch (Exception e) {
e.printStackTrace();
}
}
});
scheduleService.start();
} 然后我们 看一看在 MQPullConsumerScheduleService 类的实现里,实现负载均衡的代码PullScheduleService.java![]() https://gitee.com/apache/rocketmq/blob/develop/example/src/main/java/org/apache/rocketmq/example/simple/PullScheduleService.java
https://gitee.com/apache/rocketmq/blob/develop/example/src/main/java/org/apache/rocketmq/example/simple/PullScheduleService.java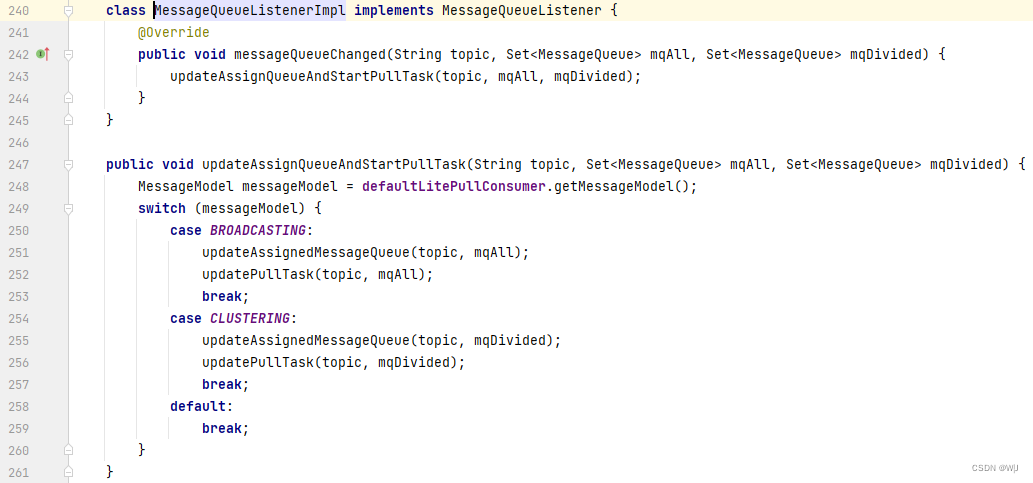
从源码中可以看出,用户通过更改 MessageQueueListenerimpl 的实现来做自己的负载均衡策略。
7.4 提高 Producer 的发送速度
发送一条消息出去要经过三步,一是客户端发送请求到服务器,二是服务器处理该请求, 三是服务器向客户端返回应答, 一次消息的发送耗时是上述三个步骤的总和 。在一些对速度要求高,但是可靠性要求不高的场景下,比如日志收集类应用 ,可以采用 Oneway 方式发送, O neway 方式只发送请求不等待应答,即将数据写入客户端的 Socket 缓冲区就返回,不等待对方返回结果,用这种方式发送消息的耗时可以缩短到微秒级。
另一种提高发送速度的方法是增加 Producer 的并发量,使用多个 Producer 同时发送,我们不用担心多 Producer 同时写会降低消息写磁盘的效率,RocketMQ 引人了 一个并发窗口,在窗口内消息可以并发地写入 DirectMem 中 ,然后异步地将连续一段无空洞的数据刷入文件系统当中 。 顺序写 CommitLog 可让 RocketMQ 无论在 HDD 还是 SSD 磁盘情况下都能保持较高的写入性能。 目前在阿里内部经过调优的服务器上,写人性能达到 90 万+的 TPS ,我们可以参考这个数据进行系统优化。
在 Linux 操作系统层级进行调优,推荐使用 EXT4 文件系统, IO 调度算法使用 deadline 算法。
如图 7-3 所示, EXT4 创建/删除文件的性能比 EXT3 及其他文件系统要好, RocketMQ 的 CommitLog 会有频繁的创建/删除动作 。
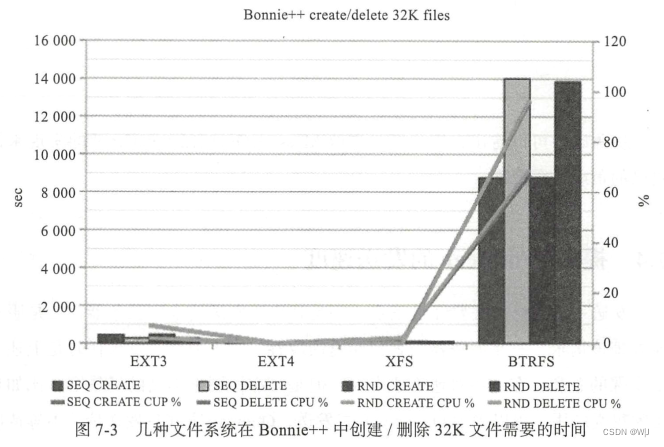
另外, IO 调度算法也推荐调整为 deadline 。 deadline 算法大致思想如下 :实现四个队列,其中两个处理正常的 read 和 write 操作,另外两个处理超时的read 和 write 操作。 正常的 read 和 write 队列中,元素按扇区号排序,进行正常的 IO 合并处理以提高吞吐量。 因为 IO 请求可能会集中在某些磁盘位置,这样会导致新来的请求一直被合并,可能会有其他磁盘位置 的 IO 请求被饿死。 超时的 read 和 write 的队列中,元素按请求创建时间排序,如果有超时的请求出现,就放进这两个队列,调度算法保证超时(达到最终期限时间)的队列中的IO 请求会优先被处理。
7.5 系统性能调优的一般流程
这里讨论的系统是指能完成某项功能的软硬件 整 体,比如我们用RocketMQ ,加上自己 写 的 Producer 、 Consumer 程序,部署到一台服务器上,组成一个消息处理系统。
首先是搭建测试环境, 查看硬件利用率。 把测试系统搭建好以后,要想办法模拟实际使用时的情况,并且逐步增大请求量 ,同时检测系统的 TPS 。 在请求量增大到一定程度时·,系统的 QPS 达到峰值,这个时候维持这种请求量,保持系统在峰值状态下运行。 然后查看此时系统的硬件使用情况:
( 1 )使用 TOP 命令查看 CPU 和内存的利用率

上面的数据显示, CPU 有 99 . 8% 空闲;内存总共 8G ,有大约 1.5G 空闲 。
( 2 ) 使用 Linux 的 sar 命令查看网卡使用情况

如果想进一步验证网卡是否达到了极限值,可以使用 iperf3 命令查看。 还可以用 nets tat 一t 查看 网卡的连接情况, 看是否有大量连接造成堵塞 。
然后用 iostat 查看磁盘的使用情况 :

经过上面的一 系列检查 ,应该能够找到系统的瓶颈。 比如瓶颈是在 CPU 、网卡还是磁盘? 可以先确定网卡和磁盘是否繁忙,这两个中如果有一个被占满了, 问题就可以被直接定位了 。 比如网 卡打满了,我们可以判断是发送的数据量超出了网卡的带宽 ,可以 考虑更换高速网卡,或者更新程序减少数据发送量。
还有一种情况是这三者都没有到使用极限, 这也是一种比较常见而且有优化空 间的情况,这种情况说明 CPU 利用率没有发挥出来, 比如可能是锁的机制有 bug ,造成线程阻塞 。对于 Java 程序来说,接下来可以用 Java 的 profiling 工具来找出程序的具体问题,比如 jvisualvm 、 jstack 、 perfJ 等 。
通过上面这些工具,可以逐步定位出是哪些 Java 线程比较慢,|那个函数占用的时间多,是否因为存在锁造成了忙等的情况,然后通过不断的更改测试,找到影响性能的关键代码,最终解决问题。